Downloaded 39 times








![There are many generalizations of eigen-problems
to tensors. Their properties are very different.
All eigenvectors have unit 2-norm. ||x||2 = 1.
Z-eigenvectors are not scale invariant. H-eigenvectors are.
SIAM ALA'18Benson & Gleich 9
There are even more types of eigen-probs!
• D-eigenvalues
• E-eigenvalues (complex Z-eigenvalues)
• Generalized versions too…
• Other normalizations! [Lim 05]
For more information about these tensor
eigenvectors and some of their fundamental
properties, we recommend the following resources
• Tensor Analysis: Spectral Theory and Special
Tensors. Qi & Luo, 2017.
• A survey on the spectral theory of nonnegative
tensors. Chang, Qi, & Zhang, 2013.](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-9-320.jpg)

![The best rank-1 approximation to a symmetric
tensor is given by the principal eigenvector.
[De Lathauwer 97; De Lathauwer-De Moor-Vandewalle 00; Kofidis-Regalia 01, 02]
A is a symmetric if the entries are the same under any
permutation of the indices.
In data mining and signal processing applications, we
are often interested in the “best” rank-1 approximation.
Notes. The first k tensor eigenvectors do not necessarily give the best rank-
k approximation. In general, this problem is not even well-posed [de Silva-
Lim 08].
Furthermore, the first eigenvector is not necessarily in the best rank-k
“orthogonal approximation” from orthogonal vectors [Kolda 01, 03].
3
2
1
SIAM ALA'18Benson & Gleich 12](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-12-320.jpg)
![Quantum
entanglement
A(i,j,k,…,l) are the normalized
amplitudes of an m-partite pure
state |ψ>
A is a nonneg sym tensor
Diffusion imaging
W is a symmetric, fourth-order kurtosis
diffusion tensor
D is a symmetric, 3 x 3 matrix
⟶ both are measured from MRI data.
Michael S. Helfenbein
Yale University
https://www.eurekalert.org/pub_r
eleases/2016-05/yu-
ddo052616.php
[Wei-Goldbart 03; Hu-Qi-Zhang
16]
is the geometric
measure of
entanglement
Paydar et al., Am. J. of
Neuroradiology, 2014
[Qi-Wang-Wu 08]
SIAM ALA'18Benson & Gleich 13](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-13-320.jpg)
![Markovian binary
trees.
Entry-wise minimal solutions
to x = Bx2 + a are extinction
Distribution of alleles (forms of a gene)
in a population at time t is x.
Start with an infinite population.
1. Every individual gets a random
mate.
2. Mates of type j and k produce
offspring of type i with probability
P(i, j, k) and then die.
Hardy-Weinberg equilibria of random mating
models are tensor eigenvectors.
Under Hardy-
Weinberg
equilibria
(steady-state), x
satisfies x = Px2.
[Bean-Kontoleon-Taylor 08;
Bini-Meini-Poloni 11; Meini-Poloni 11, 17]
SIAM ALA'18Benson & Gleich 14](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-14-320.jpg)

![Markov chains, matrices, and eigenvectors have a
long-standing relationship.
[Kemeny-Snell 76] “In the land of Oz they never have two nice
days in a row. If they have a nice day, they are just as likely to
have snow as rain the next day. If they have snow or rain, they
have an even chance of having the same the next day. If there
is a change from snow or rain, only half of the time is this
change to a nice day.”
Column-stochastic in this tutorial
(since we are linear algebra people).
Equations for stationary distribution x.
The vector x is an
eigenvector of P.
Px = x.
SIAM ALA'18Benson & Gleich 16](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-16-320.jpg)

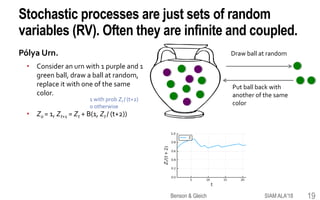


![Higher-order Markov chains & random walks are
useful models for many data problems.
Higher order Markov chains & random walks
A second order chain uses the last two states
Z-1 = “state”, Z0 = “another state”
Pr(Zt+1 = i | Zt = j, Zt-1 = k) = Pi,j,k
Simple to understand and turn out to be better models
than standard (first-order) chains in several application
domains [Ching-Ng-Fung 08]
• Traffic flow in airport networks [Rosvall+ 14]
• Web browsing behavior [Pirolli-Pitkow 99; Chierichetti+ 12]
• DNA sequences [Borodovsky-McIninch 93; Ching-Fung-Ng
04]
• Non backtracking walks in networks
[Krzakala+ 13; Arrigo-Gringod-Higham-Noferini 18]
Rosvall et al., Nature Comm., 2014.
A tensor!
SIAM ALA'18Benson & Gleich 22](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-22-320.jpg)

![Tensors are a natural representation of transition
probabilities of higher-order Markov chains.
1
3
2
P
Often called transition probability tensors.
[Li-Ng-Ye 11, Li-Ng 14, Chu-Wu 14, Culp-Pearson-
Zhang 17]
SIAM ALA'18Benson & Gleich 24](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-24-320.jpg)



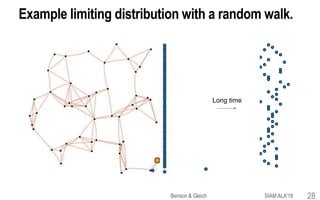
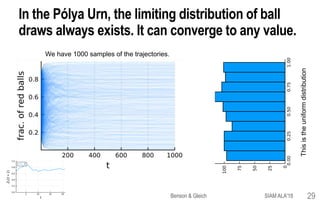

![Limiting distributions and stationary distributions
for Markov chains have different properties.
This point is often mis-understood.We want to make sure you get it right!
Limiting distribution
A stationary distribution Pk estart converges to p*
Theorem. A finite Markov chain always has a limiting distribution.
Theorem. The limiting distribution is unique if and only if the chain has only a
single recurrent class.
Theorem.A stationary distribution is limt ⟶ ∞ Prob[Zt = i].This is unique if and
only if a Markov chain has a single aperiodic, recurrent class.
SIAM ALA'18Benson & Gleich 31](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-31-320.jpg)
![States in a finite Markov chain are either recurrent
or transient.
Proof by picture.
Recurrent:
Prob[another visit] = 1
Transient:
Prob[another visit] < 1.
Markov chains ⟺ Dir. graphs
Directed graphs +Tarjan’s
algorithm give the flow among
strongly connected
components. (Block triangular
form.)
Block triangular form
fromTarjan’s algorithm
Strongly connected components
Recurrent states
SIAM ALA'18Benson & Gleich 32](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-32-320.jpg)
![The fundamental theorem of Markov chains is that
any stochastic matrix is Cesàro summable.
Limiting distribution given start node is P*[:, start] because
Pk gives the k-state transition probability.
Result. Only one recurrent class iff P* is rank 1.
Proof sketch. A recurrent class is a fully-stochastic sub-
matrix. If there are >1 recurrent classes, then P* would be
rank >1 because we could look at the sub-chain on each
recurrent class; if P* is rank 1, then the distribution is the
same regardless of where you start and so “no choice” .
Cesàro summable This always exists!
SIAM ALA'18Benson & Gleich 33](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-33-320.jpg)


![Remember! Tensors are a natural representation
of transition probabilities of higher-order Markov
chains.
1
3
2
P
But the stationary distribution on pairs of states is
still a matrix eigenvector...
[Li-Ng 14] Making the “rank-1 approximation” Xj,k = xjxk gives a
formulation for tensor eigenvectors.
SIAM ALA'18Benson & Gleich 36](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-36-320.jpg)


![Spacey random walks are stochastic processes
whose limiting distributions are such tensor
eigenvectors.
10
12
4
9
7
11
4
Zt-1
Zt
Yt
Key insight [Benson-Gleich-Lim 17]
Limiting distributions of this process are tensor eigenvectors of P.
1
3
2
P
Prob(Zt+1 = i | Zt = j, Yt = r) = P(i, j, r).
SIAM ALA'18Benson & Gleich 39](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-39-320.jpg)

![We have to be careful with undefined transitions,
which correspond to zero columns in the tensor.
10
12
4
9
7
11
4
Zt-1
Zt
Yt
1
3
2
P
Prob(Zt+1 = i | Zt = j, Yt = r) = ? P(:, j, r) = 0.
A couple options.
1. Pre-specify a distribution for when P(:, j, r) = 0.
2. Choose a random state from history ⟶ super SRW [Wu-Benson-Gleich 16]
SIAM ALA'18Benson & Gleich 41](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-41-320.jpg)
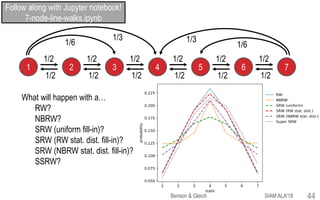
![1
2 3
1/2
1/2
1/2
1/2
1/2
1/2
Limiting distribution of
RW is [1/3, 1/3, 1/3].
What about non-backtracking RW?
NBRW disallows going back to where you came from
and re-normalizes the probabilities.
Lim. dist. is still [1/3, 1/3, 1/3], but for far different
reasons.
NBRW is a second-order Markov chain!
What happens with the spacey random walk using the NBRW transition probabilities?
Zero-column fill-in
affects the limiting
distribution and tensor
evec.
Follow along with Jupyter notebook!
3-node-cycle-walks.ipynb
SIAM ALA'18Benson & Gleich 42](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-42-320.jpg)





![An informal and intuitive proof that
spacey random walks converge to tensor
eigenvectors
Idea. Let wT be the fraction of time
spent in each state after T ≫ 1 steps.
Consider an additional L steps, T ≫ L ≫
1.Then wT ≈ wT+L if we converge.
SIAM ALA'18Benson & Gleich 50
1
3
2
P
Long time
wT wT+L
Suppose M(x) = P[wT]m-2 has a unique
stationary distribution, xT.
If the SRW converges, then xT = wT+L,
otherwise wT+L would be different.
Thus, xT = P[wT]m-1 xT ≈ P[wT+L]m-1 xT =
P[xT]m-1 xT = PxT
m-1.
Long time
wT wT+L](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-50-320.jpg)
![To formalize convergence, we need the theory of
generalized vertex reinforced random walks
(GVRRW).
A stochastic process X1, …, Xt, … is a GVRRW if
wT is the fraction of time in each state
FT is the sigma algebra generated by X1, …, XT.
M(wT) is a column stochastic matrix that depends on wT .
[Diaconis 88; Pemantle 92, 07; Benaïm 97]
SIAM ALA'18Benson & Gleich 51
The classicVRRW is the following
• Given a graph, randomly move to a
neighbor with probability propotional to
how often we’ve visited the neighbor!](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-51-320.jpg)
![To formalize convergence, we need the theory of
generalized vertex reinforced random walks
(GVRRW).
A stochastic process X1, …, Xt, … is a GVRRW if
wT is the fraction of time in each state
FT is the sigma algebra generated by X1, …, XT.
M(wT) is a column stochastic matrix that depends on wT .
Spacey random walks are GVRRWs with the map M: M(wT) = P[wT]m-2.
[Diaconis 88; Pemantle 92, 07; Benaïm 97]
SIAM ALA'18Benson & Gleich 52](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-52-320.jpg)
![To formalize convergence, we need the theory of
generalized vertex reinforced random walks
(GVRRW).
Theorem [Benaïm97] heavily paraphrased
In a discrete GVRRW, the long-term behavior of the occupancy distribution wT
follows the long-term behavior of the dynamical system
To study convergence properties of the SRW, we just need to study the
dynamical system for our map M: M(wT) = P[wT]m-2:
where maps a column stochastic matrix to its Perron vector.
SIAM ALA'18Benson & Gleich 53](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-53-320.jpg)
![More on how stationary distributions of GVRRWs
correspond to ODEs
SIAM ALA'18Benson & Gleich 54
THEOREM [Benaïm, 1997] Less Paraphrased
The sequence of empirical observation probabilities ct
is an asymptotic pseudo-trajectory for the dynamical
system
Thus, convergence of the ODE to a fixed point is
equivalent to stationary distributions of the VRRW.
• M must always have a unique stationary distribution!
• The map to M must be very continuous
• Asymptotic pseudo-trajectories satisfy](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-54-320.jpg)


![Relationship between spacey random walk
convergence and existence of tensor
eigenvectors.
SRW converges ⇒ existence of tensor e-vec of P with e-val 1.
SRW converges ⇍ existence of tensor e-vec of P with e-val 1.
Apply map f(x) = Pxm-1 satisfies conditions of Brouwer’s fixed point
theorem, so there always exists an x such that Pxm-1 = x.
Furthermore, 𝜆 = 1 is the largest eigenvalue. [Li-Ng 14]
There exists a P for which the SRW does not converge [Peterson 18]
SIAM ALA'18Benson & Gleich 57](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-57-320.jpg)

![Almost every 2-state spacey random walk
converges.
[Benson-Gleich-Lim 17]
Special case of 2 x 2 x 2 system...
SIAM ALA'18Benson & Gleich 59](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-59-320.jpg)
![Almost every 2-state spacey random walk
converges.
Theorem [Benson-Gleich-Lim 17]
The dynamics of almost every
2 x 2 x … x 2 spacey random
walk (of any order) converges
to a stable equilibrium point.
stable
stable
unstable
Things to note…
1. Multiple stable points in above example; SRW could converge to any.
2. Randomness of SRW is “baked in” to initial condition of system.
SIAM ALA'18Benson & Gleich 60](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-60-320.jpg)
![A sufficiently regularized spacey random walk
converges.
Consider a modified “spacey random surfer” model. At each step,
1. with probability α, follow SRW model P.
2. with probability 1 - α, teleport to a random node.
Equivalent to a SRW on S = αP + (1 – α)J, where J is normalized ones tensor.
Theorem.
If α < 1 / (m – 1),
1. the SRW on S converges [Benson-Gleich-Lim 17]
2. there is a unique tensor x e-vec satisfying Sxm-1 = x [Gleich-Lim-Yu 15]
[Gleich-Lim-Yu 15; Benson-Gleich-Lim 17]
SIAM ALA'18Benson & Gleich 61](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-61-320.jpg)
![A sufficiently regularized spacey random walk
converges.
The higher-order power method is an algorithm to compute the
dominant tensor eigenvector.
yk+1 = Txk
m-1
xk+1 = yk+1 / || yk+1 ||
Theorem [Gleich-Lim-Yu 15]
If α < 1 / (m – 1), the power method on S = αP + (1 – α)J converges to
the unique vector satisfying Sxm-1 = x.
Conjecture.
If the higher-order power method on P always converges, then
the spacey random walk on P always converges.
SIAM ALA'18Benson & Gleich 62](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-62-320.jpg)
![Conjecture.
Determining if a SRW converges is PPAD-complete.
Computing a limiting distribution of SRW is PPAD-complete.
Why?
In general, NP-hard to determine if tensor evec for eval 𝜆 [Hillar-Lim 13].
Know evec exists for transition probability tensor P, eval 𝜆 = 1 [Li-Ng 14].
However, no obvious way to compute it.
Similar to other PPAD-complete problems (e.g., Nash equilibria).
SIAM ALA'18Benson & Gleich 63](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-63-320.jpg)
![General Open Question.
What is the best way to compute tensor eigenvectors?
• Higher-order power method
[Kofidis-Regalia 00, 01; De Lathauwer-De Moor-Vandewalle 00]
• Shifted higher-order power method [Kolda-Mayo 11]
• SDP hierarchies [Cui-Dai-Nie 14; Nie-Wang 14; Nie-Zhang 18]
• Perron iteration [Meini-Poloni 11, 17]
For SRWs, the dynamical system offers another way.
Numerically integrate the dynamical system!
[Benson-Gleich-Lim 17; Benson-Gleich 18]
SIAM ALA'18Benson & Gleich 64
Equivalent to Perron iteration with Forward Euler & unit time-step.](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-64-320.jpg)

![Spacey random walks model sequence data.
Maximum likelihood estimation problem
(most likely P for the SRW model and the observed data).
convex
objective
linear constraints
nyc.gov
[Benson-Gleich-Lim 17]
70SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-70-320.jpg)

![• One year of 1000 taxi trajectories in NYC.
• States are neighborhoods in Manhattan.
• Compute MLE P for SRW model with 800 taxis.
• Evaluate RMSE on test data of 200 taxis.
RMSE = 1 – Prob[sequence generated by process]
Spacey random walks model sequence data.
72SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-72-320.jpg)
![Spacey random walks are identifiable via this
procedure.
73
Two difficult test tensors from [Gleich-Lim-Yu 15]
1. Generate 80 sequences with 200 transitions each from SRW model
Learn P for 2nd-order SRW, R for 2nd-order MC, P for 1st-order MC
2. Generate 20 sequences with 200 transitions each and evaluate RMSE.
Evaluate RMSE = 1 – Prob[sequence generated by process]
SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-73-320.jpg)
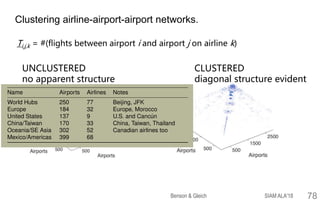
![Co-clustering nonnegative tensor data.
Joint work with
Tao Wu, Purdue
Spacey random walks that converge are
asymptotically Markov chains.
• occupancy vector wT converges to w
⟶ dynamics converge to P[w]m-2.
1
3
2
P
2
1 M(wt )
This connects to spectral clustering on graphs.
• Eigenvectors of the normalized Laplacian of a graph are
eigenvectors of the random walk matrix.
• Instead, we compute a stationary distribution w and use
eigenvectors of P = P[w]m-2.
[Wu-Benson-Gleich 16]
75SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-75-320.jpg)
![We possibly symmetrize and normalize
nonnegative data to get a transition probability
tensor.
[1, 2, …, n] x
[1, 2, …, n] x
[1, 2, …, n]
[i1, i2, …, in1
]x
[j1, j2, …, jn2
]x
[k1, k2, …, kn3
]
If the data is a brick, we symmetrize before
normalization [Ragnarsson-Van Loan 13]
Generalization of
If the data is a symmetric cube,
we can normalize it to get a
transition tensor P.
76SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-76-320.jpg)


![New framework for computing tensor evecs.
[Benson-Gleich 18]
Our stochastic viewpoint gives a new approach.
We numerically integrate the dynamical system.
Many tensor eigenvector computation algorithms are
algebraic, look like generalizations of matrix power
method, shifted iteration, Newton iteration.
[Lathauwer-Moore-Vandewalle 00, Regalia-Kofidis 00, Li-Ng
14; Chu-Wu 14; Kolda-Mayo 11, 14]
Higher-order power method
Dynamical system
Many known convergence issues!
1. The dynamical system is empirically more robust for
principal evec of transition probability tensors.
2. Can generalize for symmetric tensors & any evec.
81SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-81-320.jpg)
![New framework for computing tensor evecs.
[Benson-Gleich 18]
Let Λ be a prescribed map from a matrix to one of its eigenvectors, e.g.,
Λ(M) = eigenvector of M for kth smallest algebraic eigenvalue,
Λ(M) = eigenvector of M for largest magnitude eigenvalue
Suppose the dynamical system converges.Then
New computational framework.
1. Choose a mapΛ
2. Numerically integrate the dynamical system
82SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-82-320.jpg)
![The algorithm is evolving this system!
The algorithm has a simple Julia code
function mult3(A, x)
dims = size(A)
M = zeros(dims[1],dims[2])
for i=1:dims[3]
M += A[:,:,i]*x[i]
end
return M
end
function dynsys_tensor_eigenvector(A;
maxit=100, k=1, h=0.5)
x = randn(size(A,1)); normalize!(x)
# This is the ODE function
F = function(x)
M = mult3(A, x)
d,V = eig(M) # we use Julia's ordering (*)
v = V[:,k] # pick out the kth eigenvector
if real(v[1]) >= 0; v *= -1.0; end # canonicalize
return real(v) – x
end
# evolve the ODE via Forward Euler
for iter=1:maxit; x = x + h*F(x); end
return x, x'*mult3(A,x)*x
end
Benson & Gleich SIAM ALA'18 83](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-83-320.jpg)
![New framework for computing tensor evecs.
Empirically, we can compute all the tensor eigenpairs with this approach (including
unstable ones that higher-order power method cannot compute).
tensor is Example 3.6 from [Kolda-Mayo 11]
84SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-84-320.jpg)
![Why does this work? (Hand-wavy version)
Trajectory of dynamical system for Example 3.6
from Kolda and Mayo [2011]. Color is projection
onto first eigenvector of Jacobian which is +1 at
stationary points. Numerical integration with
forward Euler.
Why does this work?
The eigenvector map shifts
the spectrum around
unstable eigenvectors.
Benson & Gleich SIAM ALA'18 85](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-85-320.jpg)
![There are tons of open questions with this
approach that we could use help with!
Can the dynamical system cycle?
Yes, but what problems produce this behavior?
Which eigenvector (k) to use?
It really matters
How to numerically integrate?
Seems like ODE45 does the trick!
SSHOPM -> Dyn Sys?
If SSHOPM converges, can you show the dyn.
sys will converge for some k?
Can you show there are inaccessible vecs?
No clue right now!
Benson & Gleich SIAM ALA'18 86
Trajectory of dynamical system for Example 3.6
from Kolda and Mayo [2011]. Color is projection
onto first eigenvector of Jacobian which is +1 at
stationary points. Numerical integration with
forward Euler.](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-86-320.jpg)
![New framework for computing tensor evecs.
• SDP methods can compute all eigenpairs but have
scalability issues [Cui-Dai-Nie 14, Nie-Wang 14, Nie-Zhang
17]
• Empirically, we can compute the same eigenvectors
while maintaining scalability.
tensor is Example 4.11 from [Cui-Dai-Nie 14]
87SIAM ALA'18Benson & Gleich](https://image.slidesharecdn.com/tesp-siam-ala-2018-public-180506020317/85/Tensor-Eigenvectors-and-Stochastic-Processes-87-320.jpg)




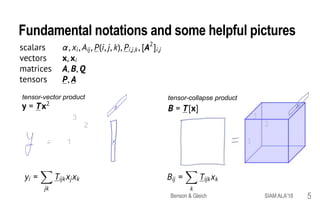
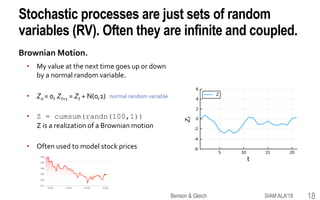
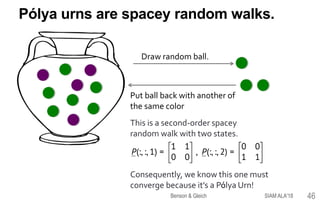
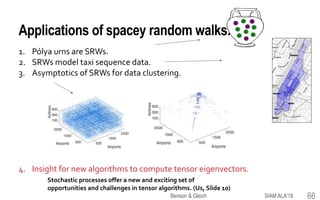
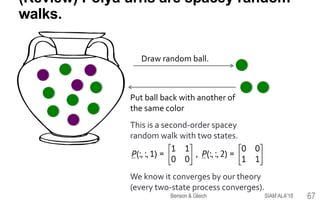
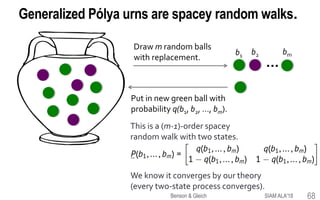
This document provides an overview of a tutorial on tensor eigenvectors and stochastic processes. The tutorial consists of 6 acts that cover basic tensor notation and operations, motivating applications involving tensors, a review of stochastic processes and Markov chains, introducing spacey random walks as stochastic processes, the theory of spacey random walks, and applications of spacey random walks. The goal is to interpret tensor objects from a stochastic perspective using concepts like random walks on graphs and higher-order Markov chains.