Download as PDF, PPTX





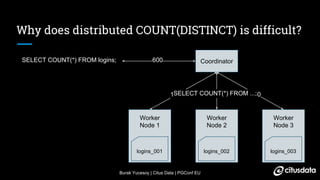
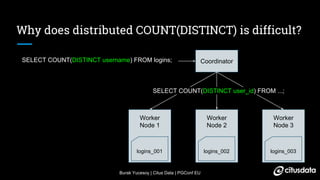













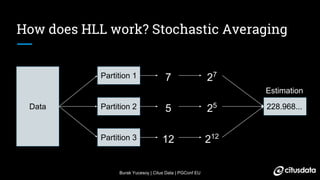








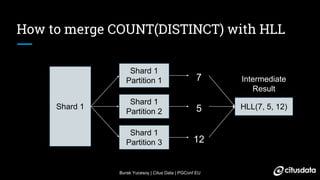
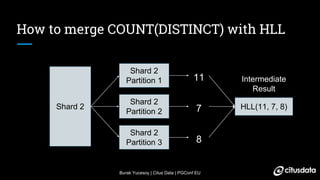



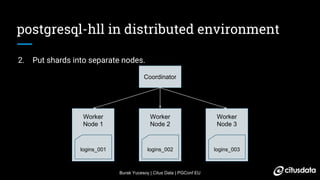


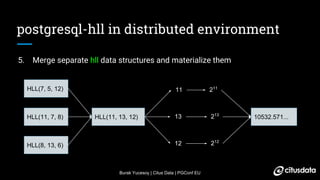



The document discusses distributed counting of distinct elements in PostgreSQL using HyperLogLog (HLL), an approximation algorithm that estimates the cardinality of data efficiently with low memory usage. It outlines the challenges of distributed counting, including data too large for a single machine's memory, and presents HLL as a scalable solution for approximating distinct counts with mathematically proven error bounds. The process involves hashing data, observing rare bit patterns, and taking stochastic averages to provide accurate estimations while minimizing memory footprint.


































































