Downloaded 485 times












![References
• [1] Pang-Ning Tan, Michael Steinbach, Vipin
Kumar:Introduction to Data Mining, Addison-
Wesley
• www.wikipedia.org](https://image.slidesharecdn.com/fp-growthalgorithm-130902000352-phpapp01/85/Fp-growth-algorithm-17-320.jpg)

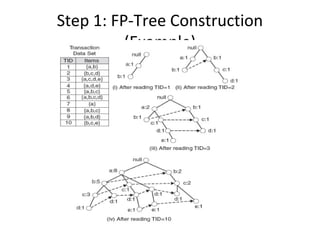
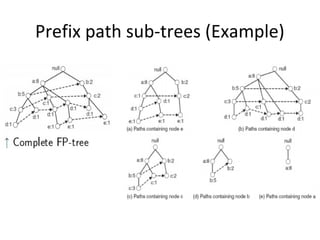
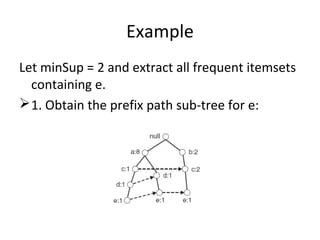
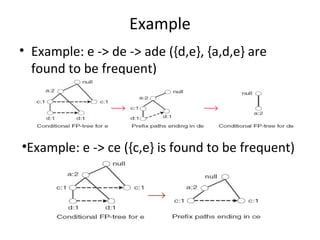
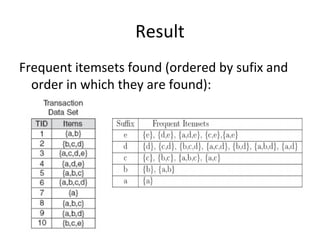
The document describes the FP-Growth algorithm for frequent itemset mining. It has two main steps: (1) building a compact FP-tree from the dataset in two passes and (2) extracting frequent itemsets directly from the FP-tree by looking for prefix paths. The FP-tree allows mining frequent itemsets without candidate generation by compressing the dataset.



































































