Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Keigo Suda
PDF, PPTX
12,966 views
基幹業務もHadoopで!! -ローソンにおける店舗発注業務への Hadoop + Hive導入と その取り組みについて-
Hadoop/Sparkカンファレンス2016講演資料
Internet
◦
Read more
29
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 71
2
/ 71
3
/ 71
4
/ 71
5
/ 71
6
/ 71
7
/ 71
8
/ 71
9
/ 71
10
/ 71
11
/ 71
12
/ 71
13
/ 71
14
/ 71
15
/ 71
16
/ 71
17
/ 71
18
/ 71
19
/ 71
20
/ 71
21
/ 71
22
/ 71
23
/ 71
24
/ 71
25
/ 71
26
/ 71
27
/ 71
28
/ 71
29
/ 71
30
/ 71
31
/ 71
32
/ 71
33
/ 71
34
/ 71
35
/ 71
36
/ 71
37
/ 71
38
/ 71
39
/ 71
40
/ 71
41
/ 71
42
/ 71
43
/ 71
44
/ 71
45
/ 71
46
/ 71
47
/ 71
48
/ 71
49
/ 71
50
/ 71
51
/ 71
52
/ 71
53
/ 71
54
/ 71
55
/ 71
56
/ 71
57
/ 71
58
/ 71
59
/ 71
60
/ 71
61
/ 71
62
/ 71
63
/ 71
64
/ 71
65
/ 71
66
/ 71
67
/ 71
68
/ 71
69
/ 71
70
/ 71
71
/ 71
More Related Content
PPTX
OSSプロジェクトへのコントリビューション はじめの一歩を踏み出そう!(Open Source Conference 2022 Online/Spring...
by
NTT DATA Technology & Innovation
PPTX
Spanner移行について本気出して考えてみた
by
techgamecollege
PPTX
ITコミュニティと情報発信に共通する成長と貢献の要素
by
NISHIHARA Shota
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PDF
DockerとPodmanの比較
by
Akihiro Suda
PPTX
フックを使ったPostgreSQLの拡張機能を作ってみよう!(第33回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料)
by
NTT DATA Technology & Innovation
PDF
containerdの概要と最近の機能
by
Kohei Tokunaga
OSSプロジェクトへのコントリビューション はじめの一歩を踏み出そう!(Open Source Conference 2022 Online/Spring...
by
NTT DATA Technology & Innovation
Spanner移行について本気出して考えてみた
by
techgamecollege
ITコミュニティと情報発信に共通する成長と貢献の要素
by
NISHIHARA Shota
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
DockerとPodmanの比較
by
Akihiro Suda
フックを使ったPostgreSQLの拡張機能を作ってみよう!(第33回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料)
by
NTT DATA Technology & Innovation
containerdの概要と最近の機能
by
Kohei Tokunaga
What's hot
PDF
新人研修資料 向き合うエンジニア
by
akira6592
PDF
Dapr × Kubernetes ではじめるポータブルなマイクロサービス(CloudNative Days Tokyo 2020講演資料)
by
NTT DATA Technology & Innovation
PDF
ChatGPTは思ったほど賢くない
by
Carnot Inc.
PDF
メルカリ・ソウゾウでは どうGoを活用しているのか?
by
Takuya Ueda
ODP
Guide To AGPL
by
Mikiya Okuno
PPTX
【Photon勉強会】1時間でわかるプラグイン開発とその実際(2017/3/23講演)
by
Photon運営事務局
PDF
ネットワークOS野郎 ~ インフラ野郎Night 20160414
by
Kentaro Ebisawa
PDF
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
PPTX
DXとかDevOpsとかのなんかいい感じのやつ 富士通TechLive
by
Tokoroten Nakayama
PDF
PostgreSQLのバグとの付き合い方 ~バグの調査からコミュニティへの報告、修正パッチ投稿まで~(PostgreSQL Conference Japa...
by
NTT DATA Technology & Innovation
PDF
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PDF
Yahoo! JAPANにおけるApache Cassandraへの取り組み
by
Yahoo!デベロッパーネットワーク
PDF
PostgreSQLでスケールアウト
by
Masahiko Sawada
PDF
入門 シェル実装
by
Yusuke Sangenya
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PDF
10分でわかる Cilium と XDP / BPF
by
Shuji Yamada
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
今話題のいろいろなコンテナランタイムを比較してみた
by
Kohei Tokunaga
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
PDF
eStargzイメージとlazy pullingによる高速なコンテナ起動
by
Kohei Tokunaga
新人研修資料 向き合うエンジニア
by
akira6592
Dapr × Kubernetes ではじめるポータブルなマイクロサービス(CloudNative Days Tokyo 2020講演資料)
by
NTT DATA Technology & Innovation
ChatGPTは思ったほど賢くない
by
Carnot Inc.
メルカリ・ソウゾウでは どうGoを活用しているのか?
by
Takuya Ueda
Guide To AGPL
by
Mikiya Okuno
【Photon勉強会】1時間でわかるプラグイン開発とその実際(2017/3/23講演)
by
Photon運営事務局
ネットワークOS野郎 ~ インフラ野郎Night 20160414
by
Kentaro Ebisawa
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
DXとかDevOpsとかのなんかいい感じのやつ 富士通TechLive
by
Tokoroten Nakayama
PostgreSQLのバグとの付き合い方 ~バグの調査からコミュニティへの報告、修正パッチ投稿まで~(PostgreSQL Conference Japa...
by
NTT DATA Technology & Innovation
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
Yahoo! JAPANにおけるApache Cassandraへの取り組み
by
Yahoo!デベロッパーネットワーク
PostgreSQLでスケールアウト
by
Masahiko Sawada
入門 シェル実装
by
Yusuke Sangenya
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
10分でわかる Cilium と XDP / BPF
by
Shuji Yamada
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
今話題のいろいろなコンテナランタイムを比較してみた
by
Kohei Tokunaga
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
eStargzイメージとlazy pullingによる高速なコンテナ起動
by
Kohei Tokunaga
Viewers also liked
PDF
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
PDF
Awsでつくるapache kafkaといろんな悩み
by
Keigo Suda
PDF
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
PDF
スマートファクトリーを支えるIoTインフラをつくった話
by
Keigo Suda
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PPTX
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
PDF
AWSマネージドサービスをフル活用したヘルスケアIoTプラットフォーム
by
Hiroki Takeda
PDF
ログモニタリングツールを自作した話
by
Hiroki Takeda
PDF
AI(強化学習)でロボットに学習させてみた
by
akmtt
PPTX
Future_Lt20160810
by
Yosuke Tanaka
PDF
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
PPTX
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
PDF
Maintainable cloud architecture_of_hadoop
by
Kai Sasaki
PDF
Spark 2.0 What's Next (Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
PPTX
Spark CL
by
力世 山本
PDF
2016-02-08 Spark MLlib Now and Beyond@Spark Conference Japan 2016
by
Yu Ishikawa
PDF
未来太郎と未来花子
by
ming li
PPTX
20161119 lt
by
aiko sato
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
Awsでつくるapache kafkaといろんな悩み
by
Keigo Suda
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
スマートファクトリーを支えるIoTインフラをつくった話
by
Keigo Suda
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
データドリブン企業におけるHadoop基盤とETL -niconicoでの実践例-
by
Makoto SHIMURA
AWSマネージドサービスをフル活用したヘルスケアIoTプラットフォーム
by
Hiroki Takeda
ログモニタリングツールを自作した話
by
Hiroki Takeda
AI(強化学習)でロボットに学習させてみた
by
akmtt
Future_Lt20160810
by
Yosuke Tanaka
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
Maintainable cloud architecture_of_hadoop
by
Kai Sasaki
Spark 2.0 What's Next (Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
Spark CL
by
力世 山本
2016-02-08 Spark MLlib Now and Beyond@Spark Conference Japan 2016
by
Yu Ishikawa
未来太郎と未来花子
by
ming li
20161119 lt
by
aiko sato
Similar to 基幹業務もHadoopで!! -ローソンにおける店舗発注業務への Hadoop + Hive導入と その取り組みについて-
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
PDF
リクルート式Hadoopの使い方
by
Recruit Technologies
PDF
Smart storeを実現するAzureサービス IoT編
by
Microsoft Azure Japan
PDF
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
PPTX
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
PPTX
ビッグデータ&データマネジメント展
by
Recruit Technologies
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
HCCJP teradata final_20190906
by
Masakazu Nomura
PPTX
700億件のリアルタイム分析の実現と運用の実態
by
Eiji Yamamoto
PDF
Apache Hadoopを利用したビッグデータ分析基盤
by
Hortonworks Japan
PPTX
(2017.6.2) Azure HDInsightで実現するスケーラブル分析環境
by
Mitsutoshi Kiuchi
PDF
基幹業務もHadoop(EMR)で!!のその後
by
Keigo Suda
PPT
Hadoop Conference Japan 2009 #1
by
Rakuten Group, Inc.
PDF
[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...
by
Insight Technology, Inc.
PDF
先進事例に見るIoT活用の事始め~データサイエンスの観点から~
by
Daiki Kato
PDF
ビッグデータ活用とサーバー基盤
by
日本ヒューレット・パッカード株式会社
PPTX
Data x AI x API で考えるビジネスインフラ
by
Daiyu Hatakeyama
PDF
「IoT時代のデータのあり方と活用の方向性」名古屋大学エネルギーシステムシンポジウム 170222
by
知礼 八子
PDF
Business encount
by
和喜 竹川
PDF
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
リクルート式Hadoopの使い方
by
Recruit Technologies
Smart storeを実現するAzureサービス IoT編
by
Microsoft Azure Japan
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
ビッグデータ&データマネジメント展
by
Recruit Technologies
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
HCCJP teradata final_20190906
by
Masakazu Nomura
700億件のリアルタイム分析の実現と運用の実態
by
Eiji Yamamoto
Apache Hadoopを利用したビッグデータ分析基盤
by
Hortonworks Japan
(2017.6.2) Azure HDInsightで実現するスケーラブル分析環境
by
Mitsutoshi Kiuchi
基幹業務もHadoop(EMR)で!!のその後
by
Keigo Suda
Hadoop Conference Japan 2009 #1
by
Rakuten Group, Inc.
[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...
by
Insight Technology, Inc.
先進事例に見るIoT活用の事始め~データサイエンスの観点から~
by
Daiki Kato
ビッグデータ活用とサーバー基盤
by
日本ヒューレット・パッカード株式会社
Data x AI x API で考えるビジネスインフラ
by
Daiyu Hatakeyama
「IoT時代のデータのあり方と活用の方向性」名古屋大学エネルギーシステムシンポジウム 170222
by
知礼 八子
Business encount
by
和喜 竹川
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
More from Keigo Suda
PDF
ストリーム処理勉強会 大規模mqttを支える技術
by
Keigo Suda
PDF
Apache Kafka & Kafka Connectを に使ったデータ連携パターン(改めETLの実装)
by
Keigo Suda
PDF
Apache drillを業務利用してみる(までの道のり)
by
Keigo Suda
PDF
Kafka logをオブジェクトストレージに連携する方法まとめ
by
Keigo Suda
PDF
Lt 私の○○遍歴教えるね これまで愛したキーボードたち
by
Keigo Suda
PDF
20171105 go con2017_lt
by
Keigo Suda
ストリーム処理勉強会 大規模mqttを支える技術
by
Keigo Suda
Apache Kafka & Kafka Connectを に使ったデータ連携パターン(改めETLの実装)
by
Keigo Suda
Apache drillを業務利用してみる(までの道のり)
by
Keigo Suda
Kafka logをオブジェクトストレージに連携する方法まとめ
by
Keigo Suda
Lt 私の○○遍歴教えるね これまで愛したキーボードたち
by
Keigo Suda
20171105 go con2017_lt
by
Keigo Suda
基幹業務もHadoopで!! -ローソンにおける店舗発注業務への Hadoop + Hive導入と その取り組みについて-
1.
基幹業務もHadoopで!! Hadoop / Spark
Conference 2016 Future Architect Keigo Suda ローソンにおける店舗発注業務への Hadoop + Hive導入と その取り組みについて
2.
本発表を通してお伝えしたいこと Enterprise 基幹領域でのHadoop活用シーンへのヒント どういった課題をクリアするために? どんなことを検討/対応する必要がある? ※資料は後ほど公開致します
3.
目に焼き付けておきなさい。 Hadoopを使うってそういうことよ (綺麗なことばかりじゃないのよ)
4.
自己紹介 * 須田 桂伍(2012年入社) *
Technology Innovation Group シニアコンサルタント * インフラエンジニア~ソフトウェアアーキテクト * 最近はビッグデータ領域(情報系~基幹系)どっぷり 最近はQiita記事に技術ネタ投稿してます 直近の生きる目標(人生のマイルストン)
5.
Outline Introduction Architecture Team Development Conclusion
6.
Our Company
7.
フューチャーアーキテクト株式会社 (英文表記:Future Architect, Inc.) 設
立 上 場 資 本 金 代 表 者 売 上 高 社 員 数 オフィス : 1989年11月28日 : 2002年6月 東証1部 : 14億21百万円 : 代表取締役会長 CEO 金丸 恭文 : 連結344億24百万円、単体197億27百万円 (2014年12月期) : 連結1,587名、単体783名 (2014年12月末日現在) : 大崎 (本社)、大阪、鹿児島、福岡
11.
Introduction
12.
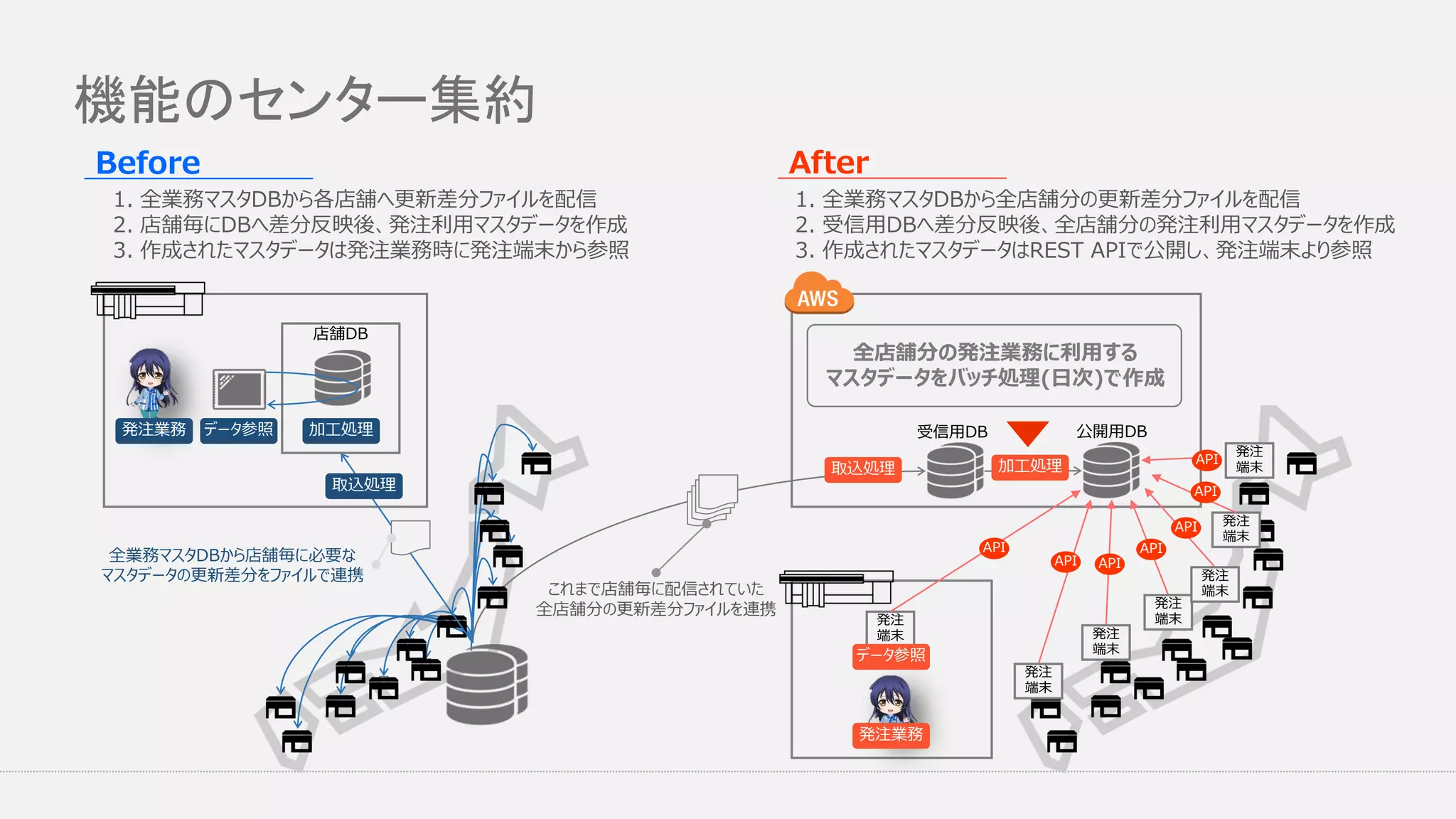
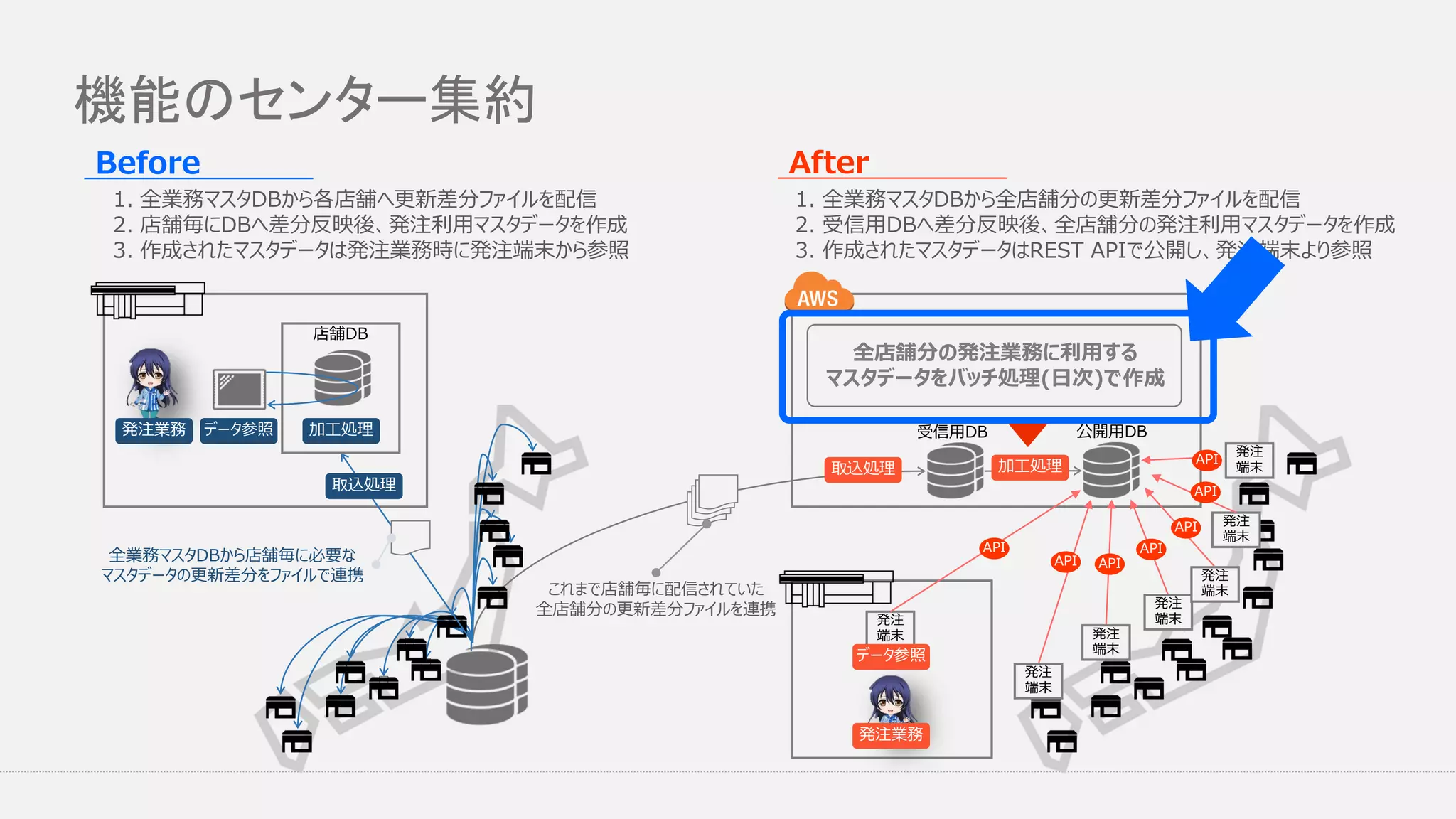
店舗発注業務のセンター化 発注時に利用するマスタ作成をセンタ集約 店舗毎に行われていたマスタデータ作成処理を集約 店舗からはAPI経由でマスタデータを参照
13.
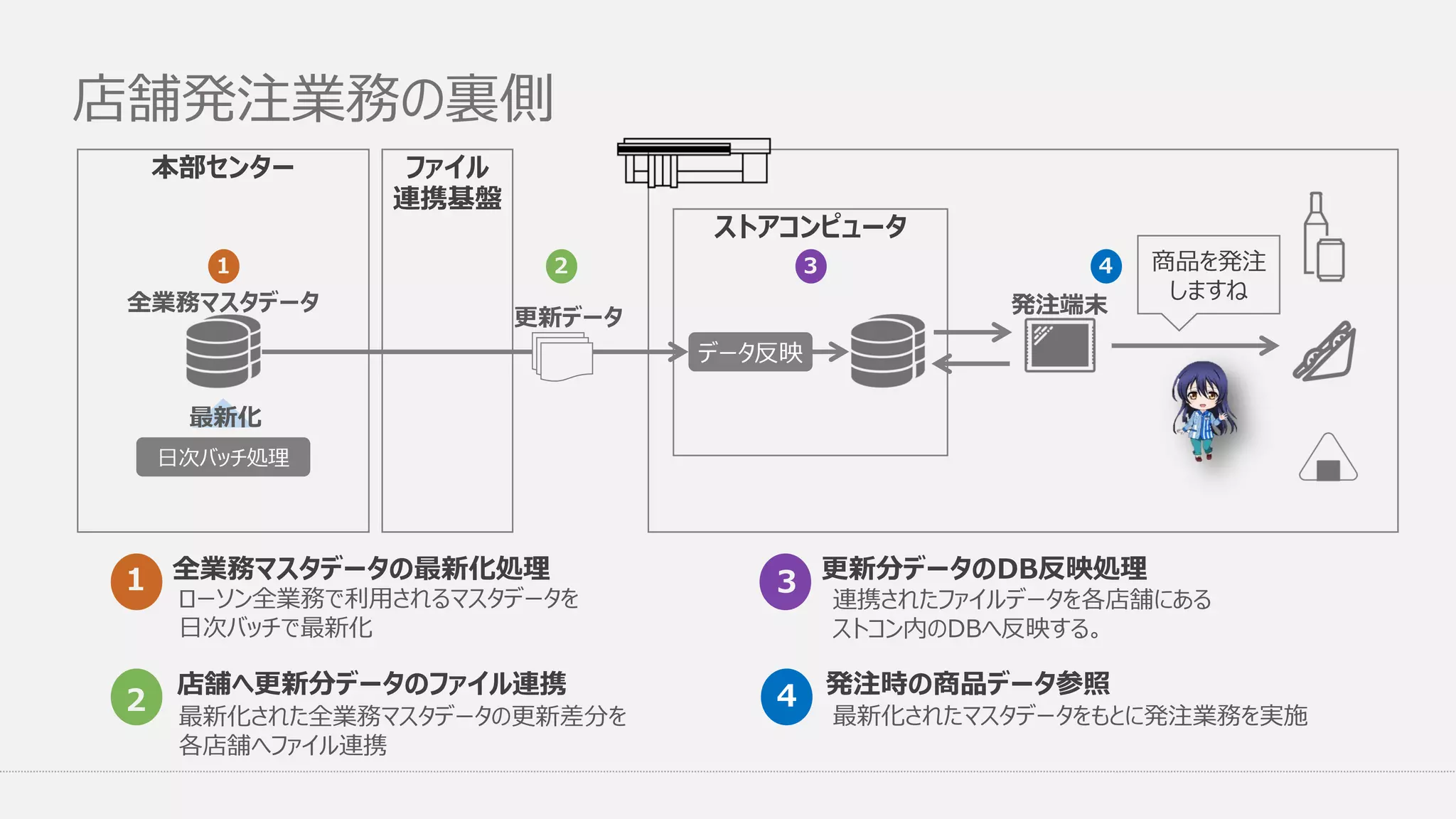
店舗発注業務の裏側 ローソン全業務で利用されるマスタデータを 日次バッチで最新化 1 最新化された全業務マスタデータの更新差分を 各店舗へファイル連携 店舗へ更新分データのファイル連携 2 本部センター ファイル 連携基盤 ストアコンピュータ データ反映 発注端末 商品を発注 しますね 更新データ 全業務マスタデータ 日次バッチ処理 最新化 1 2
3 4 全業務マスタデータの最新化処理 連携されたファイルデータを各店舗にある ストコン内のDBへ反映する。 3 最新化されたマスタデータをもとに発注業務を実施 発注時の商品データ参照4 更新分データのDB反映処理
14.
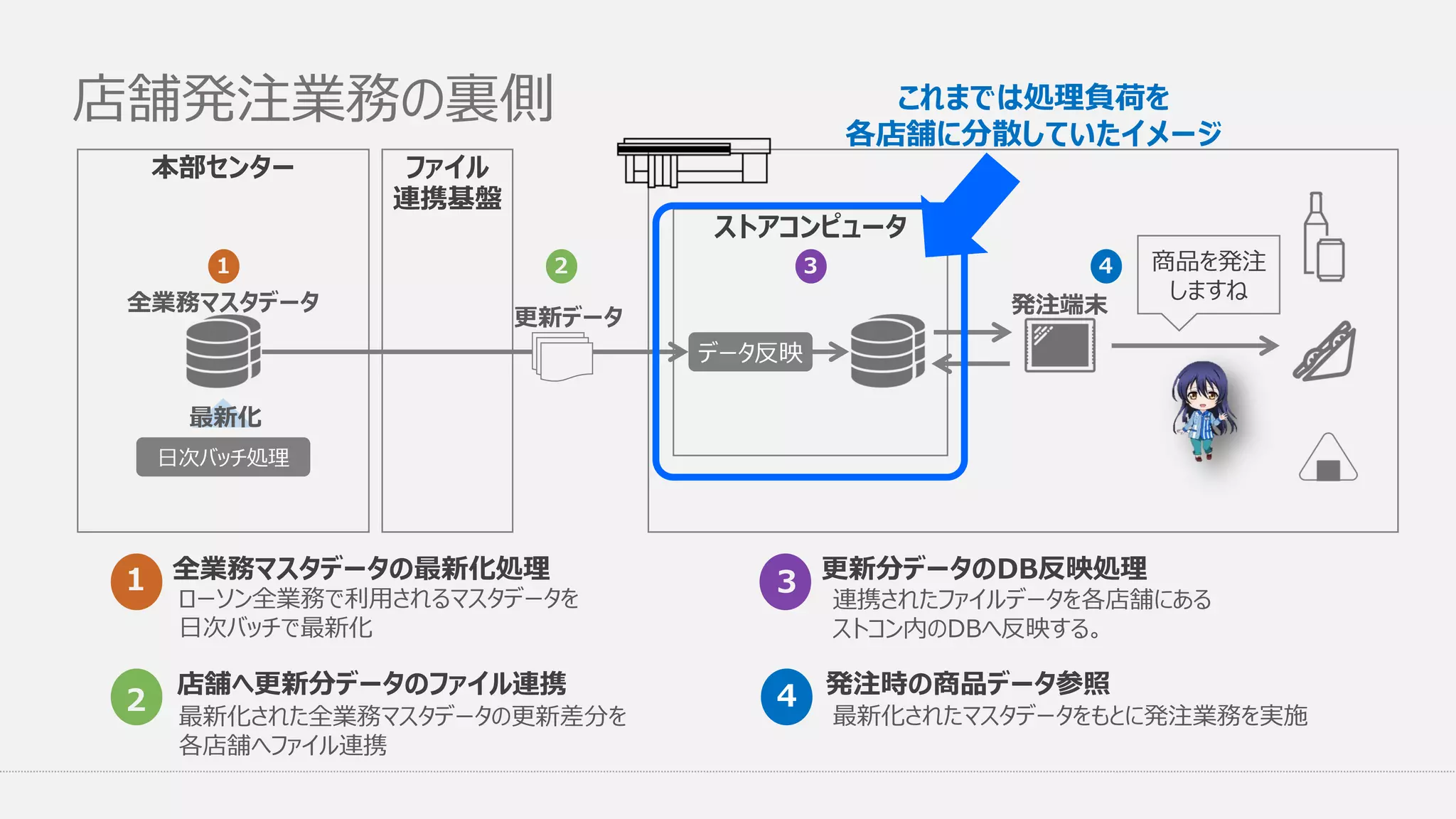
店舗発注業務の裏側 ローソン全業務で利用されるマスタデータを 日次バッチで最新化 1 最新化された全業務マスタデータの更新差分を 各店舗へファイル連携 店舗へ更新分データのファイル連携 2 本部センター ファイル 連携基盤 ストアコンピュータ データ反映 発注端末 商品を発注 しますね 更新データ 全業務マスタデータ 日次バッチ処理 最新化 1 2
3 4 全業務マスタデータの最新化処理 連携されたファイルデータを各店舗にある ストコン内のDBへ反映する。 3 最新化されたマスタデータをもとに発注業務を実施 発注時の商品データ参照4 更新分データのDB反映処理 これまでは処理負荷を 各店舗に分散していたイメージ
15.
機能のセンター集約 店舗DB 発注業務 データ参照 加工処理 加工処理取込処理 取込処理 発注 端末 発注 端末 発注 端末 発注 端末 発注 端末 発注 端末 発注 端末 API API
API API API API API 全店舗分の発注業務に利用する マスタデータをバッチ処理(日次)で作成 全業務マスタDBから店舗毎に必要な マスタデータの更新差分をファイルで連携 これまで店舗毎に配信されていた 全店舗分の更新差分ファイルを連携 受信用DB 公開用DB 1. 全業務マスタDBから各店舗へ更新差分ファイルを配信 2. 店舗毎にDBへ差分反映後、発注利用マスタデータを作成 3. 作成されたマスタデータは発注業務時に発注端末から参照 1. 全業務マスタDBから全店舗分の更新差分ファイルを配信 2. 受信用DBへ差分反映後、全店舗分の発注利用マスタデータを作成 3. 作成されたマスタデータはREST APIで公開し、発注端末より参照 データ参照 発注業務 Before After
16.
しかしその壁も高い・・・ 店舗数増加への考慮 ピーク時の処理多重度 限られたバッチウィンドウ膨大なレコード件数
18.
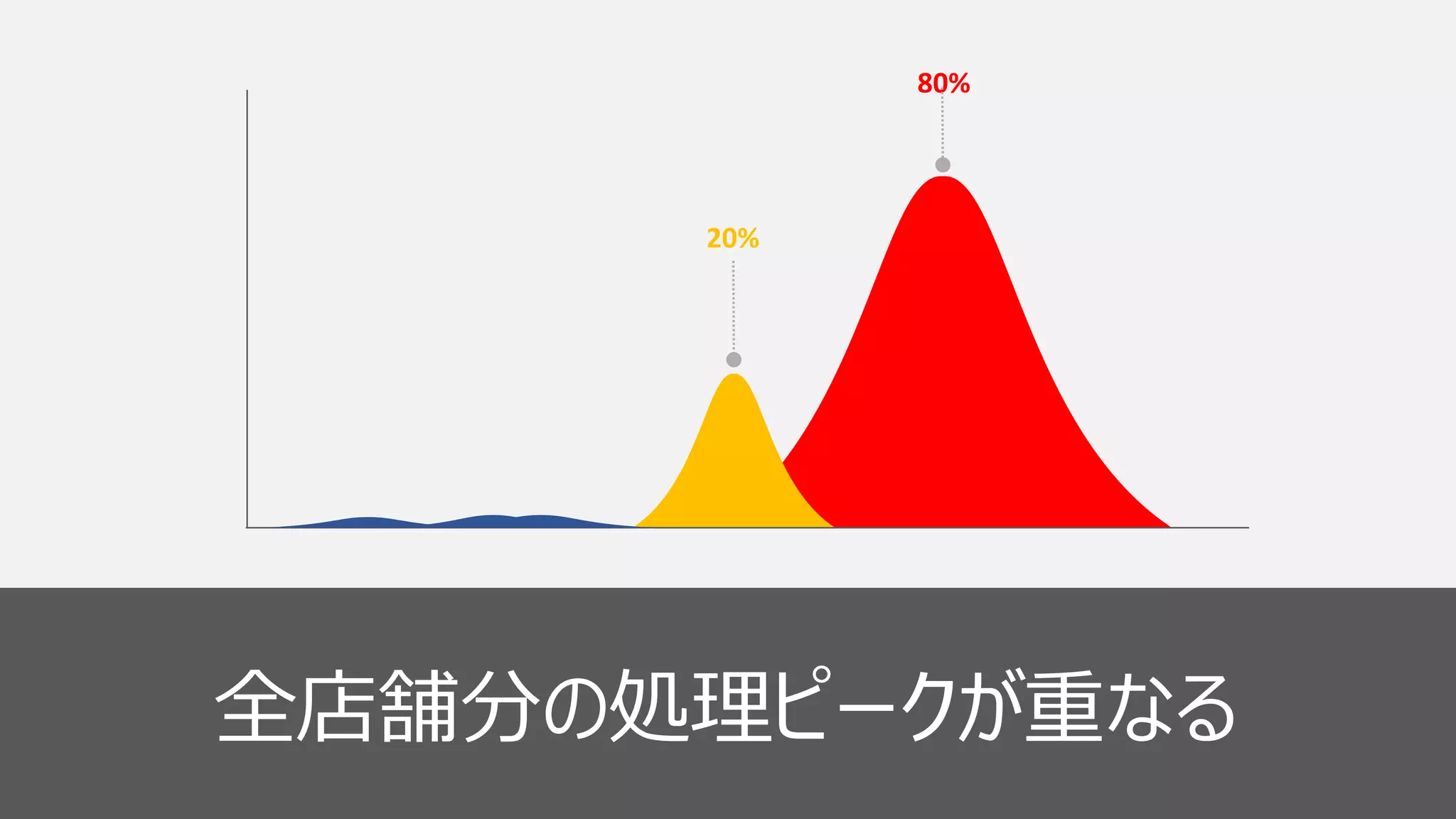
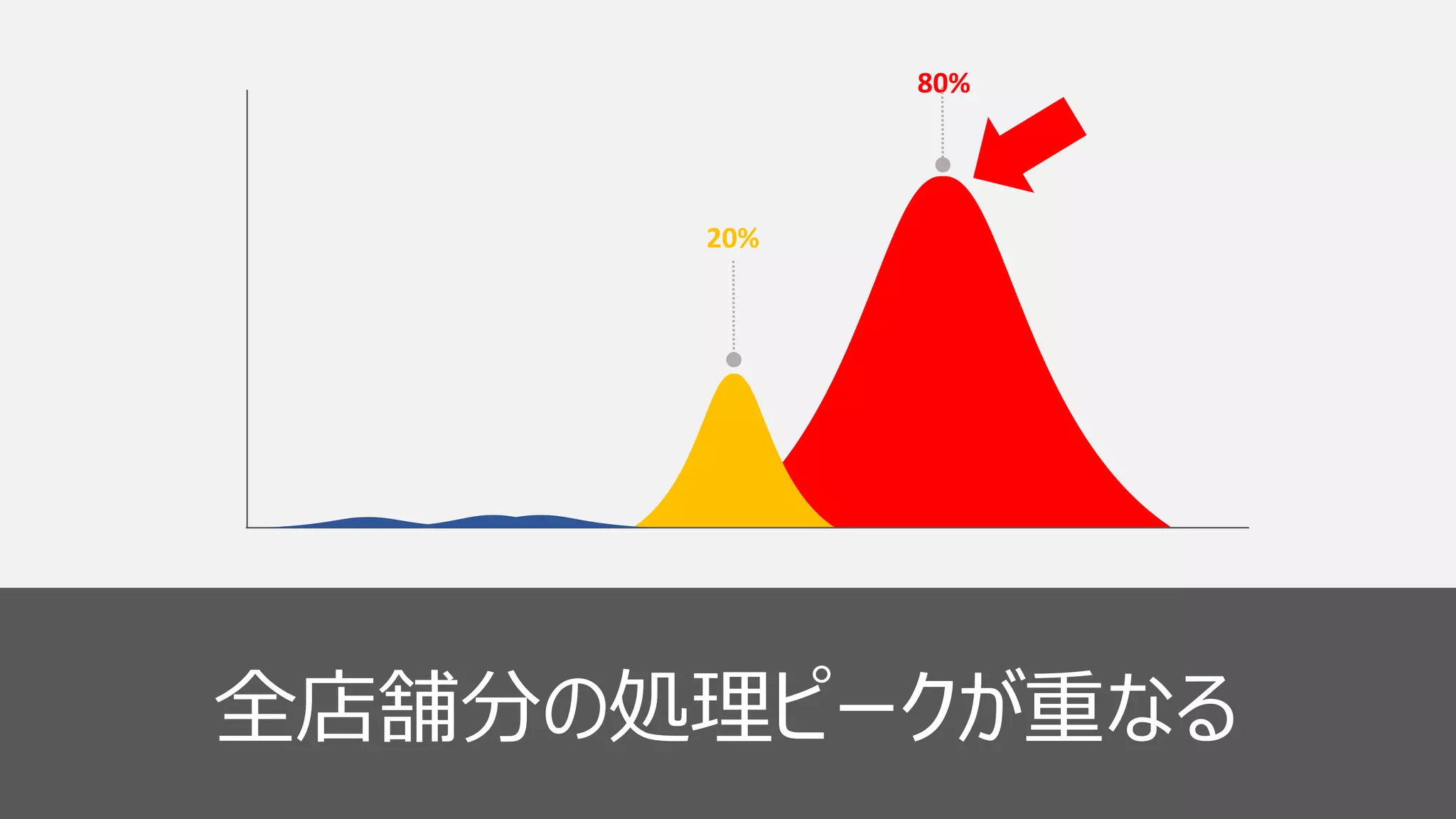
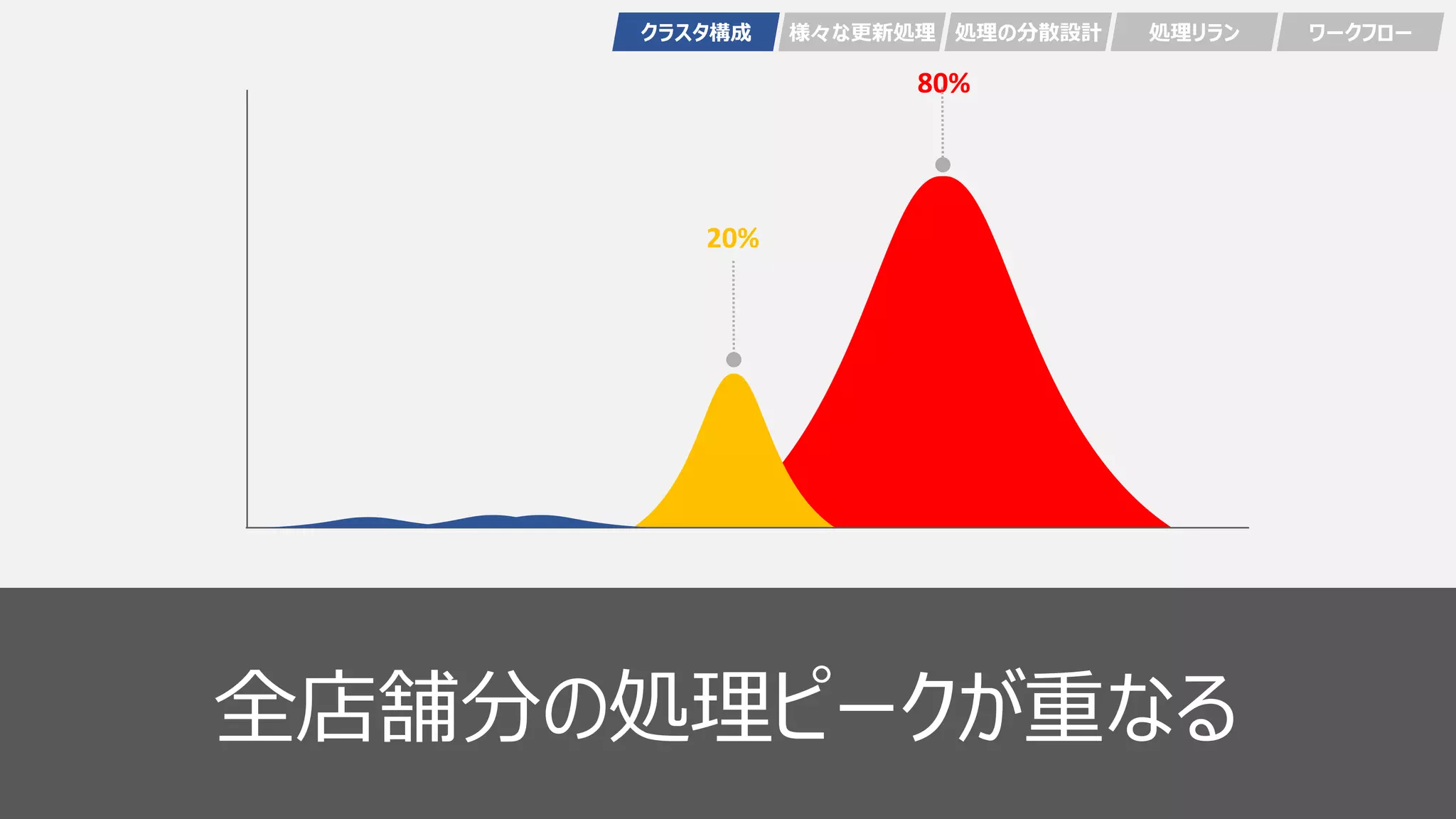
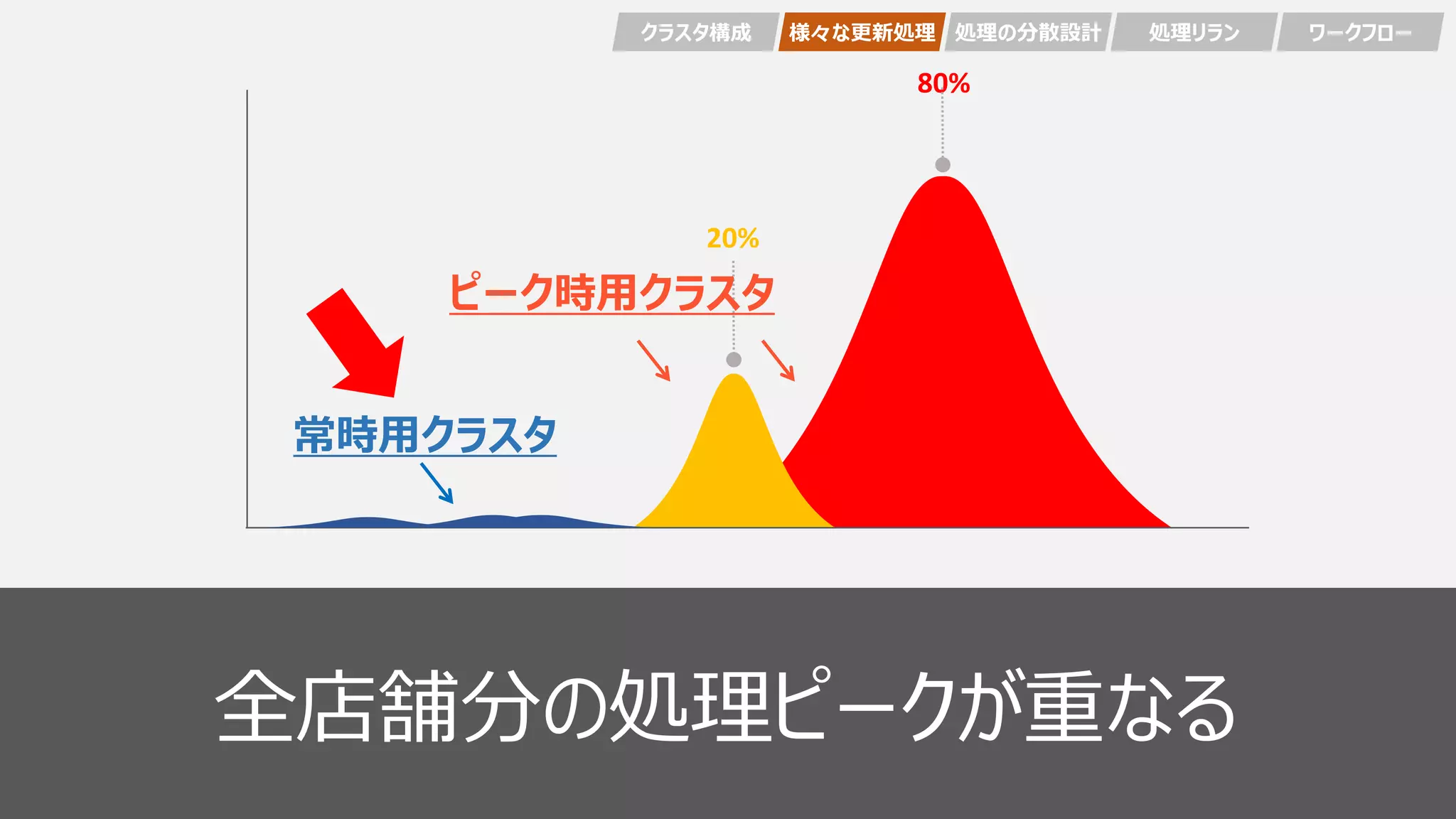
18 20% 80% 全店舗分の処理ピークが重なる
19.
19 発注商品マスタ ~10億レコード PLUマスタ ~7億レコード 商品マスタ ~5億 約70マスタテーブル(数十億レコード)
20.
~1.5時間 店舗へのデータ公開バッチ処理開始 約4時間 リラン
23.
Distributed Architecture?
24.
Get Really Excited @
Midnight
26.
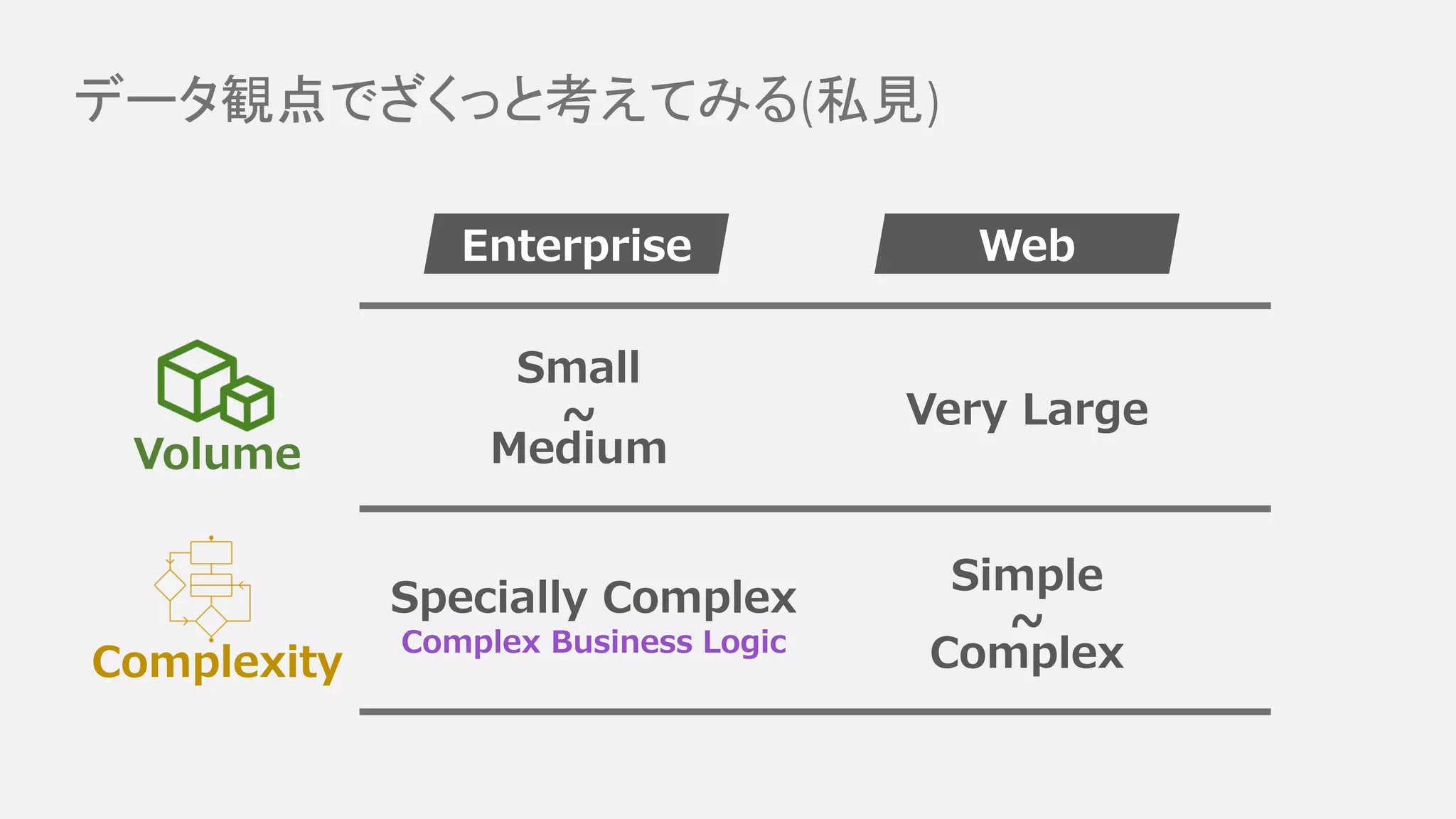
Volume Complexity Small Medium ~ Specially Complex Simple Complex ~ Enterprise Web Complex
Business Logic データ観点でざくっと考えてみる(私見) Very Large
27.
Contains Business Logic… Much Various
28.
データ観点でざくっと考えてみる(私見) Volume Complexity Very Large Specially Complex Simple Complex ~Complex
Business Logic Large Web
29.
機能のセンター集約 店舗DB 発注業務 データ参照 加工処理 加工処理取込処理 取込処理 発注 端末 発注 端末 発注 端末 発注 端末 発注 端末 発注 端末 発注 端末 API API
API API API API API 全店舗分の発注業務に利用する マスタデータをバッチ処理(日次)で作成 全業務マスタDBから店舗毎に必要な マスタデータの更新差分をファイルで連携 これまで店舗毎に配信されていた 全店舗分の更新差分ファイルを連携 受信用DB 公開用DB 1. 全業務マスタDBから各店舗へ更新差分ファイルを配信 2. 店舗毎にDBへ差分反映後、発注利用マスタデータを作成 3. 作成されたマスタデータは発注業務時に発注端末から参照 1. 全業務マスタDBから全店舗分の更新差分ファイルを配信 2. 受信用DBへ差分反映後、全店舗分の発注利用マスタデータを作成 3. 作成されたマスタデータはREST APIで公開し、発注端末より参照 データ参照 発注業務 Before After
31.
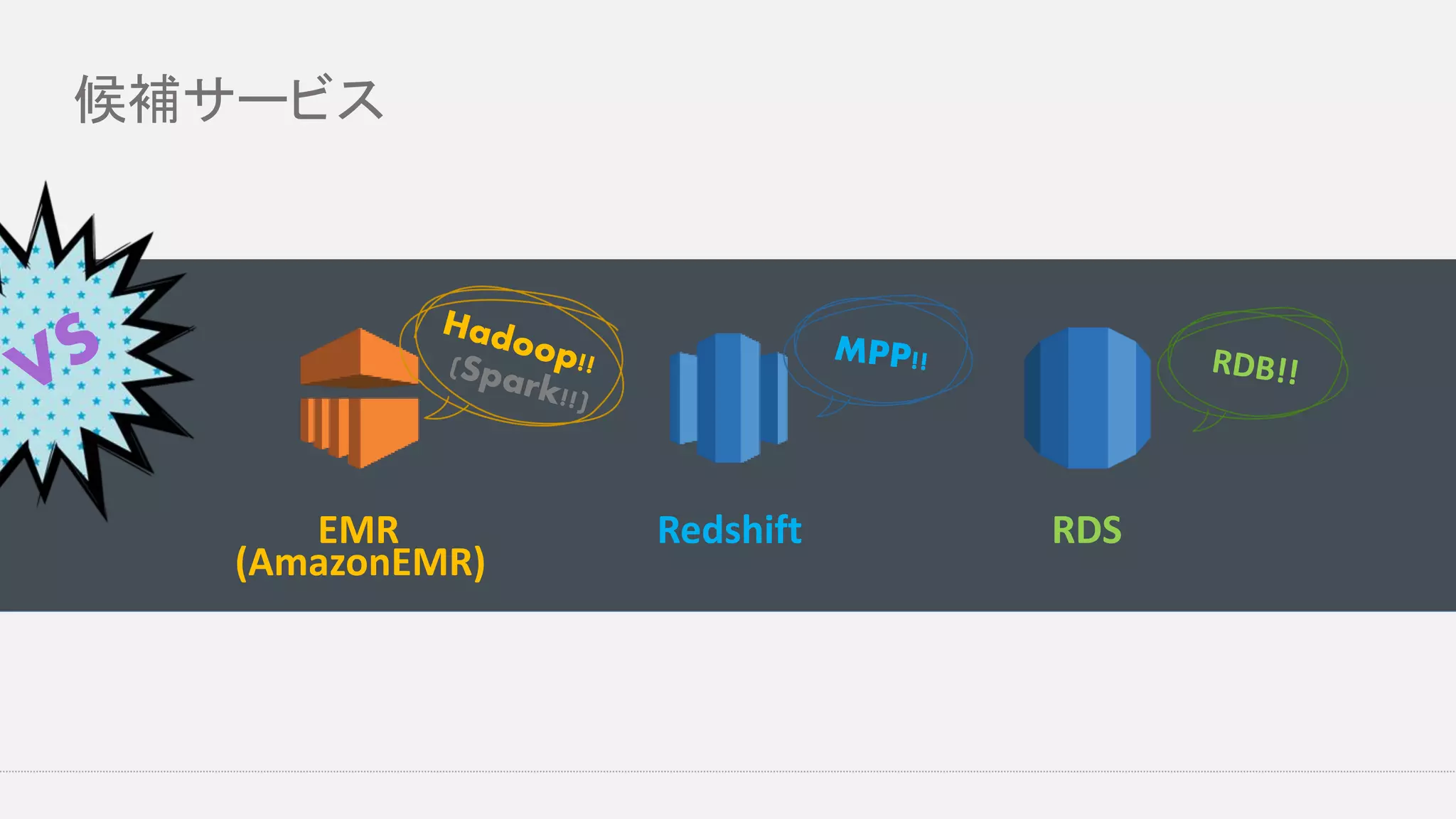
候補サービス EMR Redshift RDS (AmazonEMR)
32.
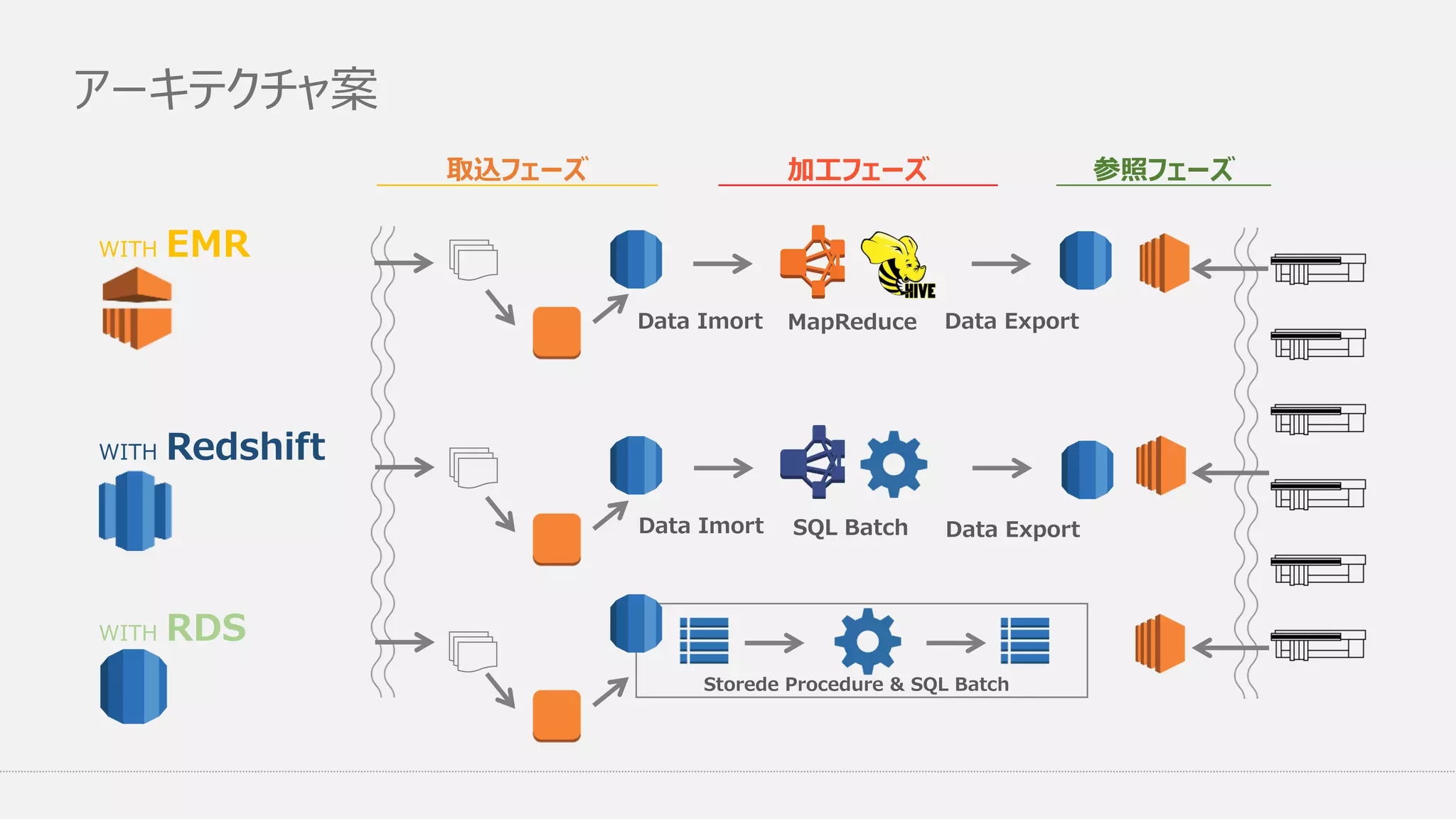
アーキテクチャ案 WITH EMR WITH Redshift WITH
RDS 取込フェーズ 加工フェーズ 参照フェーズ Data Imort Data Export SQL Batch MapReduce Storede Procedure & SQL Batch Data Imort Data Export
33.
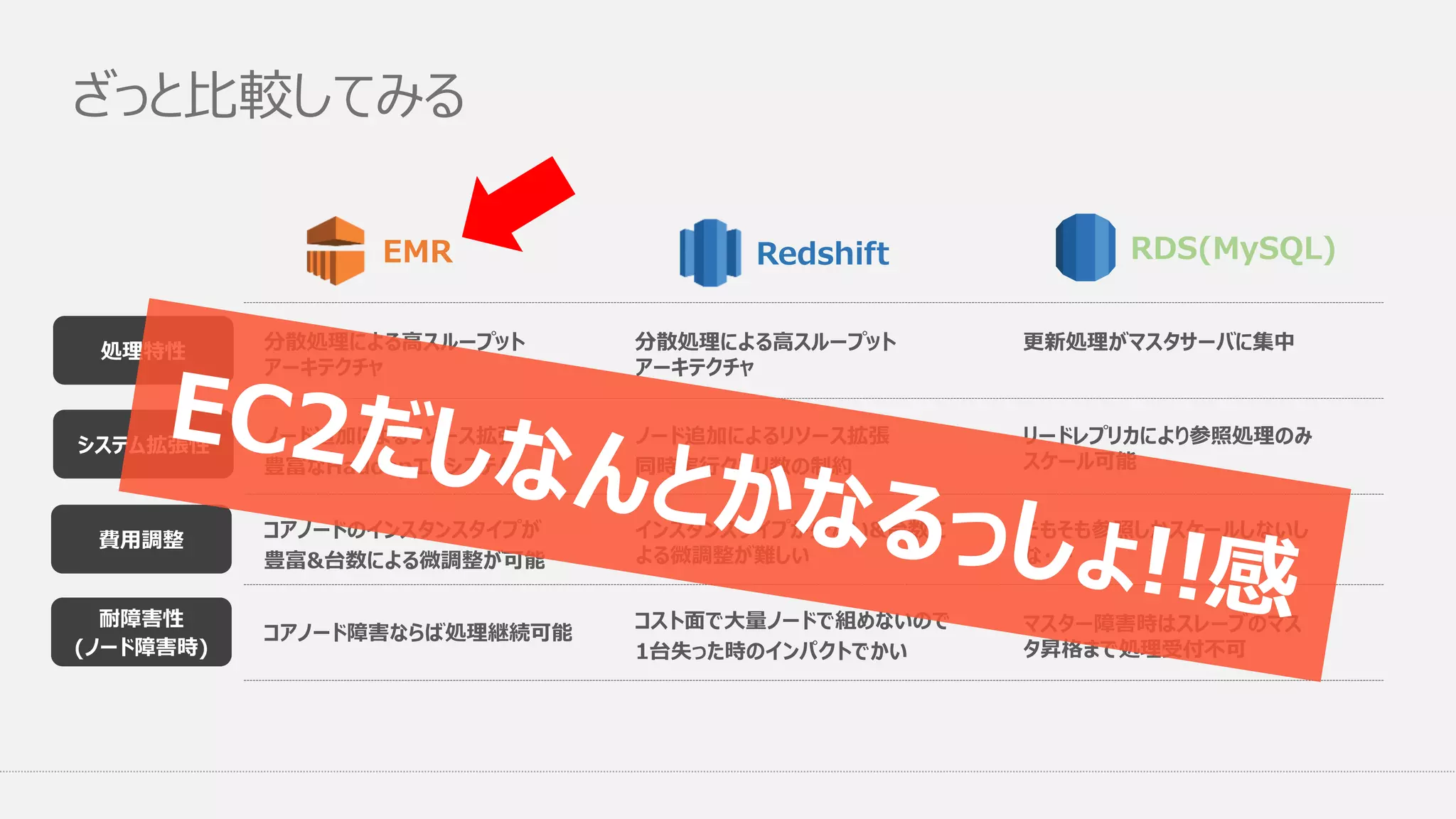
ざっと比較してみる EMR 分散処理による高スループット アーキテクチャ Redshift RDS(MySQL) ノード追加によるリソース拡張 豊富なHadoopエコシステム システム拡張性 耐障害性 (ノード障害時) 処理特性 費用調整 コアノード障害ならば処理継続可能 分散処理による高スループット アーキテクチャ ノード追加によるリソース拡張 同時実行クエリ数の制約 コスト面で大量ノードで組めないので 1台失った時のインパクトでかい 更新処理がマスタサーバに集中 リードレプリカにより参照処理のみ スケール可能 マスター障害時はスレーブのマス タ昇格まで処理受付不可 コアノードのインスタンスタイプが 豊富&台数による微調整が可能 インスタンスタイプが少ない&台数に よる微調整が難しい そもそも参照しかスケールしないし な・・・
34.
ざっと比較してみる EMR 分散処理による高スループット アーキテクチャ Redshift RDS(MySQL) ノード追加によるリソース拡張 豊富なHadoopエコシステム システム拡張性 耐障害性 (ノード障害時) 処理特性 費用調整 コアノード障害ならば処理継続可能 分散処理による高スループット アーキテクチャ ノード追加によるリソース拡張 同時実行クエリ数の制約 更新処理がマスタサーバに集中 リードレプリカにより参照処理のみ スケール可能 マスター障害時はスレーブのマス タ昇格まで処理受付不可 コアノードのインスタンスタイプが 豊富&台数による微調整が可能 インスタンスタイプが少ない&台数に よる微調整が難しい そもそも参照しかスケールしないし な・・・ コスト面で大量ノードで組めないので 1台失った時のインパクトでかい
35.
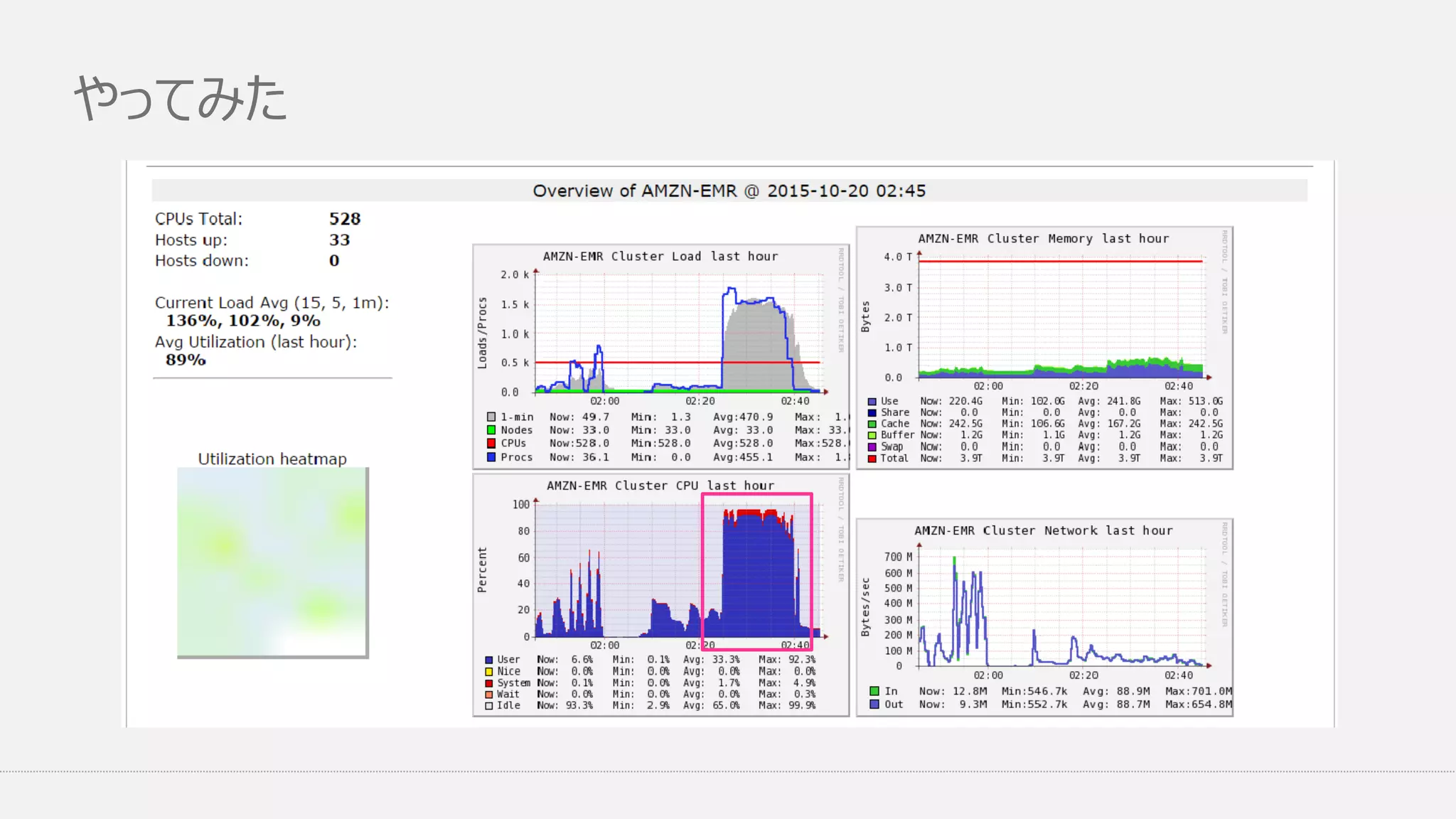
やってみた
36.
36 20% 80% 全店舗分の処理ピークが重なる
37.
37 発注商品マスタ ~10億レコード PLUマスタ ~7億レコード 商品マスタ ~5億 約70マスタテーブル(数十億レコード)
38.
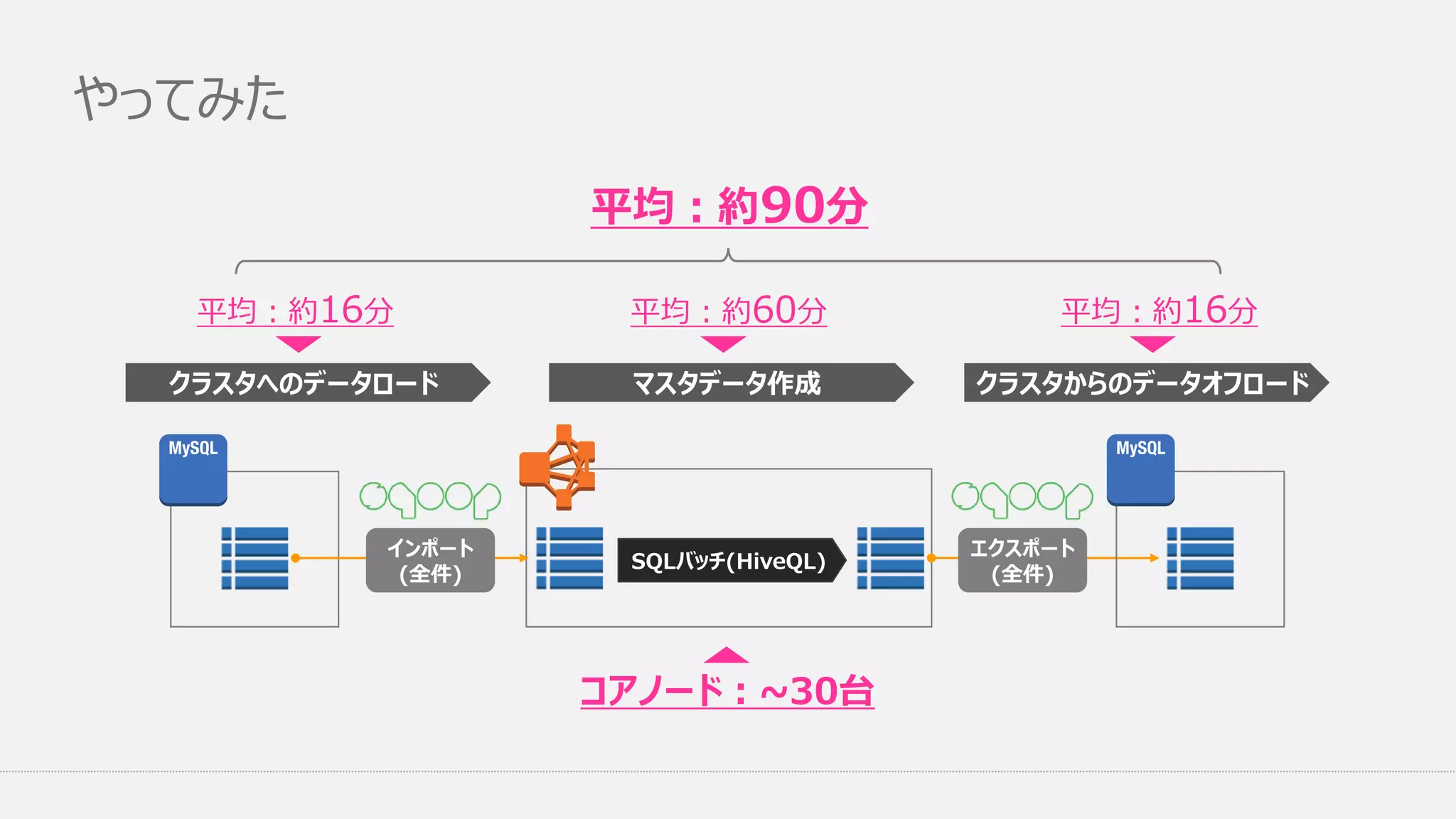
やってみた クラスタへのデータロード マスタデータ作成 インポート (全件) SQLバッチ(HiveQL) クラスタからのデータオフロード 平均:約60分 平均:約16分平均:約16分 平均:約90分 コアノード:~30台 エクスポート (全件)
39.
やってみた
40.
Architecture Overview
41.
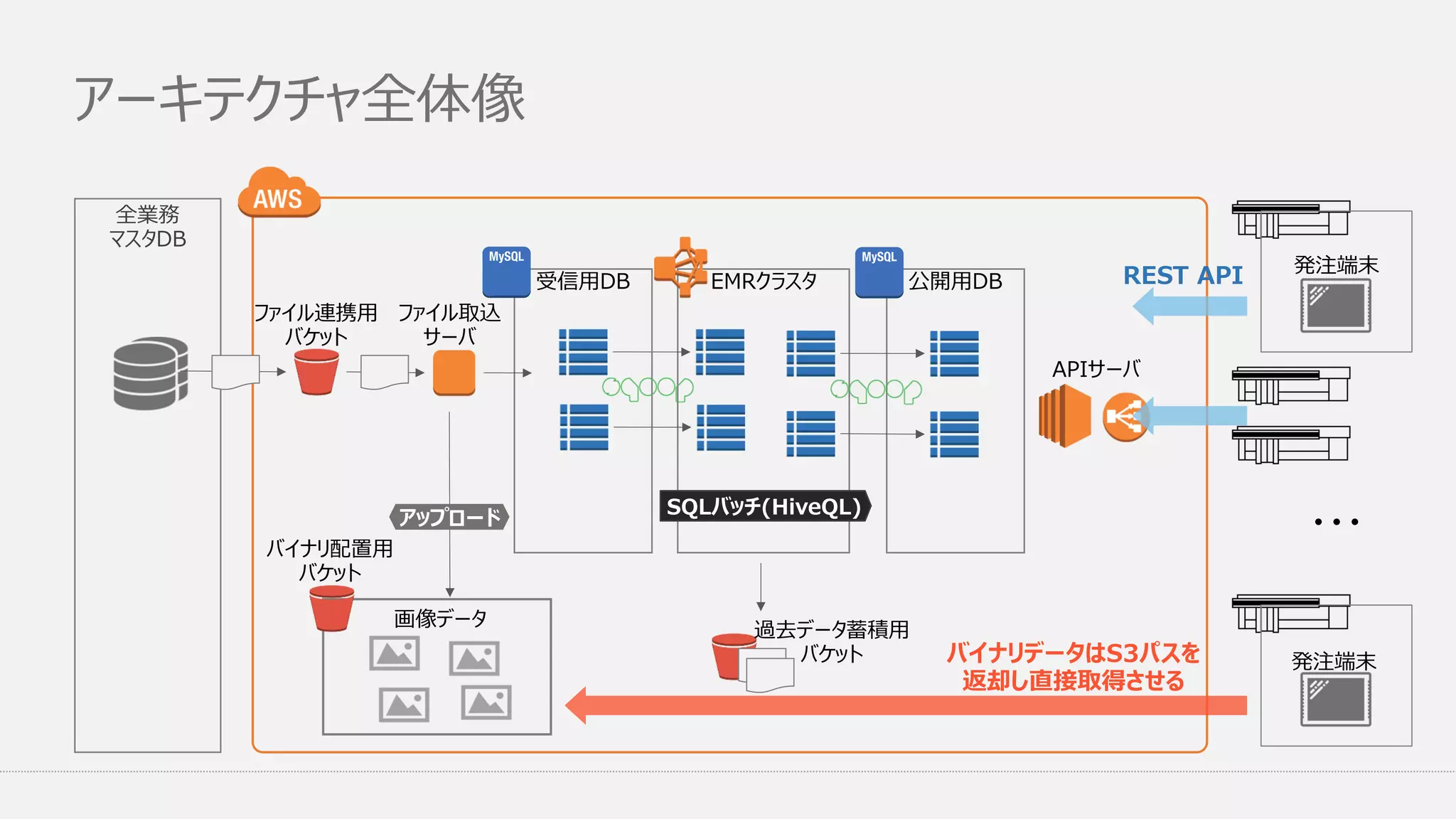
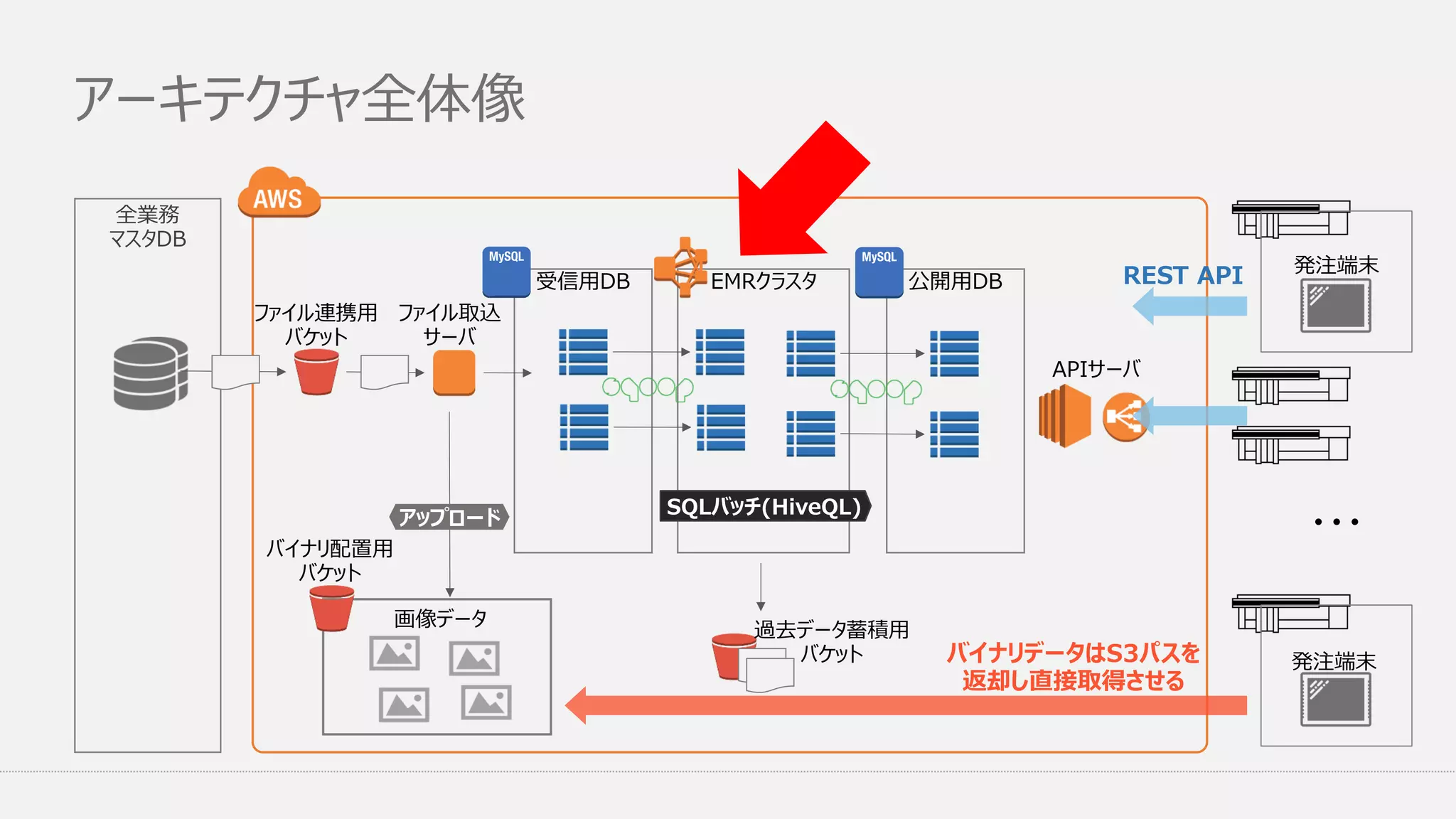
アーキテクチャ全体像 全業務 マスタDB EMRクラスタ受信用DB ファイル連携用 バケット ファイル取込 サーバ SQLバッチ(HiveQL) 公開用DB APIサーバ 過去データ蓄積用 バケット アップロード 画像データ REST API ・・・ バイナリ配置用 バケット バイナリデータはS3パスを 返却し直接取得させる 発注端末 発注端末
42.
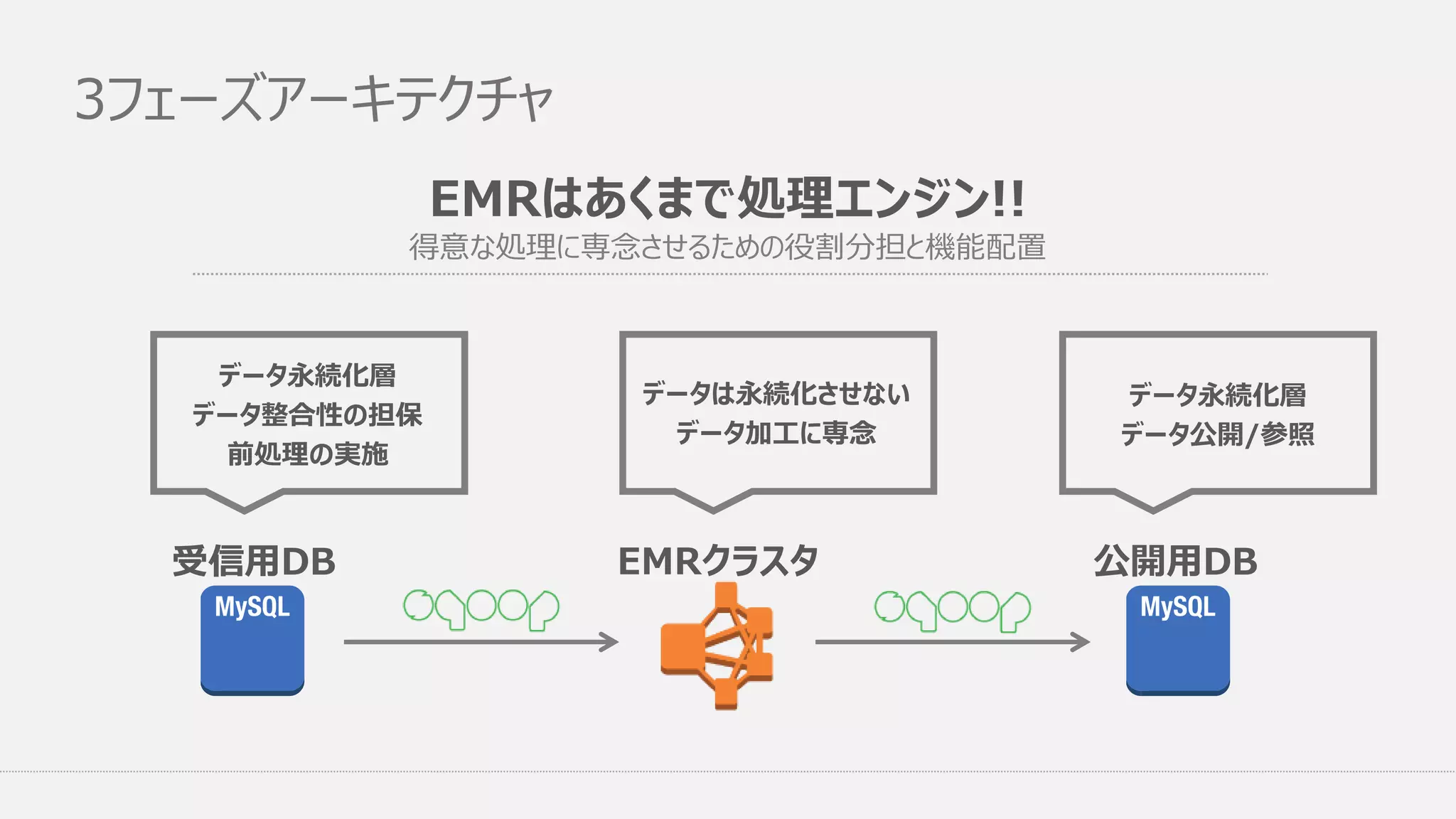
3フェーズアーキテクチャ EMRはあくまで処理エンジン!! 得意な処理に専念させるための役割分担と機能配置 データ永続化層 データ整合性の担保 前処理の実施 データは永続化させない データ加工に専念 データ永続化層 データ公開/参照 受信用DB 公開用DBEMRクラスタ
43.
Processing
44.
アーキテクチャ全体像 全業務 マスタDB EMRクラスタ受信用DB ファイル連携用 バケット ファイル取込 サーバ SQLバッチ(HiveQL) 公開用DB APIサーバ 過去データ蓄積用 バケット アップロード 画像データ REST API ・・・ バイナリ配置用 バケット バイナリデータはS3パスを 返却し直接取得させる 発注端末 発注端末
45.
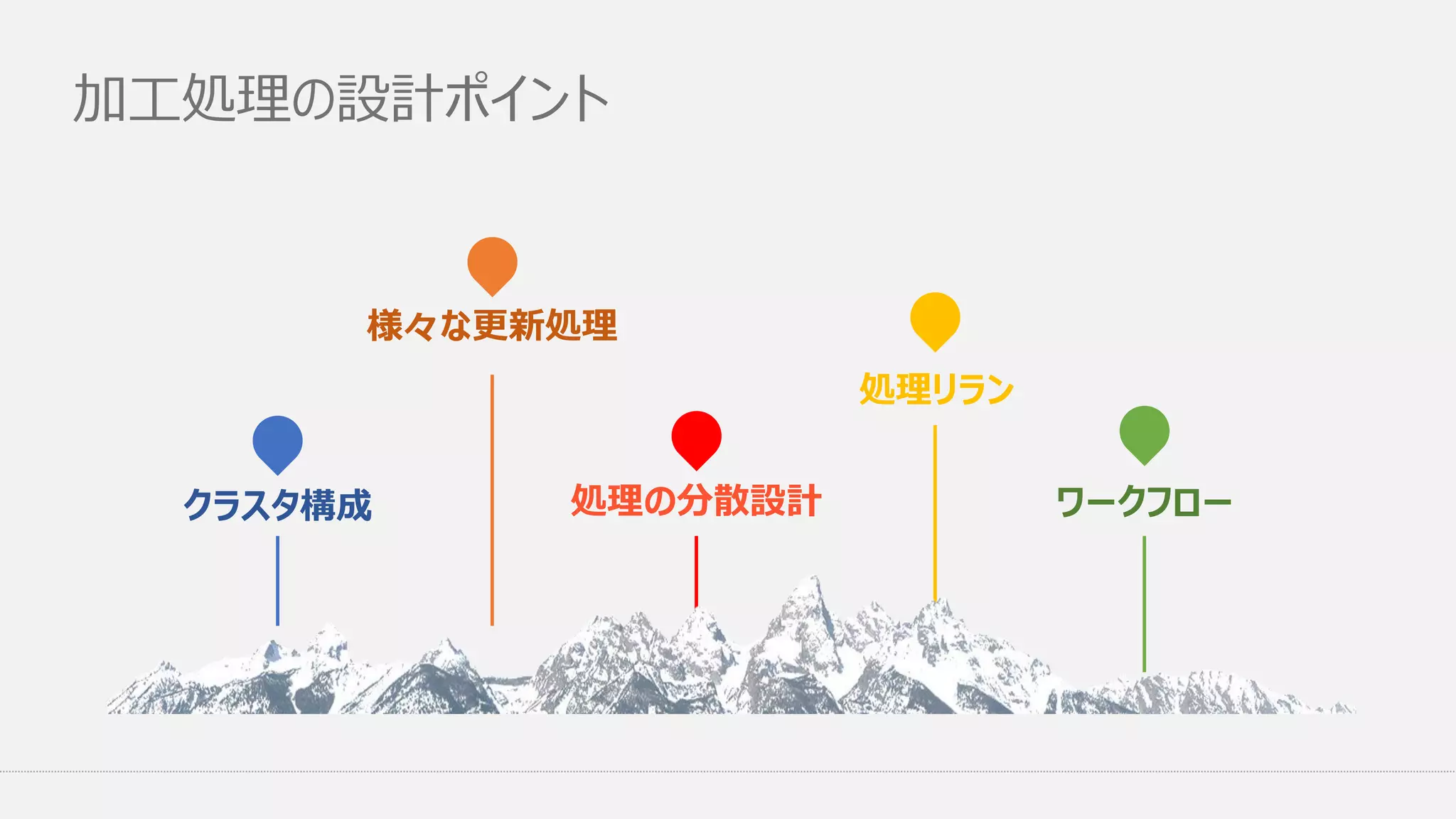
加工処理の設計ポイント クラスタ構成 様々な更新処理 処理の分散設計 処理リラン ワークフロー
46.
46 20% 80% 全店舗分の処理ピークが重なる クラスタ構成 様々な更新処理 処理の分散設計
処理リラン ワークフロー
47.
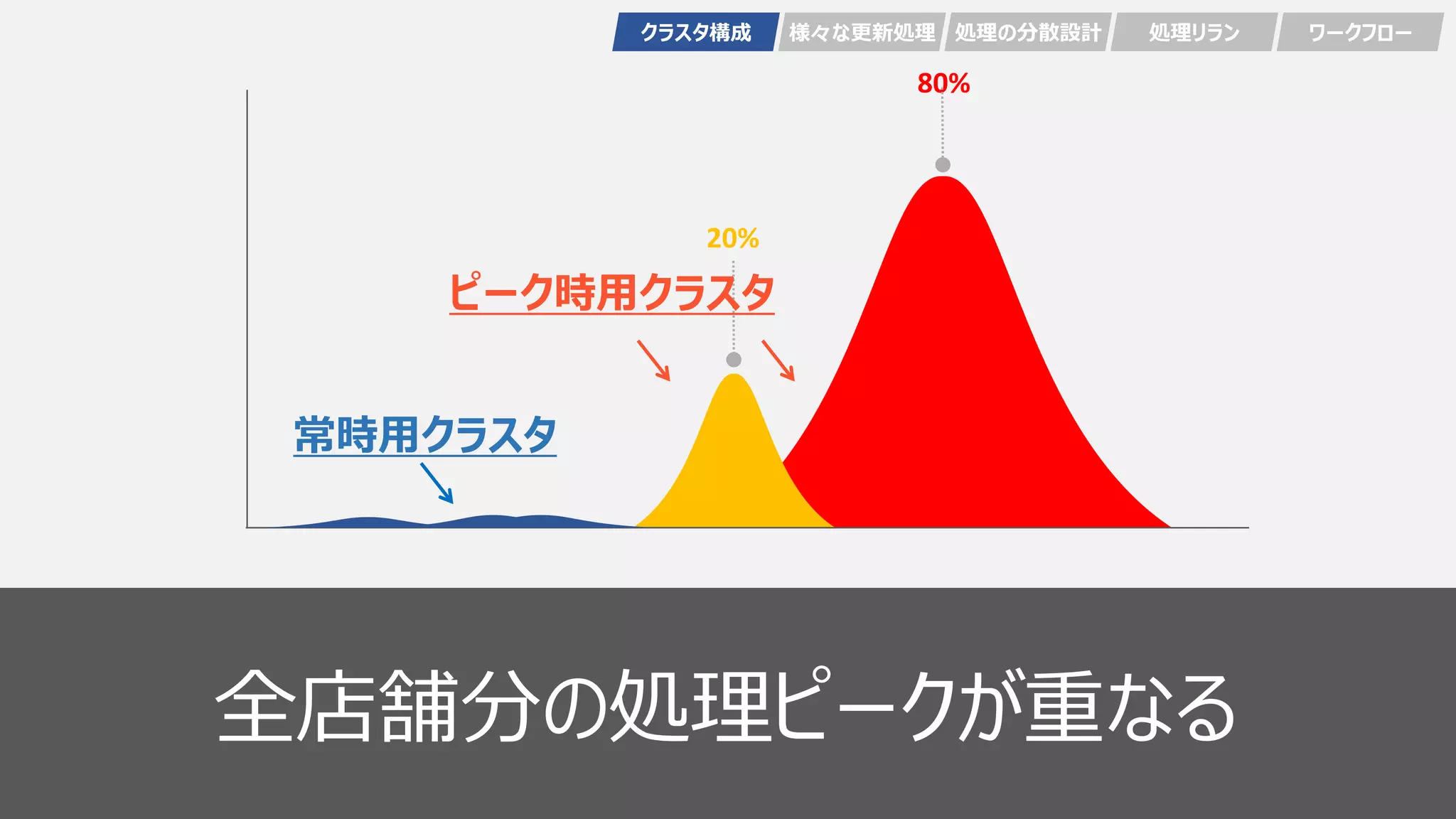
47 20% 80% 全店舗分の処理ピークが重なる ピーク時用クラスタ 常時用クラスタ クラスタ構成 様々な更新処理 処理の分散設計
処理リラン ワークフロー
48.
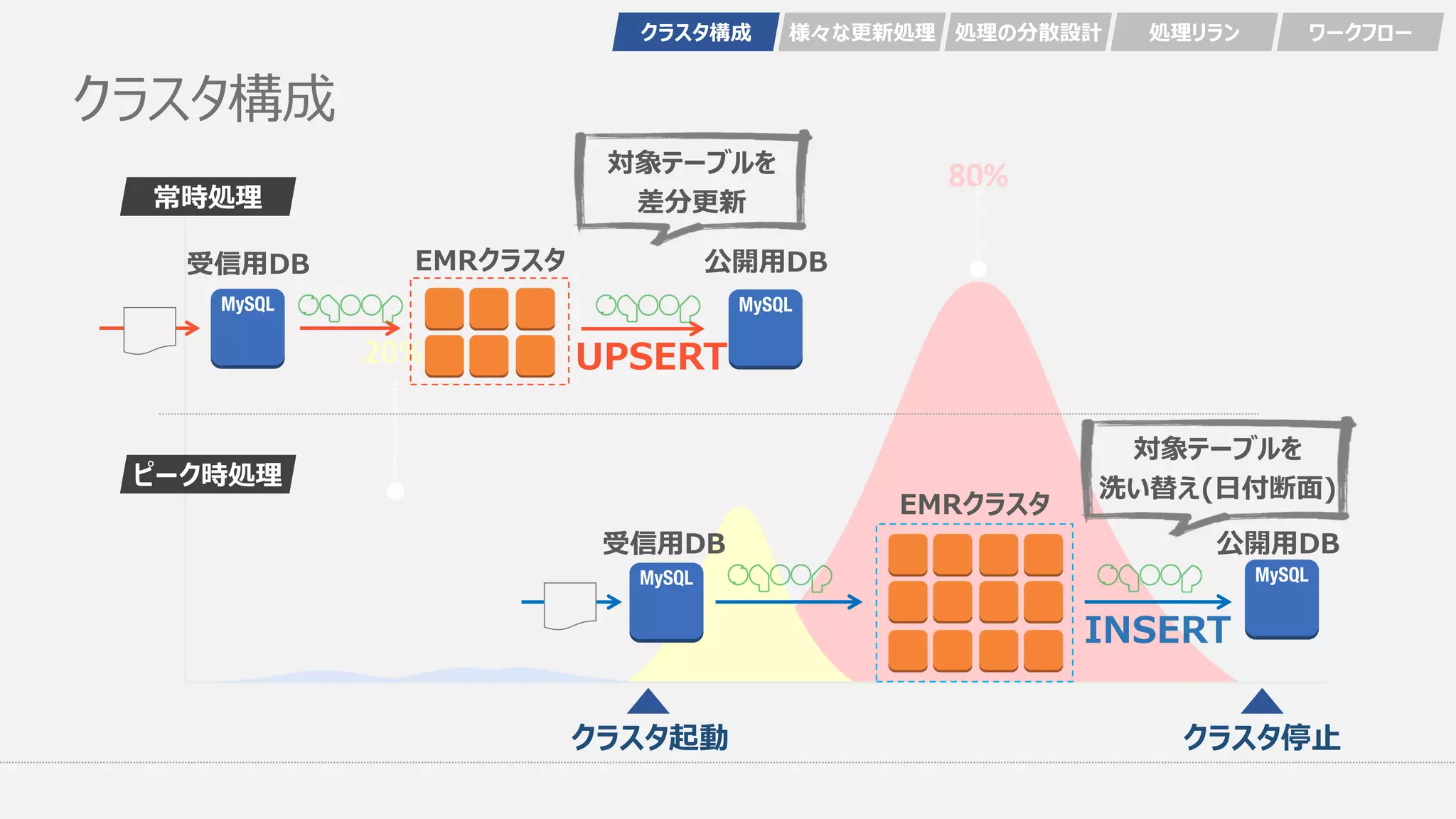
クラスタ構成 常時処理 ピーク時処理 UPSERT INSERT クラスタ起動 クラスタ停止 対象テーブルを 差分更新 対象テーブルを 洗い替え(日付断面) クラスタ構成 様々な更新処理
処理の分散設計 処理リラン ワークフロー 受信用DB 公開用DBEMRクラスタ受信用DB 公開用DB EMRクラスタ
49.
49 20% 80% 全店舗分の処理ピークが重なる ピーク時用クラスタ 常時用クラスタ クラスタ構成 様々な更新処理 処理の分散設計
処理リラン ワークフロー
50.
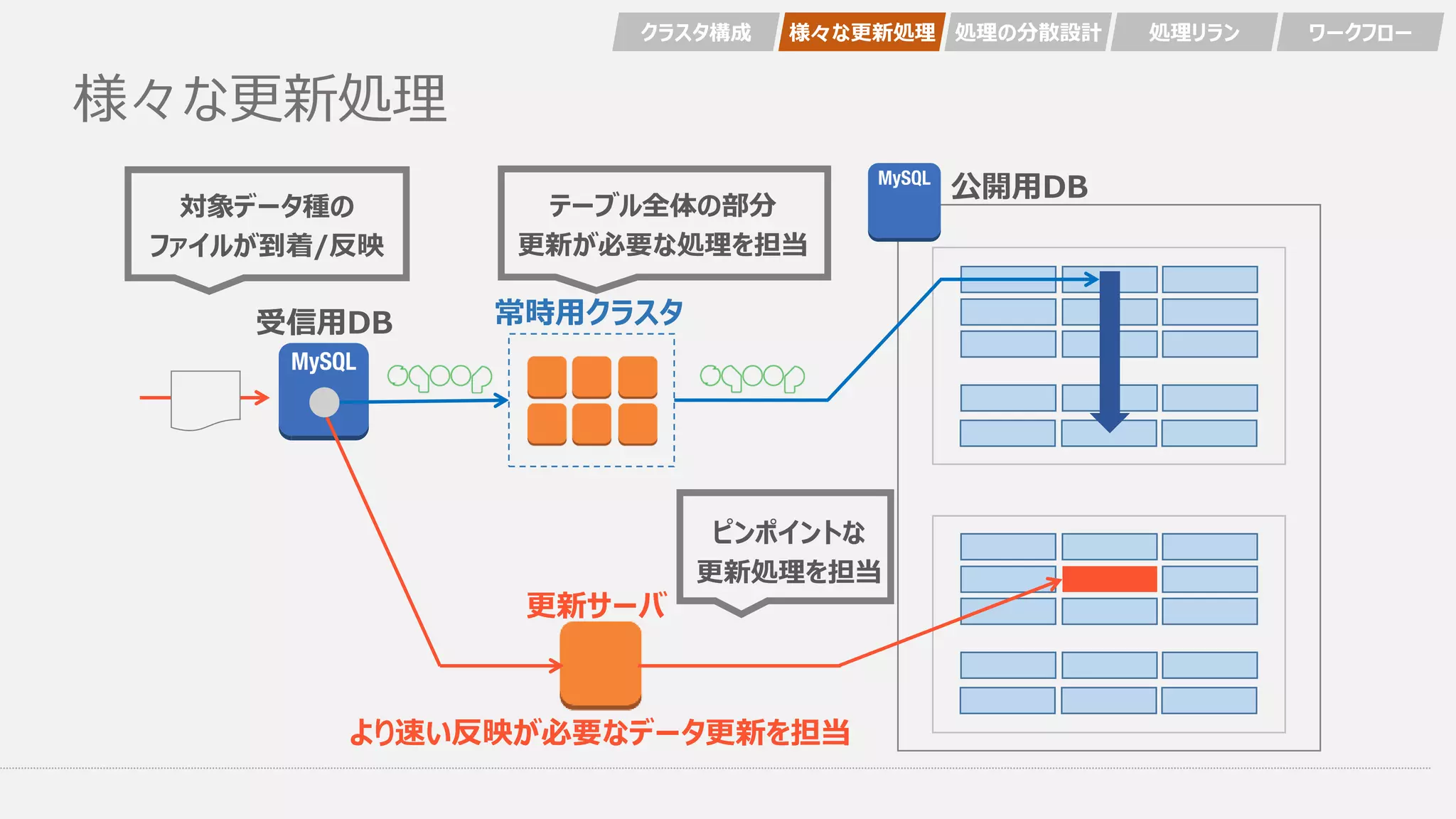
様々な更新処理 更新サーバ 常時用クラスタ テーブル全体の部分 更新が必要な処理を担当 ピンポイントな 更新処理を担当 対象データ種の ファイルが到着/反映 クラスタ構成 様々な更新処理 処理の分散設計
処理リラン ワークフロー 公開用DB 受信用DB より速い反映が必要なデータ更新を担当
51.
処理の分散設計 マスタ作成の処理粒度をどう調整するか どの粒度でマスタ作成処理(HiveQL)を並列に走らせるか 店舗毎に いっぺんにドーン 複数店舗をまとまりにして いっぺんにドーン 全店舗分を いっぺんにドーン ・・・ ・・・ クラスタ構成 様々な更新処理
処理の分散設計 処理リラン ワークフロー
52.
処理の分散設計 店舗毎に いっぺんにドーン 複数店舗をまとまりにして いっぺんにドーン 全店舗分を いっぺんにドーン ・・・ ・・・ リソース不足 リソース不足
スループット抜群 クラスタ構成 様々な更新処理 処理の分散設計 処理リラン ワークフロー マスタ作成の処理粒度をどう調整するか どの粒度でマスタ作成処理(HiveQL)を並列に走らせるか
53.
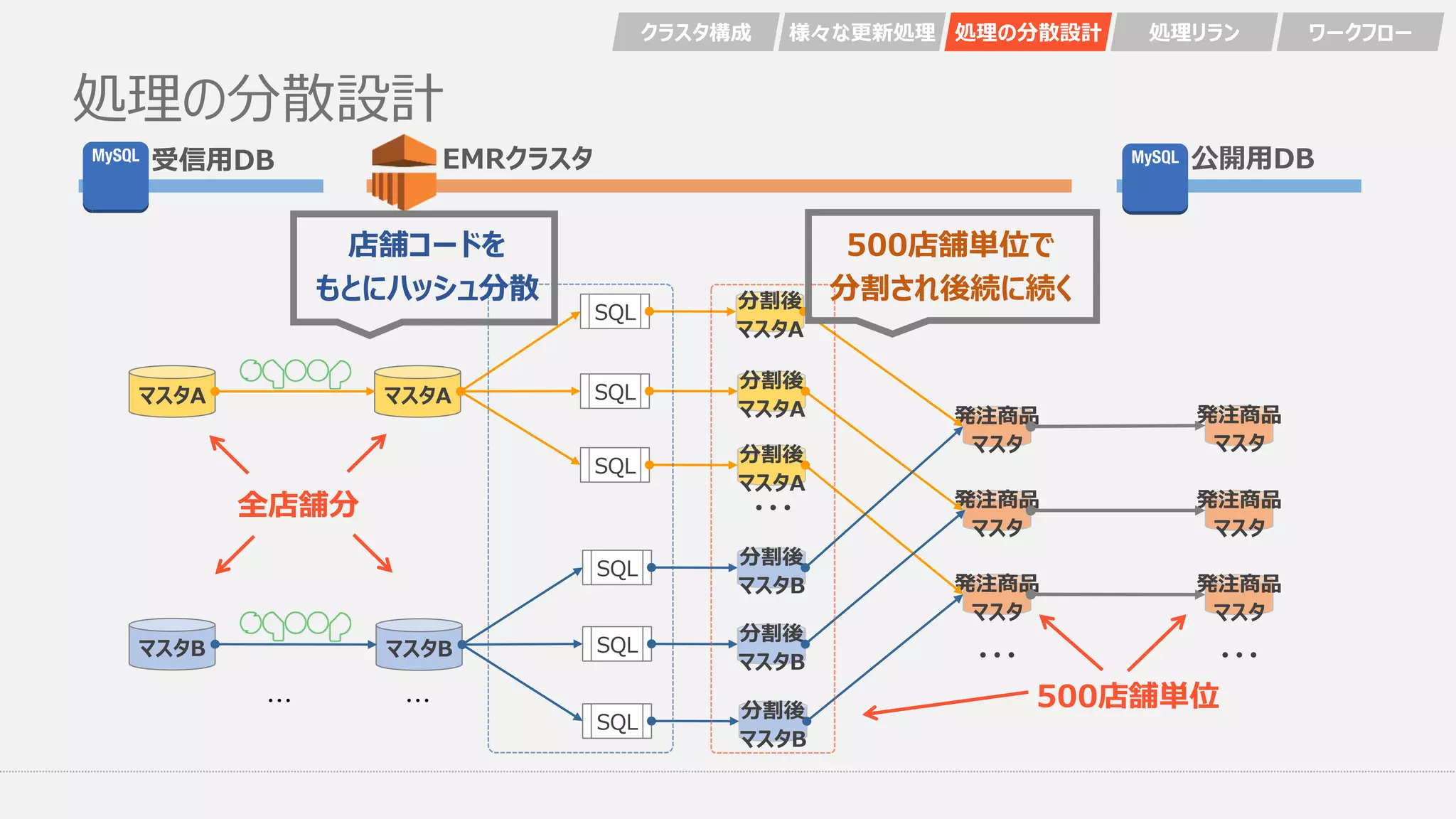
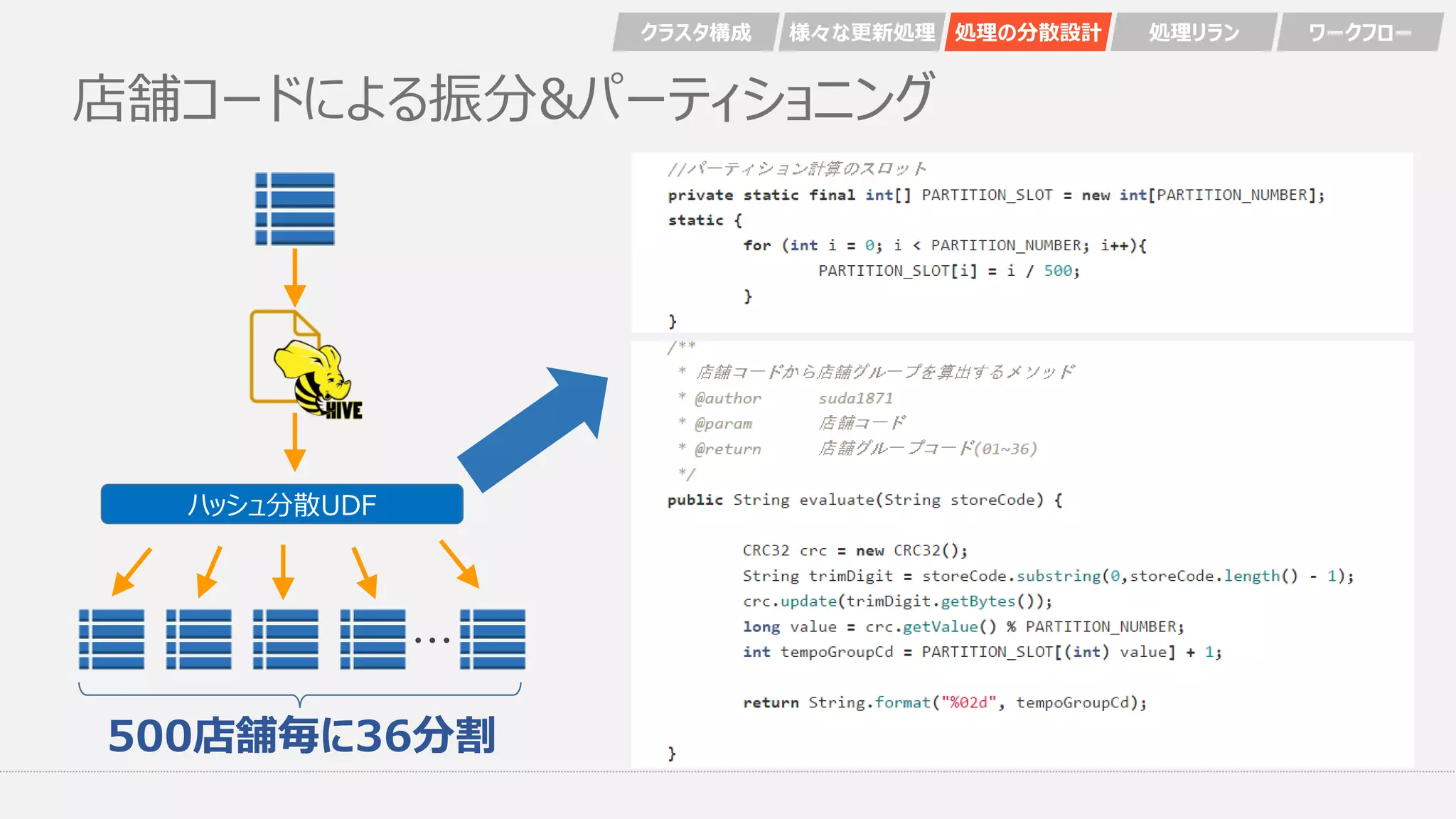
処理の分散設計 マスタA 分割後 マスタA 分割後 マスタA 分割後 マスタA ・・・ マスタB 分割後 マスタB 分割後 マスタB 分割後 マスタB 発注商品 マスタ 発注商品 マスタ 発注商品 マスタ 発注商品 マスタ マスタA マスタB ・・・・・・ SQL SQL SQL SQL SQL SQL 発注商品 マスタ 発注商品 マスタ 店舗コードを もとにハッシュ分散 500店舗単位で 分割され後続に続く クラスタ構成 様々な更新処理 処理の分散設計
処理リラン ワークフロー ・・・ ・・・ 全店舗分 500店舗単位 公開用DBEMRクラスタ受信用DB
54.
店舗コードによる振分&パーティショニング ・・・ 500店舗毎に36分割 ハッシュ分散UDF クラスタ構成 様々な更新処理 処理の分散設計
処理リラン ワークフロー
55.
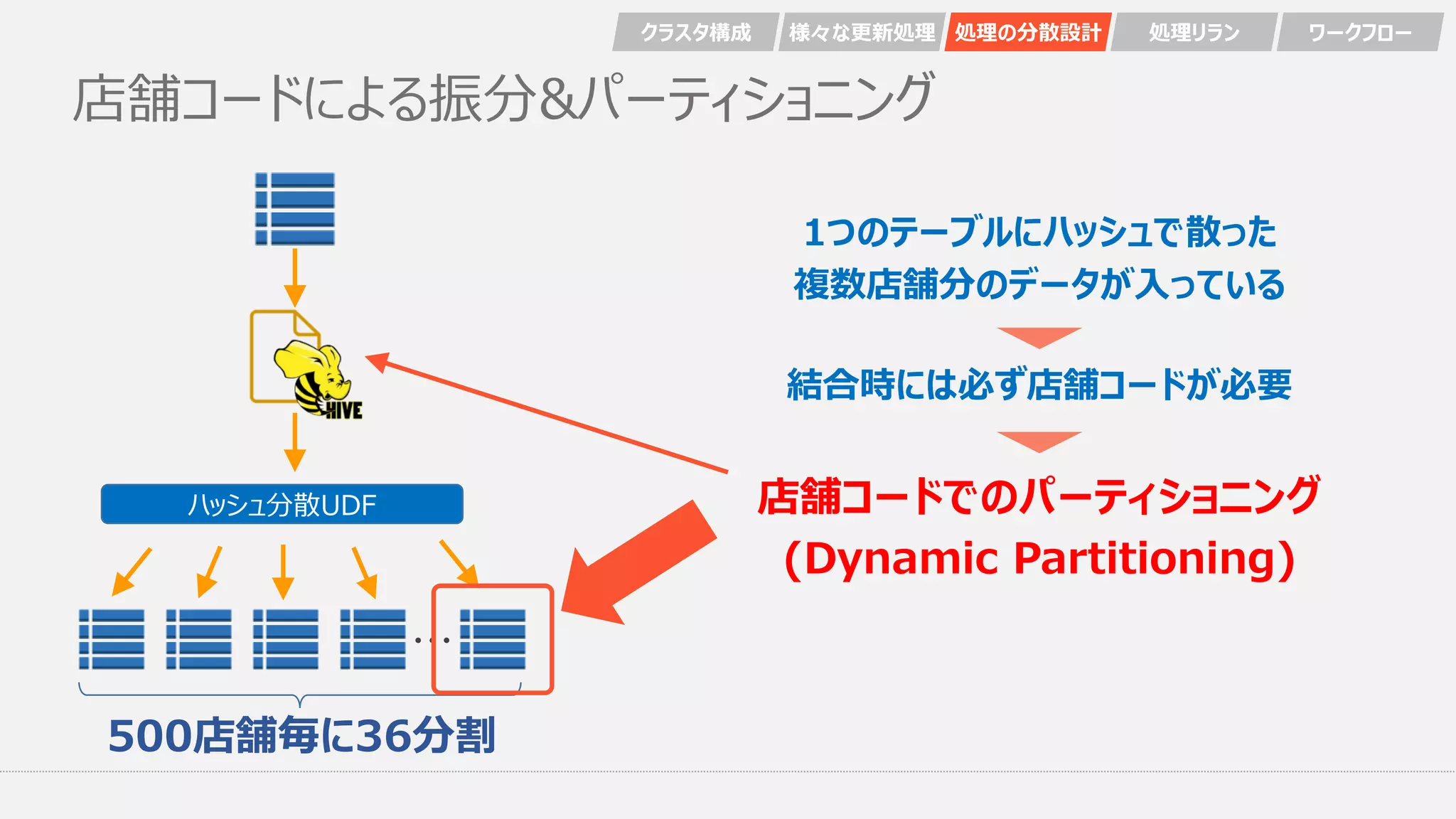
店舗コードによる振分&パーティショニング ・・・ ハッシュ分散UDF 店舗コードでのパーティショニング (Dynamic Partitioning) クラスタ構成
様々な更新処理 処理の分散設計 処理リラン ワークフロー 500店舗毎に36分割 1つのテーブルにハッシュで散った 複数店舗分のデータが入っている 結合時には必ず店舗コードが必要
56.
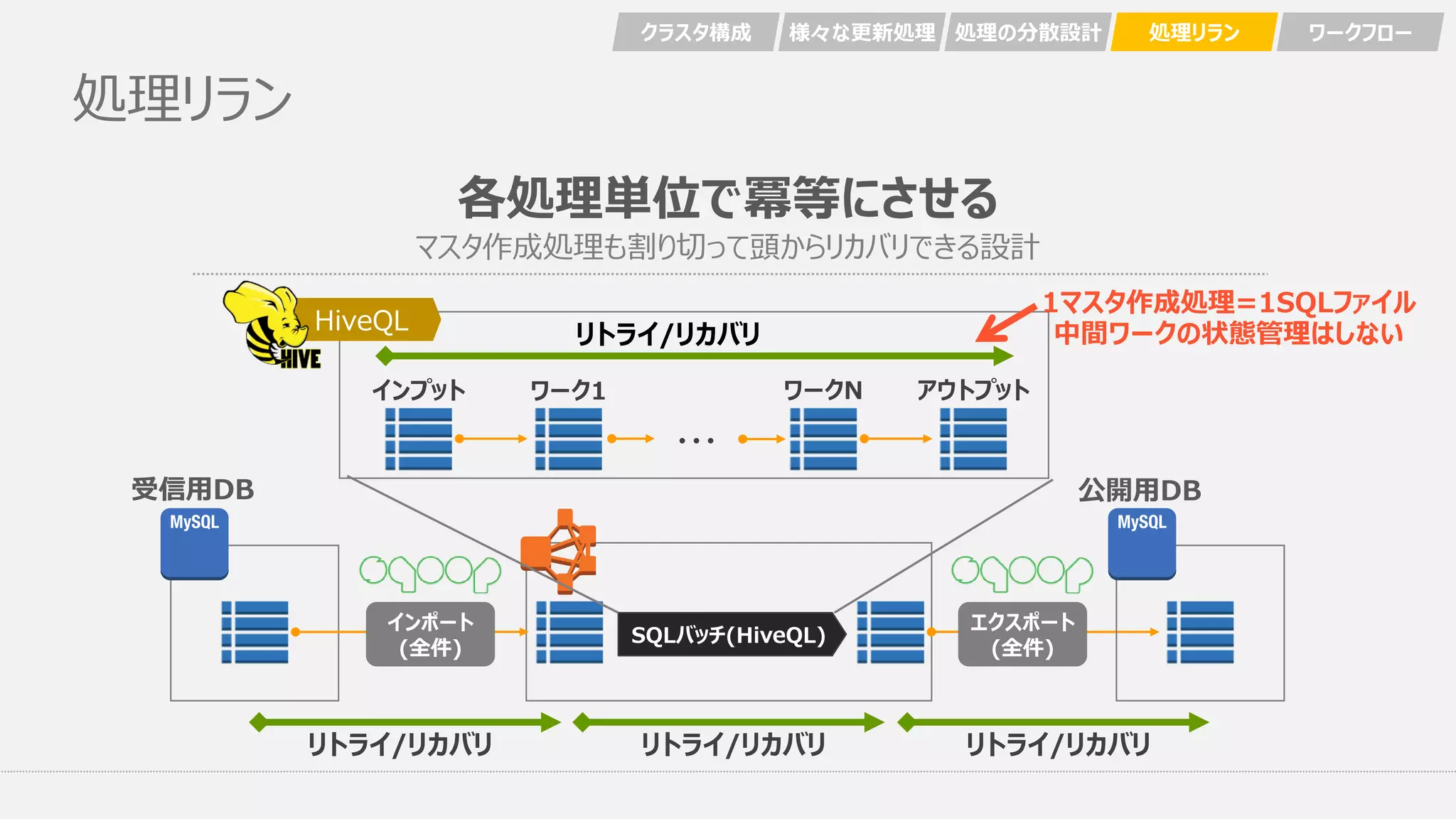
処理リラン インポート (全件) SQLバッチ(HiveQL) エクスポート (全件) リトライ/リカバリ リトライ/リカバリ リトライ/リカバリ ・・・ ワーク1
ワークN アウトプットインプット HiveQL 各処理単位で冪等にさせる マスタ作成処理も割り切って頭からリカバリできる設計 リトライ/リカバリ クラスタ構成 様々な更新処理 処理の分散設計 処理リラン ワークフロー 公開用DB受信用DB 1マスタ作成処理=1SQLファイル 中間ワークの状態管理はしない
57.
ワークフロー 処理命令はSDK経由で実行 EMRのStepではあくまでクラスタのプロビジョニング(Chefで実行)にのみに特化 コア マスター ・・・ 処理実行 スクリプト HiveQL 実行スクリプト HiveQL ワークフローサーバ コア コア コア SDK
hive -f ${HIVEQL_FILE} ¥ --hivevar PG_ID=${PG_ID} ¥ --hivevar VERSION_YMD=${VERSION_YMD} ¥ --hivevar TEMPO_GROUP_CD=${TEMPO_GROUP_CD} ¥ >> ${LOG_FILE} 2>1 クラスタ構成 様々な更新処理 処理の分散設計 処理リラン ワークフロー
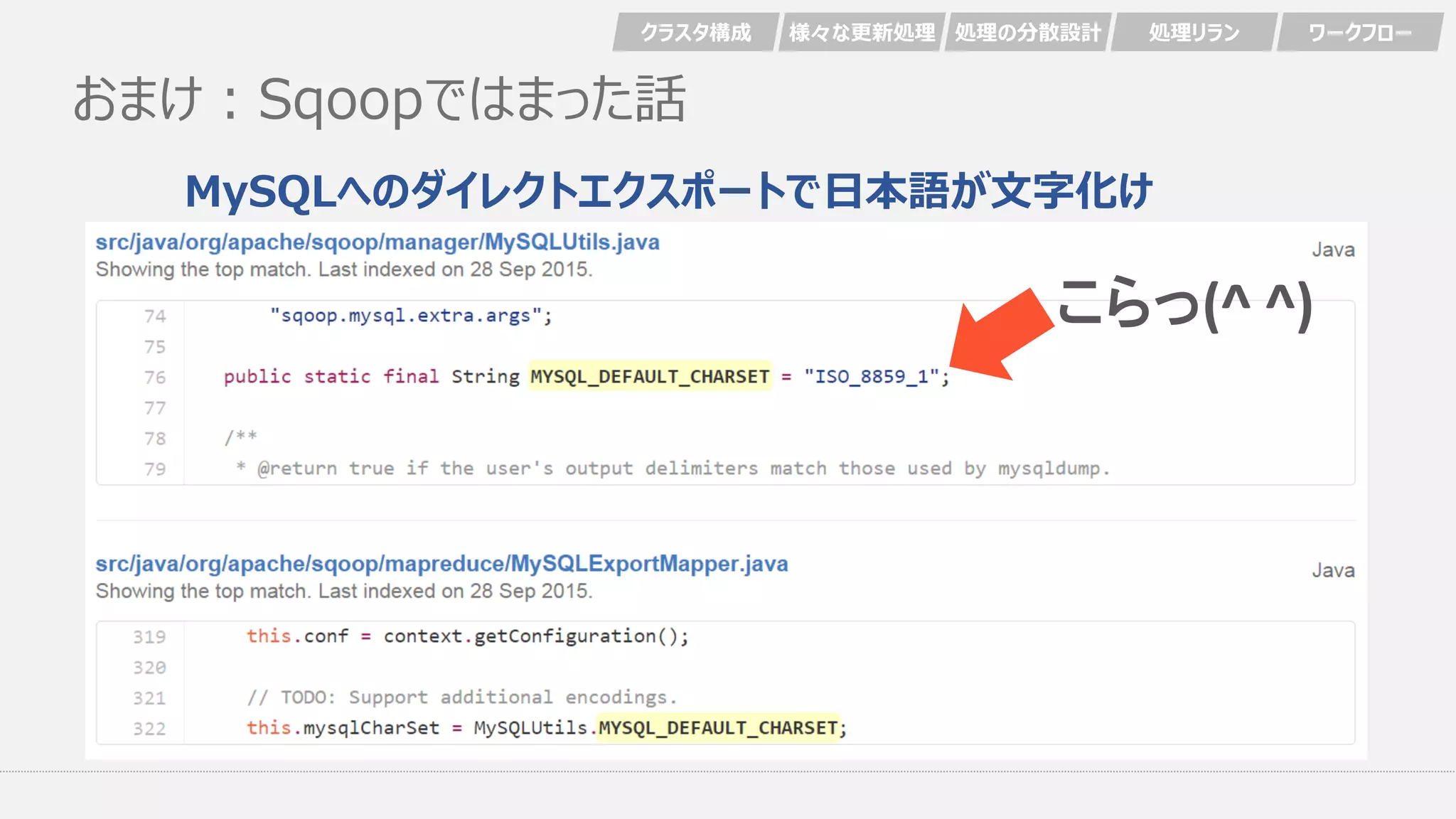
58.
おまけ:Sqoopではまった話 MySQLへのダイレクトエクスポートで日本語が文字化け クラスタ構成 様々な更新処理 処理の分散設計
処理リラン ワークフロー こらっ(^ ^)
59.
Team Development
60.
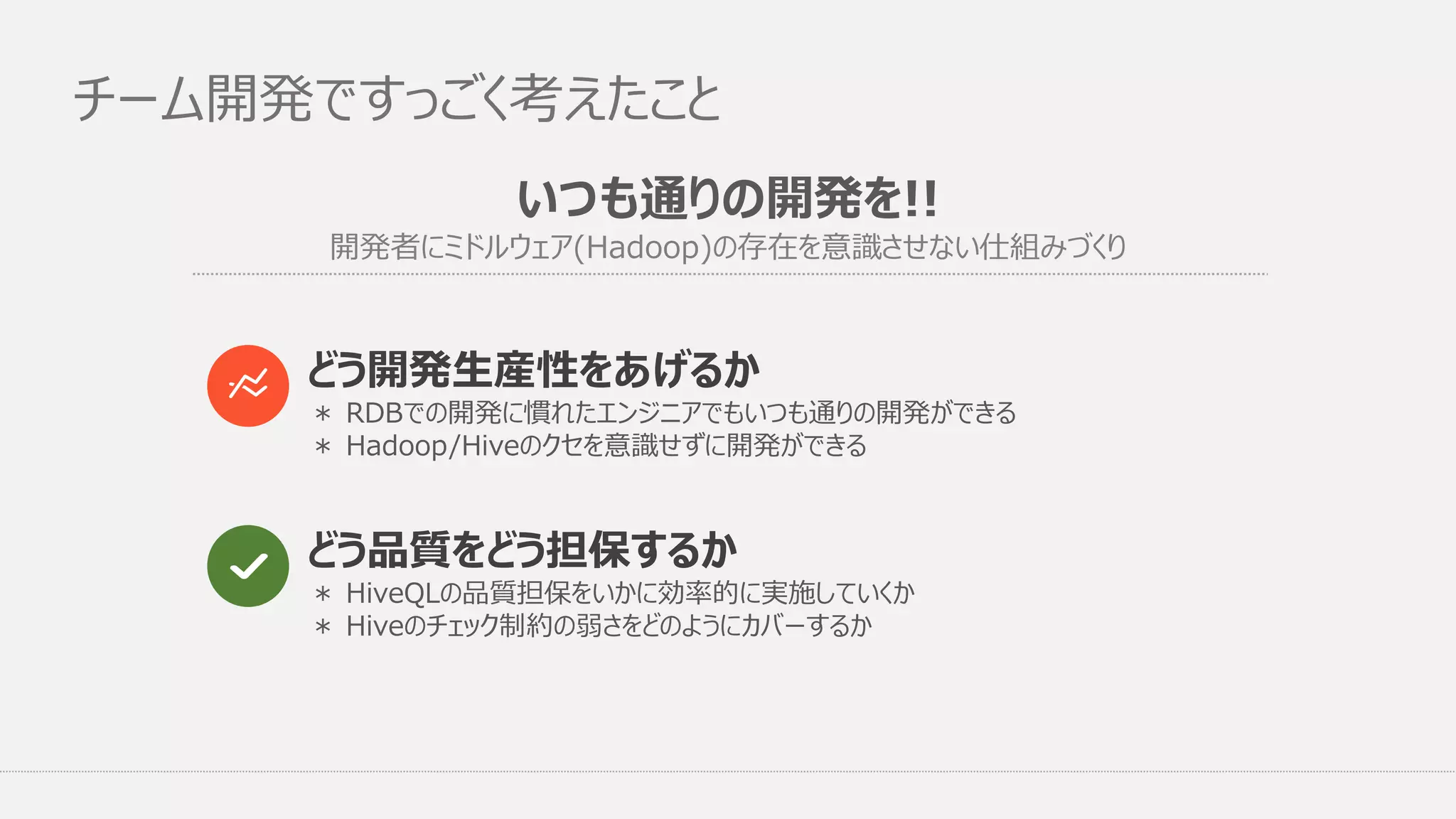
いつも通りの開発を!! 開発者にミドルウェア(Hadoop)の存在を意識させない仕組みづくり チーム開発ですっごく考えたこと どう品質をどう担保するか どう開発生産性をあげるか * RDBでの開発に慣れたエンジニアでもいつも通りの開発ができる * Hadoop/Hiveのクセを意識せずに開発ができる *
HiveQLの品質担保をいかに効率的に実施していくか * Hiveのチェック制約の弱さをどのようにカバーするか
61.
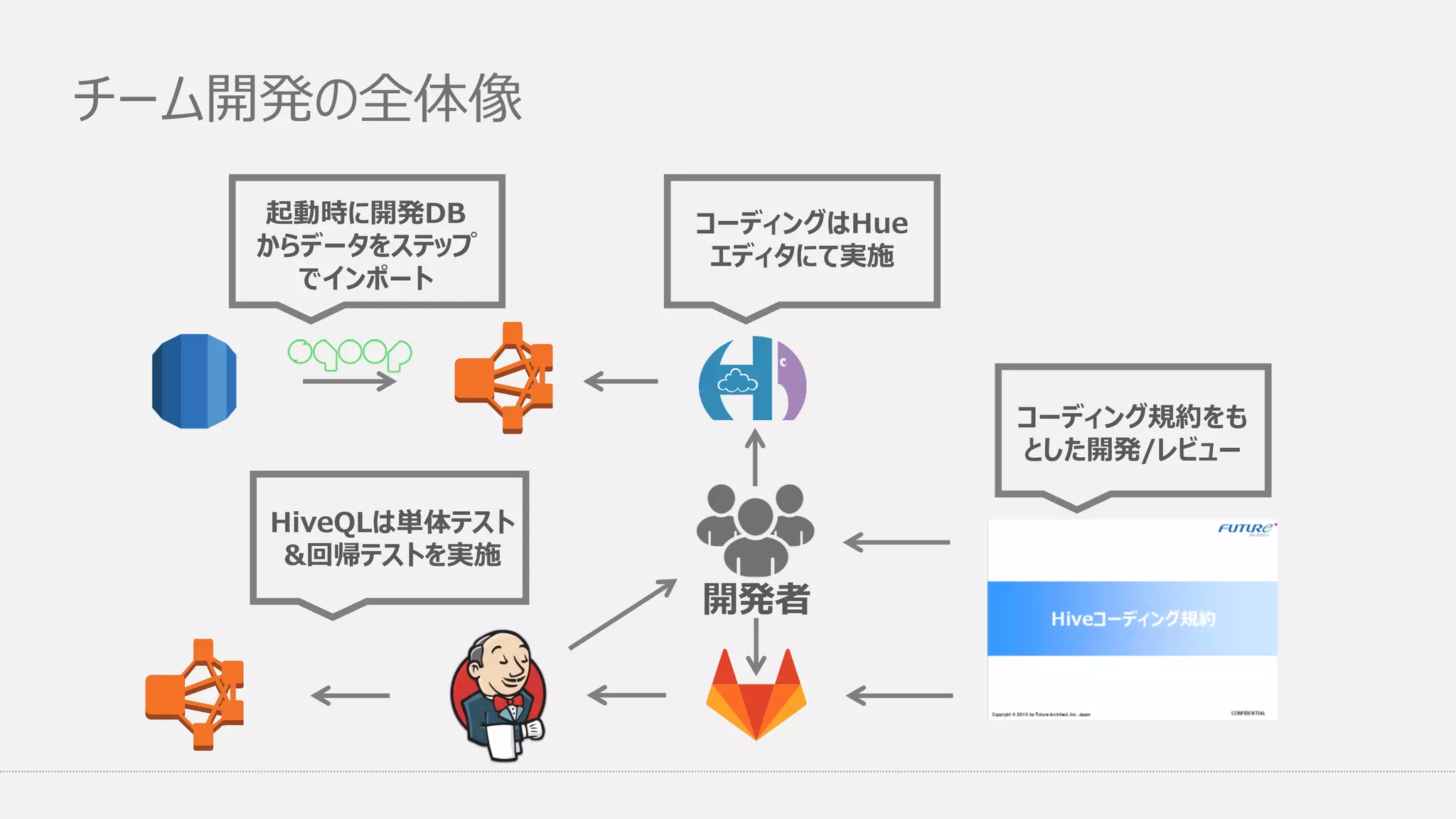
チーム開発の全体像 起動時に開発DB からデータをステップ でインポート コーディングはHue エディタにて実施 HiveQLは単体テスト &回帰テストを実施 コーディング規約をも とした開発/レビュー 開発者
62.
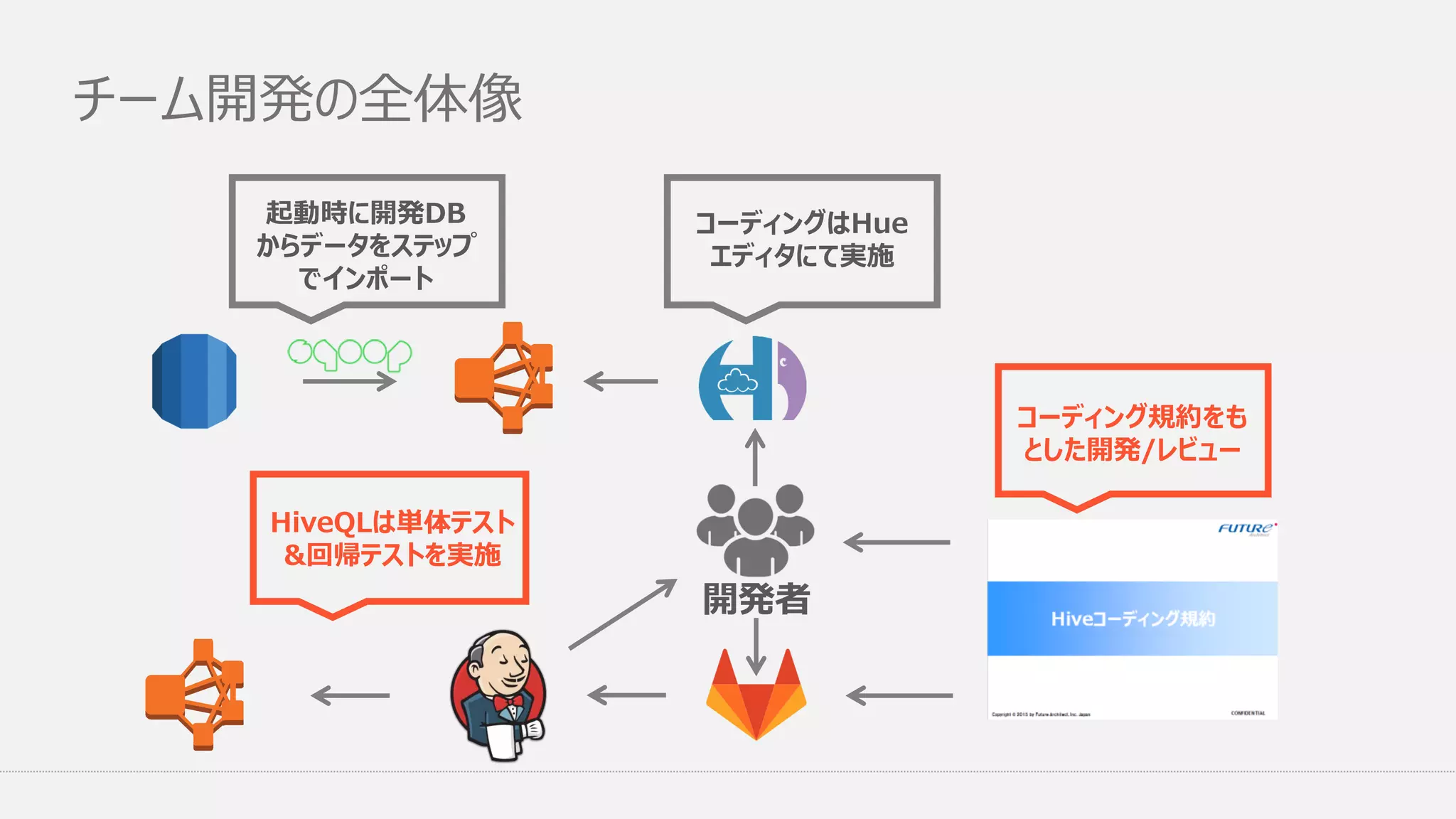
チーム開発の全体像 起動時に開発DB からデータをステップ でインポート コーディングはHue エディタにて実施 HiveQLは単体テスト &回帰テストを実施 コーディング規約をも とした開発/レビュー 開発者
63.
Hiveでのコーディング MapReduceを意識させない規約づくり 開発者間の品質のばらつきを押さえるべく、ポイントは規約化
64.
HiveのユニットテストとCI Hiveだってしっかりテストしなきゃ!! HiveQL Test PG Input Data Output
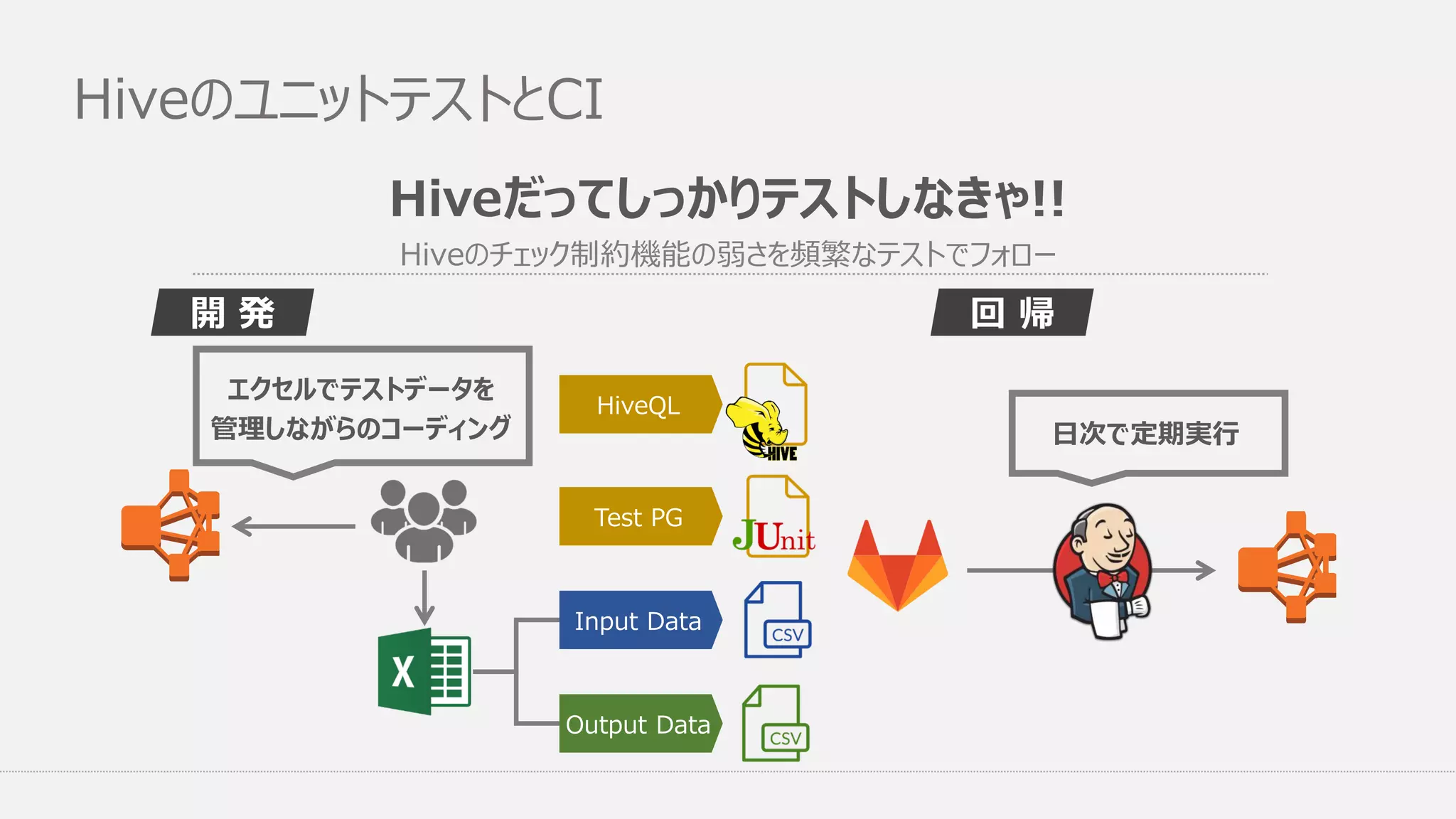
Data 回 帰開 発 日次で定期実行 エクセルでテストデータを 管理しながらのコーディング Hiveのチェック制約機能の弱さを頻繁なテストでフォロー
65.
Hiveリソースによる区分・定数管理 区分値/定数管理もHiveで!! 設計書を正とした管理(納品資料駆動開発!!) 区分/定数管理表 hiverc HiveQL
66.
パラメータも同様に管理 区分/定数管理表 hiverc Hiveパラメータ&UDF登録もエクセルで! 下回りの設定も設計書を正とした管理(Infrastructure as
納品資料!!)
67.
Need More Consideration
68.
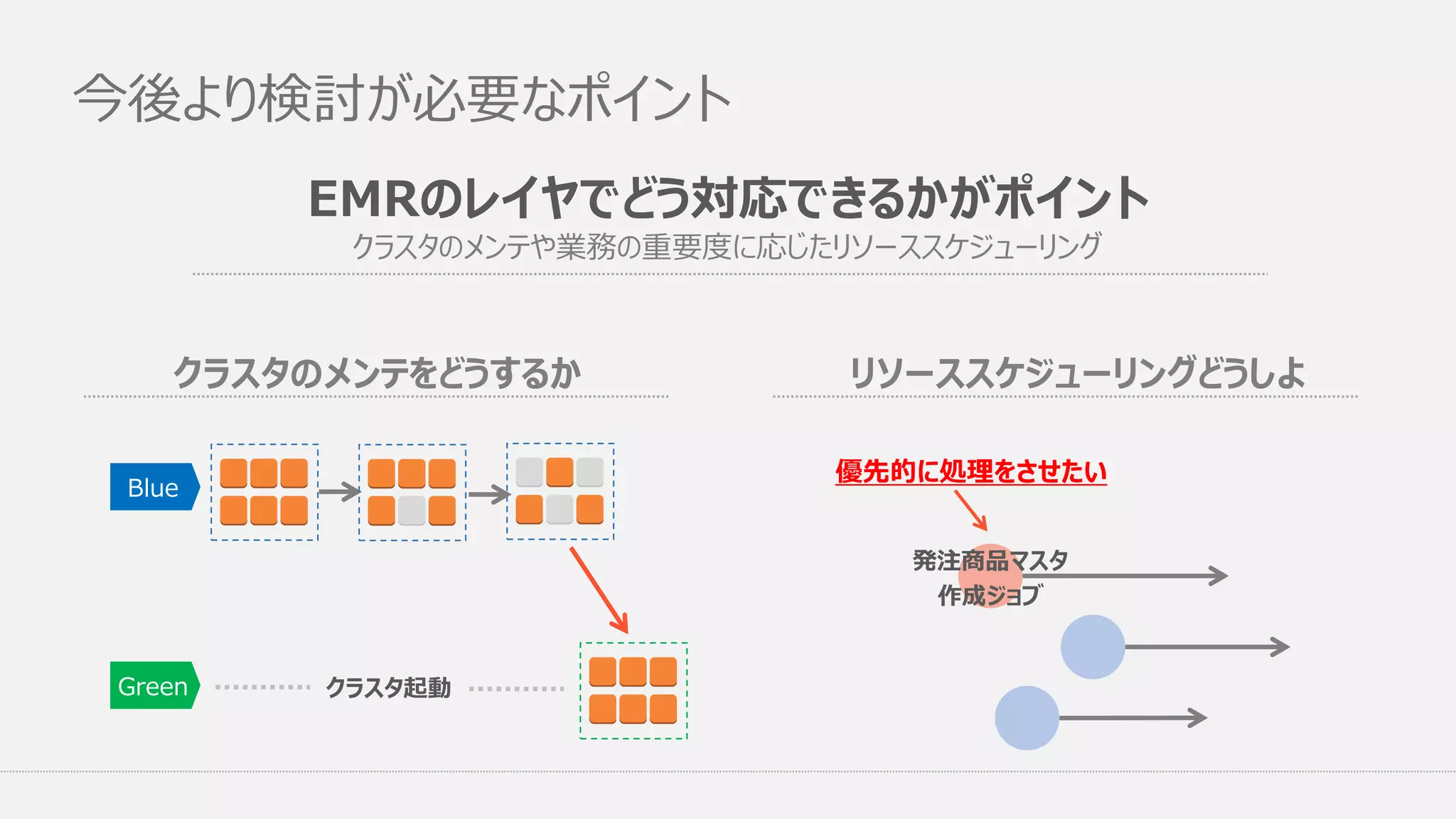
今後より検討が必要なポイント クラスタ起動 Blue Green クラスタのメンテをどうするか 発注商品マスタ 作成ジョブ 優先的に処理をさせたい リソーススケジューリングどうしよ EMRのレイヤでどう対応できるかがポイント クラスタのメンテや業務の重要度に応じたリソーススケジューリング
69.
Conclusion
70.
まとめ:基幹領域の適用シーンをもう一度考える 基幹領域だからといってHadoopを避ける理由はない(選択肢はRDBだけじゃない) 全てをHadoopで置き換えるのではなく、まずは重たいバッチ処理を部分的に切り出すよ うなはじめ方でノウハウをためるのがいいかも
Hadoop(HDFS)をベースとしてエコシステムは進化しているので、導入したHadoop基 盤をベースに様々なワークロードに対応可能 Enterprise
Download




































































































![[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e28hadoopdatalake-181004235141-thumbnail.jpg?width=640&height=640&fit=bounds)











