Downloaded 40 times











![mv ′ + kv = f (t) + mg.
This is an example of a “first order differential equation in v”, which means
that at most first order derivatives of the unknown function v = v(t) occur.
In fact, you have probably seen solutions to this in your calculus classes, at
least when f (t) = 0 and k = 0. In that case, v ′ (t) = g and so v(t) = g dt =
gt + C. Here the constant of integration C represents the initial velocity.
Differential equations occur in other areas as well: weather prediction (more
generally, fluid-flow dynamics), electrical circuits, the heat of a homogeneous
wire, and many others (see the table below). They even arise in problems
on Wall Street: the Black-Scholes equation is a PDE which models the pric-
ing of derivatives [BS-intro]. Learning to solve differential equations helps
understand the behaviour of phenomenon present in these problems.
phenomenon description of DE
weather Navier-Stokes equation [NS-intro]
a non-linear vector-valued higher-order PDE
falling body 1st order linear ODE
motion of a mass attached Hooke’s spring equation
to a spring 2nd order linear ODE [H-intro]
motion of a plucked guitar string Wave equation
2nd order linear PDE [W-intro]
Battle of Trafalger Lanchester’s equations
system of 2 1st order DEs [L-intro], [M-intro], [N-intro]
cooling cup of coffee Newton’s Law of Cooling
in a room 1st order linear ODE
population growth logistic equation
non-linear, separable, 1st order ODE
Undefined terms and notation will be defined below, except for the equations
themselves. For those, see the references or wait until later sections when
they will be introduced2 .
Basic Concepts:
Here are some of the concepts to be introduced below:
2
Except for the Navier-Stokes equation, which is more complicated and might take us
too far afield.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-11-320.jpg)




![x′ = f (t, x), x(a) = c,
where f (t, x) is a given function of two variables, and a, c are given constants.
The equation x(a) = c is the initial condition.
Under mild conditions of f , an IVP has a solution x = x(t) which is unique.
This means that if f and a are fixed but c is a parameter then the solution
x = x(t) will depend on c. This is stated more precisely in the following
result.
Theorem 1.1.1. (Existence and uniqueness) Fix a point (t0 , x0 ) in the plane.
Let f (t, x) be a function of t and x for which both f (t, x) and fx (t, x) = ∂f∂x
(t,x)
are continuous on some rectangle
a < t < b, c < x < d,
in the plane. Here a, b, c, d are any numbers for which a < t0 < b and
c < x0 < d. Then there is an h > 0 and a unique solution x = x(t) for which
x′ = f (t, x), for all t ∈ (t0 − h, t0 + h),
and x(t0 ) = x0 .
This is proven in §2.8 of Boyce and DiPrima [BD-intro], but we shall not
prove this here. In most cases we shall run across, it is easier to construct
the solution than to prove this general theorem.
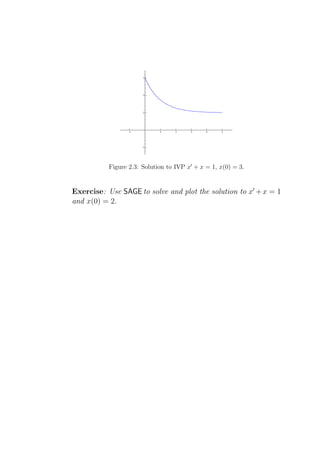
Example 1.1.5. Let us try to solve
x′ + x = 1, x(0) = 1.
The solutions to the DE x + x = 1 which we “guessed at” in the previous
′
example, x(t) = 1, satisfies this IVP.
Here a way of finding this slution with the aid of the computer algebra
system SAGE :
SAGE
sage: t = var(’t’)
sage: x = function(’x’, t)
sage: de = lambda y: diff(y,t) + y - 1
sage: desolve_laplace(de(x(t)),["t","x"],[0,1])
’1’](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-16-320.jpg)
![(The command desolve_laplace is a DE solver in SAGE which uses a special
method involving Laplace transforms which we will learn later.) Just as an
illustration, let’s try another example. Let us try to solve
x′ + x = 1, x(0) = 2.
The SAGE commands are similar:
SAGE
sage: t = var(’t’)
sage: x = function(’x’, t)
sage: de = lambda y: diff(y,t) + y - 1
sage: desolve_laplace(de(x(t)),["t","x"],[0,2])
’%eˆ-t+1’
age: solnx = lambda s: RR(eval(soln.replace("ˆ","**").
replace("%","").replace("t",str(s))))
sage: solnx(3)
1.04978706836786
sage: P = plot(solnx,0,5)
sage: show(P)
The plot is given below.
Figure 1.1: Solution to IVP x′ + x = 1, x(0) = 2.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-17-320.jpg)
![Exercise: Verify the, for any constant c, the function x(t) = 1 + ce−t solves
x′ + x = 1. Find the c for which this function solves the IVP x′ + x = 1,
x(0) = 3.. Solve this (a) by hand, (b) using SAGE .
1.2 Initial value problems
A 1-st order initial value problem, or IVP, is simply a 1-st order ODE
and an initial condition. For example,
x′ (t) + p(t)x(t) = q(t), x(0) = x0 ,
where p(t), q(t) and x0 are given. The analog of this for 2nd order linear
DEs is this:
a(t)x′′ (t) + b(t)x′ (t) + c(t)x(t) = f (t), x(0) = x0 , x′ (0) = v0 ,
where a(t), b(t), c(t), x0 , and v0 are given. This 2-nd order linear DE and
initial conditions is an example of a 2-nd order IVP. In general, in an IVP,
the number of initial conditions must match the order of the DE.
Example 1.2.1. Consider the 2-nd order DE
x′′ + x = 0.
(We shall run across this DE many times later. As we will see, it represents
the displacement of an undamped spring with a unit mass attached. The term
harmonic oscillator is attached to this situation [O-ivp].) Suppose we know
that the general solution to this DE is
x(t) = c1 cos(t) + c2 sin(t),
for any constants c1 , c2 . This means every solution to the DE must be of this
form. (If you don’t believe this, you can at least check it it is a solution by
computing x′′ (t)+x(t) and verifying that the terms cancel, as in the following
SAGE example. Later, we see how to derive this solution.) Note that there
are two degrees of freedom (the constants c1 and c2 ), matching the order of
the DE.
SAGE
sage: t = var(’t’)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-18-320.jpg)
![sage: c1 = var(’c1’)
sage: c2 = var(’c2’)
sage: de = lambda x: diff(x,t,t) + x
sage: de(c1*cos(t) + c2*sin(t))
0
sage: x = function(’x’, t)
sage: soln = desolve_laplace(de(x(t)),["t","x"],[0,0,1])
sage: soln
’sin(t)’
sage: solnx = lambda s: RR(eval(soln.replace("t","s")))
sage: P = plot(solnx,0,2*pi)
sage: show(P)
This is displayed below.
Now, to solve the IVP
x′′ + x = 0, x(0) = 0, x′ (0) = 1.
the problem is to solve for c1 and c2 for which the x(t) satisfies the initial
conditions. The two degrees of freedom in the general solution matching the
number of initial conditions in the IVP. Plugging t = 0 into x(t) and x′ (t),
we obtain
0 = x(0) = c1 cos(0) + c2 sin(0) = c1 , 1 = x′ (0) = −c1 sin(0) + c2 cos(0) = c2 .
Therefore, c1 = 0, c2 = 1 and x(t) = sin(t) is the unique solution to the IVP.
Figure 1.2: Solution to IVP x′′ + x = 0, x(0) = 0, x′ (0) = 1.
Here you see the solution oscillates, as t gets larger.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-19-320.jpg)
![Another example,
Example 1.2.2. Consider the 2-nd order DE
x′′ + 4x′ + 4x = 0.
(We shall run across this DE many times later as well. As we will see, it
represents the displacement of a critially damped spring with a unit mass
attached.) Suppose we know that the general solution to this DE is
x(t) = c1 exp(−2t) + c2 texp(−2t) = c1 e−2t + c2 te−2t ,
for any constants c1 , c2 . This means every solution to the DE must be of
this form. (Again, you can at least check it is a solution by computing x′′ (t),
4x′ (t), 4x(t), adding them up and verifying that the terms cancel, as in the
following SAGE example.)
SAGE
sage: t = var(’t’)
sage: c1 = var(’c1’)
sage: c2 = var(’c2’)
sage: de = lambda x: diff(x,t,t) + 4*diff(x,t) + 4*x
sage: de(c1*exp(-2*t) + c2*t*exp(-2*t))
4*(c2*t*eˆ(-2*t) + c1*eˆ(-2*t)) + 4*(-2*c2*t*eˆ(-2*t)
+ c2*eˆ(-2*t) - 2*c1*eˆ(-2*t)) + 4*c2*t*eˆ(-2*t)
- 4*c2*eˆ(-2*t) + 4*c1*eˆ(-2*t)
sage: de(c1*exp(-2*t) + c2*t*exp(-2*t)).expand()
0
sage: desolve_laplace(de(x(t)),["t","x"],[0,0,1])
’t*%eˆ-(2*t)’
sage: P = plot(t*exp(-2*t),0,pi)
sage: show(P)
The plot is displayed below.
Now, to solve the IVP
x′′ + 4x′ + 4x = 0, x(0) = 0, x′ (0) = 1.
we solve for c1 and c2 using the initial conditions. Plugging t = 0 into x(t)
and x′ (t), we obtain](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-20-320.jpg)
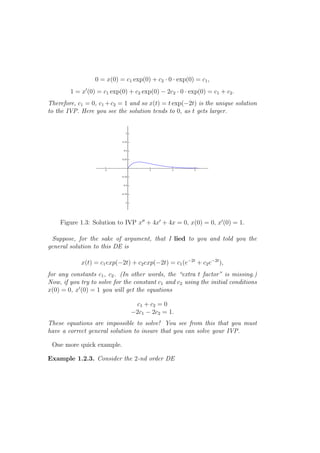
![x′′ − x = 0.
Suppose we know that the general solution to this DE is
x(t) = c1 exp(t) + c2 exp(−t) = c1 e−t + c2 e−t ,
for any constants c1 , c2 . (Again, you can check it is a solution.)
The solution to the IVP
x′′ − x = 0, x(0) = 0, x′ (0) = 1,
t
is x(t) = e +e . (You can solve for c1 and c2 yourself, as in the examples
−t
2
above.) This particular function is also called a hyperbolic cosine func-
tion, denoted cosh(t).
The hyperbolic trig functions have many properties analogous to the usual
trig functions and arise in many areas of applications [H-ivp]. For example,
cosh(t) represents a catenary or hanging cable [C-ivp].
SAGE
sage: t = var(’t’)
sage: c1 = var(’c1’)
sage: c2 = var(’c2’)
sage: de = lambda x: diff(x,t,t) - x
sage: de(c1*exp(-t) + c2*exp(-t))
0
sage: desolve_laplace(de(x(t)),["t","x"],[0,0,1])
’%eˆt/2-%eˆ-t/2’
sage: P = plot(eˆt/2-eˆ(-t)/2,0,3)
sage: show(P)
Here you see the solution tends to infinity, as t gets larger.
Exercise: The general solution to the falling body problem
mv ′ + kv = mg,
is v(t) = mg + ce−kt/m . If v(0) = v0 , solve for c in terms of v0 . Take
k
m = k = v0 = 1, g = 9.8 and use SAGE to plot v(t) for 0 < t < 1.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-22-320.jpg)
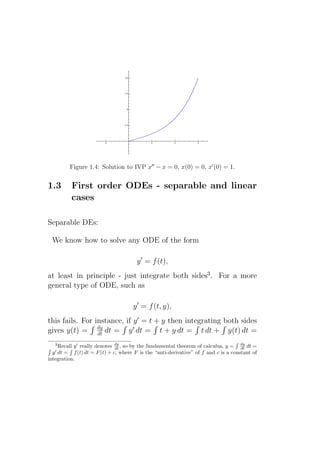


![dx
(d) dt = (c−bx)/a = − a (x− c ), so
b
b
dx
x− c
b
= − a dt, so ln |x− c | =
b
b
b
− a t + C, where C is a constant of integration. This is the
implicit general solution of the DE. The explicit general
b
solution is x = c + Be− a t , where B is a constant.
b
The explicit solution is easy find using SAGE :
SAGE
sage: a = var(’a’)
sage: b = var(’b’)
sage: c = var(’c’)
sage: t = var(’t’)
sage: x = function(’x’, t)
sage: de = lambda y: a*diff(y,t) + b*y - c
sage: desolve_laplace(de(x(t)),["t","x"])
’c/b-(a*c-x(0)*a*b)*%eˆ-(b*t/a)/(a*b)’
(e) If c = c(t) is not constant then ax′ +bx = c is not separable.
dy 1
(f ) (y−1)(y+1)= dt so 2 (ln(y − 1) − ln(y + 1)) = t + C, where C
is a constant of integration. This is the “general (implicit)
solution” of the DE.
Note: the constant functions y(t) = 1 and y(t) = −1 are
also solutions to this DE. These solutions cannot be ob-
tained (in an obvious way) from the general solution.
The integral is easy to do using SAGE :
SAGE
sage: y = var(’y’)
sage: integral(1/((y-1)*(y+1)),y)
log(y - 1)/2 - (log(y + 1)/2)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-26-320.jpg)
![Now, let’s try to get SAGE to solve for y in terms of t in
1
2 (ln(y − 1) − ln(y + 1)) = t + C:
SAGE
sage: C = var(’C’)
sage: solve([log(y - 1)/2 - (log(y + 1)/2) == t+C],y)
[log(y + 1) == -2*C + log(y - 1) - 2*t]
This is not working. Let’s try inputting the problem in a
different form:
SAGE
sage: C = var(’C’)
sage: solve([log((y - 1)/(y + 1)) == 2*t+2*C],y)
[y == (-eˆ(2*C + 2*t) - 1)/(eˆ(2*C + 2*t) - 1)]
This is what we want. Now let’s assume the initial condi-
tion y(0) = 2 and solve for C and plot the function.
SAGE
sage: solny=lambda t:(-eˆ(2*C+2*t)-1)/(eˆ(2*C+2*t)-1)
sage: solve([solny(0) == 2],C)
[C == log(-1/sqrt(3)), C == -log(3)/2]
sage: C = -log(3)/2
sage: solny(t)
(-eˆ(2*t)/3 - 1)/(eˆ(2*t)/3 - 1)
sage: P = plot(solny(t), 0, 1/2)
sage: show(P)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-27-320.jpg)
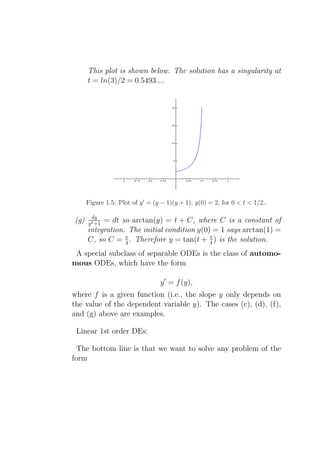
![x′ + p(t)x = q(t), (1.2)
where p(t) and q(t) are given functions (which, let’s assume,
aren’t too horrible). Every first order linear ODE can be writ-
ten in this form. Examples of DEs which have this form: Falling
Body problems, Newton’s Law of Cooling problems, Mixing
problems, certain simple Circuit problems, and so on.
There are two approaches
• “the formula”,
• the method of integrating factors.
Both lead to the exact same solution.
“The Formula”: The general solution to (1.2) is
p(t) dt
e q(t) dt + C
x= , (1.3)
e p(t) dt
where C is a constant. The factor e p(t) dt is called the inte-
grating factor and is often denoted by µ. This formula was
apparently first discovered by Johann Bernoulli [F-1st].
Example 1.3.2. Solve
xy ′ + y = ex .
x 1
1
We rewrite this as y ′ + x y = ex . Now compute µ = e x dx
=
eln(x) = x, so the formula gives
x
x ex dx + C ex dx + C ex + C
y= = = .
x x x
Here is one way to do this using SAGE :](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-29-320.jpg)
![SAGE
sage: t = var(’t’)
sage: x = function(’x’, t)
sage: de = lambda y: diff(y,t) + (1/t)*y - exp(t)/t
sage: desolve(de(x(t)),[x,t])
’(%eˆt+%c)/t’
p(t) dt
“Integrating factor method”: Let µ = e . Multiply both
sides of (1.2) by µ:
µx′ + p(t)µx = µq(t).
The product rule implies that
(µx)′ = µx′ + p(t)µx = µq(t).
(In response to a question you are probably thinking now: No,
this is not obvious. This is Bernoulli’s very clever idea.) Now
just integrate both sides. By the fundamental theorem of calcu-
lus,
µx = (µx)′ dt = µq(t) dt.
Dividing both side by µ gives (1.3).](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-30-320.jpg)


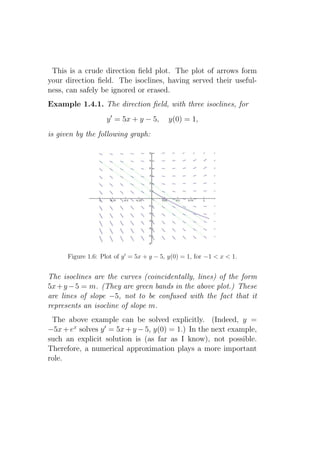
![Example 1.4.2. The direction field, with three isoclines, for
y ′ = x2 + y 2 , y(0) = 3/2,
is given by the following graph:
Figure 1.7: Direction field and solution plot of y ′ = x2 + y 2 , y(0) = 3/2, for
−3 < x < 3.
The isoclines are the concentric circles x2 + y 2 = m. (They are
green in the above plot.)
The plot above was obtained using SAGE ’s interface with Max-
ima, and the plotting package Openmath (SAGE includes both
Maxima and Openmath). :
SAGE
sage: maxima.eval(’load("plotdf")’)
sage: maxima.eval(’plotdf(xˆ2+yˆ2,[trajectory_at,0,0],
[x,-3,3],[y,-3,3])’)
This gave the above plot. (Note: the plotdf command goes on
one line; for typographical reasons, it was split in two.)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-34-320.jpg)
![There is also a way to draw these direction fields using SAGE .
SAGE
sage: pts = [(-2+i/5,-2+j/5) for i in range(20)
for j in range(20)] # square [-2,2]x[-2,2]
sage: f = lambda p:p[0]ˆ2+p[1]ˆ2
sage: arrows = [arrow(p, (p[0]+0.02,p[1]+(0.02)*f(p)),
width=1/100, rgbcolor=(0,0,1)) for p in pts]
sage: show(sum(arrows))
This gives the plot below.
Figure 1.8: Direction field for y ′ = x2 + y 2 , y(0) = 3/2, for −2 < x < 2.
Exercise: Using SAGE , plot the direction field for y ′ = x2 − y 2 .](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-35-320.jpg)
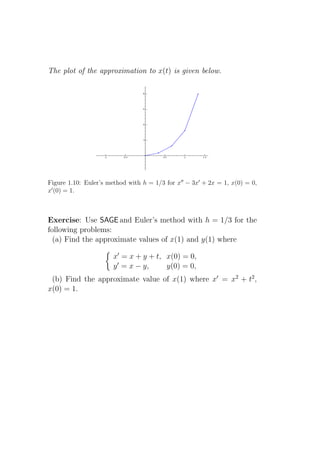
![1.5 Numerical solutions - Euler’s method and
improved Euler’s method
Read Euler: he is our master in everything.
- Pierre Simon de Laplace
Leonhard Euler was a Swiss mathematician who made signifi-
cant contributions to a wide range of mathematics and physics
including calculus and celestial mechanics (see [Eu1-num] and
[Eu2-num] for further details).
The goal is to find an approximate solution to the problem
y ′ = f (x, y), y(a) = c, (1.5)
where f (x, y) is some given function. We shall try to approxi-
mate the value of the solution at x = b, where b > a is given.
Sometimes such a method is called “numerically integrating
(1.5)”.
Note: the first order DE must be in the form (1.5) or the
method described below does not work. A version of Euler’s
method for systems of 1-st order DEs and higher order DEs will
also be described below.
Euler’s method
Geometric idea: The basic idea can be easily expressed in
geometric terms. We know the solution, whatever it is, must go
through the point (a, c) and we know, at that point, its slope is](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-36-320.jpg)


![so y(1) ∼ − 11 = −2.75. This is the final answer.
= 4
Aside: For your information, y = ex − 5x solves the DE and
y(1) = e − 5 = −2.28....
Here is one way to do this using SAGE :
SAGE
sage: x,y=PolynomialRing(QQ,2,"xy").gens()
sage: eulers_method(5*x+y-5,1,1,1/3,2)
x y h*f(x,y)
1 1 1/3
4/3 4/3 1
5/3 7/3 17/9
2 38/9 83/27
sage: eulers_method(5*x+y-5,0,1,1/2,1,method="none")
[[0, 1], [1/2, -1], [1, -11/4], [3/2, -33/8]]
sage: pts = eulers_method(5*x+y-5,0,1,1/2,1,method="none")
sage: P = list_plot(pts)
sage: show(P)
sage: P = line(pts)
sage: show(P)
sage: P1 = list_plot(pts)
sage: P2 = line(pts)
sage: show(P1+P2)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-39-320.jpg)
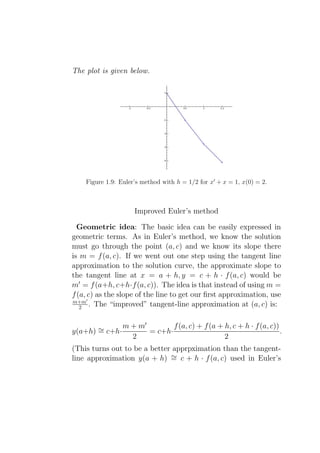



![This is the DE rewritten as a system in standard form. (In
general, the tabular method applies to any system but it must be
in standard form.)
Taking h = (1 − 0)/3 = 1/3, we have
t x1 x2 /3 x2 (1 − 2x1 + 3x2 )/3
0 0 1/3 1 4/3
1/3 1/3 7/9 7/3 22/9
2/3 10/9 43/27 43/9 xxx
1 73/27 xxx xxx xxx
So x(1) = x1 (1) ∼ 73/27 = 2.7....
Here is one way to do this using SAGE :
SAGE
sage: RR = RealField(sci_not=0, prec=4, rnd=’RNDU’)
sage: t, x, y = PolynomialRing(RR,3,"txy").gens()
sage: f = y; g = 1-2*x+3*y
sage: L = eulers_method_2x2(f,g,0,0,1,1/3,1,method="none")
sage: L
[[0, 0, 1], [1/3, 0.35, 2.5], [2/3, 1.3, 5.5],
[1, 3.3, 12], [4/3, 8.0, 24]]
sage: eulers_method_2x2(f,g, 0, 0, 1, 1/3, 1)
t x h*f(t,x,y) y h*g(t,x,y)
0 0 0.35 1 1.4
1/3 0.35 0.88 2.5 2.8
2/3 1.3 2.0 5.5 6.5
1 3.3 4.5 12 11
sage: P1 = list_plot([[p[0],p[1]] for p in L])
sage: P2 = line([[p[0],p[1]] for p in L])
sage: show(P1+P2)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-44-320.jpg)
![1.6 Newtonian mechanics
We briefly recall how the physics of the falling body problem
leads naturally to a differential equation (this was already men-
tioned in the introduction and forms a part of Newtonian me-
chanics [M-mech]). Consider a mass m falling due to gravity.
We orient coordinates to that downward is positive. Let x(t)
denote the distance the mass has fallen at time t and v(t) its
velocity at time t. We assume only two forces act: the force due
to gravity, Fgrav , and the force due to air resistence, Fres . In
other words, we assume that the total force is given by
Ftotal = Fgrav + Fres .
We know that Fgrav = mg, where g > 0 is the gravitational
constant, from high school physics. We assume, as is common
in physics, that air resistance is proportional to velocity: Fres =
−kv = −kx′ (t), where k ≥ 0 is a constant. Newton’s second
law [N-mech] tells us that Ftotal = ma = mx′′ (t). Putting these
all together gives mx′′ (t) = mg − kx′ (t), or
k
v ′ (t) + v(t) = g. (1.6)
m
This is the differential equation governing the motion of a falling
body. Equation (1.6) can be solved by various methods: separa-
tion of variables or by integrating factors. If we assume v(0) = v0
is given and if we assume k > 0 then the solution is
mg mg −kt/m
v(t) = + (v0 − )e . (1.7)
k k
In particular, we see that the limiting velocity is vlimit = mg .
k](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-46-320.jpg)
![Example 1.6.1. Wile E. Coyote (see [W-mech] if you haven’t
seen him before) has mass 100 kgs (with chute). The chute is
released 30 seconds after the jump from a height of 2000 m. The
force due to air resistence is given by Fres = −kv, where
15, chute closed,
k=
100, chute open.
Find
(a) the distance and velocity functions during the time when
the chute is closed (i.e., 0 ≤ t ≤ 30 seconds),
(b) the distance and velocity functions during the time when
the chute is open (i.e., 30 ≤ t seconds),
(c) the time of landing,
(d) the velocity of landing. (Does Wile E. Coyote survive the
impact?)
soln: Taking m = 100, g = 9.8, k = 15 and v(0) = 0 in (1.7),
we find
196 196 − 3 t
v1 (t) = − e 20 .
3 3
This is the velocity with the time t starting the moment the
parachutist jumps. After t = 30 seconds, this reaches the ve-
locity v0 = 196 − 196 e−9/2 = 64.607.... The distance fallen is
3 3
t
x1 (t) = 0 v1 (u) du
196 3
= 3 t + 3920 e− 20 t
9 − 3920
9 .
13720 3920 −9/2
After 30 seconds, it has fallen x1 (30) = 9 + 9 e =
1529.283... meters.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-47-320.jpg)

![Now let us solve this using SAGE .
SAGE
sage: RR = RealField(sci_not=0, prec=50, rnd=’RNDU’)
sage: t = var(’t’)
sage: v = function(’v’, t)
sage: m = 100; g = 98/10; k = 15
sage: de = lambda v: m*diff(v,t) + k*v - m*g
sage: desolve_laplace(de(v(t)),["t","v"],[0,0])
’196/3-196*%eˆ-(3*t/20)/3’
sage: soln1 = lambda t: 196/3-196*exp(-3*t/20)/3
sage: P1 = plot(soln1(t),0,30,plot_points=1000)
sage: RR(soln1(30))
64.607545559502
This solves for the velocity before the coyote’s chute is opened,
0 < t < 30. The last number is the velocity Wile E. Coyote is
traveling at the moment he opens his chute.
SAGE
sage: t = var(’t’)
sage: v = function(’v’, t)
sage: m = 100; g = 98/10; k = 100
sage: de = lambda v: m*diff(v,t) + k*v - m*g
sage: desolve_laplace(de(v(t)),["t","v"],[0,RR(soln1(30))])
’631931*%eˆ-t/11530+49/5’
sage: soln2 = lambda t: 49/5+(631931/11530)*exp(-(t-30))
+ soln1(30) - (631931/11530) - 49/5
sage: RR(soln2(30))
64.607545559502
sage: RR(soln1(30))
64.607545559502
sage: P2 = plot(soln2(t),30,50,plot_points=1000)
sage: show(P1+P2)
This solves for the velocity after the coyote’s chute is opened, t >](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-49-320.jpg)



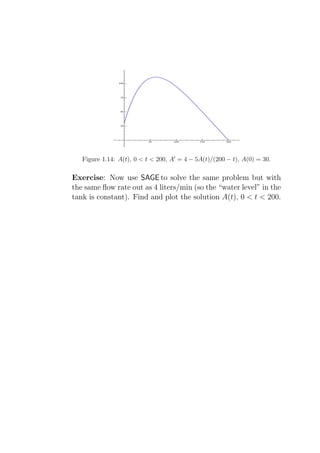
![1
where µ = e p(t) dt = e−5 200−t dt = (200 − t)−5 is the “integrating
factor”. This gives A(t) = 200 − t + C · (200 − t)5 , where the
initial condition implies C = −170 · 200−5 .
Here is one way to do this using SAGE :
SAGE
sage: t = var(’t’)
sage: A = function(’A’, t)
sage: de = lambda A: diff(A,t) + (5/(200-t))*A - 4
sage: desolve(de(A(t)),[A,t])
’(%c-1/(t-200)ˆ4)*(t-200)ˆ5’
This is the form of the general solution. (SAGE uses Maxima
and %c is Maxima’s notation for an arbitrary constant.) Let us
now solve this general solution for c, using the initial conditions.
SAGE
sage: c = var(’c’)
sage: solnA = lambda t: (c - 1/(t-200)ˆ4)*(t-200)ˆ5
sage: solnA(t)
(c - (1/(t - 200)ˆ4))*(t - 200)ˆ5
sage: solnA(0)
-320000000000*(c - 1/1600000000)
sage: solve([solnA(0) == 30],c)
[c == 17/32000000000]
sage: c = 17/32000000000
sage: solnA(t)
(17/32000000000 - (1/(t - 200)ˆ4))*(t - 200)ˆ5
sage: P = plot(solnA(t),0,200)
sage: show(P)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-55-320.jpg)


![such that every solution to (2.2) is a linear combination of
these functions y1 , . . . , yn .
• Suppose you know a solution yp (t) (a particular solution)
to (2.1). Then every solution y = y(t) (the general solu-
tion) to the DE (2.1) has the form
y(t) = yh (t) + yp (t), (2.3)
where yh (the “homogeneous part” of the general solution)
is a linear combination
yh (t) = c1 y1 (t) + y2 (t) + ... + cn yn (t),
for some constants ci , 1 ≤ i ≤ n.
• Conversely, every function of the form (2.3), for any con-
stants ci for 1 ≤ i ≤ n, is a solution to (2.1).
Example 2.1.1. Recall the example in the introduction where
we looked for functions solving x′ + x = 1 by “guessing”. The
function xp (t) = 1 is a particular solution to x′ + x = 1. The
function x1 (t) = e−t is a fundamental solution to x′ + x = 0.
The general solution is therefore x(t) = 1 + c1 e−t , for a constant
c1 .
Example 2.1.2. The charge on the capacitor of an RLC elec-
trical circuit is modeled by a 2-nd order linear DE [C-linear].
Series RLC Circuit notations:
• E = E(t) - the voltage of the power source (a battery or
other “electromotive force”, measured in volts, V)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-59-320.jpg)

![Example 2.1.4. The displacement from equilibrium of a mass
attached to a spring is modeled by a 2-nd order linear DE [O-ivp].
SSpring-mass notations:
• f (t) - the external force acting on the spring (if any)
• x = x(t) - the displacement from equilibrium of a mass
attached to a spring
• m - the mass
• b - the damping constant (if, say, the spring is immersed in
a fluid)
• k - the spring constant.
The displacement x satisfies the linear IPV:
mx′′ + bx′ + kx = f (t), x(0) = x0 , x′ (0) = v0 .
Figure 2.2: spring-mass model.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-61-320.jpg)

![Here is one way to use SAGE to solve for c1 . (Of course, you
can do this yourself, but this shows you the SAGE syntax for
solving equations. Type solve? in SAGE to get more details.)
We use SAGE to solve the last IVP discussed above and then to
plot the solution.
SAGE
sage: t = var(’t’)
sage: c1 = var(’c1’)
sage: solnx = lambda t: 1+c1*exp(-t)
sage: solnx(0)
c1 + 1
sage: solve([solnx(0) == 3],c1)
[c1 == 2]
sage: c_1 = solve([solnx(0) == 3],c1)[0].rhs()
sage: c_1
2
sage: solnx1 = lambda t: 1+c*exp(-t)
sage: plot(solnx1(t),0,2)
Graphics object consisting of 1 graphics primitive
sage: P = plot(solnx1(t),0,2)
sage: show(P)
sage: P = plot(solnx1(t),0,5)
sage: show(P)
This plot is shown below.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-63-320.jpg)

![is not hard to understand and it involves what is called “the
Wronskian1 ” [W-linear]. We’ll have to explain what this means
first. If f1 (t), f2 (t), . . . , fn (t) are given n-times differentiable
functions then their fundamental matrix is the matrix
f1 (t) f2 (t) . . . fn (t)
′ ′ ′
f1 (t) f2 (t) . . . fn (t)
Φ = Φ(f1 , ..., fn ) = . . . .
.
. .
. .
.
(n−1) (n−1) (n−1)
f1 (t) f2 (t) . . . fn (t)
The determinant of the fundamental matrix is called the Wron-
skian, denoted W (f1 , ..., fn ). The Wronskian actually helps us
answer both questions above simultaneously.
Example 2.2.1. Take f1 (t) = sin2 (t), f2 (t) = cos2 (t), and
f3 (t) = 1. SAGE allows us to easily compute the Wronskian:
SAGE
sage: SR = SymbolicExpressionRing()
sage: MS = MatrixSpace(SR,3,3)
sage: Phi = MS([[sin(t)ˆ2,cos(t)ˆ2,1],
[diff(sin(t)ˆ2,t),diff(cos(t)ˆ2,t),0],
[diff(sin(t)ˆ2,t,t),diff(cos(t)ˆ2,t,t),0]])
sage: Phi
[ sin(t)ˆ2 cos(t)ˆ2 1]
[ 2*cos(t)*sin(t) -2*cos(t)*sin(t) 0]
[2*cos(t)ˆ2 - 2*sin(t)ˆ2 2*sin(t)ˆ2 - 2*cos(t)ˆ2 0]
sage: Phi.det()
0
1
Josef Wronski was a Polish-born French mathemtician who worked in many different
areas of applied mathematics and mechanical engineering [Wr-linear].](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-66-320.jpg)

![We try one more example:
SAGE
sage: SR = SymbolicExpressionRing()
sage: MS = MatrixSpace(SR,2,2)
sage: Phi = MS([[sin(t)ˆ2,cos(t)ˆ2],
[diff(sin(t)ˆ2,t),diff(cos(t)ˆ2,t)]])
sage: Phi
[ sin(t)ˆ2 cos(t)ˆ2]
[ 2*cos(t)*sin(t) -2*cos(t)*sin(t)]
sage: Phi.det()
-2*cos(t)*sin(t)ˆ3 - 2*cos(t)ˆ3*sin(t)
This means W (sin(t)2 , cos(t)2 ) = −2 cos(t) sin(t)3 −2 cos(t)3 sin(t),
which is non-zero.
If there are constants c1 , ..., cn , not all zero, for which
c1 f1 (t) + c2 f2 (t) · · · + cn fn (t) = 0, for all t, (2.4)
then the functions fi (1 ≤ i ≤ n) are called linearly depen-
dent. If the functions fi (1 ≤ i ≤ n) are not linearly dependent
then they are called linearly independent (this definition is
frequently seen for linearly independent vectors [L-linear] but
holds for functions as well). This condition (2.4) can be inter-
preted geometrically as follows. Just as c1 x + c2 y = 0 is a line
through the origin in the plane and c1 x + c2 y + c3 z = 0 is a plane
containing the origin in 3-space, the equation
c1 x1 + c2 x2 · · · + cn xn = 0,
is a “hyperplane” containing the origin in n-space with coordi-
nates (x1 , ..., xn ). This condition (2.4) says geometrically that](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-68-320.jpg)

![Figure 2.4: Parametric plot of (sin(t)2 , cos(t)2 ).
The functions y1 (t), ..., yn (t) in the above theorem are called
fundamental solutions.
We shall not prove either of these theorems here. Please see
[BD-intro] for further details.
Exercise: Use SAGE to compute the Wronskian of
(a) f1 (t) = sin(t), f2 (t) = cos(t),
(b) f1 (t) = 1, f2 (t) = t, f3 (t) = t2 , f4 (t) = t3 .
Check that
(a) y1 (t) = sin(t), y2 (t) = cos(t) are fundamental solutions for
′′
y + y = 0,
(d) y1 (t) = 1, y2 (t) = t, y3 (t) = t2 , y4 (t) = t3 are fundamental
solutions for y (4) = y ′′′′ = 0.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-70-320.jpg)
![2.3 Undetermined coefficients method
The method of undetermined coefficients [U-uc] can be used to
solve the following type of problem.
PROBLEM: Solve
ay ′′ + by ′ + cy = f (x), (2.5)
where a = 0, b and c are constants and x is the independent
variable. (Even the case a = 0 can be handled similarly, though
some of the discussion below might need to be slightly modified.)
Where we must assume that f (x) is of a special form.
More-or-less equivalent is the method of annihilating operators
[A-uc] (they solve the same class of DEs), but that method will
be discussed separately.
For the moment, let us assume f (x) has the form a1 · p(x) ·
ea2 x · cos(a3 x), or a1 · p(x) · ea2 x · sin(a3 x), where a1 , a2 , a3 are
constants and p(x) is a polynomial.
Solution:
• Find the “homogeneous solution” yh to ay ′′ + by ′ + cy =
0, yh = c1 y1 + c2 y2 . Here y1 and y2 are determined as
follows: let r1 and r2 denote the roots of the characteristic
polynomial aD2 + bD + c = 0.
– r1 = r2 real: set y1 = er1 x , y2 = er2 x .
– r1 = r2 real: if r = r1 = r2 then set y1 = erx , y2 = xerx .
– r1 , r2 complex: if r1 = α + iβ, r2 = α − iβ, where α and
β are real, then set y1 = eαx cos(βx), y2 = eαx sin(βx).](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-71-320.jpg)






![We use SAGE for this.
SAGE
sage: x = var("x")
sage: y = function("y",x)
sage: R.<D> = PolynomialRing(QQ, "D")
sage: f = Dˆ3 - Dˆ2 - D + 1
sage: f.factor()
(D + 1) * (D - 1)ˆ2
sage: f.roots()
[(-1, 1), (1, 2)]
So the roots of the characteristic polynomial are 1, 1, −1, which
means that the homogeneous part of the solution is
yh = c1 ex + c2 xex + c3 e−x .
SAGE
sage: de = lambda y: diff(y,x,3) - diff(y,x,2) - diff(y,x,1) + y
sage: c1 = var("c1"); c2 = var("c2"); c3 = var("c3")
sage: yh = c1*eˆx + c2*x*eˆx + c3*eˆ(-x)
sage: de(yh)
0
sage: de(xˆ3*eˆx-(3/2)*xˆ2*eˆx)
12*x*eˆx
This just confirmed that yh solves y ′′′ − y ′′ − y ′ + 1 = 0. Using
the derivatives of F (x) = 12xex , we generate the general form
of the particular:
SAGE
sage: F = 12*x*eˆx](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-78-320.jpg)
![sage: diff(F,x,1); diff(F,x,2); diff(F,x,3)
12*x*eˆx + 12*eˆx
12*x*eˆx + 24*eˆx
12*x*eˆx + 36*eˆx
sage: A1 = var("A1"); A2 = var("A2")
sage: yp = A1*xˆ2*eˆx + A2*xˆ3*eˆx
Now plug this into the DE and compare coefficients of like terms
to solve for the undertermined coefficients:
SAGE
sage: de(yp)
12*x*eˆx*A2 + 6*eˆx*A2 + 4*eˆx*A1
sage: solve([12*A2 == 12, 6*A2+4*A1 == 0],A1,A2)
[[A1 == -3/2, A2 == 1]]
Finally, lets check if this is correct:
SAGE
sage: y = yh + (-3/2)*xˆ2*eˆx + (1)*xˆ3*eˆx
sage: de(y)
12*x*eˆx
Exercise: Using SAGE , solve
y ′′′ − y ′′ + y ′ − y = 12xex .
(Hint: You may need to replace sage: R.<D> = PolynomialRing(QQ, "D")
by sage: R.<D> = PolynomialRing(CC, "D").)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-79-320.jpg)


![2.4 Variation of parameters
Consider an ordinary constant coefficient non-homogeneous 2nd
order linear differential equation,
ay ′′ + by ′ + cy = F (x)
where F (x) is a given function and a, b, and c are constants. (For
the method below, a, b, and c may be allowed to depend on the
independent variable x as well.) Let y1 (x), y2 (x) be fundamental
solutions of the corresponding homogeneous equation
ay ′′ + by ′ + cy = 0.
The method of variation of parameters is originally attributed
to Joseph Louis Lagrange (1736-1813) [L-var]. It starts by as-
suming that there is a particular solution in the form
yp (x) = u1 (x)y1 (x) + u2 (x)y2 (x),
where u1 (x), u2 (x) are unknown functions [V-var].
In general, the product rule gives
(f g)′ = f ′ g + f g ′ ,
(f g)′′ = f ′′ g + 2f ′ g ′ + f g ′′ ,
(f g)′′′ = f ′′′ g + 3f ′′ g ′ + 3f ′ g ′′ + f g ′′′ ,
and so on, following Pascal’s triangle,
1
1 1](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-82-320.jpg)



![yp = (− ln | tan(x) + sec(x)| + sin(x)) cos(x) + (− cos(x)) sin(x).
The homogeneous (or complementary) part of the solution is
yh = c1 cos(x) + c2 sin(x),
so the general solution is
y = yh + yp = c1 cos(x) + c2 sin(x)
+(− ln | tan(x) + sec(x)| + sin(x)) cos(x) + (− cos(x)) sin(x).
Using SAGE , this can be carried out as follows:
SAGE
sage: SR = SymbolicExpressionRing()
sage: MS = MatrixSpace(SR, 2, 2)
sage: W = MS([[cos(t),sin(t)],[diff(cos(t), t),diff(sin(t), t)]])
sage: W
[ cos(t) sin(t)]
[-sin(t) cos(t)]
sage: det(W)
sin(t)ˆ2 + cos(t)ˆ2
sage: U1 = MS([[0,sin(t)],[tan(t),diff(sin(t), t)]])
sage: U2 = MS([[cos(t),0],[diff(cos(t), t),tan(t)]])
sage: integral(det(U1)/det(W),t)
-log(sin(t) + 1)/2 + log(sin(t) - 1)/2 + sin(t)
sage: integral(det(U2)/det(W),t)
-cos(t)
Exercise: Use SAGE to solve y ′′ + y = cot(x).](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-86-320.jpg)

![One can also align the springs left-to-right instead of top-to-
bottom, without changing the discussion below.
Notation: Consider the first two situations above: (a) a spring
at rest, without mass attached and (b) a spring at rest, with
mass attached. The distance the mass pulls the spring down is
sometimes called the “stretch”, and denoted s. (A formula for
s will be given later.)
Now place the mass in motion by imparting some initial ve-
locity (tapping it upwards with a hammer, say, and start your
timer). Consider the second two situations above: (a) a spring
at rest, with mass attached and (b) a spring in motion. The
difference between these two positions at time t is called the
displacement and is denoted x(t). Signs here will be choosen so
that down is positive.
Assume exactly three forces act:
1. the restoring force of the spring, Fspring ,
2. an external force (driving the ceiling up and down, but may
be 0), Fext ,
3. a damping force (imagining the spring immersed in oil or
that it is in fact a shock absorber on a car), Fdamp .
In other words, the total force is given by
Ftotal = Fspring + Fext + Fdamp .
Physics tells us that the following are approximately true:
1. (Hooke’s law [H-intro]): Fspring = −kx, for some “spring
constant” k > 0,](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-88-320.jpg)
![2. Fext = F (t), for some (possibly zero) function F ,
3. Fdamp = −bv, for some “damping constant” b ≥ 0 (where v
denotes velocity),
4. (Newton’s 2nd law [N-mech]): Ftotal = ma (where a denotes
acceleration).
Putting this all together, we obtain mx′′ = ma = −kx + F (t) −
bv = −kx + F (t) − bx′ , or
mx′′ + bx′ + kx = F (t).
This is the spring equation. When b = F (t) = 0 this is also
called the equation for simple harmonic motion.
Consider again first two figures above: (a) a spring at rest,
without mass attached and (b) a spring at rest, with mass at-
tached. The mass in the second figure is at rest, so the gravita-
tional force on the mass, mg, is balanced by the restoring force
of the spring: mg = ks, where s is the stretch.In particular, the
spring constant can be computed from the stretch:
mg
k= s .
Example:
A spring at rest is suspended from the ceiling without mass. A
2 kg weight is then attached to this spring, stretching it 9.8 cm.
From a position 2/3 m above equilibrium the weight is give a
downward velocity of 5 m/s.
(a) Find the equation of motion.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-89-320.jpg)
![(b) What is the amplitude and period of motion?
(c) At what time does the mass first cross equilibrium?
(d) At what time is the mass first exactly 1/2 m below equilib-
rium?
We shall solve this problem using SAGE below. Note m = 2,
b = F (t) = 0 (since no damping or external force is even
mentioned), and k = mg/s = 2 · 9.8/(0.098) = 200. There-
fore, the DE is 2x′′ + 200x = 0. This has general solution
x(t) = c1 cos(10t) + c2 sin(10t). The constants c1 and c2 can
be computed from the initial conditions x(0) = −2/3 (down is
positive, up is negative), x′ (0) = 5.
Using SAGE , the displacement can be computed as follows:
SAGE
sage: t = var(’t’)
sage: x = function(’x’, t)
sage: m = var(’m’)
sage: b = var(’b’)
sage: k = var(’k’)
sage: F = var(’F’)
sage: de = lambda y: m*diff(y,t,t) + b*diff(y,t) + k*y - F
sage: de(x(t))
-F + m*diff(x(t), t, 2) + b*diff(x(t), t, 1) + k*x(t)
sage: m = 2; b = 0; k = 2*9.8/(0.098); F = 0
sage: de(x(t))
2*diff(x(t), t, 2) + 200.000000000000*x(t)
sage: desolve(de(x(t)),[x,t])
’%k1*sin(10*t)+%k2*cos(10*t)’
sage: desolve_laplace(de(x(t)),["t","x"],[0,-2/3,5])
’sin(10*t)/2-2*cos(10*t)/3’
Now we write this in the more compact and useful form A sin(ωt+
φ) using the formulas](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-90-320.jpg)

![Figure 2.8: Plot of 2x′′ + 200x = 0, x(0) = −2/3, x′ (0) = 5, for 0 < t < 2.
Of course, the period is 2π/10 = π/5 ≈ 0.628.
To answer (c) and (d), we solve x(t) = 0 and x(t) = 1/2:
SAGE
sage: solve(A*sin(10*t + phi) == 0,t)
[t == atan(1/2)/5]
sage: RR(atan(1/2)/5)
0.0927295218001612
sage: solve(A*sin(10*t + phi) == 1/2,t)
[t == (asin(3/5) + 2*atan(1/2))/10]
sage: RR((asin(3/5) + 2*atan(1/2))/10)
0.157079632679490
In other words, x(0.0927...) ≈ 0, x(0.157...) ≈ 1/2.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-92-320.jpg)

![2.5.2 Part 2
Recall from part 1, the spring equation
mx′′ + bx′ + kx = F (t)
where x(t) denotes the displacement at time t.
Unless otherwise stated, we assume there is no external force:
F (t) = 0.
The roots of the characteristic polynomial mD2 + bD = k = 0
are
√
−b ± b2 − 4mk
.
2m
There are three cases:
(a) real distinct roots: in this case the discriminant b2 − 4mk
is positive, so b2 > 4mk. In other words, b is “large”. This
case is referred to as overdamped. In this case, the roots
are negative,
√ √
−b − b2 − 4mk −b + b2 − 4mk
r1 = < 0, and r1 = < 0,
2m 2m
so the solution x(t) = c1 er1 t + c2 er2 t is exponentially de-
creasing.
(b) real repeated roots: in this case the discriminant b2 − 4mk
√
is zero, so b = 4mk. This case is referred to as criti-
cally damped. This case is said to model new suspension
systems in cars [D-spr].](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-94-320.jpg)
![(c) Complex roots: in this case the discriminant b2 − 4mk is
negative, so b2 < 4mk. In other words, b is “small”. This
case is referred to as underdamped (or simple harmonic
when b = 0).
Example: An 8 lb weight stretches a spring 2 ft. Assume a
damping force numerically equal to 2 times the instantaneous
velocity acts. Find the displacement at time t, provided that it
is released from the equilibrium position with an upward velocity
of 3 ft/s. Find the equation of motion and classify the behaviour.
We know m = 8/32 = 1/4, b = 2, k = mg/s = 8/2 = 4,
x(0) = 0, and x′ (0) = −3. This means we must solve
1 ′′
x + 2x′ + 4x = 0, x(0) = 0, x′ (0) = −3.
4
The roots of the characteristic polynomial are −4 and −4 (so
we are in the repeated real roots case), so the general solution
is x(t) = c1 e−4t + c2 te−4t . The initial conditions imply c1 = 0,
c2 = −3, so
x(t) = −3te−4t .
Using SAGE , we can compute this as well:
SAGE
sage: t = var(‘‘t’’)
sage: x = function(‘‘x’’)
sage: de = lambda y: (1/4)*diff(y,t,t) + 2*diff(y,t) + 4*y
sage: de(x(t))
diff(x(t), t, 2)/4 + 2*diff(x(t), t, 1) + 4*x(t)
sage: desolve(de(x(t)),[x,t])
’(%k2*t+%k1)*%eˆ-(4*t)’
sage: desolve_laplace(de(x(t)),[‘‘t’’,’’x’’],[0,0,-3])](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-95-320.jpg)
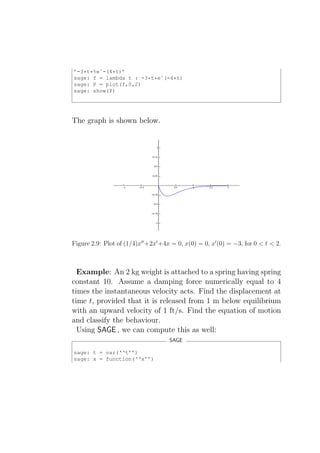
![sage: de = lambda y: 2*diff(y,t,t) + 4*diff(y,t) + 10*y
sage: desolve_laplace(de(x(t)),["t","x"],[0,1,1])
’%eˆ-t*(sin(2*t)+cos(2*t))’
sage: desolve_laplace(de(x(t)),["t","x"],[0,1,-1])
’%eˆ-t*cos(2*t)’
sage: sol = lambda t: eˆ(-t)*cos(2*t)
sage: P = plot(sol(t),0,2)
sage: show(P)
sage: P = plot(sol(t),0,4)
sage: show(P)
The graph is shown below.
Figure 2.10: Plot of 2x′′ + 4x′ + 10x = 0, x(0) = 1, x′ (0) = −1, for 0 < t < 4.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-97-320.jpg)

![sage: m = 1; b = 0; k = 4; F0 = 1; w = 2
sage: desolve(de(x(t)),[x,t])
’(2*t*sin(2*t)+cos(2*t))/8+%k1*sin(2*t)+%k2*cos(2*t)’
sage: desolve_laplace(de(x(t)),["t","x"],[0,0,0])
’t*sin(2*t)/4’
sage: soln = lambda t : t*sin(2*t)/4
sage: P = plot(soln(t),0,10)
sage: show(P)
This is displayed below:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-99-320.jpg)
![Figure 2.11: A forced undamped spring, with resonance.
Example: Solve
x′′ + ω 2 x = F0 cos(γt), x(0) = 0, x′ (0) = 0,
where ω = 2 and γ = 3 (ie, mechanical resonance). We use
SAGE for this:
SAGE
sage: t = var(’t’)
sage: x = function(’x’, t)
sage: (m,b,k,w,g,F0) = var("m,b,k,w,g,F0")
sage: de = lambda y: diff(y,t,t) + wˆ2*y - F0*cos(g*t)
sage: m = 1; b = 0; k = 4; F0 = 1; w = 2; g = 3
sage: desolve_laplace(de(x(t)),["t","x"],[0,0,0])
’cos(2*t)/5-cos(3*t)/5’
sage: soln = lambda t : cos(2*t)/5-cos(3*t)/5
sage: P = plot(soln(t),0,10)
sage: show(P)
This is displayed below:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-100-320.jpg)
![Figure 2.12: A forced undamped spring, no resonance.
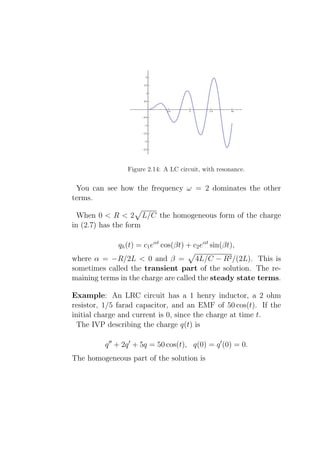
2.6 Applications to simple LRC circuits
An LRC circuit is a closed loop containing an inductor of L hen-
ries, a resistor of R ohms, a capacitor of C farads, and an EMF
(electro-motive force), or battery, of E(t) volts, all connected in
series.
They arise in several engineering applications. For example,
AM/FM radios with analog tuners typically use an LRC circuit
to tune a radio frequency. Most commonly a variable capaci-
tor is attached to the tuning knob, which allows you to change
the value of C in the circuit and tune to stations on different
frequencies [R-cir].
We use the following “dictionary” to translate between the
diagram and the DEs.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-101-320.jpg)

![According to Kirchoff’s 2nd Law and the above “dictionary”,
this circuit corresponds to the DE
1
q ′′ +
q = sin(2t) + sin(11t).
C
The homogeneous part of the solution is
√ √
qh (t) = c1 cos(t/ C) + c1 sin(t/ C).
If C = 1/4 and C = 1/121 then
1 1
qp (t) = sin(2t) + −1 sin(11t).
C −1 − 4 C − 121
When C = 1/4 and the initial charge and current are both
zero, the solution is
1 161 1
q(t) = − sin(11t) + sin(2t) − t cos(2t).
117 936 4
SAGE
sage: t = var("t")
sage: q = function("q",t)
sage: L,R,C = var("L,R,C")
sage: E = lambda t:sin(2*t)+sin(11*t)
sage: de = lambda y: L*diff(y,t,t) + R*diff(y,t) + (1/C)*y-E(t)
sage: L,R,C=1,0,1/4
sage: de(q(t))
diff(q(t), t, 2) - sin(11*t) - sin(2*t) + 4*q(t)
sage: desolve_laplace(de(q(t)),["t","q"],[0,0,0])
’-sin(11*t)/117+161*sin(2*t)/936-t*cos(2*t)/4’
sage: soln = lambda t: -sin(11*t)/117+161*sin(2*t)/936-t*cos(2*t)/4
sage: P = plot(soln,0,10)
sage: show(P)
This is displayed below:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-103-320.jpg)
![qh (t) = c1 e−t cos(2t) + c2 e−t sin(2t).
The general form of the particular solution using the method of
undetermined coefficients is
qp (t) = A1 cos(t) + A2 sin(t).
Solving for A1 and A2 gives
15 −t
qp (t) = −10e−t cos(2t) − e sin(2t).
2
SAGE
sage: t = var("t")
sage: q = function("q",t)
sage: L,R,C = var("L,R,C")
sage: E = lambda t: 50*cos(t)
sage: de = lambda y: L*diff(y,t,t) + R*diff(y,t) + (1/C)*y-E(t)
sage: L,R,C = 1,2,1/5
sage: de(q(t))
diff(q(t), t, 2) + 2*diff(q(t), t, 1) + 5*q(t) - 50*cos(t)
sage: desolve_laplace(de(q(t)),["t","q"],[0,0,0])
’%eˆ-t*(-15*sin(2*t)/2-10*cos(2*t))+5*sin(t)+10*cos(t)’
sage: soln = lambda t:
eˆ(-t)*(-15*sin(2*t)/2-10*cos(2*t))+5*sin(t)+10*cos(t)
sage: P = plot(soln,0,10)
sage: show(P)
sage: P = plot(soln,0,20)
sage: show(P)
sage: soln_ss = lambda t: 5*sin(t)+10*cos(t)
sage: P_ss = plot(soln_ss,0,10)
sage: soln_tr = lambda t: eˆ(-t)*(-15*sin(2*t)/2-10*cos(2*t))
sage: P_tr = plot(soln_tr,0,10,linestyle="--")
sage: show(P+P_tr)
This plot (the solution superimposed with the transient part of
the solution) is displayed below:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-105-320.jpg)



![for some ξ between 0 and x. Perhaps it is not clear to
everyone that as n becomes larger and larger (x fixed), the
last (“remainder”) term in this sum goes to 0. However,
Stirling’s formula tells us how large the factorial function
grows,
√ n n 1
n! ∼ 2πn (1 + O( )),
e n
so we may indeed take the limit as n → ∞ to get (2.11).
Wikipedia’s entry on “Power series” [P1-ps] has a nice an-
imation showing how more and more terms in the Taylor
polynomials approximate ex better and better.
• The cosine function:
x2 x4 x6
cos x = 1 − + − + ···
2 24 720
x2 x4 x6
=1− + − + ···
2! 4! 6!
∞ 2n
n x
= (−1) (2.12)
n=0
(2n)!
This too follows from Taylor’s theorem (take f (x) = cos x
and a = 0). However, there is another trick: Replace x in
(2.11) by ix and use the fact (“Euler’s formula”) that eix =
cos(x) + i sin(x). Taking real parts gives (2.12). Taking
imaginary parts gives (2.13), below.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-110-320.jpg)




![Solution strategy: Write y(x) = a0 + a1 x + a2 x2 + ... =
∞ k
k=0 ak x , for some real or complex numbers a0 , a1 , ....
• Plug the power series expansions for y, p, q, and f into the
DE (2.15).
• Comparing coeffiients of like powers of x, derive relations
between the aj ’s.
• Using these recurrance relations [R-ps] and the ICs, solve
for the coefficients of the power series of y(x).
Example: Solve y ′ − y = 5, y(0) = −4, using the power series
method.
This is easy to solve by undetermined coefficients: yh (x) = c1 ex
and yp (x) = A1 . Solving for A1 gives A1 = −5 and then solving
for c1 gives −4 = y(0) = −5 + c1 e0 so c1 = 1 so y = ex − 5.
Solving this using power series, we compute
∞
y ′ (x) = a1 + 2a2 x + 3a3 x2 + ... = k=0 (k + 1)ak+1 xk
−y(x) = −a0 − a1 x − a2 x2 − ... = ∞ −ak xk
k=0
− − −− −− − − − − − − − − − − − − − − − − − − − − − − −−
5 = (−a0 + a1 ) + (−a1 + 2a2 )x + ... = ∞ (−ak + (k + 1)ak+1 )xk
k=0
Comparing coefficients,
• for k = 0: 5 = −a0 + a1 ,
• for k = 1: 0 = −a1 + 2a2 ,
• for general k: 0 = −ak + (k + 1)ak+1 for k > 0.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-115-320.jpg)
![The IC gives us −4 = y(0) = a0 , so
a0 = −4, a1 = 1, a2 = 1/2, a3 = 1/6, · · · , ak = 1/k!.
This implies
y(x) = −4 + x + x/2 + · · · + xk /k! + · · · = −5 + ex ,
which is in agreement from the previous discussion.
Example: Solve Bessel’s equation [B-ps] of the 0-th order,
x2 y ′′ + xy ′ + x2 y = 0, y(0) = 1, y ′ (0) = 0,
using the power series method.
This DE is so well-known (it has important applications to
physics and engineering) that the series expansion has already
been worked out (most texts on special functions or differential
equations have this but an online reference is [B-ps]). Its Taylor
series expansion around 0 is:
∞
(−1)m x 2m
J0 (x) =
m=0
m!2 2
for all x. We shall see below that y(x) = J0 (x).
Let us try solving this ourselves using the power series method.
We compute
x2 y ′′ (x) = 0 + 0 · x + 2a2 x2 + 6a3 x3 + 12a4 x4 + ... = ∞ (k + 2)(k +
k=0
∞
xy ′ (x) = 2 3
0 + a1 x + 2a2 x + 3a3 x + ... = k=0 kak x k
x2 y(x) = 0 + 0 · x + a0 x2 + a1 x3 + ... = ∞ ak−2 xk
k=2
− − −− −− − − − − − − − − − − − − − − − − − − − − − − −−
0 = 0 + a1 x + (a0 + 4a2 )x2 + ..... = a1 x + ∞ (ak−2 + k 2 ak )xk .
k=2](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-116-320.jpg)


![2.8 The Laplace transform method
2.8.1 Part 1
The Laplace transform (LT) of a function f (t), defined for all
real numbers t ≥ 0, is the function F (s), defined by:
∞
F (s) = L [f (t)] = e−st f (t) dt.
0
This is named for Pierre-Simon Laplace, one of the best French
mathematicians in the mid-to-late 18th century [L-lt], [LT-lt].
The LT sends “nice” functions of t (we will be more precise later)
to functions of another variable s. It has the wonderful property
that it transforms constant-coefficient differential equations in t
to algebraic questions in s.
The LT has two very familiar properties: Just as the integral
of a sum is the sum of the integrals, the Laplace transform of a
sum is the sum of Laplace transforms:
L [f (t) + g(t)] = L [f (t)] + L [g(t)]
Just as constant factor can be taken outside of an integral, the
LT of a constant times a function is that constant times the LT
of that function:
L [af (t)] = aL [f (t)]
In other words, the LT is linear.
For which functions f is the LT actually defined on? We want
the indefinite integral to converge, of course. A function f (t) is
of exponential order α if there exist constants t0 and M such](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-120-320.jpg)
![that
|f (t)| < M eαt , for all t > t0 .
t
If 0 0 f (t) dt exists and f (t) is of exponential order α then the
Laplace transform L [f ] (s) exists for s > α.
Example 2.8.1. Consider the Laplace transform of f (t) = 1.
The LT integral converges for s > 0.
∞
L [f ] (s) = e−st dt
0
∞
1
= − e−st
s 0
1
=
s
Example 2.8.2. Consider the Laplace transform of f (t) = eat .
The LT integral converges for s > a.
∞
L [f ] (s) = e(a−s)t dt
0
∞
1 (a−s)t
= − e
s−a 0
1
=
s−a
Example 2.8.3. Consider the Laplace transform of the unit step
(Heaviside) function,
0 for t < c
u(t − c) =
1 for t > c,](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-121-320.jpg)
![where c > 0.
∞
L[u(t − c)] = e−st H(t − c) dt
0
∞
= e−st dt
c
∞
e−st
=
−s c
e−cs
= for s > 0
s
The inverse Laplace transform in denoted
f (t) = L−1 [F (s)](t),
where F (s) = L [f (t)] (s).
Example 2.8.4. Consider
1, for t < 2,
f (t) =
0, on t ≥ 2.
We show how SAGE can be used to compute the LT of this.
SAGE
sage: t = var(’t’)
sage: s = var(’s’)
sage: f = Piecewise([[(0,2),1],[(2,infinity),0]])
sage: f.laplace(t, s)
1/s - eˆ(-(2*s))/s
sage: f1 = lambda t: 1
sage: f2 = lambda t: 0
sage: f = Piecewise([[(0,2),f1],[(2,10),f2]])
sage: P = f.plot(rgbcolor=(0.7,0.1,0.5),thickness=3)
sage: show(P)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-122-320.jpg)
![According to SAGE , L [f ] (s) = 1/s − e−2s /s. Note the function
f was redefined for plotting purposes only (the fact that it was
redefined over 0 < t < 10 means that SAGE will plot it over that
range.) The plot of this function is displayed below:
Figure 2.19: The piecewise constant function 1 − u(t − 2).
Next, some properties of the LT.
• Differentiate the definition of the LT with respect to s:
∞
′
F (s) = − e−st tf (t) dt.
0
Repeating this:
∞
dn
n
F (s) = (−1)n e−st tn f (t) dt. (2.16)
ds 0
• In the definition of the LT, replace f (t) by it’s derivative
f ′ (t):
∞
′
L [f (t)] (s) = e−st f ′ (t) dt.
0](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-123-320.jpg)
![Now integrate by parts (u = e−st , dv = f ′ (t) dt):
∞ ∞
−st ′
e f (t) dt = f (t)e−st |∞ −
0 f (t)·(−s)·e−st dt = −f (0)+sL [f (t)] (
0 0
Therefore, if F (s) is the LT of f (t) then sF (s) − f (0) is the
LT of f ′ (t):
L [f ′ (t)] (s) = sL [f (t)] (s) − f (0). (2.17)
• Replace f by f ′ in (2.17),
L [f ′′ (t)] (s) = sL [f ′ (t)] (s) − f ′ (0), (2.18)
and apply (2.17) again:
L [f ′′ (t)] (s) = s2 L [f (t)] (s) − sf (0) − f ′ (0), (2.19)
• Using (2.17) and (2.19), the LT of any constant coefficient
ODE
ax′′ (t) + bx′ (t) + cx(t) = f (t)
is
a(s2 L [x(t)] (s) − sx(0) − x′ (0)) + b(sL [x(t)] (s) − x(0)) + cL [x(t)] (s) = F (s),
where F (s) = L [f (t)] (s). In particular, the LT of the
solution, X(s) = L [x(t)] (s), satisfies
X(s) = (F (s) + asx(0) + ax′ (0) + bx(0))/(as2 + bs + c).](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-124-320.jpg)
![Note that the denominator is the characteristic polynomial
of the DE.
Moral of the story: it is always very easy to compute the LT
of the solution to any constant coefficient non-homogeneous
linear ODE.
Example 2.8.5. We know now how to compute not only the
LT of f (t) = eat (it’s F (s) = (s − a)−1 ) but also the LT of any
function of the form tn eat by differentiating it:
L teat = −F ′ (s) = (s−a)−2 , L t2 eat = F ′′ (s) = 2·(s−a)−3 , L t3 eat = −F ′ (s) =
and in general
L tn eat = −F ′ (s) = n! · (s − a)−n−1 . (2.20)
Example 2.8.6. Let us solve the DE
x′ + x = t100 e−t , x(0) = 0.
using LTs. Note this would be highly impractical to solve using
undetermined coefficients. (You would have 101 undetermined
coefficients to solve for!)
First, we compute the LT of the solution to the DE. The LT of
the LHS: by (2.20),
L [x′ + x] = sX(s) + X(s),
where F (s) = L [f (t)] (s). For the LT of the RHS, let
1
F (s) = L e−t = .
s+1
By (2.16),](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-125-320.jpg)
![d100 100 −t d100 1
F (s) = L t e = 100 .
ds100 ds s + 1
1
The first several derivatives of s+1 are as follows:
d 1 1 d2 1 1 d3 1 1
=− , =2 , = −62 ,
ds s + 1 (s + 1)2 ds2 s + 1 (s + 1)3 ds3 s + 1 (s + 1)4
and so on. Therefore, the LT of the RHS is:
d100 1 1
= 100! .
ds100 s + 1 (s + 1)101
Consequently,
1
X(s) = 100! .
(s + 1)102
Using (2.20), we can compute the ILT of this:
1 1 −1 1 1
x(t) = L−1 [X(s)] = L−1 100! = L 101! = t
(s + 1)102 101 (s + 1)102 101
Example 2.8.7. Let us solve the DE
x′′ + 2x′ + 2x = e−2t , x(0) = x′ (0) = 0,
using LTs.
The LT of the LHS: by (2.20) and (2.18),
L [x′′ + 2x′ + 2x] = (s2 + 2s + 2)X(s),
as in the previous example. The LT of the RHS is:
1
L e−2t = .
s+2](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-126-320.jpg)
![Solving for the LT of the solution algebraically:
1
X(s) = .
(s + 2)((s + 1)2 + 1)
The inverse LT of this can be obtained from LT tables after
rewriting this using partial fractions:
1 1 1 s 1 1 1 s+1 1 1
X(s) = · − = · − + .
2 s + 2 2 (s + 1)2 + 1 2 s + 2 2 (s + 1)2 + 1 2 (s + 1)2 + 1
The inverse LT is:
1 −2t 1 −t 1
x(t) = L−1 [X(s)] = · e − · e cos(t) + · e−t sin(t).
2 2 2
We show how SAGE can be used to do some of this.
SAGE
sage: t = var(’t’)
sage: s = var(’s’)
sage: f = 1/((s+2)*((s+1)ˆ2+1))
sage: f.partial_fraction()
1/(2*(s + 2)) - s/(2*(sˆ2 + 2*s + 2))
sage: f.inverse_laplace(s,t)
eˆ(-t)*(sin(t)/2 - cos(t)/2) + eˆ(-(2*t))/2
Exercise: Use SAGE to solve the DE
x′′ + 2x′ + 5x = e−t , x(0) = x′ (0) = 0.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-127-320.jpg)
,
then
L
f (t)u(t − c) −→ e−cs L[f (t + c)](s), (2.21)
and
L
f (t − c)u(t − c) −→ e−cs F (s). (2.22)
These two properties are called translation theorems.
Example 2.8.8. First, consider the Laplace transform of the
piecewise-defined function f (t) = (t − 1)2 u(t − 1). Using (2.22),
this is
1 −s
L[f (t)] = e−s L[t2 ](s) = 2 e .
s3
Second, consider the Laplace transform of the piecewise-constant
function
0
for t < 0,
f (t) = −1 for 0 ≤ t ≤ 2,
1 for t > 2.
](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-128-320.jpg)
![This can be expressed as f (t) = −u(t) + 2u(t − 2), so
L[f (t)] = −L[u(t)] + 2L[u(t − 2)]
1 1
= − + 2 e−2s .
s s
Finally, consider the Laplace transform of f (t) = sin(t)u(t−π).
Using (2.21), this is
1
L[f (t)] = e−πs L[sin(t+π)](s) = e−πs L[− sin(t)](s) = −e−πs .
s2 +1
The plot of this function f (t) = sin(t)u(t − π) is displayed below:
Figure 2.20: The piecewise continuous function u(t − π) sin(t).
We show how SAGE can be used to compute these LTs.
SAGE
sage: t = var(’t’)
sage: s = var(’s’)
sage: assume(s>0)
sage: f = Piecewise([[(0,1),0],[(1,infinity),(t-1)ˆ2]])
sage: f.laplace(t, s)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-129-320.jpg)
![2*eˆ(-s)/sˆ3
sage: f = Piecewise([[(0,2),-1],[(2,infinity),2]])
sage: f.laplace(t, s)
3*eˆ(-(2*s))/s - 1/s
sage: f = Piecewise([[(0,pi),0],[(pi,infinity),sin(t)]])
sage: f.laplace(t, s)
-eˆ(-(pi*s))/(sˆ2 + 1)
sage: f1 = lambda t: 0
sage: f2 = lambda t: sin(t)
sage: f = Piecewise([[(0,pi),f1],[(pi,10),f2]])
sage: P = f.plot(rgbcolor=(0.7,0.1,0.5),thickness=3)
sage: show(P)
The plot given by these last few commands is displayed above.
Before turning to differential equations, let us introduce con-
volutions.
Let f (t) and g(t) be continuous (for t ≥ 0 - for t < 0, we
assume f (t) = g(t) = 0). The convolution of f (t) and g(t) is
defined by
t t
(f ∗ g) = f (u)g(t − u) du = f (t − u)g(u) du.
0 0
The convolution theorem states
L[f ∗ g(t)](s) = F (s)G(s) = L[f ](s)L[g](s).
The LT of the convolution is the product of the LTs. (Or, equiv-
alently, the inverse LT of the product is the convolution of the
inverse LTs.)
To show this, do a change-of-variables in the following double
integral:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-130-320.jpg)
 = e−st f (u)g(t − u) du dt
0 0
∞ ∞
= e−st f (u)g(t − u) dt du
0 u
∞ ∞
−su
= e f (u) e−s(t−u) g(t − u) dt du
0 u
∞ ∞
−su
= e f (u) du e−sv g(v) dv
0 0
= L[f ](s)L[g](s).
1
Example 2.8.9. Consider the inverse Laplace transform of s3 −s2 .
This can be computed using partial fractions and LT tables.
However, it can also be computed using convolutions.
First we factor the denominator, as follows
1 1 1
= 2 .
s3 − s2 s s−1
We know the inverse Laplace transforms of each term:
1 1
L−1
2
= t, L−1 = et
s s−1
We apply the convolution theorem:
t
−1 1 1
L = uet−u du
s2 s − 1 0
t
t t
=e −ue−u 0 −e t
−e−u du
0
t
= −t − 1 + e
Therefore,](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-131-320.jpg)
 = (1/s)5 = = F (s).
s5
4!
We know from LT tables that L−1 s5 (t) = t4 , so
1 −1 4! 1
f (t) = L−1 [F (s)] (t) = L (t) = t4 .
4! s5 4!
Now let us turn to solving a DE of the form
ay ′′ + by ′ + cy = f (t), y(0) = y0 , y ′ (0) = y1 . (2.23)
First, take LTs of both sides:
as2 Y (s) − asy0 − ay1 + bsY (s) − by0 + cY (s) = F (s),
so
1 asy0 + ay1 + by0
Y (s) = F (s) + . (2.24)
as2 + bs + c as2 + bs + c
1
The function as2 +bs+c is sometimes called the transfer function
(this is an engineering term) and it’s inverse LT,](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-132-320.jpg)



![3.1 An introduction to systems of DEs: Lanch-
ester’s equations
The goal of military analysis is a means of reliably predicting
the outcome of military encounters, given some basic informa-
tion about the forces’ status. The case of two combatants in an
“aimed fire” battle was solved during World War I by Frederick
William Lanchester, a British engineer in the Royal Air Force,
who discovered a way to model battle-field casualties using sys-
tems of differential equations. He assumed that if two armies
fight, with x(t) troops on one side and y(t) on the other, the
rate at which soldiers in one army are put out of action is pro-
portional to the troop strength of their enemy. This give rise to
the system of differential equations
x′ (t) = −Ay(t), x(0) = x0 ,
y ′ (t) = −Bx(t), y(0) = y0 ,
where A > 0 and B > 0 are constants (called their fighting effec-
tiveness coefficients) and x0 and y0 are the intial troop strengths.
For some historical examples of actual battles modeled using
Lanchester’s equations, please see references in the paper by
McKay [M-intro].
We show here how to solve these using Laplace transforms.
Example: A battle is modeled by
x′ = −4y, x(0) = 150,
y ′ = −x, y(0) = 90.
(a) Write the solutions in parameteric form. (b) Who wins?
When? State the losses for each side.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-136-320.jpg)
![soln: Take Laplace transforms of both sides:
sL [x (t)] (s) − x (0) = −4 L [y (t)] (s),
sL [x (t)] (s) − x (0) = −4 L [y (t)] (s).
Solving these equations gives
sx (0) − 4 y (0) 150 s − 360
L [x (t)] (s) = = ,
s2 − 4 s2 − 4
−sy (0) + x (0) −90 s + 150
L [y (t)] (s) = − =− .
s2 − 4 s2 − 4
Laplace transform Tables give
x(t) = −15 e2 t + 165 e−2 t
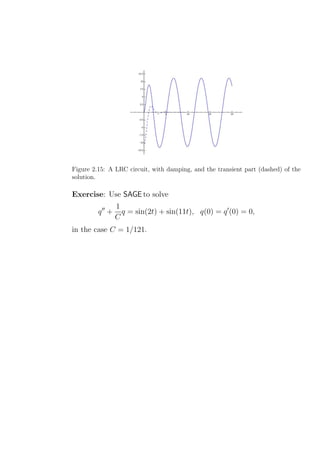
y(t) = 90 cosh (2 t) − 75 sinh (2 t)
Their graph looks like
The “y-army” wins. Solving for x(t) = 0 gives twin = log(11)/4 =
.5994738182..., so the number of survivors is y(twin ) = 49.7493718,
so 49 survive.
Lanchester’s square law: Suppose that if you are more inter-
ested in y as a function of x, instead of x and y as functions of
t. One can use the chain rule form calculus to derive from the
system x′ (t) = −Ay(t), y ′ (t) = −Bx(t) the single equation
dy Bx
= .
dx Ay
This differential equation can be solved by the method of sepa-
ration of variables: Aydy = Bxdx, so
Ay 2 = Bx2 + C,](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-137-320.jpg)
![x(0) are initially placed in a fighting capacity and T − x(0) are
in a support role. If your tropps outnumber the enemy then you
want to choose the number of support units to be the smallest
number such that the fighting effectiveness is not decreasing
(therefore is roughly constant). The remainer should be engaged
with the enemy in battle [M-intro].
A battle between three forces gives rise to the differential equa-
tions
′
x (t) = −A1 y(t) − A2 z(t), x(0) = x0 ,
y ′ (t) = −B1 x(t) − B2 z(t), y(0) = y0 ,
′
z (t) = −C1 x(t) − C2 y(t), z(0) = z0 ,
where Ai > 0, Bi > 0, and Ci > 0 are constants and x0 , y0 and
z0 are the intial troop strengths.
Example: Consider the battle modeled by
′
x (t) = −y(t) − z(t), x(0) = 100,
′
y (t) = −2x(t) − 3z(t), y(0) = 100,
′
z (t) = −2x(t) − 3y(t), z(0) = 100.
The Y-men and Z-men are better fighters than the X-men, in the
sense that the coefficient of z in 2nd DE (describing their battle
with y) is higher than that coefficient of x, and the coefficient of
y in 3rd DE is also higher than that coefficient of x. However,
as we will see, the worst fighter wins!
Taking Laplace transforms, we obtain the system
sX(s) + Y (s) + Z(s) = 100
2X(s) + sY (s) + 3Z(s) = 100,
2X(s) + 3Y (s) + sZ(s) = 100,
](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-139-320.jpg)



![4. the pivot position of the ith row is to the left and above
the pivot position of the (i + 1)st row (therefore, all entries
below the diagonal of B are 0).
This matrix B is unique (this is a theorem which you can find
in any text on elementary matrix theory or linear algebra1 ) and
is called the row reduced echelon form of A, sometimes written
rref (A).
Two comments: (1) If you are your friend both start out play-
ing this game, it is likely your choice of legal moves will differ.
That is to be expected. However, you must get the same result
in the end. (2) Often if someone is to get “stuck” it is becuase
they forget that one of the goals is to “kill as many terms as
possible (i.e., you need B to have as many 0’s as possible). If
you forget this you might create non-zero terms in the matrix
while killing others. You should try to think of each move as
being made in order to to kill a term. The exception is at the
very end where you can’t kill any more terms but you want to
do row swaps to put it in diagonal form.
Now it’s time for an example.
Example: Solve
x + 2y = 3
(3.2)
4x + 5y = 6
The augmented matrix is
1 2 3
A=
4 5 6
One sequence of legal moves is the following:
1
For example, [B-rref] or [H-rref].](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-144-320.jpg)

![1 2 3
4 5 6
using SAGE , just type the following:
SAGE
sage: MS = MatrixSpace(QQ,2,3)
sage: A = MS([[1,2,3],[4,5,6]])
sage: A
[1 2 3]
[4 5 6]
sage: A.echelon_form()
[ 1 0 -1]
[ 0 1 2]
Solving systems using inverses
There is another method of solving “square” systems of linear
equations which we discuss next.
One can rewrite the system (3.1) as a single matrix equation
a b x r1
= ,
c d y r2
or more compactly as
AX = r, (3.4)
x r1
where X = and r = . How do you solve (3.4)?
y r2
The obvious this to do (“divide by A”) is the right idea:
x
= X = A−1 r.
y](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-146-320.jpg)
![Here A−1 is a matrix with the property that A−1 A = I, the
identity matrix (which satisfies I X = X).
If A−1 exists (and it usually does), how do we compute it?
There are a few ways. One, if using a formula. In the 2 × 2 case,
the inverse is given by
−1
a b 1 d −b
= .
c d ad − bc −c a
There is a similar formula for larger sized matrices but it is so
unwieldy that is is usually not used to compute the inverse. In
the 2 × 2 case, it is easy to use and we see for example,
−1
1 2 1 5 −2 −5/3 2/3
= = .
4 5 −3 −4 1 4/3 −1/3
To find the inverse of
1 2
4 5
using SAGE , just type the following:
SAGE
sage: MS = MatrixSpace(QQ,2,2)
sage: A = MS([[1,2],[4,5]])
sage: A
[1 2]
[4 5]
sage: Aˆ(-1)
[-5/3 2/3]
[ 4/3 -1/3]
A better way to compute A−1 is the following. Compute the
row reduced echelon form of the matrix (A, I), where I is the](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-147-320.jpg)

![−5/3 2/3
A−1 = .
4/3 −1/3
Now, to solve the system, compute
−1
x 1 2 3 −5/3 2/3 3 −1
= = = .
y 4 5 6 4/3 −1/3 6 2
To make SAGE do the above computation, just type the follow-
ing:
SAGE
sage: MS = MatrixSpace(QQ,2,2)
sage: A = MS([[1,2],[4,5]])
sage: V = VectorSpace(QQ,2)
sage: v = V([3,6])
sage: Aˆ(-1)*v
(-1, 2)
Application: Solving systems of DEs
Suppose we have a system of DEs in “standard form”
x′ = ax + by + f (t), x(0) = x0 ,
(3.5)
y ′ = cx + dy + g(t), y(0) = y0 ,
where a, b, c, d, x0 , y0 are given constants and f (t), g(t) are given
“nice” functions. (Here “nice” will be left vague but basically
we don’t want these functions to annoy us with any bad be-
haviour while trying to solve the DEs by the method of Laplace
transforms.)
One way to solve this system if to take Laplace transforms of
both sides. If we let](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-149-320.jpg)
, Y (s) = L[y(t)](s), F (s) = L[f (t)](s), G(s) = L[g(t)](s),
then (3.5) becomes
sX(s) − x0 = aX(s) + bY (s) + F (s),
(3.6)
sY (s) − y0 = cX(s) + dY (s) + G(s).
This is now a 2 × 2 system of linear equations in the unknowns
X(s), Y (s) with augmented matrix
s − a −b F (s) + x0
A= .
−c s − d G(s) + y0
Example: Solve
x′ = −y + 1, x(0) = 0,
y ′ = −x + t, y(0) = 0,
The augmented matrix is
s 1 1/s
A= .
1 s 1/s2
The row reduced echelon form of this is
1 0 1/s2
.
0 1 0
Therefore, X(s) = 1/s2 and Y (s) = 0. Taking inverse Laplace
transforms, we see that the solution to the system is x(t) = t
and y(t) = 0. It is easy to check that this is indeed the solution.
To make SAGE compute the row reduced echelon form, just
type the following:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-150-320.jpg)
![SAGE
sage: R = PolynomialRing(QQ,"s")
sage: F = FractionField(R)
sage: s = F.gen()
sage: MS = MatrixSpace(F,2,3)
sage: A = MS([[s,1,1/s],[1,s,1/sˆ2]])
sage: A.echelon_form()
[ 1 0 1/sˆ2]
[ 0 1 0]
To make SAGE compute the Laplace transform, just type the
following:
SAGE
sage: maxima("laplace(1,t,s)")
1/s
sage: maxima("laplace(t,t,s)")
1/sˆ2
To make SAGE compute the inverse Laplace transform, just
type the following:
SAGE
sage: maxima("ilt(1/sˆ2,s,t)")
t
sage: maxima("ilt(1/(sˆ2+1),s,t)")
sin(t)
Example: Solve
x′ = −4y, x(0) = 400,
y ′ = −x, y(0) = 100,](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-151-320.jpg)

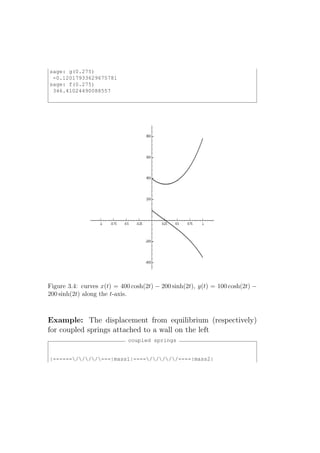
![spring1 spring2
is modeled by the system of 2nd order ODEs
m1 x′′ + (k1 + k2 )x1 − k2 x2 = 0,
1 m2 x′′ + k2 (x2 − x1 ) = 0,
2
where x1 denotes the displacement from equilibrium of mass
1, denoted m1 , x2 denotes the displacement from equilibrium
of mass 2, denoted m2 , and k1 , k2 are the respective spring
constants [CS-rref].
As another illustration of solving linear systems of equations to
solving systems of linear 1st order DEs, we use SAGE to solve the
above problem with m1 = 2, m2 = 1, k1 = 4, k2 = 2, x1 (0) = 3,
x′1 (0) = 0, x2 (0) = 3, x′2 (0) = 0.
Soln: Take Laplace transforms of the first DE (for simplicity
of notation, let x = x1 , y = x2 ):
SAGE +Maxima
sage: _ = maxima.eval("x2(t) := diff(x(t),t, 2)")
sage: maxima("laplace(2*x2(t)+6*x(t)-2*y(t),t,s)")
2*(-?%at(’diff(x(t),t,1),t=0)+sˆ2*?%laplace(x(t),t,s)-x(0)*s)-2*?%laplace(y(t),t,s)+6*?%laplace(x(t),t,s)
This says −2x′1 (0) + 2s2 ∗ X1 (s) − 2sx1 (0) − 2X2 (s) + 2X1 (s) = 0
(where the Laplace transform of a lower case function is the
upper case function). Take Laplace transforms of the second
DE:
SAGE +Maxima
sage: _ = maxima.eval("y2(t) := diff(y(t),t, 2)")
sage: maxima("laplace(y2(t)+2*y(t)-2*x(t),t,s)")
-?%at(’diff(y(t),t,1),t=0)+sˆ2*?%laplace(y(t),t,s)+2*?%laplace(y(t),t,s)-2*?%laplace(x(t),t,s)-y(0)*s
This says s2 X2 (s) + 2X2 (s) − 2X1 (s) − 3s = 0. Solve these two
equations:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-154-320.jpg)
![SAGE
sage: s,X,Y = var(’s X Y’)
sage: eqns = [(2*sˆ2+6)*X-2*Y == 6*s, -2*X +(sˆ2+2)*Y == 3*s]
sage: solve(eqns, X,Y)
[[X == (3*sˆ3 + 9*s)/(sˆ4 + 5*sˆ2 + 4),
Y == (3*sˆ3 + 15*s)/(sˆ4 + 5*sˆ2 + 4)]]
This says X1 (s) = (3s3 + 9s)/(s4 + 5s2 + 4), X2 (s) = (3s3 +
15s)/(s4 + 5s2 + 4). Take inverse Laplace transforms to get the
answer:
SAGE
sage: s,t = var(’s t’)
sage: inverse_laplace((3*sˆ3 + 9*s)/(sˆ4 + 5*sˆ2 + 4),s,t)
cos(2*t) + 2*cos(t)
sage: inverse_laplace((3*sˆ3 + 15*s)/(sˆ4 + 5*sˆ2 + 4),s,t)
4*cos(t) - cos(2*t)
Therefore, x1 (t) = cos(2t) + 2 cos(t), x2 (t) = 4 cos(t) − cos(2t).
Using SAGE , this can be plotted parametrically using
SAGE
sage: P = parametric_plot([cos(2*t) + 2*cos(t),4*cos(t) - cos(2*t)],0,3)
sage: show(P)
You can also try
SAGE +Maxima
sage.: maxima.plot2d(’cos(2*x) + 2*cos(x)’,’[x,0,1]’,’[plot_format, openmath]’)
for the output of a slightly different looking plotting program.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-155-320.jpg)
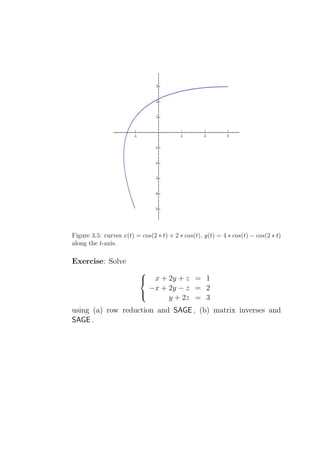


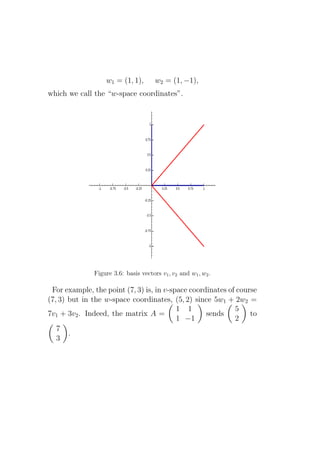

![Since this section is only intended to be motivation, we shall
not prove this here (see any text on linear algebra, for example
[B-rref] or [H-rref]).
SAGE
sage: MS = MatrixSpace(CC,2,2)
sage: A = MS([[0,1],[1,0]])
sage: A.eigenspaces()
[
(1.00000000000000, [
(1.00000000000000, 1.00000000000000)
]),
(-1.00000000000000, [
(1.00000000000000, -1.00000000000000)
])
]](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-161-320.jpg)

![You can use the quadratic formula, for example to get them:
a+d (a + d)2 − 4(ad − bc) a+d (a + d)2 − 4(ad − bc)
λ1 = + , λ2 = − .
2 2 2 2
• Find the eigenvectors. If b = 0 then you can use the for-
mulas
b b
v1 = , v2 = .
λ1 − a λ2 − a
In general, you can get them by solving the eigenvector
equation Av = λv.
SAGE
sage: MS = MatrixSpace(CC,2,2)
sage: A = MS([[1,2],[3,4]])
sage: A.eigenspaces()
[
(-0.372281323269014, [
(1.00000000000000, -0.457427107756338)
]),
(5.37228132326901, [
(1.00000000000000, 1.45742710775634)
])
]
• Plug these into the following formulas:
(a) λ1 = λ2 , real:
x(t)
= c1 v1 exp(λ1 t) + c2 v2 exp(λ2 t).
y(t)
(b) λ1 = λ2 = λ, real:
x(t)
= c1 v1 exp(λt) + c2 (v1 t + p) exp(λt),
y(t)](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-163-320.jpg)
![where p is any non-zero vector satisfying (A − λI)p =
v1 .
(c) λ1 = α + iβ, complex: write v1 = u1 + iu2 , where u1
and u2 are both real vectors.
x(t)
= c1 [exp(αt) cos(βt)u1 − exp(αt) sin(βt)u2 ]
y(t)
+c2 [− exp(αt) cos(βt)u2 − exp(αt) sin(βt)u1 ].
Examples
Example 3.3.1. Solve
x′ (t)) = x(t)−y(t), y ′ (t) = 4x(t)+y(t), x(0) = −1, y(0) = 1.
Let
1 −1
A=
4 1
and so the characteristc polynomial is
p(x) = det(A − xI) = x2 − 2x + 5.
The eigenvalues are
λ1 = 1 + 2i, λ2 = 1 − 2i,
so α = 1 and β = 2. Eigenvectors v1 , v2 are given by
−1 −1
v1 = , v2 = ,
2i −2i
though we actually only need to know v1 . The real and imaginary
parts of v1 are
−1 0
u1 = , u2 = .
0 2](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-164-320.jpg)



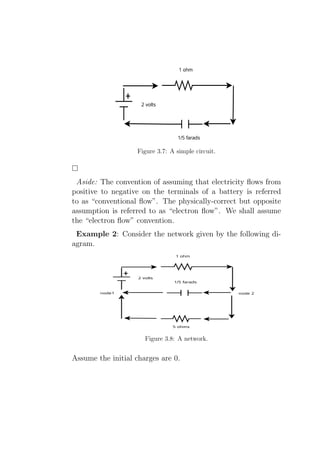

![We therefore have this matrix equation
0 5 s Q1 (s) 2/s
5s 0 s Q2 (s) = 2/s .
1 1 −1 Q3 (s) 0
The augmented matrix describing this system is
0 5 s 2/s
5s 0 s 2/s
1 1 −1 0
The row-reduced echelon form is
2/(s3 + 6s2 )
1 0 0
0 1 0 2/(s2 + 6s)
0 0 1 2(s + 1)/(s3 + 6s2 )
Therefore
2 2 2(s + 1)
Q1 (s) = , Q2 (s) = , Q3 (s) = .
s3 + 6s2 s2 + 6s s2 (s + 6)
This implies
q1 (t) = −1/18+e−6t /18+t/3, q2 (t) = 1/3−e−6t /3, q3 (t) = q2 (t)+q1 (t).
This computation can be done in SAGE as well:
SAGE
sage: s = var("s")
sage: MS = MatrixSpace(SymbolicExpressionRing(), 3, 4)
sage: A = MS([[0,5,s,2/s],[5*s,0,s,2/s],[1,1,-1,0]])
sage: B = A.echelon_form(); B](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-170-320.jpg)
![[ 1 0 0 2/(5*sˆ2) - (-2/(5*s) - 2/(5*sˆ2))/(5*(-s/5 - 6/5))]
[ 0 1 0 2/(5*s) - (-2/(5*s) - 2/(5*sˆ2))*s/(5*(-s/5 - 6/5)) ]
[ 0 0 1 (-2/(5*s) - 2/(5*sˆ2))/(-s/5 - 6/5) ]
sage: Q1 = B[0,3]
sage: t = var("t")
sage: Q1.inverse_laplace(s,t)
eˆ(-(6*t))/18 + t/3 - 1/18
sage: Q2 = B[1,3]
sage: Q2.inverse_laplace(s,t)
1/3 - eˆ(-(6*t))/3
sage: Q3 = B[2,3]
sage: Q3.inverse_laplace(s,t)
-5*eˆ(-(6*t))/18 + t/3 + 5/18
Example 3: Consider the network given by the following dia-
gram.
Figure 3.9: Another network.
Assume the initial charges are 0.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-171-320.jpg)
, I2 (s) = L[i2 (t)](s), and I3 (s) =
L[i3 (t)](s). The augmented matrix of this system is
1 −1 −1 0
2 + s/5 1 0 6/s
0 −1 s/10 0
(Check this yourself!) The row-reduced echelon form is
30(s+10)
1 0 0 s(s2 +25s+100)
30
0 1 0 s2 +25s+100
300
0 0 1 s(s2 +25s+100)
Therefore
1 2 3 2 2 1 4
I1 (s) = − − + , I2 (s) = − + , I3 (s) = −
s + 20 s + 5 s s + 20 s + 5 s + 20 s +
This implies
i1 (t) = 3−2e−5t −e−20t , i2 (t) = 2e−5t −2e−20t , i3 (t) = 3−4e−5t +e−20t .
Exercise: Use SAGE to solve for i1 (t), i2 (t), and i3 (t) in the
above problem.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-172-320.jpg)

![PDE which arises in applications and use it to introduce the
method of solution called separation of variables.
The transport or advection equation
Advection is the transport of a some conserved scalar quantity
in a vector field. A good example is the transport of pollutants
or silt in a river (the motion of the water carries these impurities
downstream) or traffic flow.
The advection equation is the PDE governing the motion of
a conserved quantity as it is advected by a given velocity field.
The advection equation expressed mathematically is:
∂u
+ ∇ · (ua) = 0
∂t
where ∇· is the divergence and a is the velocity field of the fluid.
Frequently, it is assumed that ∇ · a = 0 (this is expressed by
saying that the velocity field is solenoidal). In this case, the
above equation reduces to
∂u
+ a · ∇u = 0.
∂t
Assume we have horizontal pipe in which water is flowing at a
constant rate c in the positive x direction. Add some salt to this
water and let u(x, t) denote the concentration (say in lbs/gallon)
at time t. Note that the amount of salt in an interval I of the
pipe is I u(x, t) dx. This concentration satisfies the transport
(or advection) equation:
ut + cux = 0.
(For a derivation of this, see for example Strauss [S-pde], §1.3.)
How do we solve this?](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-174-320.jpg)

![′
constant. (Indeed, try taking the partial derivative of T (t) with
T
(t)
respect to x. You get 0 since it doesn’t depend on x. Therefore,
′ ′
the partial derivative of −c X (x) is akso 0, so X (x) is a constant!)
X(x) X(x)
′ ′
Therefore, T (t) = −c X (x) = K, for some (unknown) constant
T
(t)
X(x)
K. So, we have two ODEs:
T ′ (t) X ′ (x)
= K, = −K/c.
T (t) X(x)
Therefore, we can converted the PDE into two ODEs. Solving,
we get
T (t) = c1 eKt , X(x) = c2 e−Kx/c ,
K
so, u(x, t) = AeKt−Kx/c = Ae− c (x−ct) , for some constants K
and A (where A is shorthand for c1 c2 ; in terms of D’Alembert’s
K
solution, f (y) = Ae− c (y) ). The “general solution” is a sum of
these (for various A’s and K’s).
This can also be done in SAGE :
SAGE
sage: t = var("t")
sage: T = function("T",t)
sage: K = var("K")
sage: T0 = var("T0")
sage: maxima.de_solve(’diff(T,t) =
K*T’, [’t’,’T’], [0,T0])
T=%eˆ(t*K)*T0
sage: x = var("x")
sage: X = function("X",x)
sage: c = var("c")
sage: X0 = var("X0")
sage: maxima.de_solve(’diff(X,x) =
-cˆ(-1)*K*X’, [’x’,’X’], [0,X0])
X=%eˆ-(x*K/c)*X0
sage: solnX = maxima.de_solve(’diff(X,x) =](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-176-320.jpg)
![-cˆ(-1)*K*X’, [’x’,’X’], [0,X0])
sage: solnX.rhs()
%eˆ-(x*K/c)*X0
sage: solnT = maxima.de_solve(’diff(T,t) =
K*T’, [’t’,’T’], [0,T0])
sage: solnT.rhs()
%eˆ(t*K)*T0
sage: solnT.rhs()*solnX.rhs()
%eˆ(t*K-x*K/c)*T0*X0
Example: Assume water is flowing along a horizontal pipe at
3 gal/min in the x direction and that there is an initial con-
centration of salt distributed in the water with concentration of
u(x, 0) = e−x . Using separation of variables, find the concentra-
tion at time t. Plot this for various values of t.
Solution: The method of separation of variables gives the “sep-
arated form” of the solution to the transport PDE as u(x, t) =
AeKt−Kx/c , where c = 3. The initial condition implies
e−x = u(x, 0) = AeK·0−Kx/c = Ae−Kx/3 ,
so A = 1 and K = 3. Therefore, u(x, t) = e3t−x . In other words,
the salt concentration is increasing in time. This makes sense if
you think about it this way: “freeze” the water motion at time
t = 0. There is a lot of salt at the beginning of the pipe and
less and less salt as you move along the pipe. Now go down the
pipe in the x-direction some amount where you can barely tell
there is any salt in the water. Now “unfreeze” the water motion.
Looking along the pipe, you see the concentration is increasing
since the saltier water is now moving toward you.
This is produced using either the Maxima command](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-177-320.jpg)
![Figure 4.1: Transport with velocity c = 3.
Maxima
(%i1) plot3d(exp(3*t-x),[x,0,2],[t,0,2],[grid,12,12]);
or the SAGE command
SAGE
sage: maxima.plot3d ("exp(3*t-x)", "[x,0,2]", "[t,0,2]",
"[grid,12,12]", ’[plot_format, openmath]’)
In both cases, wish and tcl/tk must also be installed.
What if the initial concentration was not u(x, 0) = e−x but
instead u(x, 0) = e−x + 3e−5x ? How does the solution to
ut + 3ux = 0, u(x, 0) = e−x + 3e−5x , (4.1)
differ from the method of solution used above? In this case, we
must use the fact that (by superposition) “the general solution”
is of the form](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-178-320.jpg)


![theorem below for a more precise description of what happens).
Definitions: Let f (x) be a function defined on an interval of
the real line. We allow f (x) to be discontinuous but the points
in this interval where f (x) is discontinuous must be finite in
number and must be jump discontinuities.
First, we discuss Fourier series. To have a Fourier series you
must be given two things: (1) a “period” P = 2L, (2) a function
f (x) defined on an interval of length 2L, usually we take −L <
x < L (but sometimes 0 < x < 2L is used instead). The Fourier
series of f (x) with period 2L is
∞
a0 nπx nπx
f (x) ∼ + [an cos( ) + bn sin( )],
2 n=1
L L
where an and bn are given by the formulas2 ,
L
1 nπx
an = f (x) cos( ) dx, (4.3)
L −L L
and
1 L nπx
bn = f (x) sin( ) dx. (4.4)
L −L L
Next, we discuss cosine series. To have a cosine series you must
be given two things: (1) a “period” P = 2L, (2) a function f (x)
defined on the interval of length L, 0 < x < L. The cosine
series of f (x) with period 2L is
∞
a0 nπx
f (x) ∼ + an cos( ),
2 n=1
L
where an is given by
2
These formulas were not known to Fourier. To compute the Fourier coefficients an , bn
he used sometimes ingenious round-about methods using large systems of equations.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-181-320.jpg)

![resp.. The meaning of ∼ is that the series does necessarily not
converge to the value of f (x) at every point3 . The convergence
proprties are given by the theorem below.
Dirichlet’s theorem4 : Let f (x) be a function as above and
let −L < x < L. The Fourier series of f (x),
∞
a0 nπx nπx
f (x) ∼ + [an cos( ) + bn sin( )],
2 n=1
L L
(where an and bn are as in the formulas (4.3), (4.4)) converges
to
f (x+) + f (x−)
.
2
In other words, the Fourier series of f (x) converges to f (x) only
if f (x) is continuous at x. If f (x) is not continuous at x then
then Fourier series of f (x) converges to the “midpoint of the
jump”.
Examples: (1) If f (x) = 2+x, −2 < x < 2, then the definition
of L implies L = 2. Without even computing the Fourier series,
we can evaluate it using Dirichlet’s theorem.
Question: Using periodicity and Dirichlet’s theorem, find the
value that the Fourier series of f (x) converges to at x = 1, 2, 3.
(Ans: f (x) is continuous at 1, so the FS at x = 1 converges to f (1) = 3 by
Dirichlet’s theorem. f (x) is not defined at 2. It’s FS is periodic with period 4, so at
f (2+)+f (2−) 0+4
x = 2 the FS converges to 2 = 2 = 2. f (x) is not defined at 3. It’s FS
f (−1)+f (−1+) 1+1
is periodic with period 4, so at x = 3 the FS converges to 2 = 2 = 1.)
The formulas (4.3) and (4.4) enable us to compute the Fourier
series coefficients a0 , an and bn . (We skip the details.) These
3
Fourier believed his series converged to the function in the early 1800’s but we now
know this is not always true.
4
Pronounced “Dear-ish-lay”.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-183-320.jpg)
![formulas give that the Fourier series of f (x) is
∞
4 nπ cos (nπ) nπx
f (x) ∼ + −4 sin( ).
2 n=1 n2 π 2 2
The Fourier series approximations to f (x) are
4 πx sin 1 π x
2 sin (π x)
S0 = 2, S1 = 2+ sin( ), S2 = 2+4 −2 , ...
π 2 π π
The graphs of each of these functions get closer and closer to
the graph of f (x) on the interval −2 < x < 2. For instance, the
graph of f (x) and of S8 are given below:
Notice that f (x) is only defined from −2 < x < 2 yet the Fourier
series is not only defined everywhere but is periodic with period
P = 2L = 4. Also, notice that S8 is not a bad approximation to
f (x).
This can also be done in SAGE . First, we define the function.
SAGE
sage: f = lambda x:x+2
sage: f = Piecewise([[(-2,2),f]])
This can be plotted using the command f.plot().show(). Next,
we compute the Fourier series coefficients:
SAGE
sage: f.fourier_series_cosine_coefficient(0,2) # a_0
4
sage: f.fourier_series_cosine_coefficient(1,2) # a_1
0
sage: f.fourier_series_cosine_coefficient(2,2) # a_2
0
sage: f.fourier_series_cosine_coefficient(3,) # a_3](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-184-320.jpg)
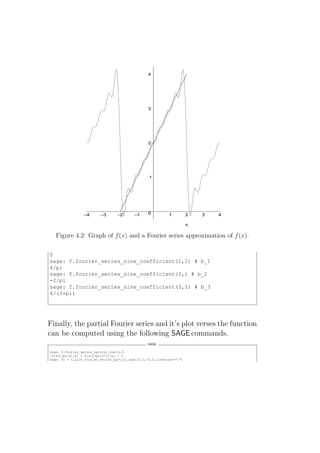
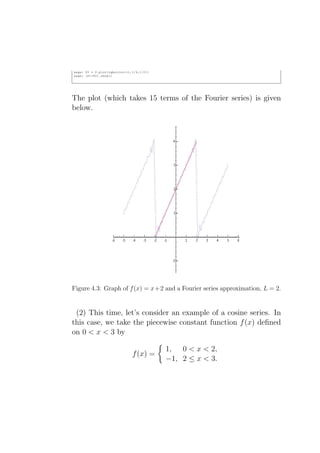



![Exercise: Let f (x) = x2 , −2 < x < 2 and L = 2. Use SAGE to
compute the first 10 terms of the Fourier series, and plot the
corresponding partial sum. Next plot the partial sum of the
first 50 terms and compare them.
Exercise: What mathematical results do the following SAGE commands
give you? In other words, if you can seen someone typing these
commands into a computer, explain what problem they were
trying to solve.
SAGE
sage: x = var("x")
sage: f0 = lambda x: 0*x
sage: f1 = lambda x: -xˆ0
sage: f2 = lambda x: xˆ0
sage: f = Piecewise([[(-2,0),f1],[(0,3/2),f0],[(3/2,2),f2]])
sage: P1 = f.plot()
sage: a10 = [f.fourier_series_cosine_coefficient(n,2) for n in range(10)]
sage: b10 = [f.fourier_series_sine_coefficient(n,2) for n in range(10)]
sage: fs10 = a10[0]/2 + sum([a10[i]*cos(i*pi*x/2) for i in
range(1,10)]) + sum([b10[i]*sin(i*pi*x/2) for i in range(10)])
sage: P2 = fs10.plot(-4,4,linestyle=":")
sage: (P1+P2).show()
sage:
sage: a50 = [f.fourier_series_cosine_coefficient(n,2) for n in range(50)]
sage: b50 = [f.fourier_series_sine_coefficient(n,2) for n in range(50)]
sage: fs50 = a50[0]/2 + sum([a50[i]*cos(i*pi*x/2) for i in
range(1,50)]) + sum([b50[i]*sin(i*pi*x/2) for i in range(50)])
sage: P3 = fs50.plot(-4,4,linestyle="--")
sage: (P1+P2+P3).show()
sage: a100 = [f.fourier_series_cosine_coefficient(n,2) for n in range(100)]
sage: b100 = [f.fourier_series_sine_coefficient(n,2) for n in range(100)]
sage: fs100 = a100[0]/2 + sum([a100[i]*cos(i*pi*x/2) for i in
range(1,100)]) + sum([b100[i]*sin(i*pi*x/2) for i in range(100)])
sage: P3 = fs100.plot(-4,4,linestyle="--")
sage: (P1+P2+P3).show()
sage:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-190-320.jpg)

![Example: Let
−1, 0 ≤ x ≤ π/2,
f (x) =
2, π/2 < x < π.
Then L = π and
π 1
2 2 cos(nπ) − 3 cos( 2 nπ) + 1
bn (f ) = f (x) sin(nx)dx = −2 .
π 0 nπ
Thus
2 6 2
f (x) ∼ b1 (f ) sin(x)+b2 (f ) sin(2x)+... = sin(x)− sin(2x)+ sin(3x)+....
π π 3π
This can also be done in SAGE :
SAGE
sage: f1 = lambda x: -1
sage: f2 = lambda x: 2
sage: f = Piecewise([[(0,pi/2),f1],[(pi/2,pi),f2]])
sage: P1 = f.plot()
sage: b10 = [f.sine_series_coefficient(n,pi) for n in range(1,10)]
sage: b10
[2/pi, -6/pi, 2/(3*pi), 0, 2/(5*pi), -2/pi, 2/(7*pi), 0, 2/(9*pi)]
sage: ss10 = sum([b10[n]*sin((n+1)*x) for n in range(len(b50))])
sage: ss10
2*sin(9*x)/(9*pi) + 2*sin(7*x)/(7*pi) - 2*sin(6*x)/pi
+ 2*sin(5*x)/(5*pi) + 2*sin(3*x)/(3*pi) - 6*sin(2*x)/pi + 2*sin(x)/pi
sage: b50 = [f.sine_series_coefficient(n,pi) for n in range(1,50)]
sage: ss50 = sum([b50[n]*sin((n+1)*x) for n in range(len(b))])
sage: P2 = ss10.plot(-5,5,linestyle="--")
sage: P3 = ss50.plot(-5,5,linestyle=":")
sage: (P1+P2+P3).show()
This illustrates how the series converges to the function. The
function f (x), and some of the partial sums of its sine series,
looks like Figure 4.6.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-192-320.jpg)
![Figure 4.6: f (x) and two sine series approximations.
As you can see, taking more and more terms gives functions
which better and better approximate f (x).
The solution to the heat equation, therefore, is
∞
nπx nπ
u(x, t) = bn (f ) sin( ) exp(−k( )2 t).
n=1
L L
Next, we see how SAGE can plot the solution to the heat equa-
tion (we use k = 1):
SAGE
sage: t = var("t")
sage: soln50 = sum([b[n]*sin((n+1)*x)*eˆ(-(n+1)ˆ2*t) for n in range(len(b50))])
sage: soln50a = sum([b[n]*sin((n+1)*x)*eˆ(-(n+1)ˆ2*(1/10)) for n in range(len(b50))])
sage: P4 = soln50a.plot(0,pi,linestyle=":")](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-193-320.jpg)
![sage: soln50b = sum([b[n]*sin((n+1)*x)*eˆ(-(n+1)ˆ2*(1/2)) for n in range(len(b50))])
sage: P5 = soln50b.plot(0,pi)
sage: soln50c = sum([b[n]*sin((n+1)*x)*eˆ(-(n+1)ˆ2*(1/1)) for n in range(len(b50))])
sage: P6 = soln50c.plot(0,pi,linestyle="--")
sage: (P1+P4+P5+P6).show()
Taking 50 terms of this series, the graph of the solution at
t = 0, t = 0.5, t = 1, looks approximately like Figure 4.7.
Figure 4.7: f (x), u(x, 0.1), u(x, 0.5), u(x, 1.0) using 60 terms of the sine
series.
The heat equation with insulated ends boundary conditions
models the temperature of an (insulated) wire of length L:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-194-320.jpg)

![a0
+ a1 (f ) cos(x) + a2 (f ) cos(2x) + ...
f (x) ∼
2
This can also be done in SAGE :
SAGE
sage: f1 = lambda x: -1
sage: f2 = lambda x: 2
sage: f = Piecewise([[(0,pi/2),f1],[(pi/2,pi),f2]])
sage: P1 = f.plot()
sage: a10 = [f.cosine_series_coefficient(n,pi) for n in range(10)]
sage: a10
[1, -6/pi, 0, 2/pi, 0, -6/(5*pi), 0, 6/(7*pi), 0, -2/(3*pi)]
sage: a50 = [f.cosine_series_coefficient(n,pi) for n in range(50)]
sage: cs10 = a10[0]/2 + sum([a10[n]*cos(n*x) for n in range(1,len(a10))])
sage: P2 = cs10.plot(-5,5,linestyle="--")
sage: cs50 = a50[0]/2 + sum([a50[n]*cos(n*x) for n in range(1,len(a50))])
sage: P3 = cs50.plot(-5,5,linestyle=":")
sage: (P1+P2+P3).show()
This illustrates how the series converges to the function. The
piecewise constant function f (x), and some of the partial sums
of its cosine series (one using 10 terms and one using 50 terms),
looks like Figure 4.8.
As you can see, taking more and more terms gives functions
which better and better approximate f (x).
The solution to the heat equation, therefore, is
∞
a0 nπx nπ
u(x, t) = + an (f ) cos( ) exp(−k( )2 t).
2 n=1
L L
Using SAGE , we can plot this function:
SAGE
sage: soln50a = a50[0]/2 + sum([a50[n]*cos(n*x)*eˆ(-(n+1)ˆ2*(1/100)) for n in range(1,len(a50))])
sage: soln50b = a50[0]/2 + sum([a50[n]*cos(n*x)*eˆ(-(n+1)ˆ2*(1/10)) for n in range(1,len(a50))])
sage: soln50c = a50[0]/2 + sum([a50[n]*cos(n*x)*eˆ(-(n+1)ˆ2*(1/2)) for n in range(1,len(a50))])
sage: P4 = soln50a.plot(0,pi)
sage: P5 = soln50b.plot(0,pi,linestyle=":")](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-196-320.jpg)
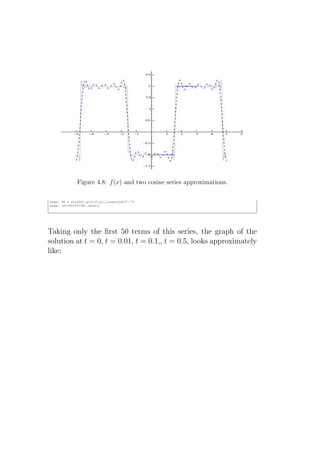
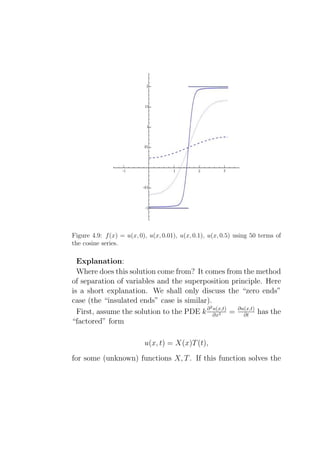







![sage: f = Piecewise([[(0,pi/2),f1],[(pi/2,pi),f2]])
sage: P1 = f.plot(rgbcolor=(1,0,0))
sage: b50 = [f.sine_series_coefficient(n,pi) for n in range(1,50)]
sage: ss50 = sum([b50[i-1]*sin(i*x) for i in range(1,50)])
sage: b50[0:5]
[2/pi, -6/pi, 2/(3*pi), 0, 2/(5*pi)]
sage: P2 = ss50.plot(-5,5,linestyle="--")
sage: (P1+P2).show()
As you can see, taking more and more terms gives functions
which better and better approximate f (x).
The solution to the wave equation, therefore, is
∞
nπt Lbn (g) nπt nπx
w(x, t) = (bn (f ) cos(c )+ sin(c )) sin( ).
n=1
L cnπ L L
Taking only the first 50 terms of this series, the graph of the
solution at t = 0, t = 0.1, t = 1/5, t = 1/4, looks approximately
like:
Figure 4.11: Wave equation with c = 3.
This was produced using the SAGE commands:](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-206-320.jpg)
![SAGE
sage: t = var("t")
sage: w50t1 = sum([b50[i-1]*sin(i*x)*cos(3*i*(1/10)) for i in range(1,50)])
sage: P3 = w50t1.plot(0,pi,linestyle=":")
sage: w50t2 = sum([b50[i-1]*sin(i*x)*cos(3*i*(1/5)) for i in range(1,50)])
sage: P4 = w50t2.plot(0,pi,linestyle=":",rgbcolor=(0,1,0))
sage: w50t3 = sum([b50[i-1]*sin(i*x)*cos(3*i*(1/4)) for i in range(1,50)])
sage: P5 = w50t3.plot(0,pi,linestyle=":",rgbcolor=(1/3,1/3,1/3))
sage: (P1+P2+P3+P4+P5).show()
Of course, taking terms would give a better approximation to
w(x, t). Taking the first 100 terms of this series (but with dif-
ferent times):
Figure 4.12: Wave equation with c = 3.](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-207-320.jpg)

![Bibliography
[A-pde] Wikipedia articles on the Transport equation:
http://en.wikipedia.org/wiki/Advection
http://en.wikipedia.org/wiki/Advection_equation
[A-uc] Wikipedia entry for the annihilator method: http://en.
wikipedia.org/wiki/Annihilator_method
[B-rref] Robert A. Beezer, A First Course in Linear Alge-
bra, released under the GNU Free Documentation License,
available at http://linear.ups.edu/
[B-ps] Wikipedia entry for the Bessel functions:
http://en.wikipedia.org/wiki/Bessel_function
[B-fs] Wikipedia entry for Daniel Bernoulli:
http://en.wikipedia.org/wiki/Daniel_Bernoulli
[BD-intro] W. Boyce and R. DiPrima, Elementary Differen-
tial Equations and Boundary Value Problems, 8th
edition, John Wiley and Sons, 2005.
[BS-intro] General wikipedia introduction to the Black-Scholes
model:
http://en.wikipedia.org/wiki/Black-Scholes
[C-ivp] General wikipedia introduction to the Catenary:
http://en.wikipedia.org/wiki/Catenary
201](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-209-320.jpg)
![[C-linear] General wikipedia introduction to RLC circuits:
http://en.wikipedia.org/wiki/RLC_circuit
[CS-rref] Wikipedia article on normal modes of coupled springs:
http://en.wikipedia.org/wiki/Normal_mode
[D-df] Wikipedia introduction to direction fields:
http://en.wikipedia.org/wiki/Slope_field
[DF-df] Direction Field Plotter of Prof Robert Israel:
http://www.math.ubc.ca/~israel/applet/dfplotter/
dfplotter.html
[D-spr] Wikipedia entry for damped motion: http://en.
wikipedia.org/wiki/Damping
[E-num] General wikipedia introduction to Euler’s method:
http://en.wikipedia.org/wiki/Euler_integration
[Eu1-num] Wikipedia entry for Euler: http://en.wikipedia.
org/wiki/Euler
[Eu2-num] MacTutor entry for Euler:
http://www-groups.dcs.st-and.ac.uk/~history/Biographies/Euler.html
[F-1st] General wikipedia introduction to First order linear
differential equations:
http://en.wikipedia.org/wiki/Linear_
differential_equation#First_order_equation
[F1-fs] Wikipedia Fourier series article
http://en.wikipedia.org/wiki/Fourier_series
[F2-fs] MacTutor Fourier biography:
http://www-groups.dcs.st-and.ac.uk/%7Ehistory/
Biographies/Fourier.html](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-210-320.jpg)
![[H-rref] Jim Hefferon, Linear Algebra, released under the
GNU Free Documentation License, available at http://
joshua.smcvt.edu/linearalgebra/
[H-ivp] General wikipedia introduction to the Hyperbolic trig
function
http://en.wikipedia.org/wiki/Hyperbolic_function
[H-intro] General wikipedia introduction to Hooke’s Law: http:
//en.wikipedia.org/wiki/Hookes_law
[H-fs] General wikipedia introduction to the heat equation:
http://en.wikipedia.org/wiki/Heat_equation
[H1-spr] Wikipedia entry for Robert Hooke: http://en.
wikipedia.org/wiki/Robert_Hooke
[H2-spr] MacTutor entry for Hooke:
http://www-groups.dcs.st-and.ac.uk/%7Ehistory/Biographies/Hooke.html
[KL-cir] Wikipedia entry for Kirchhoff’s laws: http://en.
wikipedia.org/wiki/Kirchhoffs_circuit_laws
[K-cir] Wikipedia entry for Kirchhoff: http://en.wikipedia.
org/wiki/Gustav_Kirchhoff
[L-var] Wikipedia article on Joseph Louis Lagrange:
http://en.wikipedia.org/wiki/Joseph_Louis_
Lagrange
[LE-sys] Everything2 entry for Lanchester’s equations:
http://www.everything2.com/index.pl?node=
Lanchester%20Systems%20and%20the%20Lanchester%
20Laws%20of%20Combat](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-211-320.jpg)
![[L-sys] Wikipedia entry for Lanchester: http://en.
wikipedia.org/wiki/Frederick_William_Lanchester
[LA-sys] Lanchester automobile information: http:
//www.amwmag.com/L/Lanchester_World/lanchester_
world.html
[L-intro] F. W. Lanchester, Mathematics in Warfare, in The
World of Mathematics, J. Newman ed., vol.4, 2138-
2157, Simon and Schuster (New York) 1956; now Dover
2000. (A four-volume collection of articles.)
http://en.wikipedia.org/wiki/Frederick_W.
_Lanchester
[La-sys] Frederick William Lanchester, Aviation in Warfare:
The Dawn of the Fourth Arm, Constable and Co., Lon-
don, 1916.
[L-lt] Wikipedia entry for Laplace: http://en.wikipedia.
org/wiki/Pierre-Simon_Laplace
[LT-lt] Wikipedia entry for Laplace transform: http://en.
wikipedia.org/wiki/Laplace_transform
[L-linear] General wikipedia introduction to Linear Indepen-
dence:
http://en.wikipedia.org/wiki/Linearly_
independent
[Lo-intro] General wikipedia introduction to the logistic func-
tion model of population growth:
http://en.wikipedia.org/wiki/Logistic_function
[M-intro] Niall J. MacKay, Lanchester combat models, May
2005. http://arxiv.org/abs/math.HO/0606300](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-212-320.jpg)
![[M-ps] Sean Mauch, Introduction to methods of Applied Mathe-
matics,
http://www.its.caltech.edu/~sean/book/
unabridged.html
[M] Maxima, a general purpose Computer Algebra system.
http://maxima.sourceforge.net/
[M-mech] General wikipedia introduction to Newtonian me-
chanics
http://en.wikipedia.org/wiki/Classical_mechanics
[M-fs] Wikipedia entry for the physics of music:
http://en.wikipedia.org/wiki/Physics_of_music
[N-mech] General wikipedia introduction to Newton’s three
laws of motion:
http://en.wikipedia.org/wiki/Newtons_Laws_of_
Motion
[N-intro] David H. Nash, Differential equations and the Battle of
Trafalgar, The College Mathematics Journal, Vol. 16, No.
2 (Mar., 1985), pp. 98-102.
[N-cir] Wikipedia entry for Electrical Networks: http://en.
wikipedia.org/wiki/Electrical_network
[NS-intro] General wikipedia introduction to Navier-Stokes
equations:
http://en.wikipedia.org/wiki/Navier-Stokes_
equations
Clay Math Institute prize page:
http://www.claymath.org/millennium/
Navier-Stokes_Equations/](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-213-320.jpg)
![[O-ivp] General wikipedia introduction to the Harmonic oscilla-
tor
http://en.wikipedia.org/wiki/Harmonic_oscillator
[P-fs] Howard L. Penn, “Computer Graphics for the Vibrating
String,” The College Mathematics Journal, Vol. 17, No. 1
(Jan., 1986), pp. 79-89
[P1-ps] Wikipedia entry for Power series: http://en.
wikipedia.org/wiki/Power_series
[P2-ps] Wikipedia entry for the power series method: http:
//en.wikipedia.org/wiki/Power_series_method
[R-ps] Wikipedia entry for the recurrence relations:
http://en.wikipedia.org/wiki/Recurrence_
relations
[R-cir] General wikipedia introduction to LRC circuits: http:
//en.wikipedia.org/wiki/RLC_circuit
[S-intro] The SAGE Group, SAGE : Mathematical software, ver-
sion 2.8.
http://www.sagemath.org/
http://sage.scipy.org/
[SH-spr] Wikipedia entry for Simple harmonic motion: http:
//en.wikipedia.org/wiki/Simple_harmonic_motion
[S-pde] W. Strauss, Partial differential equations, an introduc-
tion, John Wiley, 1992.
[U-uc] General wikipedia introduction to undetermined co-
efficients: http://en.wikipedia.org/wiki/Method_of_
undetermined_coefficients](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-214-320.jpg)
![[V-var] Wikipedia introduction to variation of parameters:
http://en.wikipedia.org/wiki/Method_of_
variation_of_parameters
[W-intro] General wikipedia introduction to the Wave equation:
http://en.wikipedia.org/wiki/Wave_equation
[W-mech] General wikipedia introduction to Wile E. Coyote
and the RoadRunner:
http://en.wikipedia.org/wiki/Wile_E._Coyote_and_
Road_Runner
[W-linear] General wikipedia introduction to the Wronskian
http://en.wikipedia.org/wiki/Wronskian
[Wr-linear] St. Andrews MacTutor entry for Wronski
http://www-groups.dcs.st-and.ac.uk/%7Ehistory/Biographies/Wronski.
html](https://image.slidesharecdn.com/des-book-120430192234-phpapp02/85/Calculus-Research-Lab-3-Differential-Equations-215-320.jpg)


This document provides an introduction to differential equations. It defines key concepts such as dependent and independent variables, ordinary and partial differential equations, order of a differential equation, and linearity. Examples of first order differential equations are given, including one modeling the motion of a falling body subject to gravity and air resistance. Differential equations arise in many areas of physics and applied mathematics, such as modeling the weather, electrical circuits, cooling objects, and population growth. The document outlines some basic types of differential equations that will be covered in subsequent chapters.














![[Steven h. weintraub]_jordan_canonical_form_appli(book_fi.org)](https://cdn.slidesharecdn.com/ss_thumbnails/stevenh-150418132059-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)




































































