Download to read offline



![Problem Statement
• Train a self driving agent using
RL algorithms in simulation.
• To have an algorithm that can
be run on Argo’s driving logs.
• To aim for sample efficient
algorithms. An agent exploring the CARLA environment [1]](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-4-320.jpg)
![Motivation – Why Reinforcement Learning?
• End-to-end system.
Self-driving cars today are highly modular [2]](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-5-320.jpg)
![Motivation – Why Reinforcement Learning?
• End-to-end system.
• Verifiable performance
through simulation.
We can simulate rare events to test the robustness of an algorithm [1]](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-6-320.jpg)


![Related work
• Controllable Imitative
Reinforcement Learning
• Train an imitation learning
model and finetunes using
DDPG
[3] Liang, Xiaodan, et al. "Cirl: Controllable imitative reinforcement learning for vision-based self-driving." Proceedings of the European Conference on Computer Vision (ECCV). 2018.](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-9-320.jpg)
![Related work
• Controllable Imitative
Reinforcement Learning
• Learning by Cheating
• A big improvement
• Uses an abundant supply
of “oracle” info to train a
large model ( Resnet-34 )
[1] Chen et al.,“Learning by cheating”, Conference on Robot Learning, 2019](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-10-320.jpg)
![Related work
• Controllable Imitative
Reinforcement Learning
• Learning by Cheating
• Learning to drive in a day
• RL on a real car!
• Uses a tiny model (10k) and a
tiny state space (~10).
• No dynamic actors
• Uses DDPG
[4] Kendall, Alex, et al. "Learning to drive in a day." 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019.](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-11-320.jpg)







![Previous Work in Lab
• Used Proximal Policy Optimization (PPO)
• State space
• Encoded SS Images with WP
• Reward
• Speed based reward
• Distance to trajectory
• Collision reward
[5] Agarwal, et al. “Learning to Drive using Waypoints“, NeurIPS 2019 Workshop – ML4AD](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-19-320.jpg)
![Previous Work in Lab
• Excels in Straight, Navigation and One-
Turn
• Struggles to brake for other cars in
Navigation with dynamic actors.
[5] Agarwal, et al. “Learning to Drive using Waypoints“, NeurIPS 2019 Workshop – ML4AD](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-20-320.jpg)
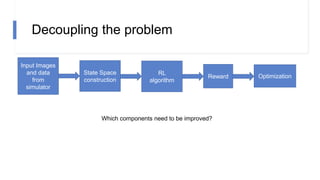
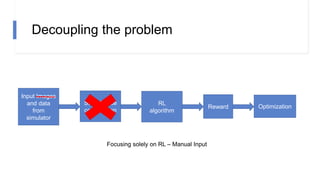
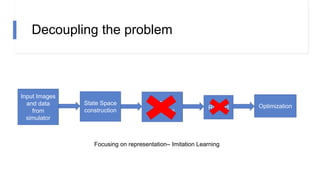
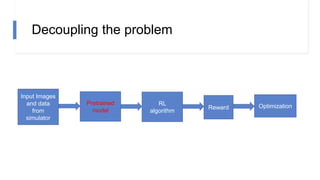


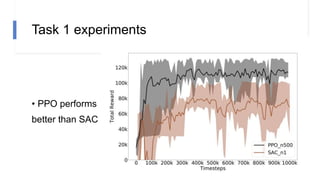

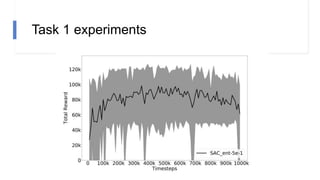
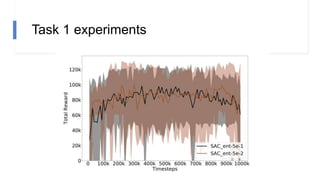
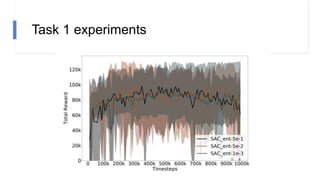
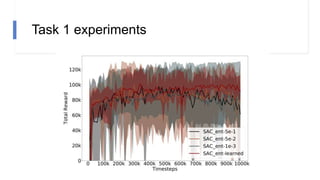


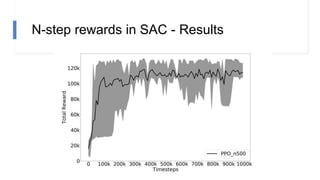
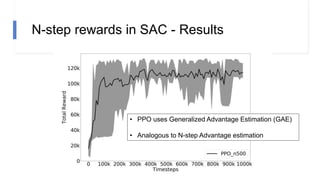
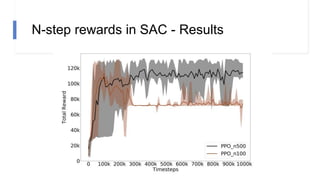
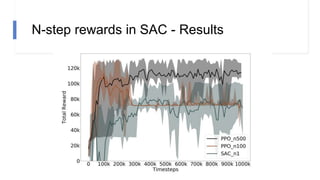
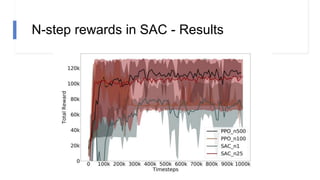
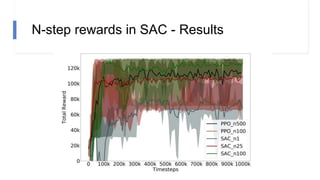
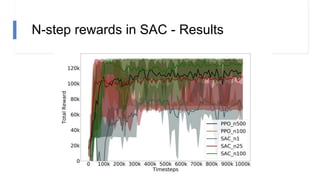
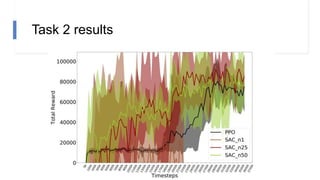
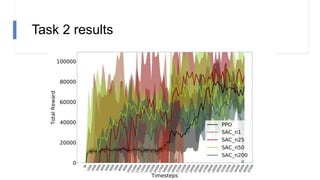
![N-step rewards in SAC - Results
• Not using importance sampling
• No major effect for small N
• Large N will induce bias again!
[6] Hernandez-Garcia, J. Fernando, and Richard S. Sutton. "Understanding multi-step deep reinforcement learning: A systematic study of the DQN target.“
[7] Hessel, et al. "Rainbow: Combining improvements in deep reinforcement learning." AAAI 2018.](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-43-320.jpg)






![Future Work – Image inputs
• Move from manual state space
to image state space
• Instead of using Autoencoder
representations, leverage the
Imitation learning pretrained
model
Channel visualization from output of conv layers of LBC’s Resnet-34 [1] trained to drive](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-56-320.jpg)
![References
[1] Chen et al., “Learning by cheating”, CoRL 2019.
[2] Prof Jeff Schneider’s RI Seminar Talk
[3] Liang, Xiaodan, et al. "Cirl: Controllable imitative reinforcement learning for vision-based self-
driving.“, ECCV, 2018.
[4] Kendall, Alex, et al. "Learning to drive in a day.“, ICRA, IEEE, 2019.
[5] Agarwal, et al. “Learning to Drive using Waypoints“, NeurIPS 2019 Workshop – ML4AD
[6] Hernandez-Garcia, J. Fernando, and Richard S. Sutton. "Understanding multi-step deep
reinforcement learning: A systematic study of the DQN target.“
[7] Hessel, et al. "Rainbow: Combining improvements in deep reinforcement learning." AAAI 2018.](https://image.slidesharecdn.com/rlfinalpresentation-200508204243/85/MSCV-Capstone-Spring-2020-Presentation-RL-for-AD-58-320.jpg)

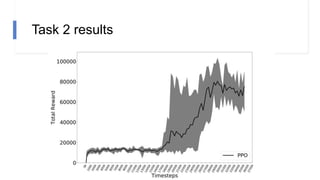
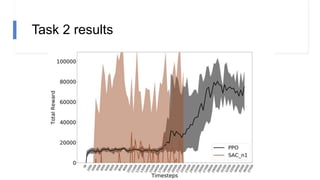
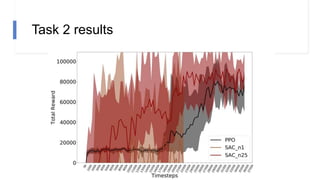
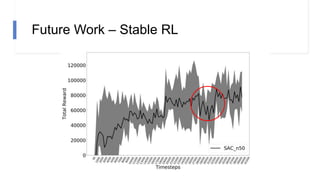
The document describes research on using reinforcement learning for self-driving cars. It discusses using the Soft Actor Critic algorithm to train an agent in a simulated environment. Experiments are conducted in navigation tasks with and without dynamic actors. The agent is able to complete the simple navigation task but struggles in the more complex task with actors. Future work focuses on improving algorithm stability and using image inputs instead of a manual state space.














![[1808.00177] Learning Dexterous In-Hand Manipulation](https://cdn.slidesharecdn.com/ss_thumbnails/learningdextrousinhandmanipulation-180814000608-thumbnail.jpg?width=640&height=640&fit=bounds)












































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)