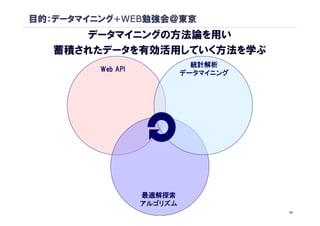
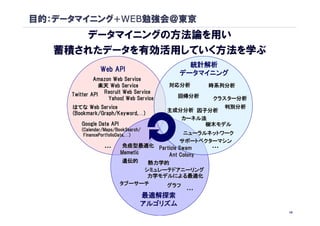
目的:データマイニング+WEB勉強会@東京
データマイニングの方法論を用い
蓄積されたデータを有効活用していく方法を学ぶ
統計解析
Web API
データマイニング
Amazon Web Service
楽天 Web Service 対応分析 時系列分析
Twitter API Recruit Web Service 回帰分析
Yahoo! Web Service クラスター分析
はてな Web Service 判別分析
主成分分析 因子分析
(Bookmark/Graph/Keyword,…)
Bookmark/Graph/Keyword,
カーネル法
Google Data API 樹木モデル
(Calendar/Maps/BookSearch/
FinancePortfolioData,…)
FinancePortfolioData, ニューラルネットワーク
サポートベクターマシン
… …
最適解探索
アルゴリズム
16
17.
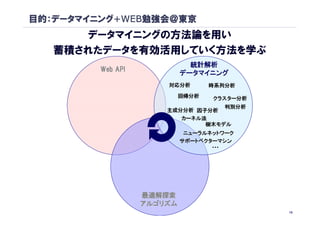
目的:データマイニング+WEB勉強会@東京
データマイニングの方法論を用い
蓄積されたデータを有効活用していく方法を学ぶ
統計解析
Web API
データマイニング
Amazon Web Service
楽天 Web Service 対応分析 時系列分析
Twitter API Recruit Web Service 回帰分析
Yahoo! Web Service クラスター分析
はてな Web Service 判別分析
主成分分析 因子分析
(Bookmark/Graph/Keyword,…)
Bookmark/Graph/Keyword,
カーネル法
Google Data API 樹木モデル
(Calendar/Maps/BookSearch/
FinancePortfolioData,…)
FinancePortfolioData, ニューラルネットワーク
サポートベクターマシン
… 免疫型最適化 Particle Swam …
Memetic Ant Colony
遺伝的 熱力学的
シミュレーテドアニーリング
力学モデルによる最適化
タブーサーチ グラフ
…
最適解探索
アルゴリズム
17
18.
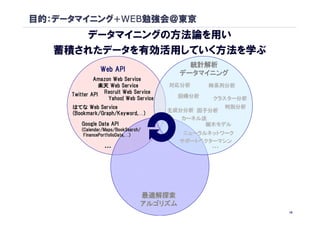
目的:データマイニング+WEB勉強会@東京
データマイニングの方法論を用い
蓄積されたデータを有効活用していく方法を学ぶ
統計解析
Web API
データマイニング
Amazon Web Service
楽天 Web Service 対応分析 時系列分析
Twitter API Recruit Web Service 回帰分析
Yahoo! Web Service クラスター分析
はてな Web Service 判別分析
主成分分析 因子分析
(Bookmark/Graph/Keyword,…)
Bookmark/Graph/Keyword,
カーネル法
Google Data API 樹木モデル
(Calendar/Maps/BookSearch/
FinancePortfolioData,…)
FinancePortfolioData, ニューラルネットワーク
サポートベクターマシン
… 免疫型最適化 Particle Swam …
Memetic Ant Colony
遺伝的 熱力学的
シミュレーテドアニーリング
力学モデルによる最適化
タブーサーチ グラフ
…
最適解探索
アルゴリズム
18
19.
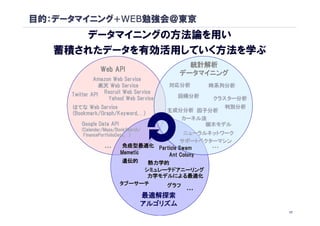
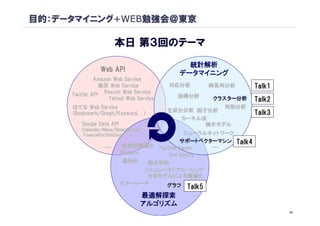
目的:データマイニング+WEB勉強会@東京
本日 第3回のテーマ
統計解析
Web API
データマイニング
Amazon Web Service
楽天 Web Service 対応分析 時系列分析 Talk1
Twitter API Recruit Web Service 回帰分析
Yahoo! Web Service クラスター分析 Talk2
はてな Web Service 判別分析
主成分分析 因子分析
(Bookmark/Graph/Keyword,…)
Bookmark/Graph/Keyword, Talk3
カーネル法
Google Data API 樹木モデル
(Calendar/Maps/BookSearch/
FinancePortfolioData,…)
FinancePortfolioData, ニューラルネットワーク
サポートベクターマシン Talk4
… 免疫型最適化 Particle Swam …
Memetic Ant Colony
遺伝的 熱力学的
シミュレーテドアニーリング
力学モデルによる最適化
タブーサーチ グラフ Talk5
…
最適解探索
アルゴリズム
19



































![[R勉強会][データマイニング] R言語による時系列分析](https://cdn.slidesharecdn.com/ss_thumbnails/r-100423232629-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる R言語によるクラスター分析 - 似ているものをグループ化する-](https://cdn.slidesharecdn.com/ss_thumbnails/webmining2cluster-100319212743-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[データマイニング+WEB勉強会][R勉強会] R言語によるクラスター分析 - 活用編](https://cdn.slidesharecdn.com/ss_thumbnails/cluster-100416230155-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






































