Downloaded 685 times




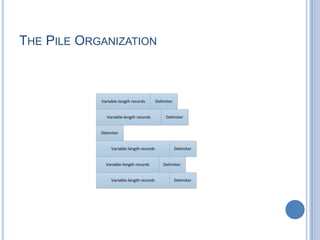


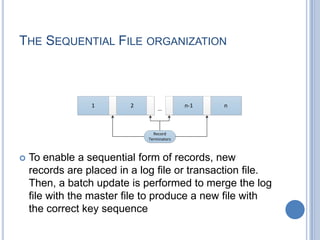


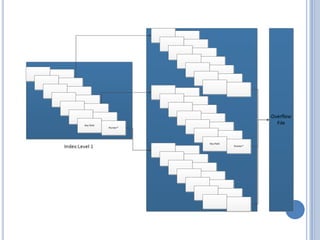

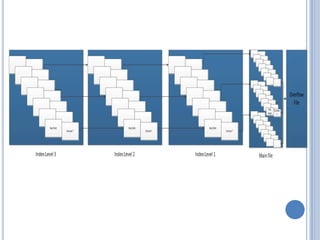

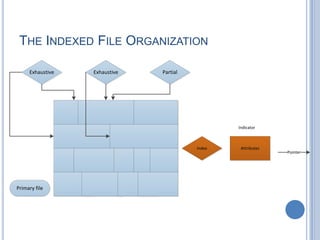

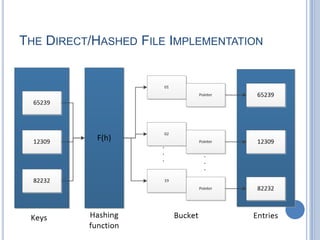


This document discusses different file organization methods including sequential files, indexed sequential files, indexed files, and direct/hashed files. Sequential files store records in the order they are entered with each record having a fixed format. Indexed sequential files add an index to allow random access by key fields while maintaining sequential ordering. Indexed files use multiple indexes on different keys to allow searching by different fields. Direct/hashed files directly access records by key values using hashing techniques for fast random access.



































































