귤 익은 것구별하기
개발자인 제가 시골에 갔습니다.
과수원 하시는 어머니가 일을 시킵니다. 귤 익은 것만 골라내라고.
창고로 갔습니다. 큰 바구니에 귤 들이 담겨 있습니다.
골라내야 하긴 하는데, 어떻게.
“엄마, 어떻게 골라?”
“거기 골라진 것 보고 알아서 해"
6.
귤 익은 것구별하기
상자가 2개 있습니다.
짐작해 보건데 한 상자에는 익은 것들이, 다른 상자에는 안 익은 것들이.
고것들을 보고 대애충 감잡아서 구별해 놓았습니다.
“다 했어?”
“다 했어"
“잘했다. 온 김에 1달 하고 가"
7.
귤 익은 것구별하기 - 깡통 로봇으로.
옆에 로봇이 있습니다.
저는 개발자입니다. SW 엔지니어입니다. 대신 하게 코딩해봅시다.
로직을 입력해야 합니다.
‘Xxx 하면 우측 상자에, 그렇지 않으면 좌측 상자에 넣도록.’
어떻게 했더라?
8.
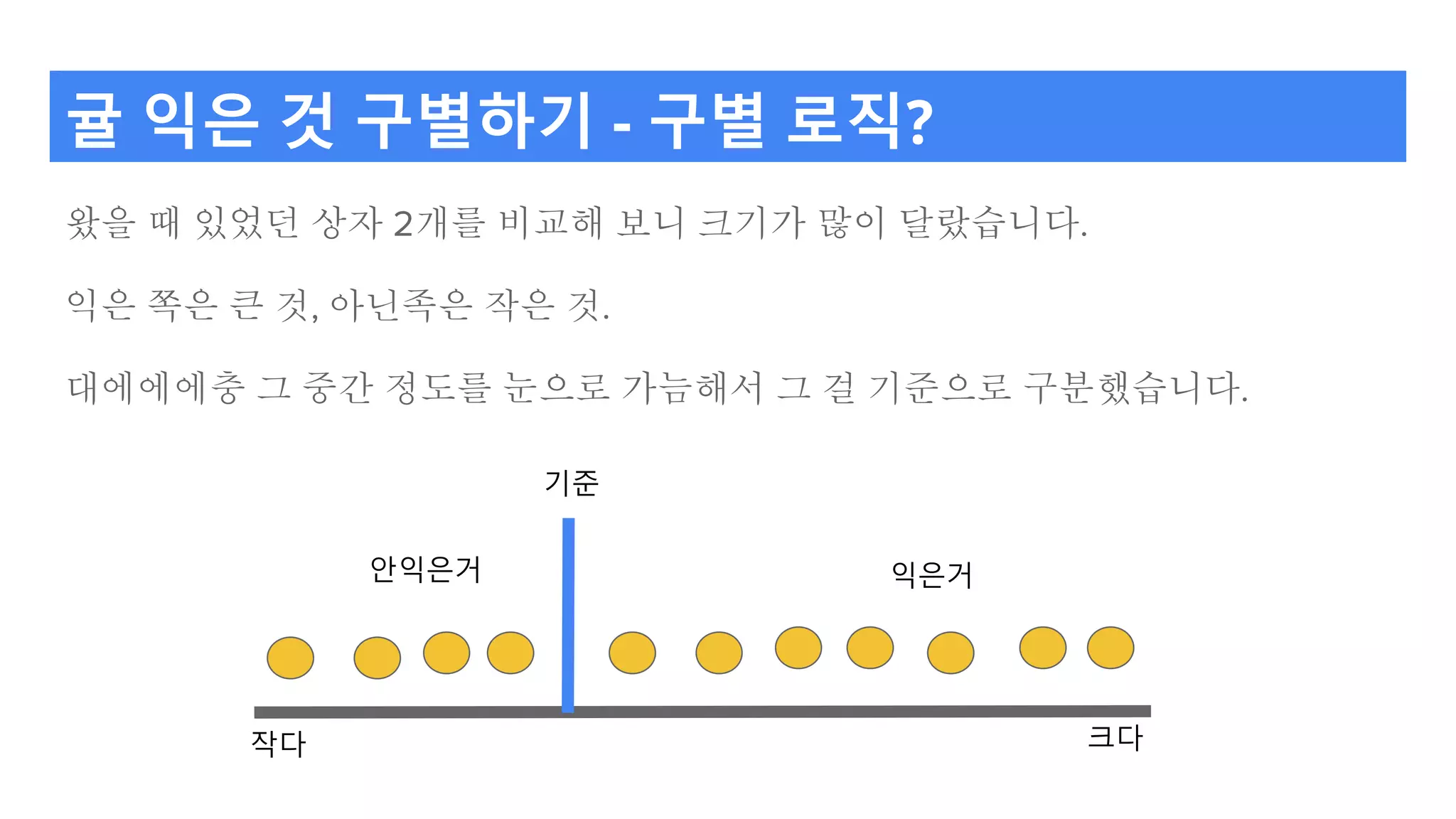
귤 익은 것구별하기 - 구별 로직?
왔을 때 있었던 상자 2개를 비교해 보니 크기가 많이 달랐습니다.
익은 쪽은 큰 것, 아닌족은 작은 것.
대에에에충 그 중간 정도를 눈으로 가늠해서 그 걸 기준으로 구분했습니다.
크다작다
기준
익은거안익은거
9.
귤 익은 것구별하기 - 구별 로직!
귤의 크기를 로봇이 측정하게 했고,
눈으로 가늠 했던 그 기준을 입력했습니다.
아자! 깡통 로봇이 잘 구분합니다. 뿌듯합니다.
“엄마 놀다 올게요.”
“그려"
10.
사과 익은 거구별하기
새벽일찍 들어와 속쓰린데, 일어나 밥 먹으랍니다.
“어제 욕봤어, 퍼뜩 먹고, 귤 옆에 보면 사과도 있어 그 것도 혀.”
11.
사과 익은 거구별하기 - 다시 로봇으로
사과도 역시 상자 2개가 있네요.
익은 거, 안익은 거. 그리고 구별할 거 바구니에 잔뜩.
역시 로봇이 하게 해야지.
로직이야 비슷할 테고, 그렇다면 기준을 찾아내기만 하면 되겠네.
상자 2개의 사과를 보고 기준을 찾아내는 로직을 구현하고 실행시킵니다.
자러갑니다.
귤은 내가 학습했는데(직접코딩한 알고리즘),
사과는 기계가 학습했네요(기계 학습한 알고리즘).
그 둘의 목적이나 사용새는 똑 같아요.
분류기크기 익었다 구분
22.
구분을 위해 ‘크기를재서 기준 크기를 가지고 구별’을 고안해요. ←model
학습 시키려면 사과 2상자가 필요해요. 익은거 상자, 안익은거 상자. ←training set
여러번 반복해서, ← iteration, step
원하는 기준 크기를 찾아내요. ← learning
기준 크기는 숫자로 표현되네요.
그리고 구분 안된 바구니에 적용해요. ← test set
23.
사과 익은 것구별하기 - 로봇으로
자고 나왔더니 기준을 찾았네요.
찾은 기준을 입력했습니다.
다시 실행시키니, 아자! 깡통 로봇이 잘 구분합니다. 흐흐흐
“엄마 또 놀다 올게요.”
“일찍 들어와!”
24.
사과 익은 것구별하기 - 다시
오늘도 얼마 못잤는데, 깨웁니다.
“사과 구별해 놓은 거 다시 허야혀.”
“왜! 크기 보고 잘했는데"
“크기만 하면 뭘해. 퍼런게 익지도 않았는디. 다시 혀!"
25.
“다시 혀야혀" ←성능이 안좋다.
training set으로 학습된 결과를 test set에 적용했더니 그 결과가 좋지 않다.
training set에서의 성능이 100%이더라도 그것이 test set과 직결되지 않는다.
26.
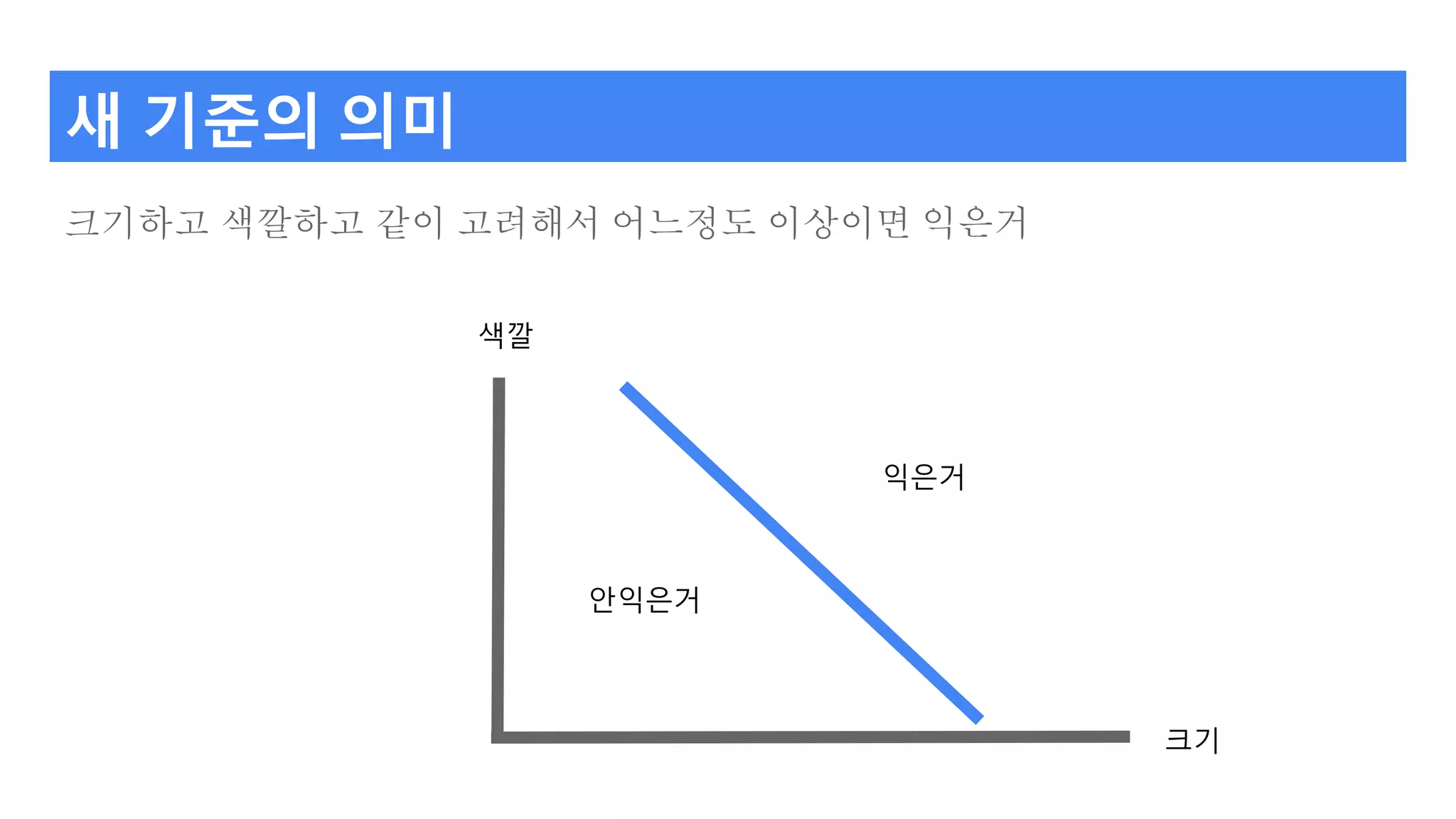
사과 익은 것구별하기 - 왜?
구별해 놓은 걸 봤습니다.
정말 큰것중에 퍼런게 익었다고 구별되어 있네요.
아. 색깔도 신경쓰자.
크더라도 퍼러면 안익은거, 작더라도 뻘거면 익은거.
크다작다
안익은거 익은거
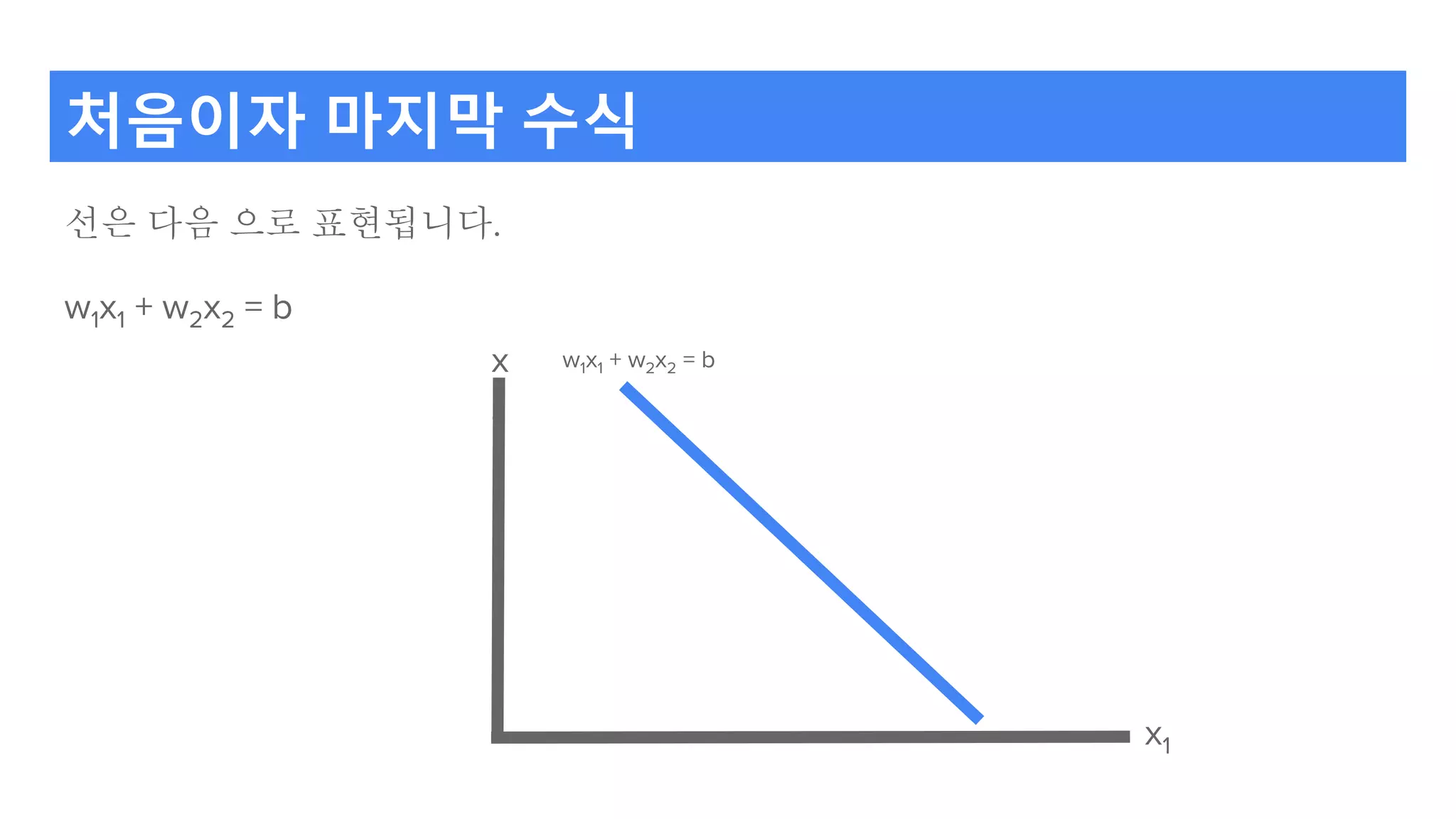
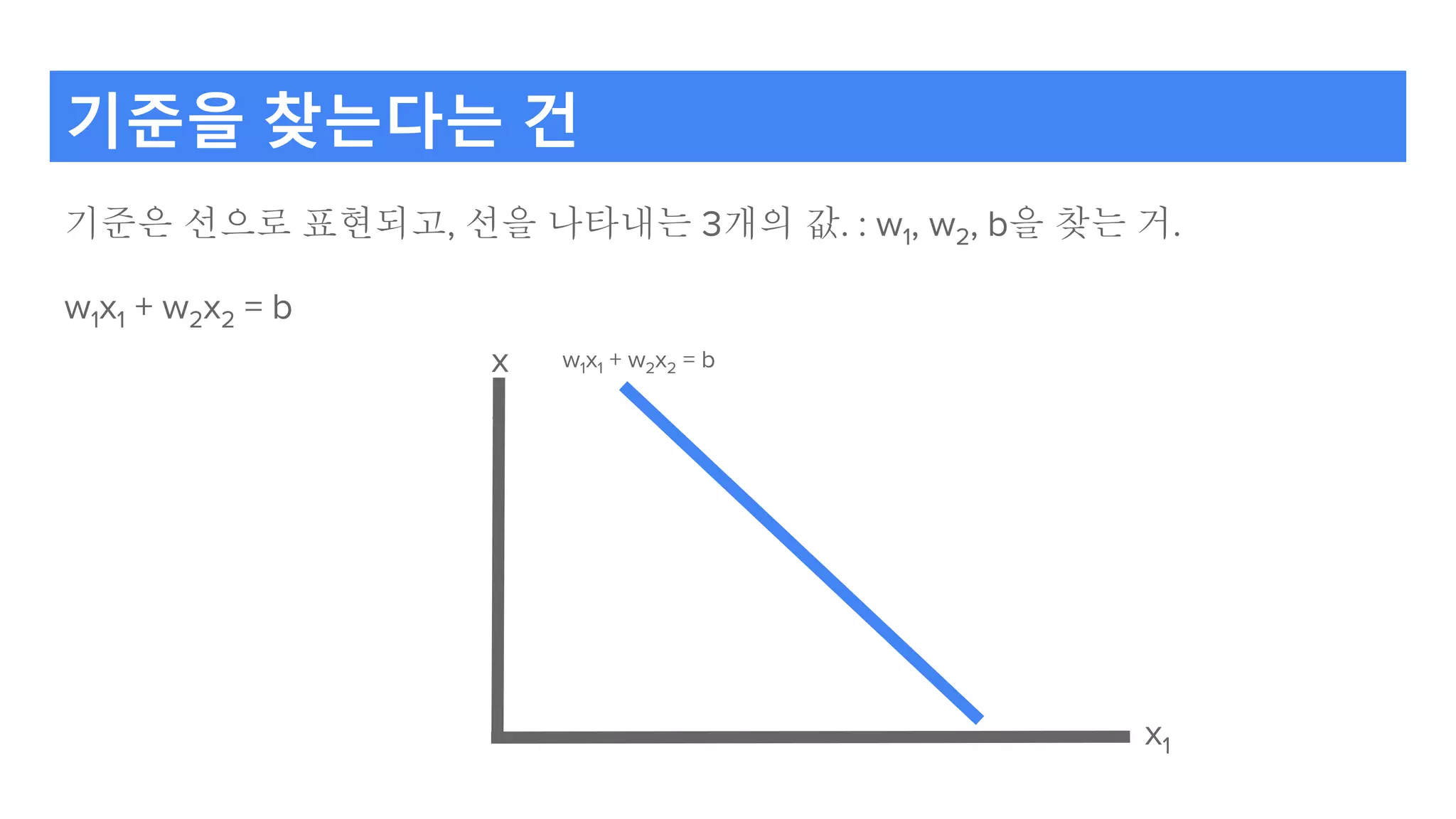
기준을 찾는다는 건
기준은선으로 표현되고, 선을 나타내는 3개의 값. : w1, w2, b을 찾는 거.
w1x1 + w2x2 = b
w1x1 + w2x2 = bx
2
x1
37.
선을 학습하는 방법
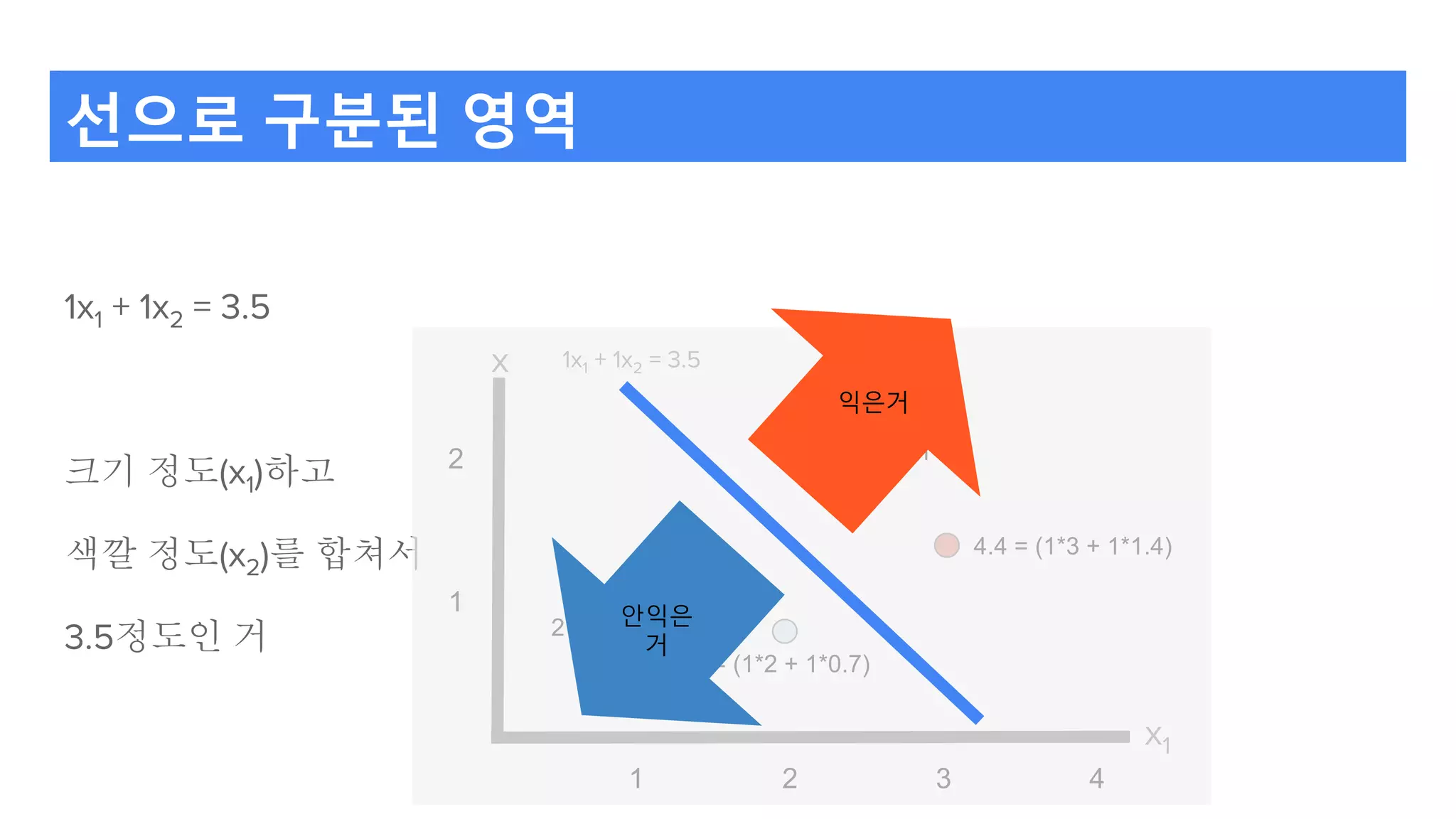
기본아이디어 : ‘최종 오차는 해당 입력 값 크기에 기인한다.’
(3, 1)의 안 익은 배의 경우 크기(3)가 색깔(1)보다 그 결과에 크게 작용했다.
색깔의 비중보다
크기의 비중을 더 조정하자.
(3, 1)
4 = 1x3 + 1x1
1x1 + 1x2 = 3.5
크기 3, 색깔 1
크기에 대한 비중을 더 조정
38.
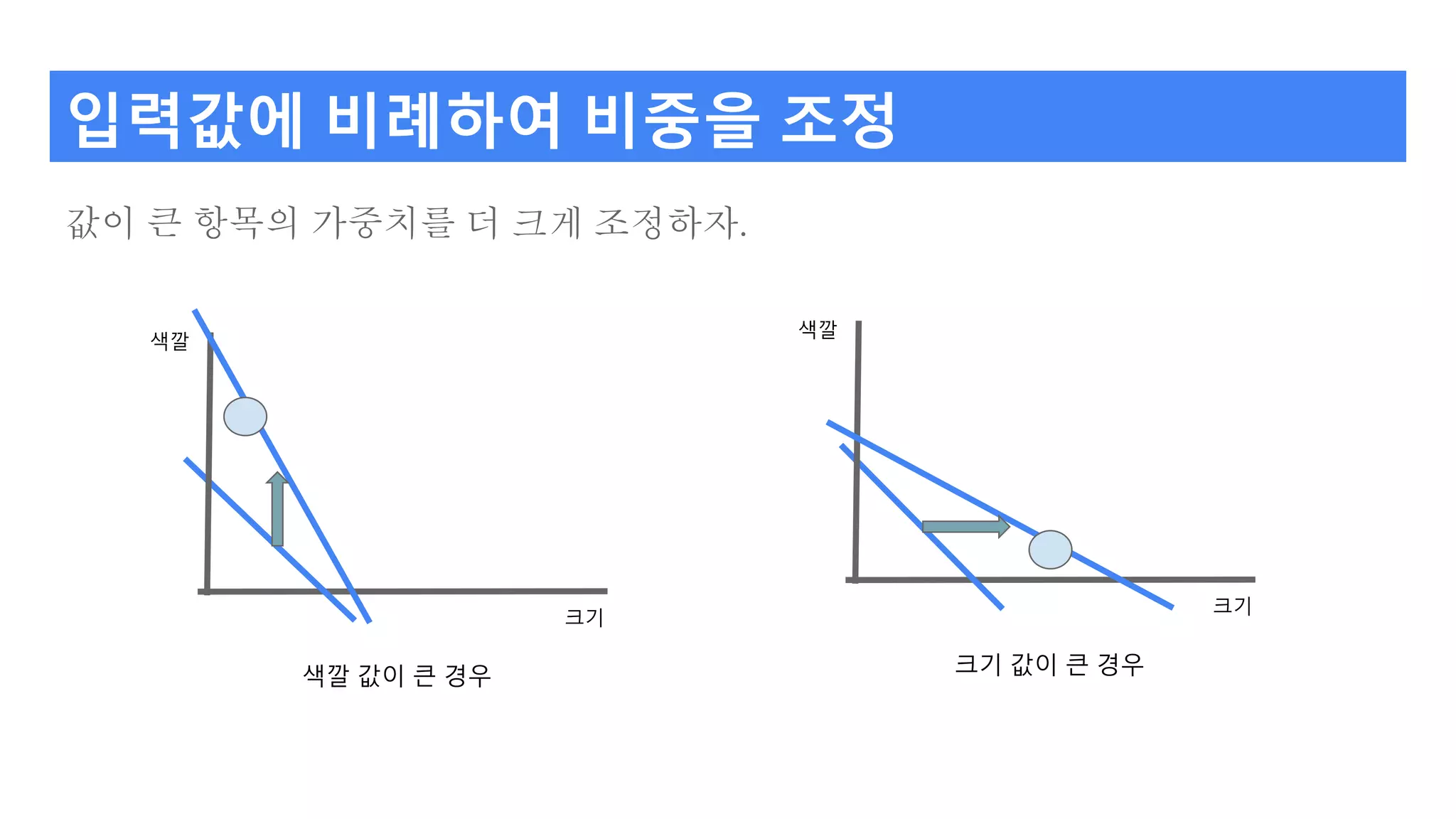
값이 큰 항목의가중치를 더 크게 조정하자.
입력값에 비례하여 비중을 조정
크기
색깔
크기
색깔
색깔 값이 큰 경우 크기 값이 큰 경우
39.
선을 학습하는 방법
각비중치를 오차와 각 입력값의 곱에 비례해서 비중치를 수정한다.
가중치의 변경 크기 = 입력값 * 오차 * 학습율
크기에다가 색깔을 추가하니더 잘된다. ← 크기, 색깔을 특질(feature)라 한다.
각 사과 마다 2개 값의 특질이 있다. 크기 3, 색깔 2 ← 특질 벡터 혹은 입력 벡터라 한
다.
사과 예의 경우 2개 특질(크기, 색깔)을 사용했다. ← 입력 벡터가 2차원.
학습을 한다는 건 선을 구성하는 3개의 값을 찾는 것이다.
선으로 양분한다. ← 선형 분리(linear separating)
각 입력에 곱해지는 w1, w2들을 가중치(weight)라 칭한다. 각 입력 별 중한 정도?
45.
오차 함수(Cost Function)
귤의예에서, 그 기준의 값에 따라 오
차의 크기가 결정된다.
결국 학습의 목표는 오차를 최소로,
혹은 오차함수의 값이 최소가되는 w
를 찾는것.
오차 함수는 모델을 구성하는 가중치
(w)의 함수이다.
예에서의 기준값에 의해 발생하는 오
차의 정도.
46.
경사 하강법(Gradient Descent)
현재계수 w에서 오차가 줄어드는 방
향과 그 때의 경사로 w를 조정한다.
오차 평면위에 공을 놓았을 때 공은
최소가 되는 지점으로 흘러간다.
더 이상 공이 움직이지 않으면 혹은
오차가 충분히 작으면 학습을 종료한
다.
http://rasbt.github.io/mlxtend/user_guide/general_concepts/gradient-
optimization/
47.
사과 예에서의 학습방법
경사하강법은 오차함수를 구하고, 이를 각 weigth 별로 편미분하면 각 weigth 별로
수정할 다음 값을 구할 수 있다. 그렇다고 한다.
선형 모델(w1x1 + w2x2 = b)에서는 경사하강법의 결과가 직관적으로 설명했던 방법과
동일하다.
사실 그 직관적인 설명의 방법은 증명된 것이다.
결국 사과예에서 학습한 방법은 경사하강법을 사용한 것이다.
48.
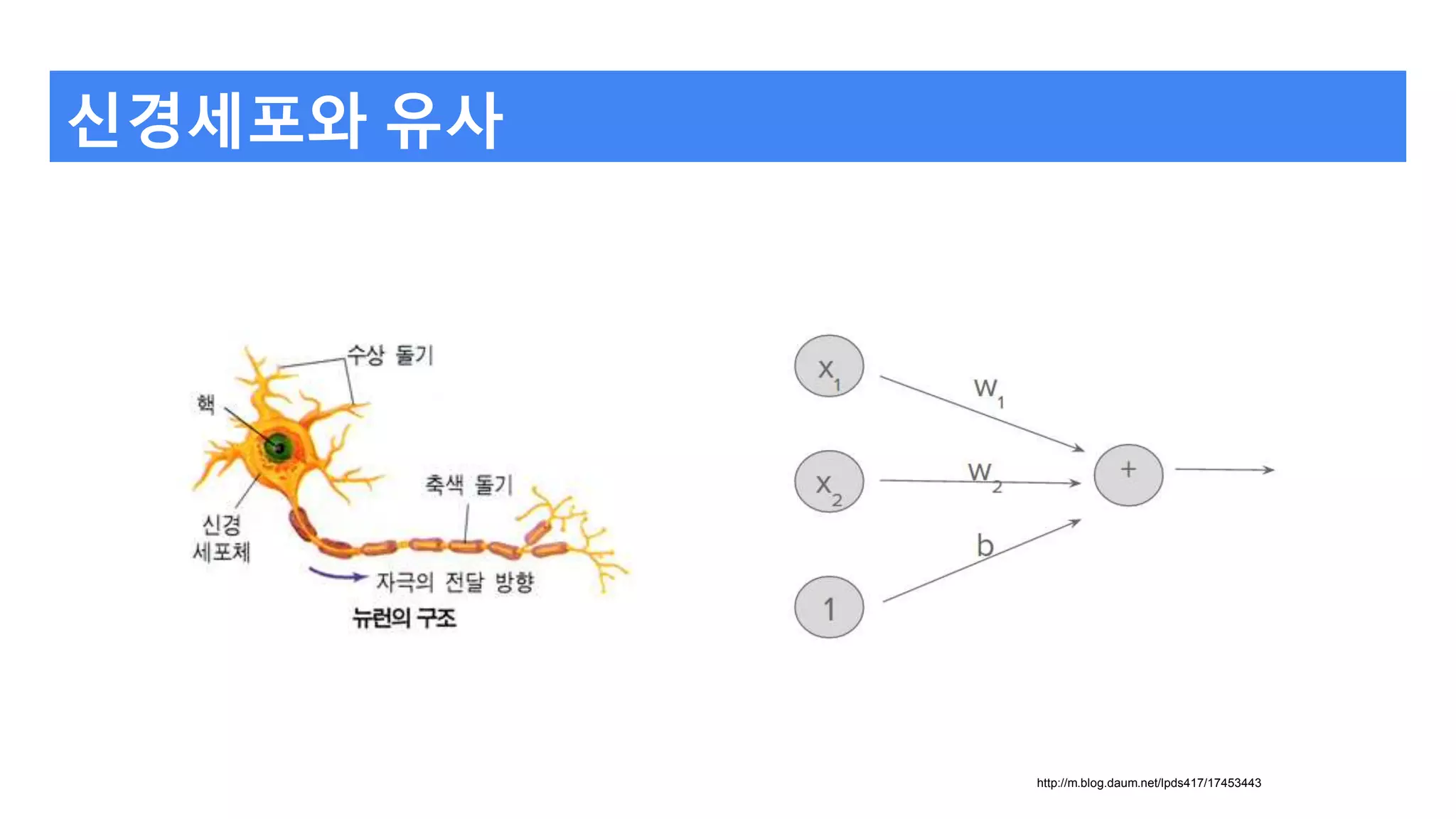
신경 세포
여러개의 수상돌기에서자극이 합해져서
그 값이 어느 값 이상일 경우
축색돌기로 자극을 발생시킨다.
http://m.blog.daum.net/lpds417/17453443
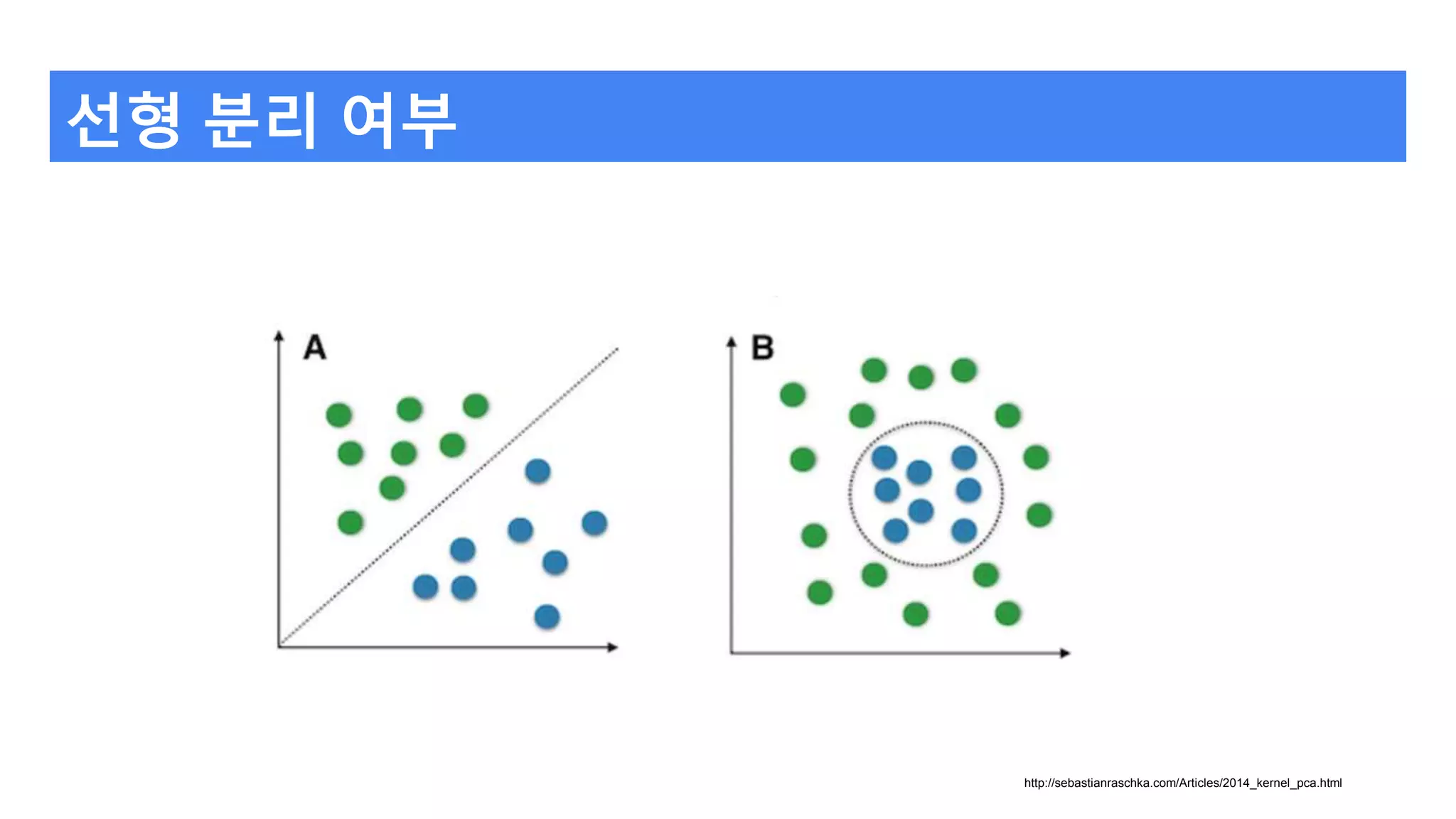
선형 분리 불가문제의 해결 방법
입력 차원을 늘린다.(사과 예)
입력 차원의 비선형 변환하여 선형분리 가능하도록 한다.
혹은 MLP.
http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/
54.
MLP(Multi Layer Perceptron)
입력과출력 사이에 층이 더 있다.
개별 perceptron의 결과를 다음 층의 입력으로 사용하고 결과적으로 선형 분리의 제
약을 극복한다.
http://docs.opencv.org/2.4/modules/ml/doc/neural_networks.html
55.
Perceptron의 능력
1개의 Perceptron은1개의 선형 분리를 할 수 있다.
perceptron의 결과를 다른 perceptron의 입력으로 하면 여러개의 선으로 분리를 할
수 있다.
https://www.wikipendium.no/TDT4137_Cognitive_Architectures
기계학습(Machine Learning) 이란
특정문제의 경우 사람이 알고리즘을 고안하기가 아주 어렵다.(얼굴 인식 같은)
그런 문제의 경우 기계가 학습하게 하자.
기반 데이타(train set)를 가지고 학습한다.
사람이 코딩한
알고리즘
기계가 학습한
알고리즘
하드 코딩된 룰 찾아낸 수치
58.
기계학습과 신경망
아주 많은기계학습 방법이 있다. 아주 많다.
그 중의 하나가 신경망이다.
신경망에도 MLP를 비롯한 아주 많은 모델이 있다.
59.
신경망과 심층신경망(Deep NeuralNetwork)
에전에는 은닉층이 2,3개에 불과했으나 요즈음은 몇십개를 사용하기도 한다.
그 은닉층이 깊다고 해서 심층신경망(Deep Neural Network)이라 불린다.
60.
기계학습과 심층학습(Deep Learning)
사실다른게 없다.
AI, 기계학습에 대한 엄청난 기대가 20년 전 쯤에 있었지만 엄청난 계산량의 필요로
인해 기대만큼의 실망이었다.
최근 Big(저장공간, 컴퓨팅 파워)덕분에 압도적인 성능을 보임.
실망했던 용어 대신 붐을 일으키기 위한 용어이다.
61.
기계학습과 AI?
인간이 고안한알고리즘이건, 기계가 학습한 알고리즘이건 어떤 기계가 판단해서
처리하면 AI라 한다.
AI 밥통, AI 세탁기, 자동주행 자동차.
단지 기계가 학습한 경우를 기계학습이라 한다.
그리고 요즘 신경망의 압도적인 성능으로 기계학습의 대부분은 신경망을 사용한다.
그래서, 그냥 NN = ML = AI 라고 부른다. 맞는 말은 아니지만.
62.
ML의 쓰임새
분류(classification) :귤분류, 사과 분류, 숫자 인식
군집화(clustering) : 뉴스나 데이터의 군집화
회기(regerssion) : 집값 예측
http://www.aishack.in/tutorials/kmeans-clustering/http://www.holehouse.org/mlclass/01_02_Introduction_regression_anal
ysis_and_gr.html
63.
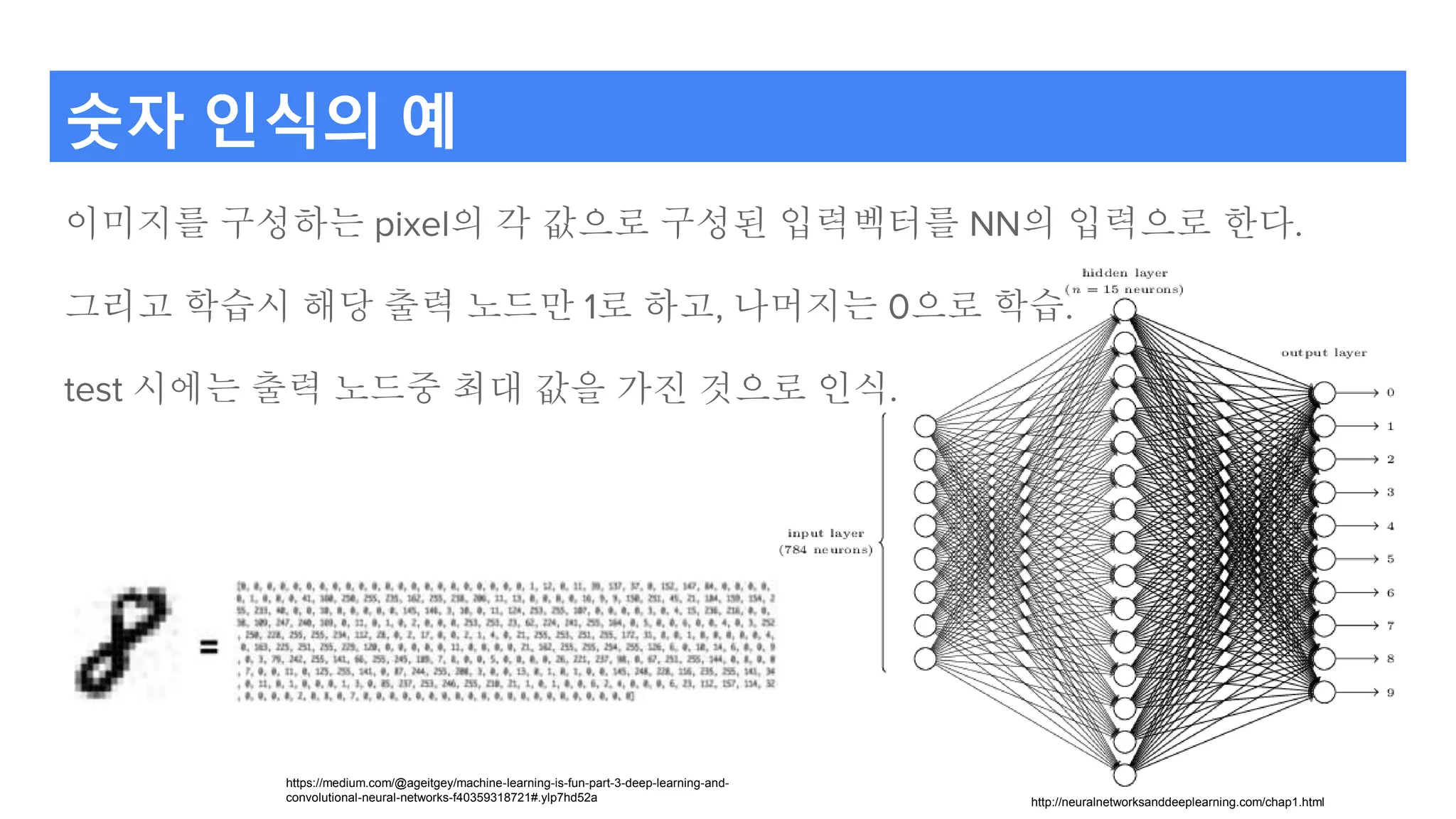
숫자 인식의 예
이미지를구성하는 pixel의 각 값으로 구성된 입력벡터를 NN의 입력으로 한다.
그리고 학습시 해당 출력 노드만 1로 하고, 나머지는 0으로 학습.
test 시에는 출력 노드중 최대 값을 가진 것으로 인식.
https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-
convolutional-neural-networks-f40359318721#.ylp7hd52a http://neuralnetworksanddeeplearning.com/chap1.html
64.
CNN, RNN
최근 CNN과RNN의 월등한 성능을 보이고 있다.
그래서 ML의 다른 방법을 제끼고 AI하면 NN라고 할만큼 대세이다.
65.
CNN(Convolutional NN)
사람눈에는 특정모양에 반응하는 신경세포들이 있다.
이를 구현한 가장 간단한 방법이 convolution filter이다.
https://developer.apple.com/library/content/documentation/Performance/Conceptual/vImage/Con
volutionOperations/ConvolutionOperations.html
66.
Convolutional Filter
필터 모양의자극이 있으면 그 결과가 최대가 된다.
http://www.kdnuggets.com/2016/08/brohrer-convolutional-neural-networks-explanation.html
67.
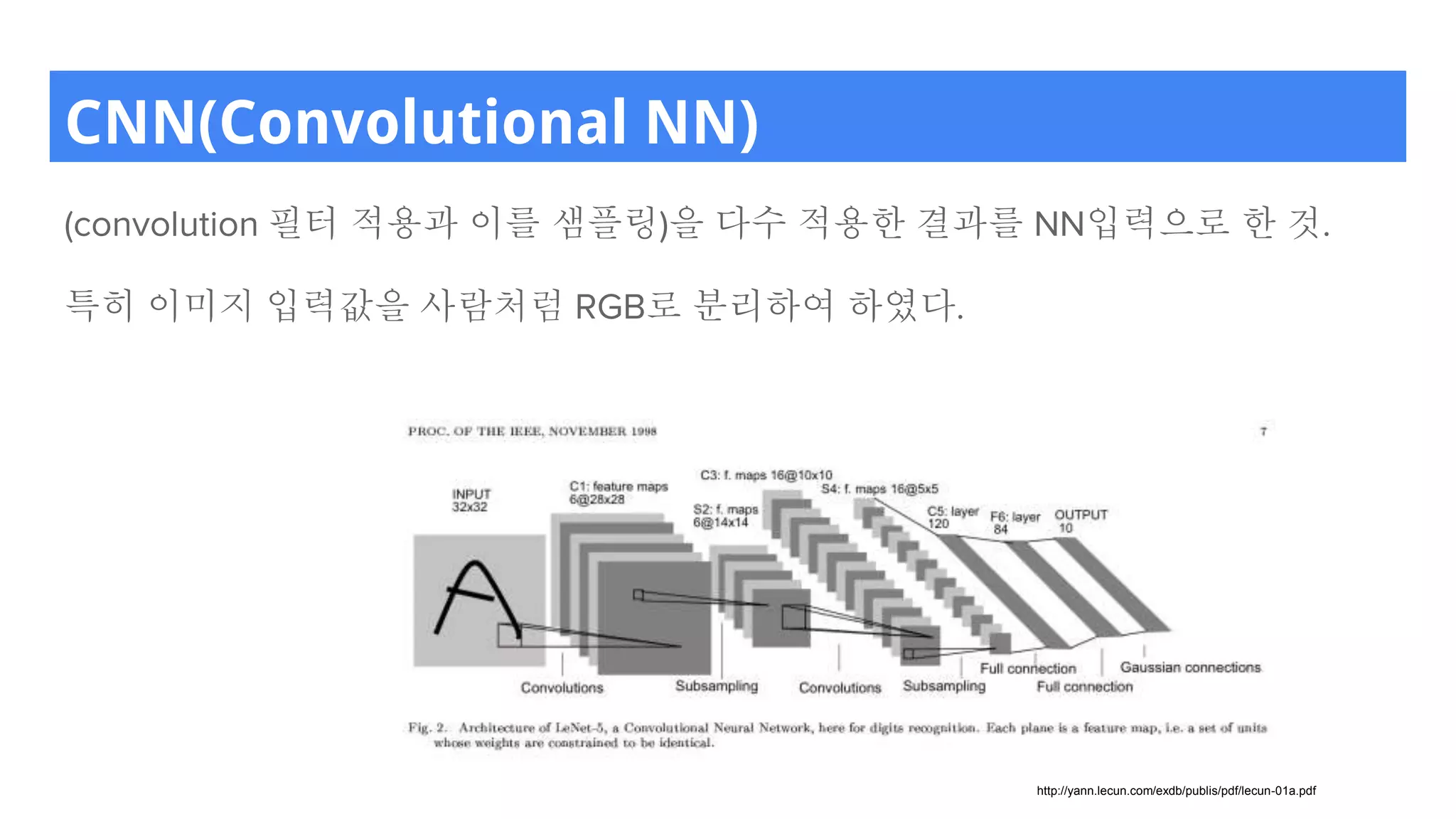
CNN(Convolutional NN)
(convolution 필터적용과 이를 샘플링)을 다수 적용한 결과를 NN입력으로 한 것.
특히 이미지 입력값을 사람처럼 RGB로 분리하여 하였다.
http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
68.
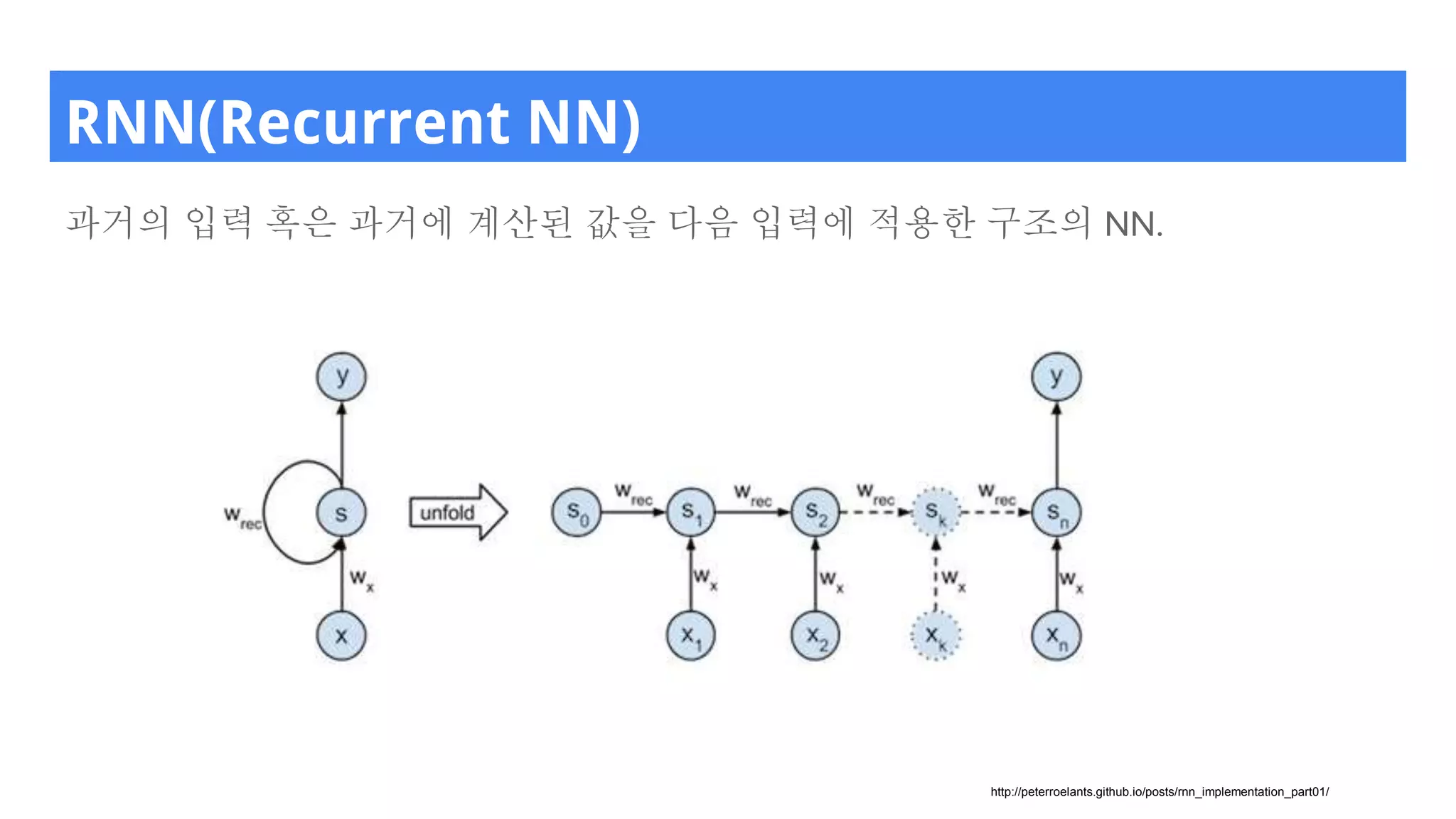
RNN(Recurrent NN)
과거의 입력혹은 과거에 계산된 값을 다음 입력에 적용한 구조의 NN.
http://peterroelants.github.io/posts/rnn_implementation_part01/
MLP 정의
# MLP모델
def multilayer_perceptron(x, weights, biases):
# h = x * w + b
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
# h = relu(h)
layer_1 = tf.nn.relu(layer_1)
# o = h * w + b
out_layer = tf.matmul(layer_1, weights['out']) + biases['out']
return out_layer
85.
학습 방법 정의
#출력값 : 학습된(weights, biases) 모델에 값(x)을 입력.
out = multilayer_perceptron(x, weights, biases)
# 오차 : out과 y의 차이
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(out, y))
# 학습. 오차를 최소로 하게 한다.
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# 요 코드는 단지 실행에 대한 정의이다.
# session.ru()으로 호출될 때 실행된다.
86.
학습
with tf.Session() assess: # tf.Session.run(op)로 실행시킨다
sess.run(init) # 변수들을 초기화 하고
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(training_epochs): # 정해진 학습 횟수 만큼
for i in range(total_batch): # 전체 데이터를 한번에 batch_size 개수만큼
batch_x, batch_y = mnist.train.next_batch(batch_size) # 학습시킬 데이터를 꺼내서
sess.run([optimizer, cost], feed_dict={x: batch_x, y: batch_y}) # 학습시킨다.
87.
성능 확인
# out의최대 노드와 y의 최대 노드가 같은면
correct_prediction = tf.equal(tf.argmax(out, 1), tf.argmax(y, 1))
# correct_prediection의 평균
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# 테스트 집합으로 값을 구한다.
print("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))
88.
실행 결과
$ pythonmlp.py
Optimization Finished!
Accuracy: 0.9399
아이리스
3가지 종류가 있다.
꽃받침과꽃잎의 폭과 길이로 구분
입력벡터는 4차원.
http://sebastianraschka.com/Articles/2015_pca_in_3_steps.html
91.
TensorFlow로 MLP 학습
학습대상 : 아이리스 인식
ML 방법 : 신경망 MLP
사용 데이타 : 학습 데이터 120개, 테스트 데이터 30개
https://www.tensorflow.org/tutorials/tflearn/
92.
MLP 모델
입력 노드수 : 4개
히든 레이어 3개
히든 레이어의 노드 수 : 10개, 20개, 20개
출력 노드 수 : 3개
https://www.r-bloggers.com/r-for-deep-learning-i-build-fully-connected-
neural-network-from-scratch/
93.
입력, 출력
입력 벡터: 길이 4
6.4, 2.8, 5.6, 2.2
출력 값
setosa : 0
versicolor : 1
virginica : 2
데이터 정의
training_set =tf.contrib.learn.datasets.base.load_csv_with_header( # 학습 데이타
filename="iris_training.csv",
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header( # 테스트 데이타
filename="iris_test.csv",
target_dtype=np.int,
features_dtype=np.float32)
# 실수 타입의 4 차원의 입력 백터
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
96.
데이터 파일
training_set =tf.contrib.learn.datasets.base.load_csv_with_header( # 학습 데이타
filename="iris_training.csv",
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header( # 테스트 데이타
filename="iris_test.csv",
target_dtype=np.int,
features_dtype=np.float32)
# 실수 타입의 4 차원의 입력 백터
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# 파일 iris_training.csv
120,4,setosa,versicolor,virginica
6.4,2.8,5.6,2.2,2
5.0,2.3,3.3,1.0,1
4.9,2.5,4.5,1.7,2
4.9,3.1,1.5,0.1,0
5.7,3.8,1.7,0.3,0
4.4,3.2,1.3,0.2,0
...
# 파일 iris_test.csv
30,4,setosa,versicolor,virginica
5.9,3.0,4.2,1.5,1
6.9,3.1,5.4,2.1,2
5.1,3.3,1.7,0.5,0
6.0,3.4,4.5,1.6,1
5.5,2.5,4.0,1.3,1
6.2,2.9,4.3,1.3,1
...
학습 실행
# 입력은training_set.data
# 출력은 training_set.target
# 모두 2000번 반복
classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000)
99.
결과 확인
# 입력은test_set.data
# 출력은 test_set.target
accuracy_score =
classifier.evaluate(x=test_set.data,y=test_set.target)["accuracy"]
print('Accuracy: {0:f}'.format(accuracy_score))
100.
결과 확인 -개별 데이터로
# 2개의 입력
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=float)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Predictions: {}'.format(str(y)))
101.
실행 결과
$ pythoniris.py
Accuracy: 0.966667
Predictions: [1, 1]




































































![파라매터 정의
learning_rate = 0.001 # 학습률
training_epochs = 100 # 학습 회수
batch_size = 100 # 배치 학습 갯수
n_hidden_1 = 15 # 히든레이어의 노드 수
n_input = 784 # 입력층의 노드수(img shape: 28*28)
n_classes = 10 # 출력층의 노드수 = 클래스 수(0-9 digits)
x = tf.placeholder("float", [None, n_input]) # 입력
y = tf.placeholder("float", [None, n_classes]) # 출력](https://image.slidesharecdn.com/ai-161223013443/75/Ai-82-2048.jpg)
![학습할 weigth와 bias
# 학습할 weigth와 bias
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'out': tf.Variable(tf.random_normal([n_hidden_1, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'out': tf.Variable(tf.random_normal([n_classes]))
}](https://image.slidesharecdn.com/ai-161223013443/75/Ai-83-2048.jpg)
![MLP 정의
# MLP 모델
def multilayer_perceptron(x, weights, biases):
# h = x * w + b
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
# h = relu(h)
layer_1 = tf.nn.relu(layer_1)
# o = h * w + b
out_layer = tf.matmul(layer_1, weights['out']) + biases['out']
return out_layer](https://image.slidesharecdn.com/ai-161223013443/75/Ai-84-2048.jpg)

![학습
with tf.Session() as sess: # tf.Session.run(op)로 실행시킨다
sess.run(init) # 변수들을 초기화 하고
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(training_epochs): # 정해진 학습 횟수 만큼
for i in range(total_batch): # 전체 데이터를 한번에 batch_size 개수만큼
batch_x, batch_y = mnist.train.next_batch(batch_size) # 학습시킬 데이터를 꺼내서
sess.run([optimizer, cost], feed_dict={x: batch_x, y: batch_y}) # 학습시킨다.](https://image.slidesharecdn.com/ai-161223013443/75/Ai-86-2048.jpg)








![데이터 정의
training_set = tf.contrib.learn.datasets.base.load_csv_with_header( # 학습 데이타
filename="iris_training.csv",
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header( # 테스트 데이타
filename="iris_test.csv",
target_dtype=np.int,
features_dtype=np.float32)
# 실수 타입의 4 차원의 입력 백터
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]](https://image.slidesharecdn.com/ai-161223013443/75/Ai-95-2048.jpg)
![데이터 파일
training_set = tf.contrib.learn.datasets.base.load_csv_with_header( # 학습 데이타
filename="iris_training.csv",
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header( # 테스트 데이타
filename="iris_test.csv",
target_dtype=np.int,
features_dtype=np.float32)
# 실수 타입의 4 차원의 입력 백터
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# 파일 iris_training.csv
120,4,setosa,versicolor,virginica
6.4,2.8,5.6,2.2,2
5.0,2.3,3.3,1.0,1
4.9,2.5,4.5,1.7,2
4.9,3.1,1.5,0.1,0
5.7,3.8,1.7,0.3,0
4.4,3.2,1.3,0.2,0
...
# 파일 iris_test.csv
30,4,setosa,versicolor,virginica
5.9,3.0,4.2,1.5,1
6.9,3.1,5.4,2.1,2
5.1,3.3,1.7,0.5,0
6.0,3.4,4.5,1.6,1
5.5,2.5,4.0,1.3,1
6.2,2.9,4.3,1.3,1
...](https://image.slidesharecdn.com/ai-161223013443/75/Ai-96-2048.jpg)
![분류기 정의
# 분류기 정의
# 입력층의 정의는 feature_columns로. 입력벡터는 4차원. 타입은 실수
# 히든 레이어 3개. 각 레이어의 노드수는 10, 20, 10
# 출력층의 노드는 3개. 분류한 클래스가 3개이다.
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")](https://image.slidesharecdn.com/ai-161223013443/75/Ai-97-2048.jpg)

![결과 확인
# 입력은 test_set.data
# 출력은 test_set.target
accuracy_score =
classifier.evaluate(x=test_set.data,y=test_set.target)["accuracy"]
print('Accuracy: {0:f}'.format(accuracy_score))](https://image.slidesharecdn.com/ai-161223013443/75/Ai-99-2048.jpg)
![결과 확인 - 개별 데이터로
# 2개의 입력
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=float)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Predictions: {}'.format(str(y)))](https://image.slidesharecdn.com/ai-161223013443/75/Ai-100-2048.jpg)
![실행 결과
$ python iris.py
Accuracy: 0.966667
Predictions: [1, 1]](https://image.slidesharecdn.com/ai-161223013443/75/Ai-101-2048.jpg)


![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)























![[논문리뷰] Data Augmentation for 1D 시계열 데이터](https://cdn.slidesharecdn.com/ss_thumbnails/20181204a-gistdataugwearableeegdkim-181212141033-thumbnail.jpg?width=640&height=640&fit=bounds)







![[모두의연구소] 쫄지말자딥러닝](https://cdn.slidesharecdn.com/ss_thumbnails/20160528-160529034614-thumbnail.jpg?width=640&height=640&fit=bounds)












![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)





![[신경망기초] 신경망의시작-퍼셉트론](https://cdn.slidesharecdn.com/ss_thumbnails/nn02-180318141341-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D2대학생세미나]lovely algrorithm](https://cdn.slidesharecdn.com/ss_thumbnails/d2lovelyalgrorithm-140827015148-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























