Download as PDF, PPTX

















































![67Copyright©2016 NTT corp. All Rights Reserved.
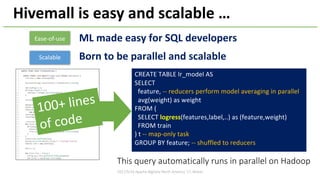
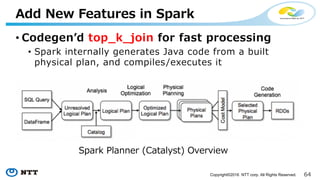
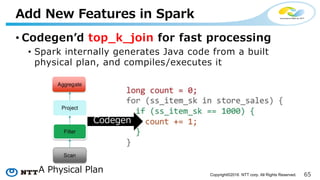
• Codegenʼd top_k_join for fast processing
• Spark internally generates Java code from a built
physical plan, and compiles/executes it
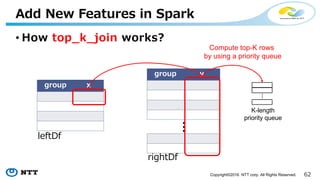
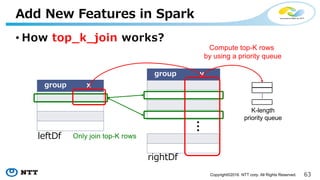
Add New Features in Spark
scala> topkDf.explain
== Physical Plan ==
*ShuffledHashJoinTopK 1, [group#10], [group#27]
:- Exchange hashpartitioning(group#10, 200)
: +- LocalTableScan [group#10, x#11]
+- Exchange hashpartitioning(group#27, 200)
+- LocalTableScan [group#27, y#28]
ʻ*ʼ in the head means a codegenʼd plan](https://image.slidesharecdn.com/apachebigdata2017-170520184648/85/Apache-Hivemall-Apache-BigData-17-Miami-67-320.jpg)












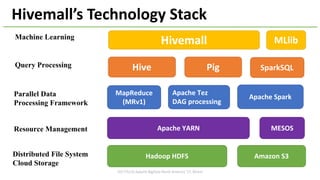
This document summarizes a presentation about Apache Hivemall, a scalable machine learning library for Apache Hive, Spark, and Pig. Hivemall provides easy-to-use machine learning functions that can run efficiently in parallel on large datasets. It supports various classification, regression, recommendation, and clustering algorithms. The presentation outlines Hivemall's capabilities, how it works with different big data platforms like Hive and Spark, and its ongoing development including new features like XGBoost integration and generalized linear models.






































































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)





