Download as PDF, PPTX















![#SAISML11 22
DataFrame
DataFrame
Feature transform
S3
"transform" : [
{
"type" : "Bucketize",
"input" : "ad_duration",
"output" : "ad_duration_bucket",
"thresholds" : [
10.0,
15.0,
20.0,
25.0,
30.0,
45.0,
75.0,
120.0
]
},
...
],
...
Feature transformation](https://image.slidesharecdn.com/08cyrilledubarryhanju-181011204225/85/Machine-Learning-for-AdTech-in-Action-with-Cyrille-Dubarry-and-Han-Ju-22-320.jpg)
![#SAISML11 23
DataFrame
DataFrame
RDD[LabeledPoint]
Feature transform
Feature vectorize
S3Feature vectorization
...,
"vectorize" : [
{
"type" : "ConstantVectorize",
"value" : 1.0
},
{
"type" : "HashVectorize",
"inputs" : [
"ad_duration_bucket",
...
],
"inputTypes" : ...,
],
"size" : 2145483000
}
],
"label" : {
"input" : "event_billable_dbl"
},
...](https://image.slidesharecdn.com/08cyrilledubarryhanju-181011204225/85/Machine-Learning-for-AdTech-in-Action-with-Cyrille-Dubarry-and-Han-Ju-23-320.jpg)
![#SAISML11 24
DataFrame
DataFrame
RDD[LabeledPoint]
Predictor
Feature transform
Feature vectorize
Model training
S3
S3
Online service
Model training
- Initial model
- Model seeding
...,
"initialModel" : {
"type" : "Logistic",
"intercept" : 0.0,
"slopes" : {
"type" : "Sparse",
"indices" : [
],
"values" : [
],
"length" : 2145483000
}
},
...](https://image.slidesharecdn.com/08cyrilledubarryhanju-181011204225/85/Machine-Learning-for-AdTech-in-Action-with-Cyrille-Dubarry-and-Han-Ju-24-320.jpg)
![#SAISML11 25
DataFrame
DataFrame
RDD[LabeledPoint]
Predictor
Feature transform
Feature vectorize
Model training
S3
S3
Online service
Model training
- Other settings
...,
"loss" : {
"type" : "LogisticLoss"
},
"regularization" : {
"type" : "L2",
"alpha" : 29.0,
...
},
"optimization" : {
"type" : "LBFGS",
"maxIterations" : 150,
"tolerance" : 1.0E-4
},
...](https://image.slidesharecdn.com/08cyrilledubarryhanju-181011204225/85/Machine-Learning-for-AdTech-in-Action-with-Cyrille-Dubarry-and-Han-Ju-25-320.jpg)






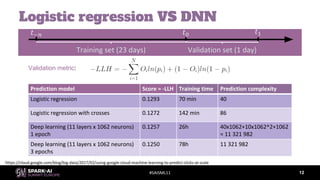
![#SAISML11
Predictor
Configuration of model scoring
Components
- Feature transform
- Feature vectorization
- Trained model
Same feature generation as in training
- Vectors are the same online and
offline
33
{
"transform" : [...],
"vectorize" : [...],
"model" : {
"type" : "Logistic",
"intercept" : -0.59580942,
"slopes" : {
"type" : "Sparse",
"indices" : [
5385, 6271, ...
],
"values" : [
-0.002536684,
0.026973965,
...
],
"length" : 2145483000
}
}
}](https://image.slidesharecdn.com/08cyrilledubarryhanju-181011204225/85/Machine-Learning-for-AdTech-in-Action-with-Cyrille-Dubarry-and-Han-Ju-33-320.jpg)
![#SAISML11
Online feature transform
34
case class PredictionKey private (values: Vector[Any], schema: Type) {
def add[T: Convert](name: String, t: T): PredictionKey = {...}
def value(idx: Int): Any = {...}
def get[T: Convert](name: String): T = {...}
def get[T: Convert](idx: Int): T = {...}
}](https://image.slidesharecdn.com/08cyrilledubarryhanju-181011204225/85/Machine-Learning-for-AdTech-in-Action-with-Cyrille-Dubarry-and-Han-Ju-34-320.jpg)






The document discusses the implementation and challenges of machine learning in the ad tech industry, focusing on real-time bidding (RTB) workflows and model training methodologies. It highlights the use of various algorithms, including logistic regression and deep learning, detailing the machine learning stack developed to address specific needs not met by existing frameworks. Additionally, it emphasizes the importance of feature transformation, model deployment, and the evaluation of models through offline experiments.























































































