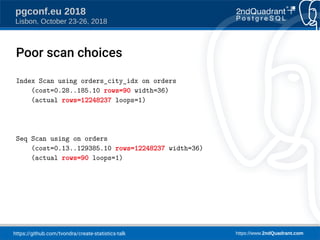
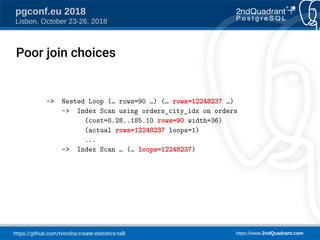
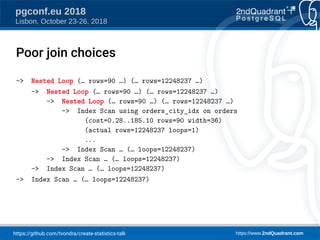
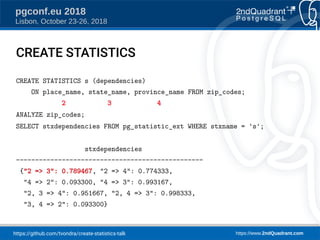
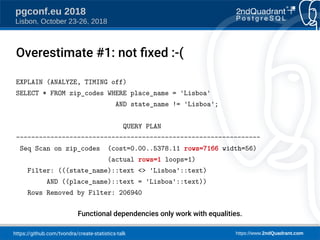
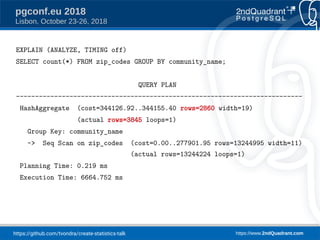
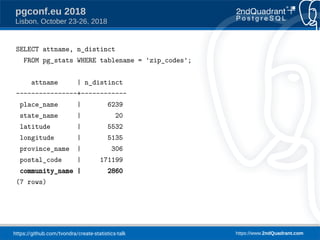
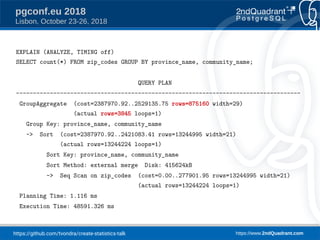
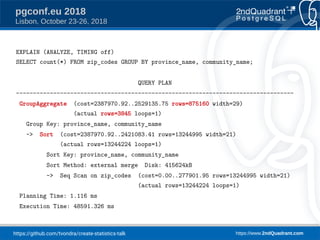
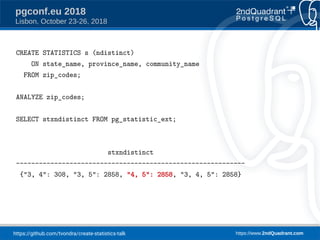
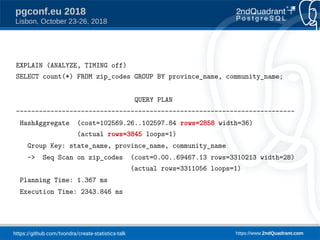
The document discusses a presentation on creating statistics in PostgreSQL presented at PGConf.EU 2018, focusing on improving query planning and estimates through functional dependencies and ndistinct statistics. It includes practical examples using a zip codes dataset, showcasing how correlated columns can lead to inaccurate estimations and offering solutions to enhance query performance. Key topics covered include the creation of statistics, analysis of query plans, and the use of functional dependencies for more accurate data predictions.













![https://github.com/tvondra/create-statistics-talk https://www.2ndQuadrant.com
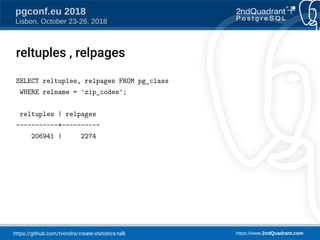
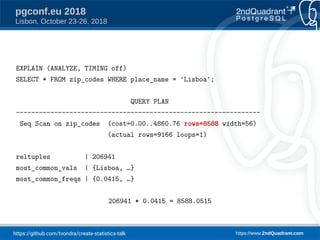
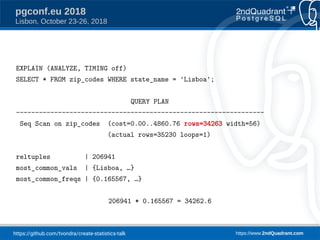
pgconf.eu 2018
Lisbon, October 23-26, 2018
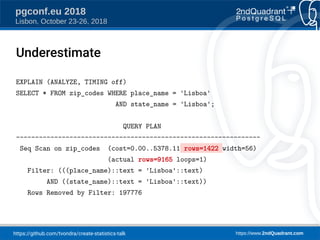
place → state: 0.789 = d
P(place = 'Lisboa' & state = 'Lisboa') =
P(place = 'Lisboa') * [d + (1-d) * P(state = 'Lisboa')]
206941 * 0.0415 * (0.789 + (1-0.789) * 0.1656) = 7076.05](https://image.slidesharecdn.com/create-statistics-what-is-it-181025091214/85/CREATE-STATISTICS-what-is-it-for-21-320.jpg)








![[TechPlayConf]Rekognition導入事例](https://cdn.slidesharecdn.com/ss_thumbnails/techplayconfrekognition-170820072435-thumbnail.jpg?width=640&height=640&fit=bounds)































































