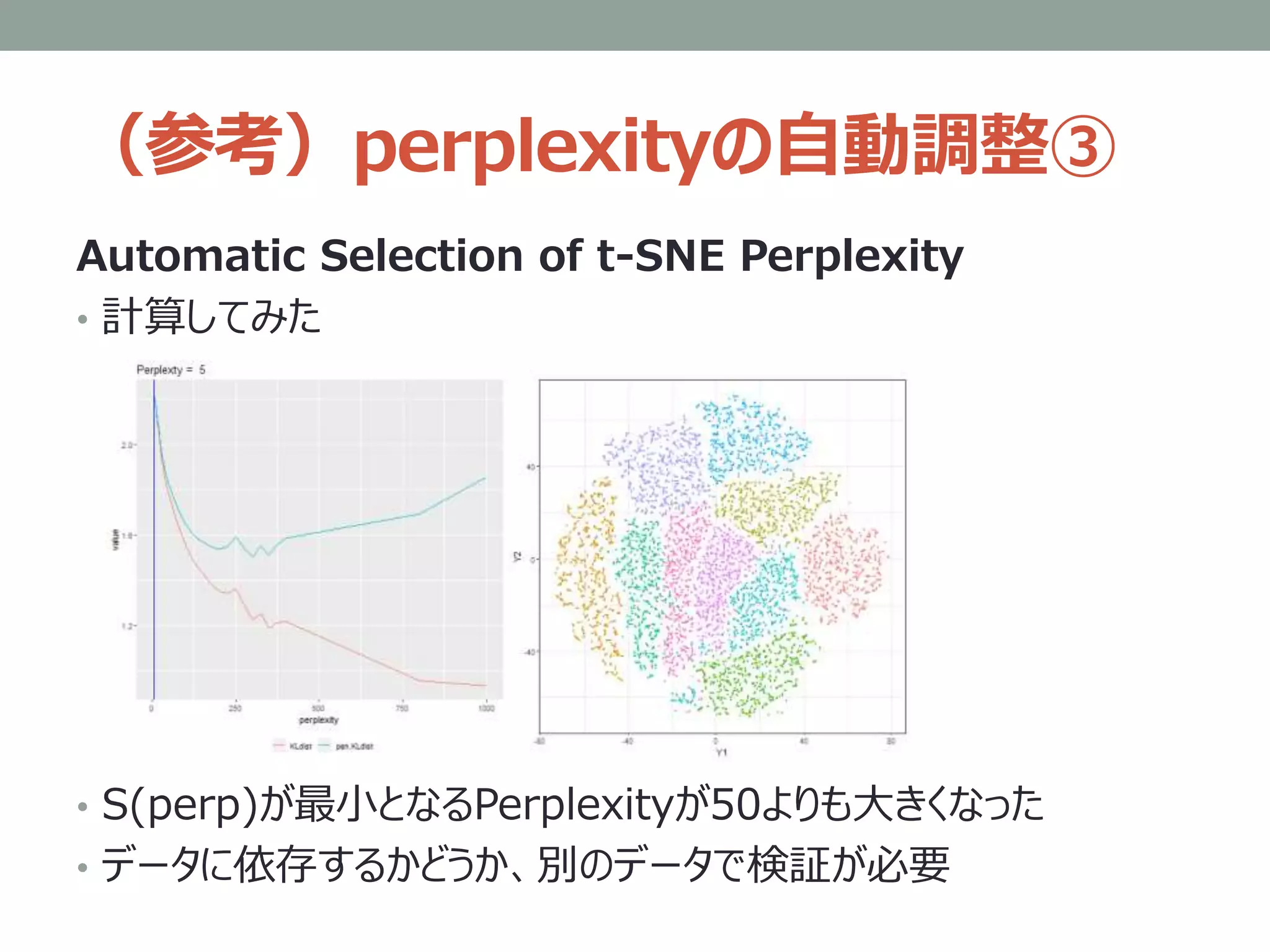
(参考)perplexityの自動調整①
Automatic Selection oft-SNE Perplexity
• Cao and Wang 2017
• よさそうなperplexityを探すのは計算時間が掛かる+目視での評
価になるため、選択基準を与えて自動探索したい
• KL(P||Q) にperplexityによる罰則項を加えた指標を提案
• この指標が有効なら、S(perp)の最小点を二分探索(=自動
化)できる
• 探索範囲は、 5 ~ データサイズ/3のあいだ
KL(P||Q)が得られれば
S(perp)は計算できる
25.
(参考)perplexityの自動調整②
Automatic Selection oft-SNE Perplexity
• Rtsne() は、KL(P||Q) を返してくれるので計算できる
itercosts:
• The total costs (KL-divergence) for all objects
in every 50th + the last iteration
pen.KLdist = last(mapping.tsne$itercosts) +
log(mapping.tsne$N) * perplexity/ mapping.tsne$N)
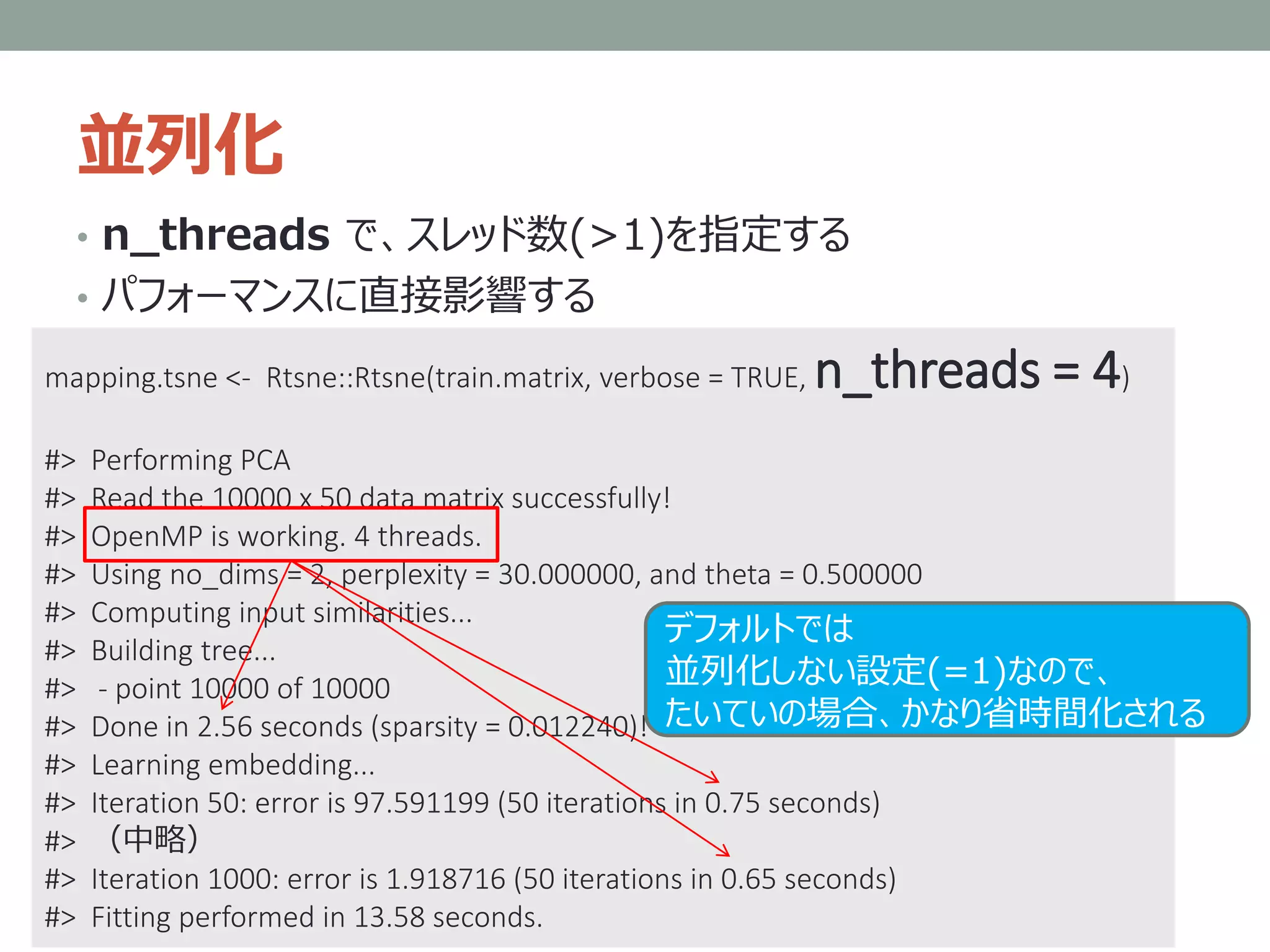
概要? :UMAP
• Thedetails for the underlying mathematics can be
found in:
• McInnes, L, Healy, J, UMAP: Uniform Manifold
Approximation and Projection for Dimension Reduction,
ArXiv e-prints 1802.03426, 2018
• https://arxiv.org/abs/1802.03426
• The important thing is that:
• you don't need to worry about that
• you can use UMAP right now for dimension reduction and
visualisation as easily as a drop in replacement for scikit-
learn's t-SNE.
※ ただし「拡張とか考えるなら、きちんと理解しておけ」みたいなことは書いてある
https://github.com/lmcinnes/umap




































![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190920dlhack-190920011134-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)































