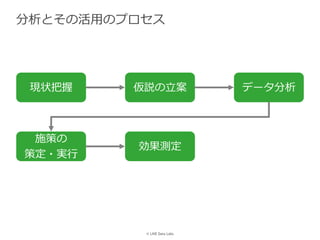
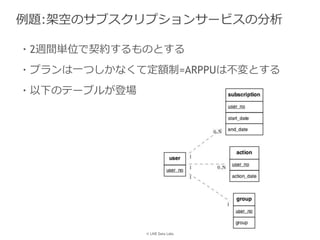
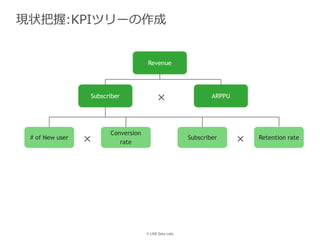
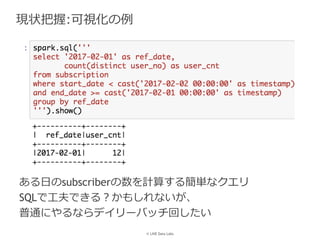
LINE株式会社 DataLabs 丸尾大貴 PyData.Tokyo Meetup #17 - データ分析の現場 での発表資料です。 https://pydatatokyo.connpass.com/event/77008/















![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Wav2CLIP: Learning Robust Audio Representations From CLIP](https://cdn.slidesharecdn.com/ss_thumbnails/dlwav2clip1-211105022837-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)
 Variational Autoencoders for Collaborative Filtering](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0207hozumi-200207030936-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


































