Download as PDF, PPTX






![DNNの動向(4/8)
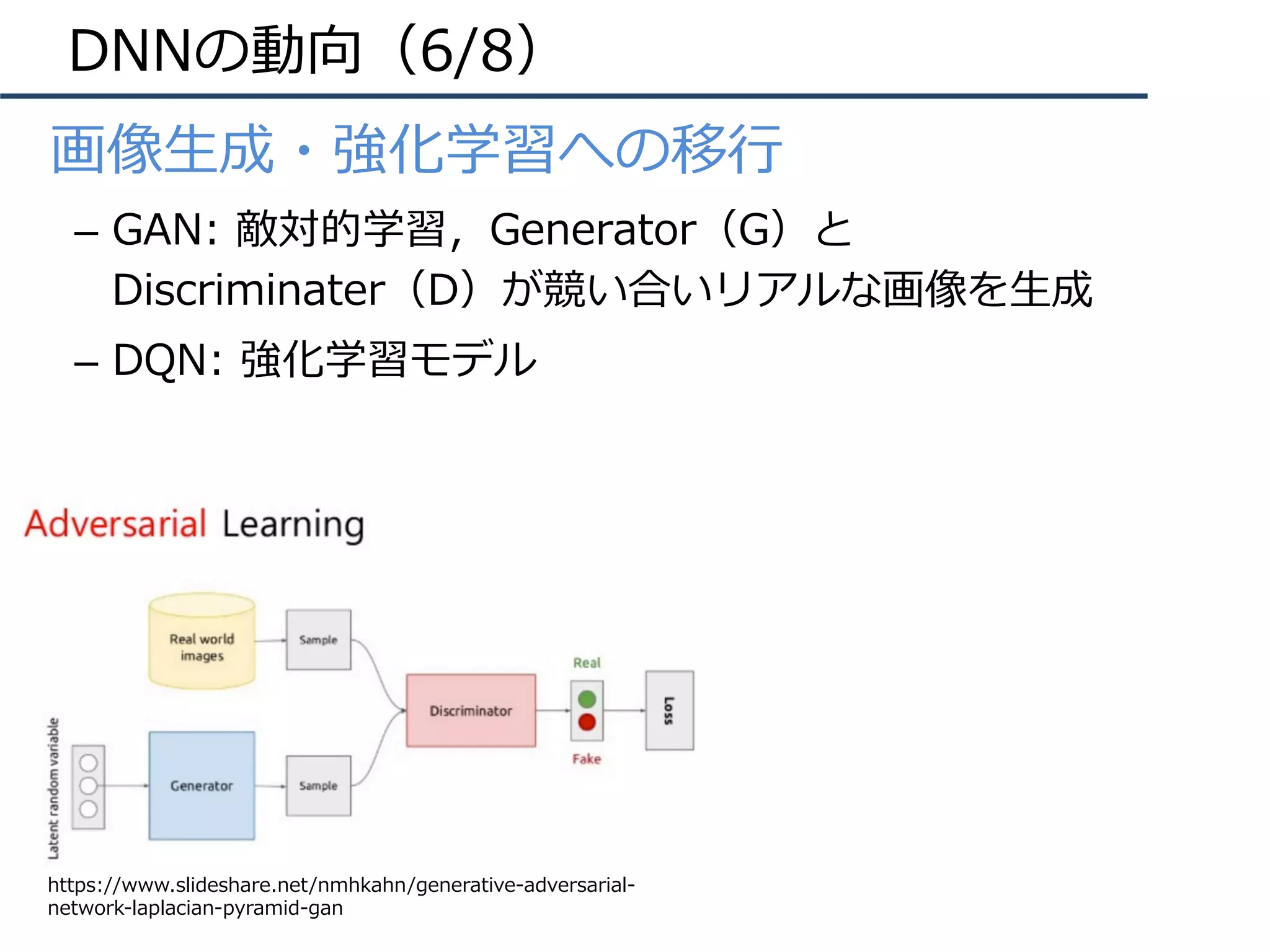
• 構造の深化
– 2014年頃から「構造をより深くする」ための知⾒が整う
– 現在(主に画像識別で)主流なのはResidual Network
AlexNet [Krizhevsky+, ILSVRC2012]
VGGNet [Simonyan+, ILSVRC2014]
GoogLeNet [Szegedy+, ILSVRC2014/CVPR2015]
ResNet [He+, ILSVRC2015/CVPR2016]
ILSVRC2012 winner,DLの⽕付け役
16/19層ネット,deeperモデルの知識
ILSVRC2014 winner,22層モデル
ILSVRC2015 winner, 152層!(実験では103+層も)](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-7-2048.jpg)
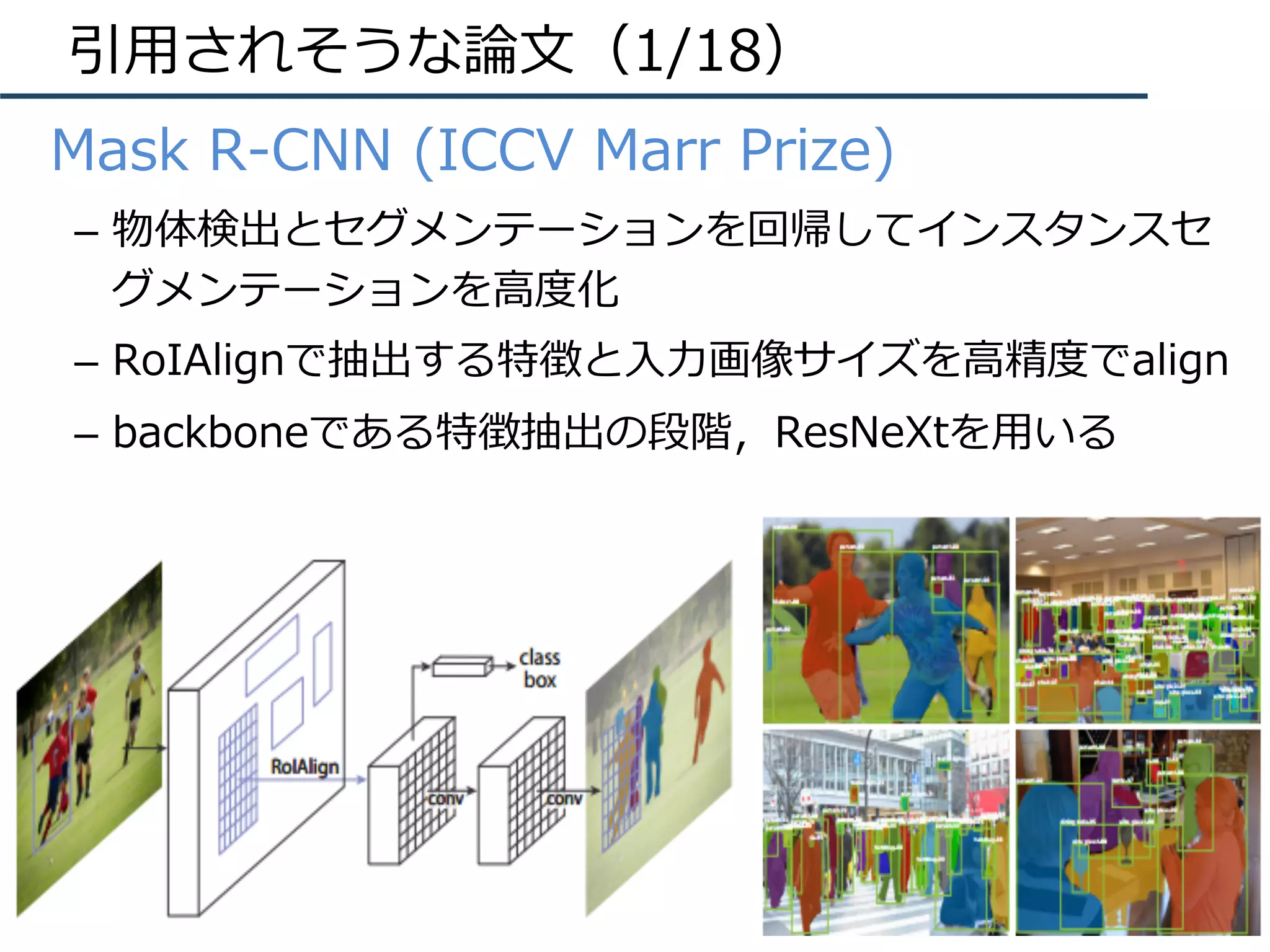
![DNNの動向(5/8)
• 他タスクへの応⽤(画像認識・動画認識)
– R-CNN: 物体検出
– FCN: セマンティックセグメンテーション
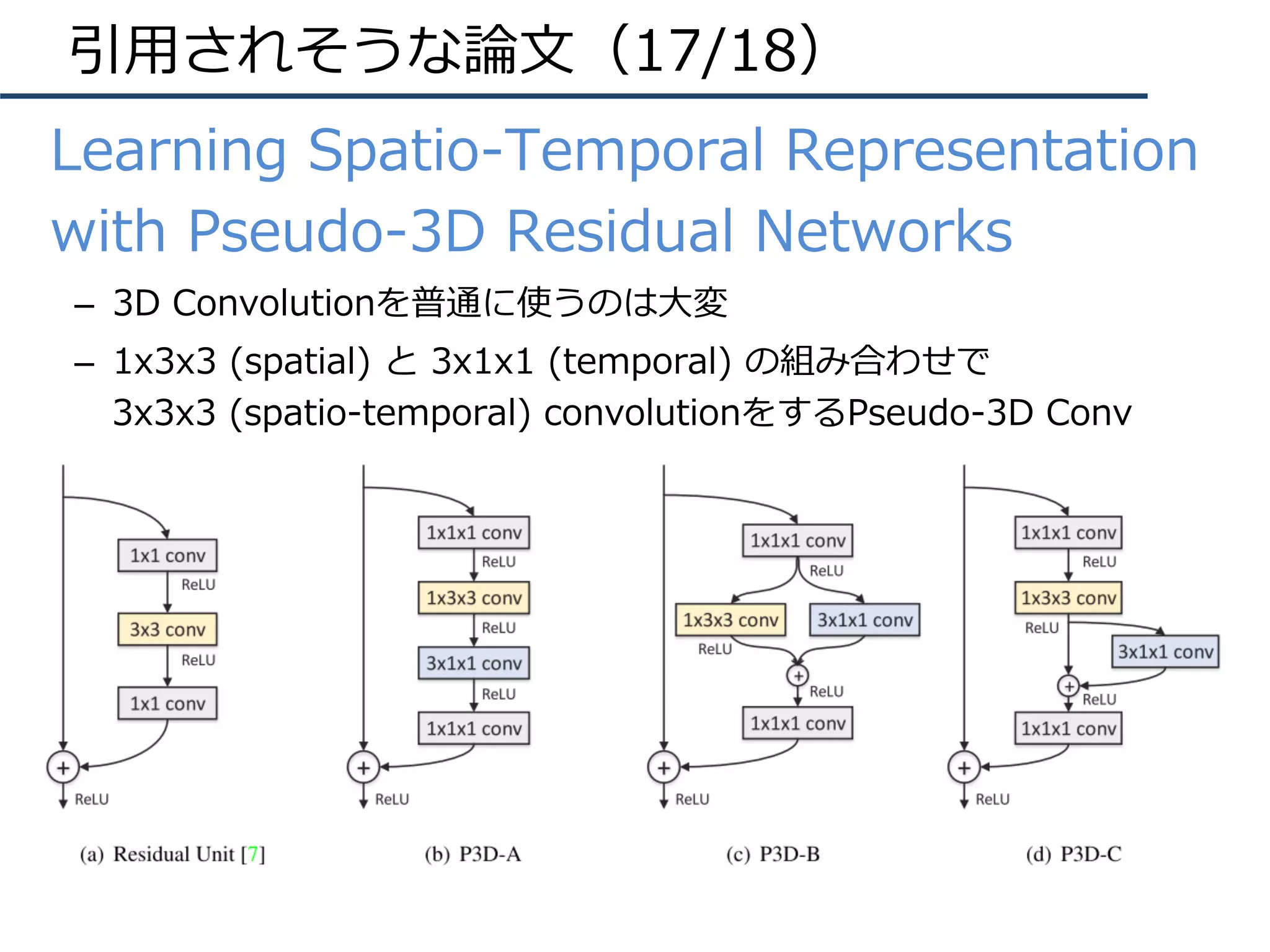
– CNN+LSTM: 画像説明⽂
– Two-Stream CNN: 動画認識
Person
Uma
Show and Tell [Vinyals+, CVPR15]
R-CNN [Girshick+, CVPR14]
FCN [Long+, CVPR15]
Two-Stream CNN [Simonyan+, NIPS14]](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-8-2048.jpg)


























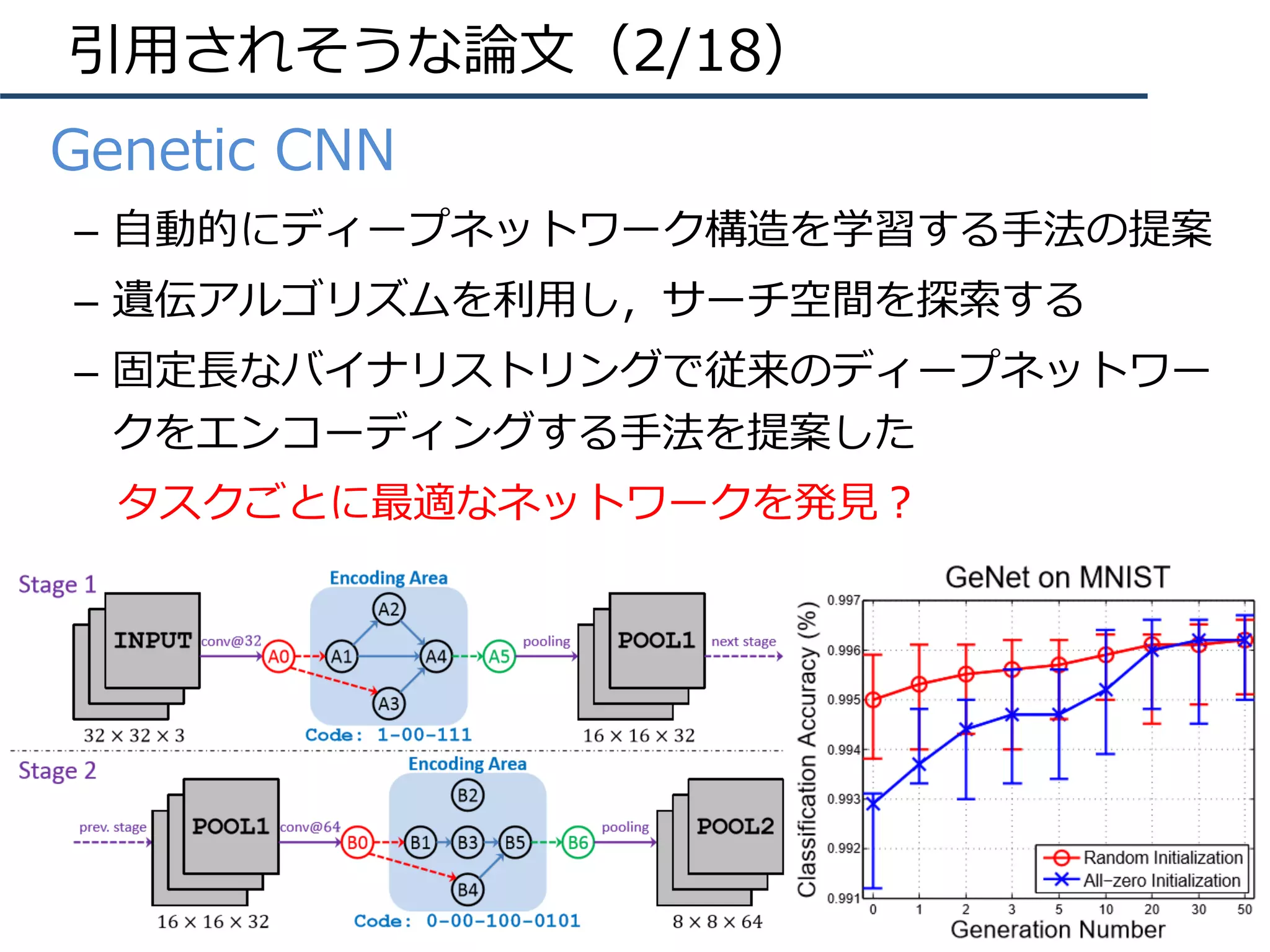
























![今後の⽅針(2/3)
• 研究のグランドデザイン(普遍的に重要)
– ICCV 2017 Best Paper (Marr Prize)より
– Kaimingさんや研究グループ員は初めからグランドデザイ
ン(⼤きな地図)がを共有していて,⾃分がいる場所/進む
べき⽅向が直感的に分かっている(ように⾒える)
– グランドデザイン例:位置・領域・意味を同時に推定
• SPP [TPAMI15]:任意の領域で特徴抽出
• Faster R-CNN [NIPS15]:候補領域+物体識別をEnd-to-End処理
• Residual Learning [CVPR16]:構造をより深く,特徴を先鋭化
• Mask R-CNN [ICCV17]:グランドデザインを達成
– さらに,Sub-ThemeやSub-IssueをMSR/FAIRの優秀なイ
ンターン⽣と研究
BestPaper!
BestPaper!](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-65-2048.jpg)












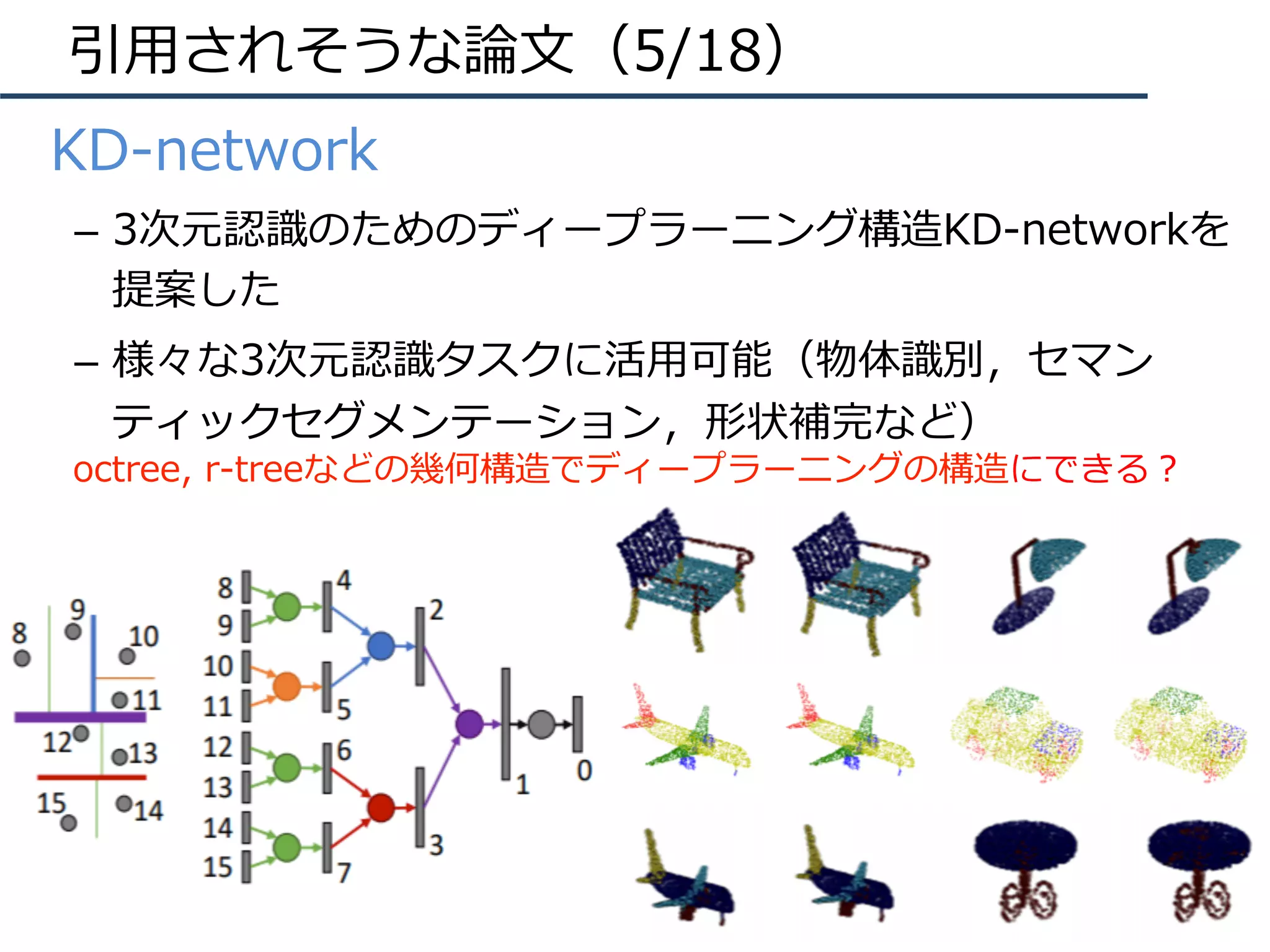
![Jacob Walker, Kenneth Marino, Abhinav Gupta, Martial Hebert, “The Pose
Knows: Video Forecasting by Generating Pose Futures”, in ICCV, 2017.
【11】
Keywords: GAN, VAE, Pose Generation
新規性・差分
概要
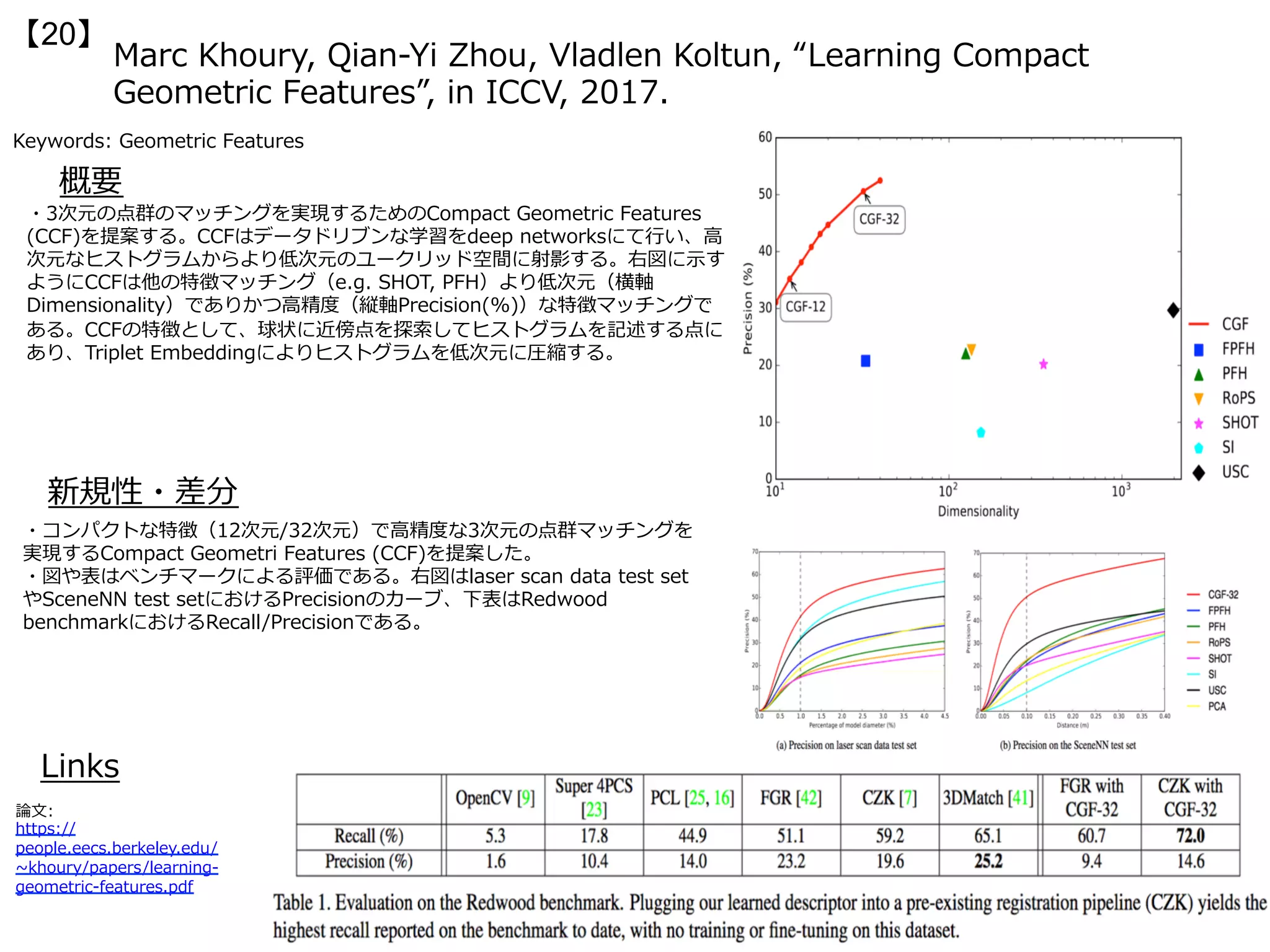
・画像⽣成の枠組みを⽤いて、⼈物姿勢の予測結果を⽣成するという⼿法を提案する。右図が
姿勢を予測する枠組みであり、(a)は⼊⼒のRGB画像、(b)は任意の⼿法により推定された⼈物
姿勢、(c)は予測された⼈物姿勢、(d)は予測された⼈物姿勢を基にして⽣成された未来のビデ
オである。本論⽂ではVAEやGANを⽤いた⽣成モデルを構成する。右下の図は全体のフローを
⽰している。基本的には過去の特徴記述(Past Encoder; CNN (AlexNet) + LSTM)、未来
の⼈物姿勢予測(Future Decoder; Pose-VAE)、最後に動画⽣成(Video Generator;
Pose-GAN)という形式になっている。
・画像全体よりも限られた特徴空間である「姿勢の予測」というもの
をベースにして動画⽣成を⾏うとより鮮明なモーションを推定するこ
とに成功する。
・従来法のVideoGAN[Vondrick+, NIPS16]よりもリアルな動画⽣成
が実現している。詳細はビデオ(
http://www.cs.cmu.edu/%7Ejcwalker/POS/selected1.html )を
参照。
Links
論⽂: https://arxiv.org/pdf/1705.00053.pdf
プロジェクト :
http://www.cs.cmu.edu/~jcwalker/POS/POS.html
GAN-Zoo :
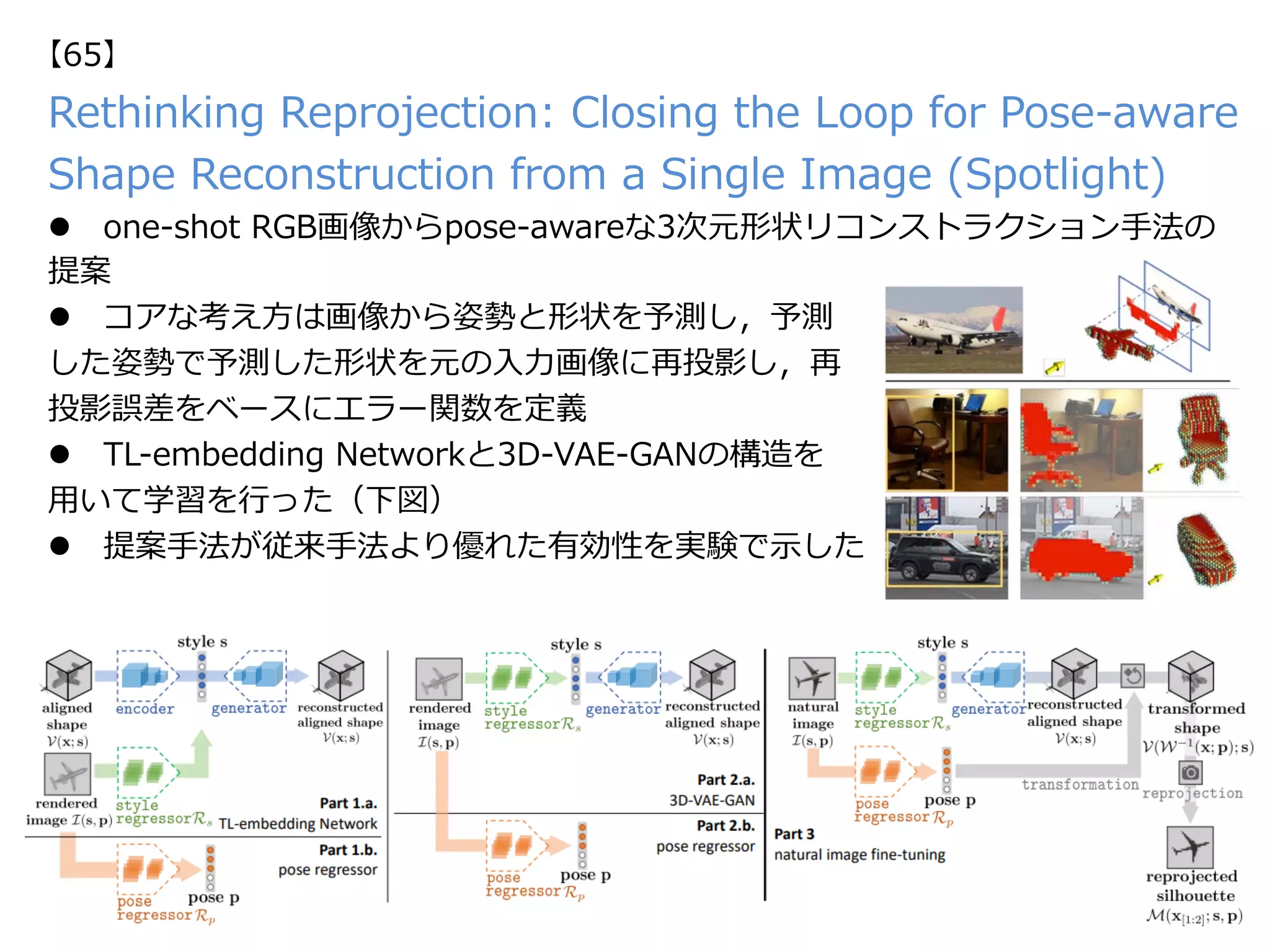
https://github.com/hindupuravinash/the-gan-zoo](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-78-2048.jpg)
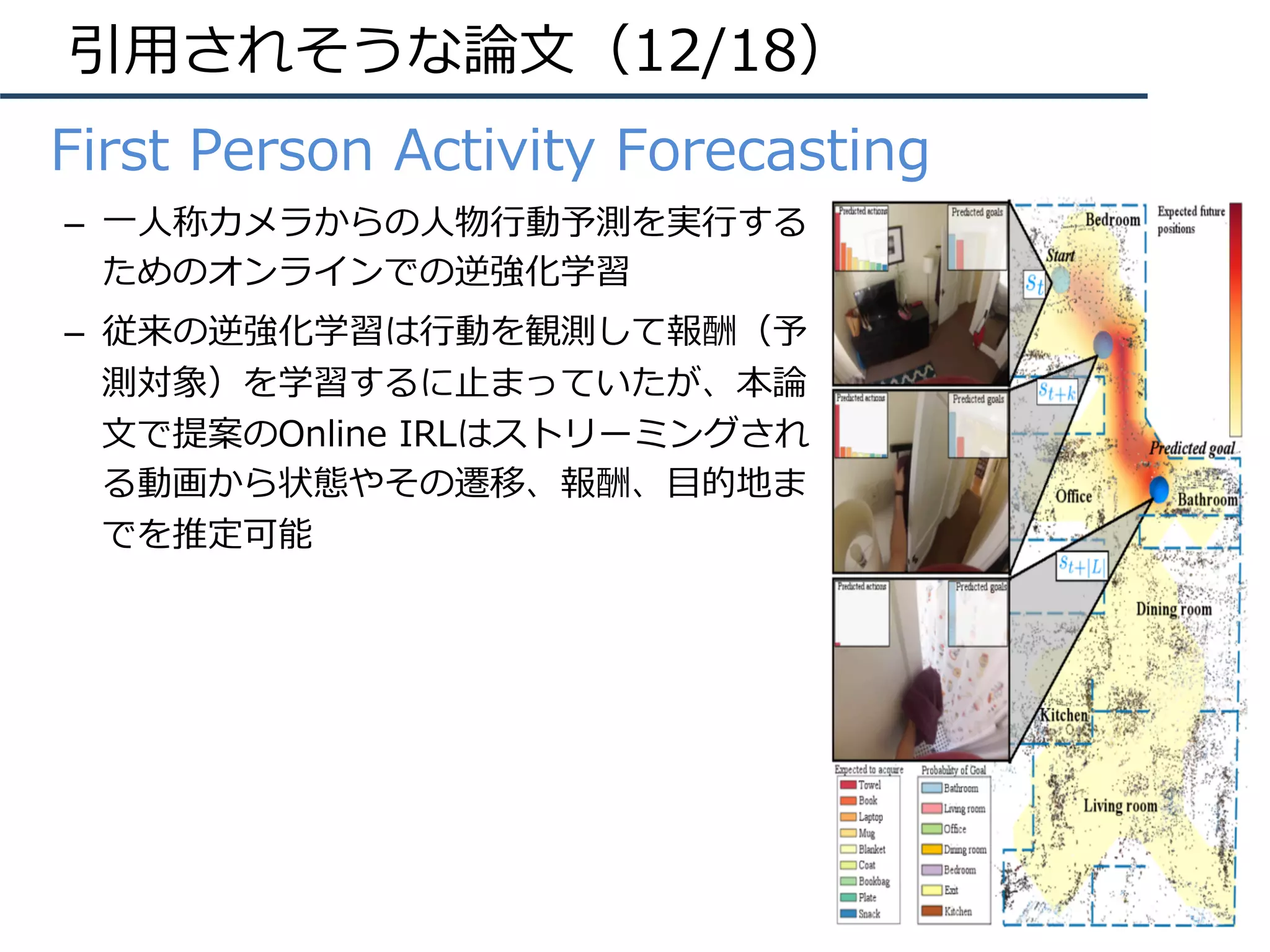
![Nicholas Rhinehart, Kris M. Kitani, “First-Person Activity Forecasting with
Online Inverse Reinforcement Learning”, in ICCV, 2017. (Oral)
【13】
Keywords: First-Person View, Activity Forecasting
新規性・差分
概要
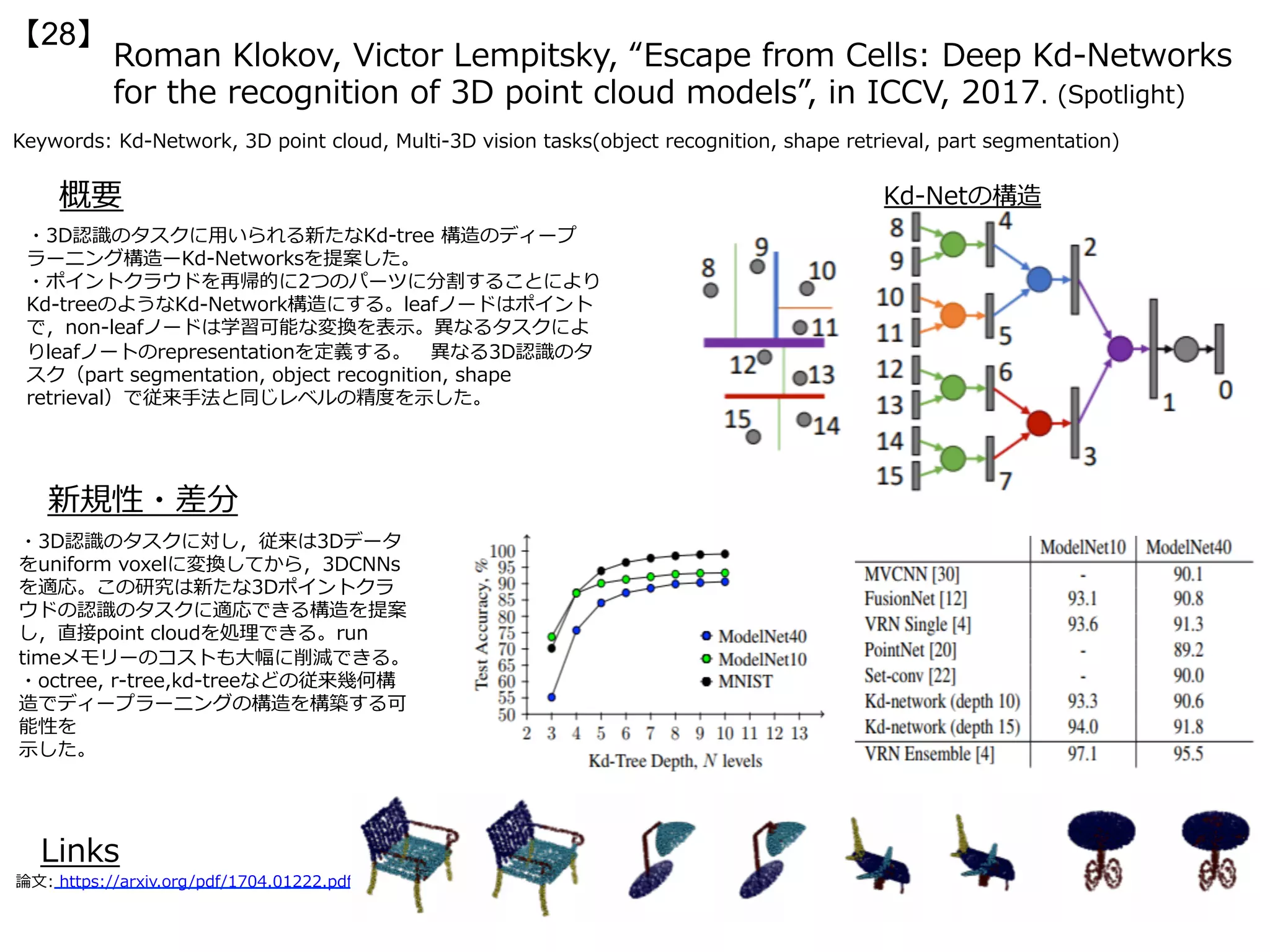
・⼀⼈称カメラからの⼈物⾏動予測を実⾏するためのオンラインでの逆強化学習(Online
Inverse Reinforcement Learning (IRL))を提案する。従来の逆強化学習は⾏動を観測して
報酬(予測対象)を学習するに⽌まっていたが、本論⽂で提案のOnline IRLはストリーミン
グされる動画から状態やその遷移、報酬、⽬的地までを推定可能である。
定義される状態は3次元位置(x,y,z)や把持している物体O、過去に⼈物が位置していたシーン
Hを含む(sは s = [x, y, z, o_1, …, o_|o|, h1, …, h_|K|] で⽰される)。そこにActions
a(やTransition Function T: (s, a) -> sʼ)を含めて報酬関数 R(s, a; Θ) が定義される。状
態や⾏動が観測されていくと次の状態遷移、報酬、⽬的地を予測する。
・⼀⼈称カメラにおいて初めてオンライン
で逆強化学習を⾏い、状態遷移、報酬、⽬
的地までを推定した。
・右の表はゴールの予測精度、右下の表は
ゴール発⾒と⾏動認識の結果である。
Links
論⽂
https://arxiv.org/pdf/
1612.07796.pdf
プロジェクト
http://www.cs.cmu.edu/
~nrhineha/darko.html
ビデオ
https://www.youtube.com/
watch?v=rvVoW3iuq-s
上の図はVisualSLAMにより観測された空間や
⼀⼈称カメラからの映像である。把持してい
る物体や常時観測する⼈物⾏動により、予測
対象を当てる。](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-80-2048.jpg)
![Congqi Cao, Yifan Zhang, Yi Wu, Hanqing Lu, Jian Cheng, “Egocentric
Gesture Recognition Using Recurrent 3D Convolutional Neural Networks
with Spatiotemporal Transformer Modules”, in ICCV, 2017. (Spotlight)
【14】
Keywords: 3D Convolution, Egocentric Video, Gesture Recognition
新規性・差分
概要
・⼀⼈称ビジョンのジェスチャー認識において、Recurrent 3D Convolutional Networks
を⽤いて精度向上に取り組み、End-to-Endの学習を成功させた。特に、Spatio-Temporal
Transformer Module (STTM)により時空間的に隣接する3次元の特徴マップに対して変換
を⾏い、3次元のhomographyを考慮して特徴間の類似性を強める。⼿法を検証するため、
既存データのみならずジェスチャー認識に関するDBを新規に提案した。同データには83
ジェスチャー、24,000枚のRGB-D情報、50サブジェクト、6シーンを撮影した、という特
徴がある。
・従来のSpatial Transformer [11]を3次
元に拡張して、時系列変換を⾏うSTTMを
提案
・⼀⼈称ビジョンに現れるHomographyの
変化に対応
・新規にジェスチャー認識を⾏うデータ
セットを考案した
Links
論⽂:
http://www.nlpr.ia.ac.cn/iva/yfzhang/
datasets/iccv2017_cqcao.pdf 表は提案データセットでの実験結果。Homographyの
考慮や3DConvを再帰的ネットで特徴強化を⾏った結
果、SoTAな精度で認識した。](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-81-2048.jpg)















![Shizhan Zhu, Sanja Fidler, Raquel Urtasun, Dahua Lin, Chen Change
Loy, “Be Your Own Prada: Fashion Synthesis with Structural
Coherence”, in ICCV,2017 .
【33】
Keywords: Generative Adversarial Networks, Image Retrival
新規性・差分
概要
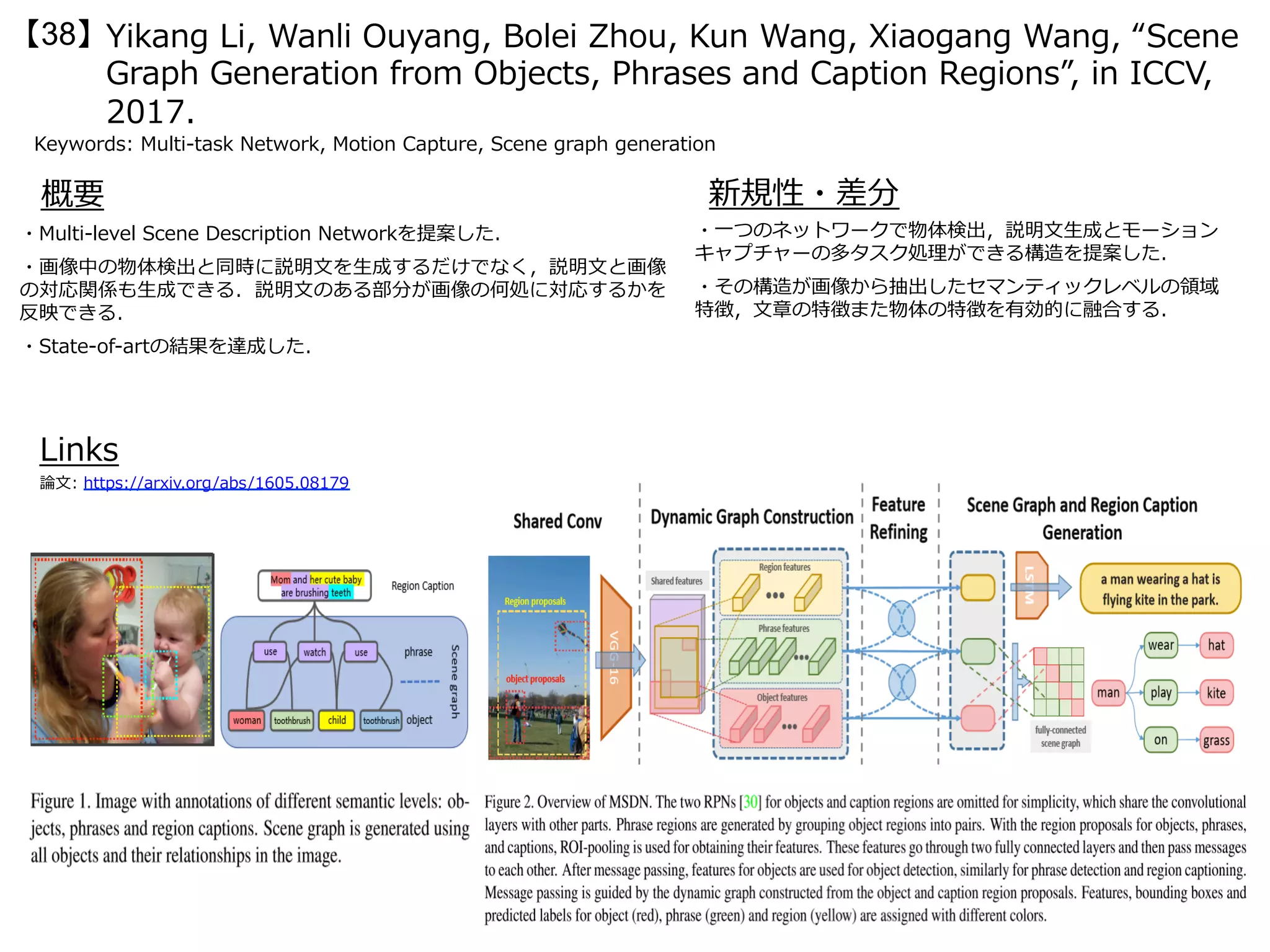
・GANを⽤いた服装の合成画像⽣成の研究.合成したい
服装の⽂章を⼊⼒内容に沿った服装を⽣成し,⼊⼒画像中
の⼈物の姿勢に沿ってレンダリングする.79K枚分の服装
画像の⽂章記述を収集し,DeepFashionデータセット[8]
を拡張した.
・評価実験では,合成データを⽤いたファッションアイテ
ム検索およびアンケート調査といった定量的・定性的評価
を⾏い、両⽅でベースラインを上回った.
・⼈物の姿勢を保持したままでの服装の合成を実現した.
Fashion GANの提案: 2種類のGANを⽤いている.まず初め
に,服装画像および⽂章を⼊⼒し, Generatorからセグメ
ンテーションマップ S が⽣成される.次に⽣成したセグメ
ンテーションマップ S に基づいて,もう⼀⽅のGANによっ
て⽣成した服装(テクスチャ)をレンダリングしていく.
Links
論⽂:
https://www.cs.toronto.edu/~urtasun/publications/
zhu_etal_iccv17.pdf
プロジェクト: http://mmlab.ie.cuhk.edu.hk/projects/FashionGAN/
(上) Fashion GANのフレームワーク:
(中央) 定量的評価結果: ⽣成画像によ
るファッションアイテム検索の精度
(下) 定性的評価結果: ⼈による評価
結果.ランクが⾼いほど不⾃然な合成
画像](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-100-2048.jpg)













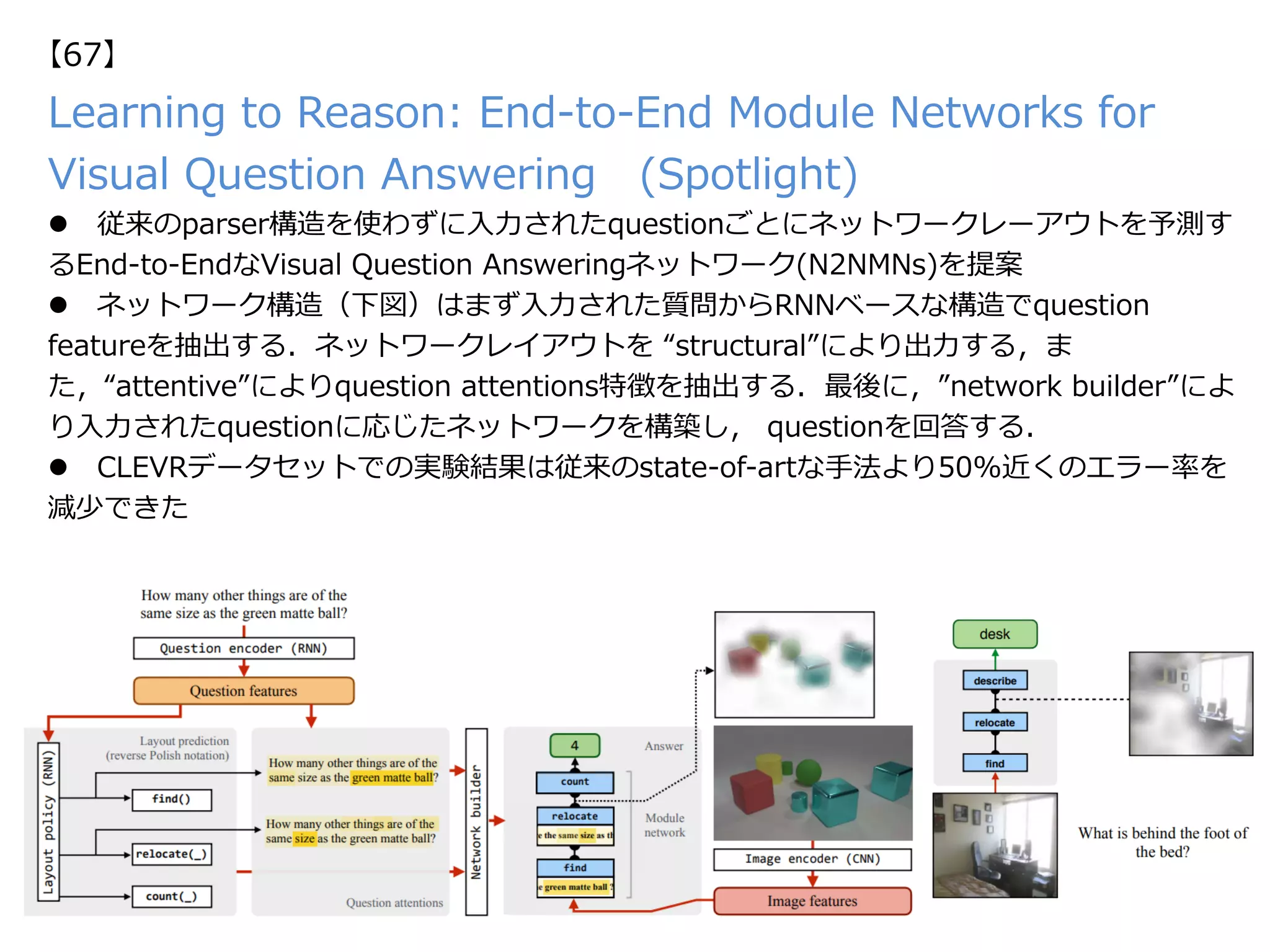
![Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, Juan Carlos Niebles,
“Dense-Captioning Events in Videos”, in ICCV, 2017.
【49】
Keywords: Video Captioning, Dense Captioning, 3D Convolution
新規性・差分
概要
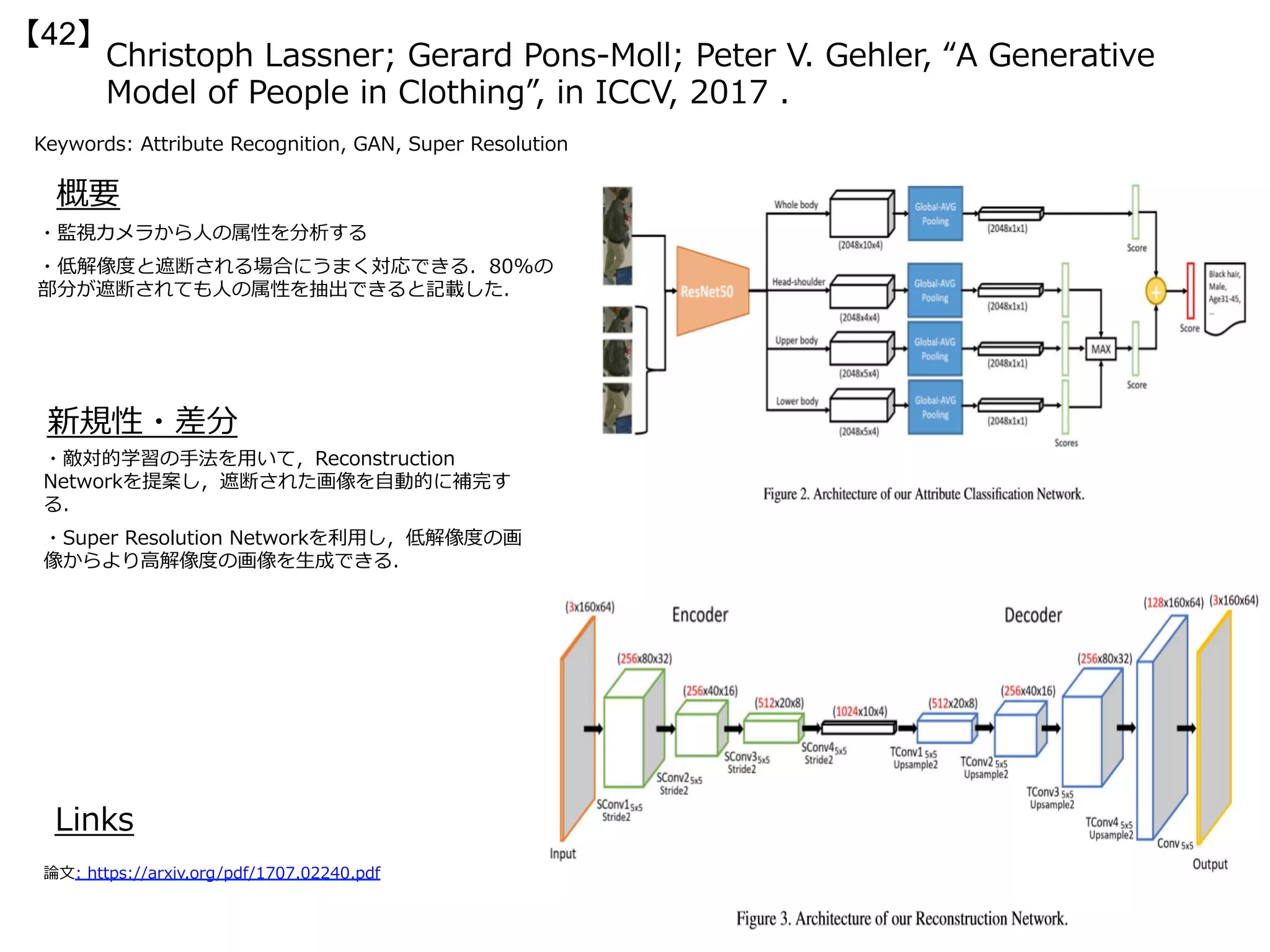
・動画に対してのDenseCaptioning [Johnson+, CVPR2016]を実
⾏した。同タスクはActivityNet Challengeのタスクのひとつにも取
り上げられており、849時間に及ぶ20Kのビデオ、トータルで100k
の動画キャプショニングが与えられている。特徴量はC3Dベースで
抽出(ActivityNetのHPからDL可能、fc7の4096-d特徴をPCAによ
り500-dに圧縮
http://activity-net.org/challenges/2016/
download.html#c3d)、フレーム単位の候補セグメントを抽出
し、キャプショニングモジュールに⼊⼒する。同モジュールでは候
補領域の開始・終了・Hidden Representationを⼊⼒としてC3D
fc7+LSTMにより動画のキャプショニングを実⾏。
・動画に対するキャプショニング⼿法Dense-Captioning
Events in Videosを提案
・ActivityNetのビデオキャプショニングタスクにてベン
チマークを⾏った結果、State-of-the-artな結果を実現
Links
論⽂: https://arxiv.org/pdf/1705.00754.pdf
プロジェクト :
http://cs.stanford.edu/people/ranjaykrishna/
densevid/
116](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-116-2048.jpg)

![Mohammadreza Zolfaghari, Gabriel L. Oliveira, Nima Sedaghat, Thomas
Brox, “Chained Multi-stream Networks Exploiting Pose, Motion, and
Appearance for Action Classification and Detection”, in ICCV, 2017.
【52】
Keywords: 3D CNN, Multi-stream convnet, Action Recognition
新規性・差分
概要
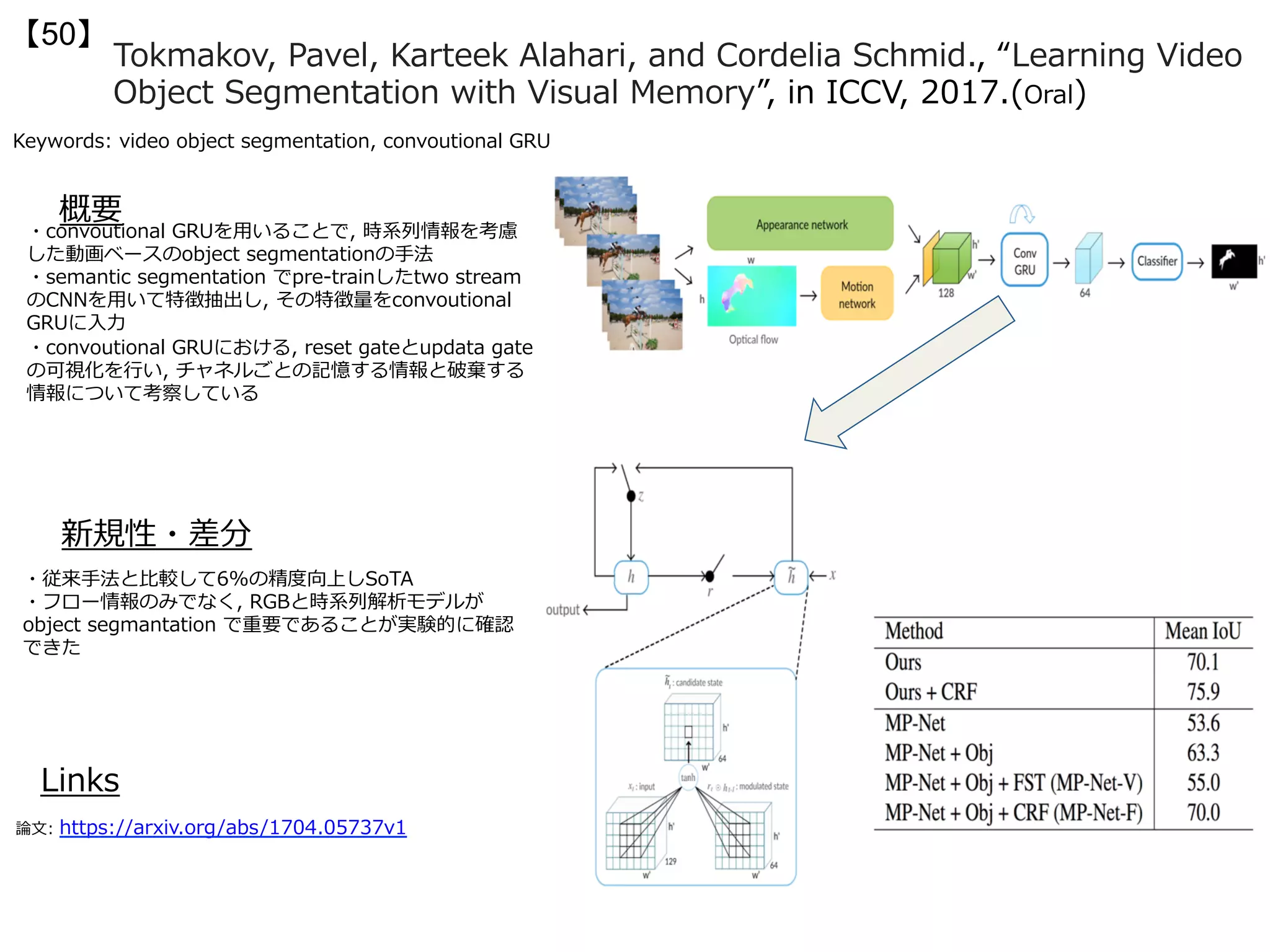
・⼈物⾏動認識に対して、複数のモダリティ(Pose, Optical Flow, RGB)の⼊⼒を適⽤す
る。連続的な⼿がかりを加えて総合的に判断するためにMarkov chain modelを適⽤する。
姿勢推定にはFat-Net[27], 3D-CNNにはC3D[37]、オプティカルフローは基本的にTwo-
stream CNNを参考にした。Chained Multi-Stream 3D-CNNは後段にロスを伝えていく、
各⼯程で誤差学習ができるというところがミソである。Chained Multi-Stream 3D-CNN
の出⼒は後段に伝え、全結合層を経て次の出⼒が⾏われる。
・HMDB51(69.7%), J-HMDB(76.1%), NTU
RGB+D(80.8%)にて識別率、UCF101
(38.0%@IoU0.3)やJ-HMDB(75.53%@IoU0.5)
にて⾏動検出率がstate-of-the-art
・Markov ChainのOptical Flow, Pose, RGBの順
番は全通りを探索してもっとも良い順番にした
・Poseのモダリティによる⾏動識別では
55.7%@UCF101, 40.9%@HMDB51,
47.1%@J-HMDBであった
Links
論⽂: https://arxiv.org/pdf/1704.00616.pdf
Chained Multi-Stream
3D-CNN。上から順列に
Pose, Optical Flow, RGB
と連なっている。下の階層
は上の階層から情報を受け
取り出⼒を⾏う。ロスであ
るY_poseやY_ofは学習に
は使⽤され、最終的な出⼒
であるY_rgbがラベルの推
定には使⽤される。](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-119-2048.jpg)


![Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaolei Huang,
Xiaogang Wang, Dimitris Metaxas, “StackGAN: Text to Photo-realistic
Image Synthesis with Stacked Generative Adversarial Networks” , in
ICCV, 2017.(Oral)
【56】
Keywords: stacked GAN
新規性・差分
概要
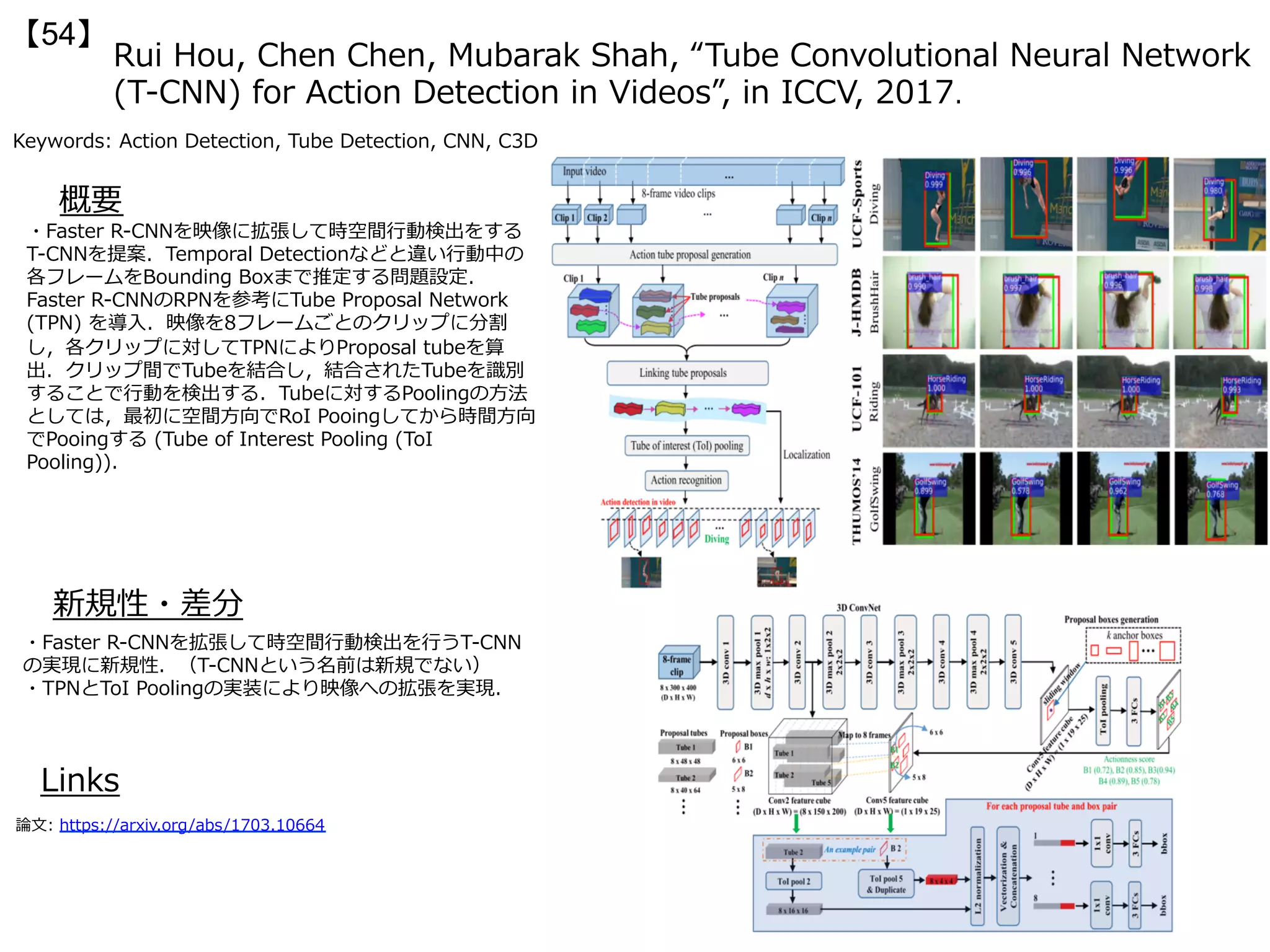
・Generative Adversarial Network(GAN)を2段階にス
タッキングすることで、⽣成する画像をよりリアルにし
た。ステージ1では⼤まかな形状や⾊のつながりを⽣成す
る低解像の画像が⽣成され、ステージ2ではステージ1の
結果(やテキストによるキャプション)を⼊⼒として写真
に近いリアルな画像を出⼒する。
・学習済みの⽣成モデルはテキストを⼊⼒として画像を出
⼒するモデルになった(おそらく初めて)
・256x256, 128x128 [pixel]の画像出⼒に関してState-
of-the-Art。CUB(28.47%改善)や
Oxford-102(20.30%改善)データセットに対して実験
を⾏った
Links
論⽂:
https://arxiv.org/pdf/
1612.03242.pdf
テキストによ
る⼊⼒をベー
スとして、2
ステージの学
習を⾏う。ス
テージ1で出
⼒された画像
はステージ2
の⼊⼒として
扱われる。ス
テージ1では
ラフだった低
解像画像が、
ステージ2で
は⾼解像な画
像に変換され
ている。](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-123-2048.jpg)




![“A Generative Model of People in Clothing”, in ICCV2017.
【62】
Keywords:GAN,VAE, semantic segmentation
新規性・差分
概要
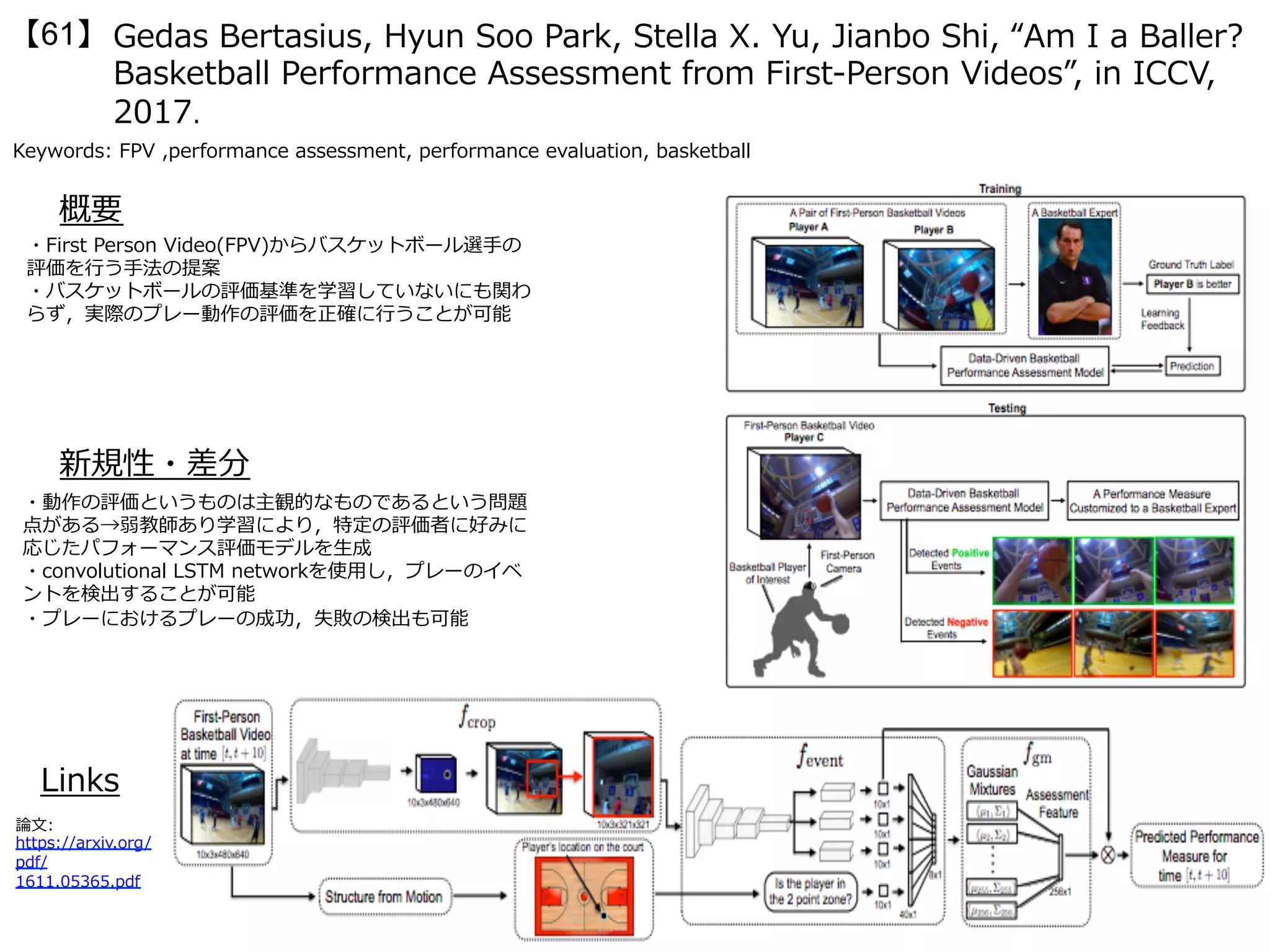
・服を着た⼈の3Dモデルは,布の物理的パラメータや⾝体と
⾐服との相互作⽤が課題であり,⼈間の⼊⼒が必須で⼿間が
かかる.本論⽂では別のアプローチとして3Dではなく2Dの
画像ベースのモデル学習とモデルの⾃動⽣成を提案する.⾐
服と⾝体の姿勢との対応を明らかにさせるために,データ
セットと⾝体モデルとの最適化,2段階の⽣成ステップを⾏
うClothNetを提案している.
・Chictopia10Kデータセット[1]とSMPLボディモデルをフィッティン
グさせ,データセットとして強化
・2段階の生成タスク
(1)姿勢ごとの服と身体の部位によるセグメンテーション
(2)セグメンテーションによるテクスチャ予測から,正確な人の外
観モデルを生成(256x256の高解像度)
Links
論⽂:
http://openaccess.thecvf.com/content_ICCV_2017/papers/
Lassner_A_Generative_Model_ICCV_2017_paper.pdf
・(左)SMPLモデルと(右)生成例
(a)基本的にはVAEの構造(lsm) (b)conditionalを導入したthe conditional sketch
module consists of a conditional variational auto-encoder(csm)
(c)画像から画像への変換ネットワーク(生成ではなく変換で,高解像度を達成)
論文中では(a)+(c)をClothNet-full (b)+(c)をClothNet-bodyとしている
1行目-提案手法のユーザー評価
2行目-gland truthのユーザー評価](https://image.slidesharecdn.com/iccv17finalize-171029152601/75/ICCV-2017-129-2048.jpg)

























ICCV 2017 ( http://iccv2017.thecvf.com/ )の参加速報を書きました。合計で約160ページあります。 この資料には下記の項目が含まれています。 ・DNNの概要(DNN以前の歴史や最近の動向) ・ICCV 2017での動向や気付き ・これから引用されそう(流行りそう)な論文 ・フォーカスすべき研究分野 ・今後の方針 ・論文まとめ(約90本あります) cvpaper.challengeはコンピュータビジョン分野の「今」を映す挑戦です。論文読破・まとめ・アイディア考案・議論・実装・論文執筆(・社会実装)に至るまで広く取り組み、あらゆる知識を共有します。 https://sites.google.com/site/cvpaperchallenge/








![[DL輪読会]Knowing When to Look: Adaptive Attention via A Visual Sentinel for Im...](https://cdn.slidesharecdn.com/ss_thumbnails/20180420dlhacksseki-180420000509-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)


