Download as PDF, PPTX









![bought to you by
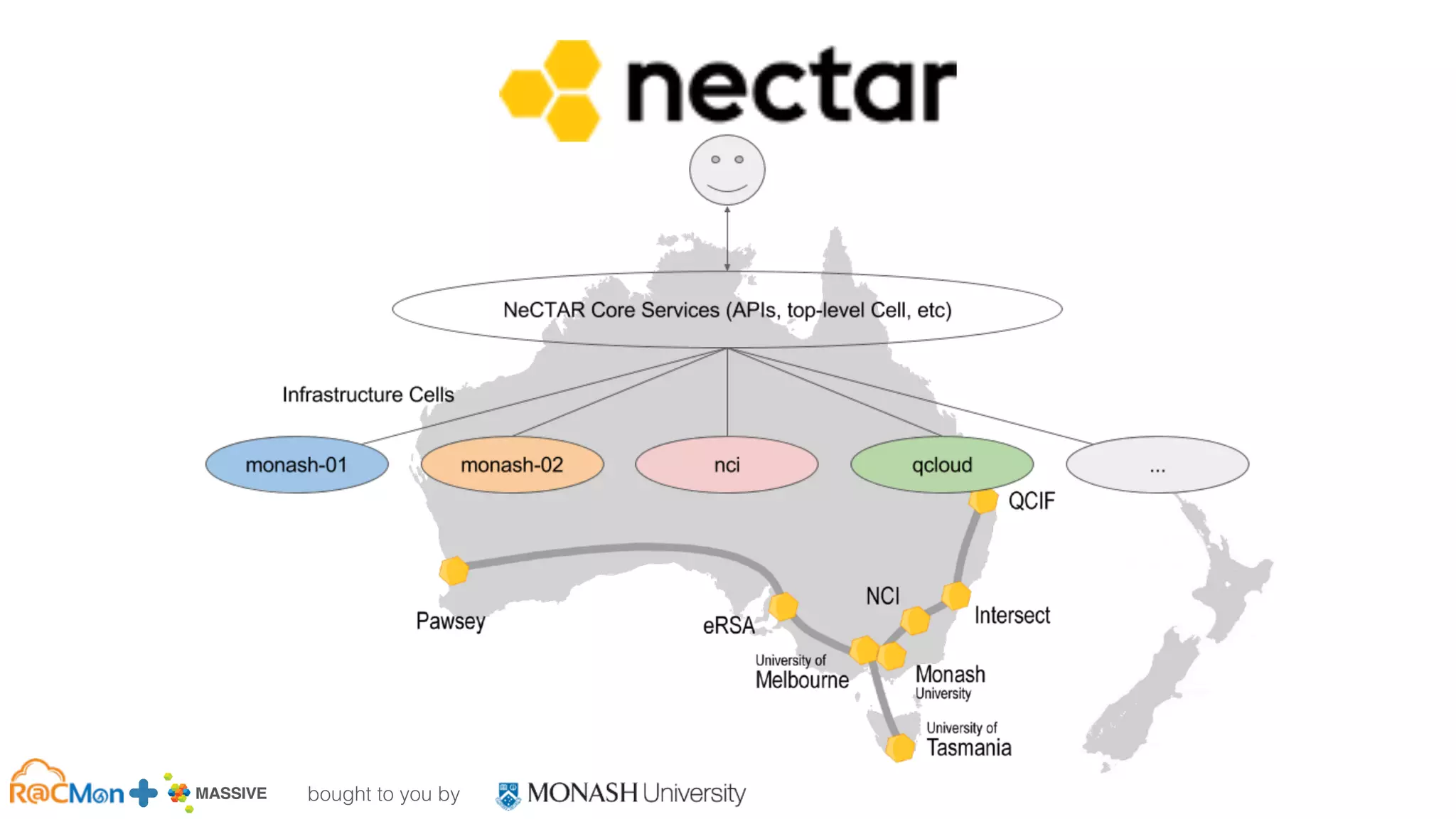
MASSIVE Business Plan 2013 / 2014 DRAFT
GPU-accelerated OpenStack Instances
1. Confirm hardware capability
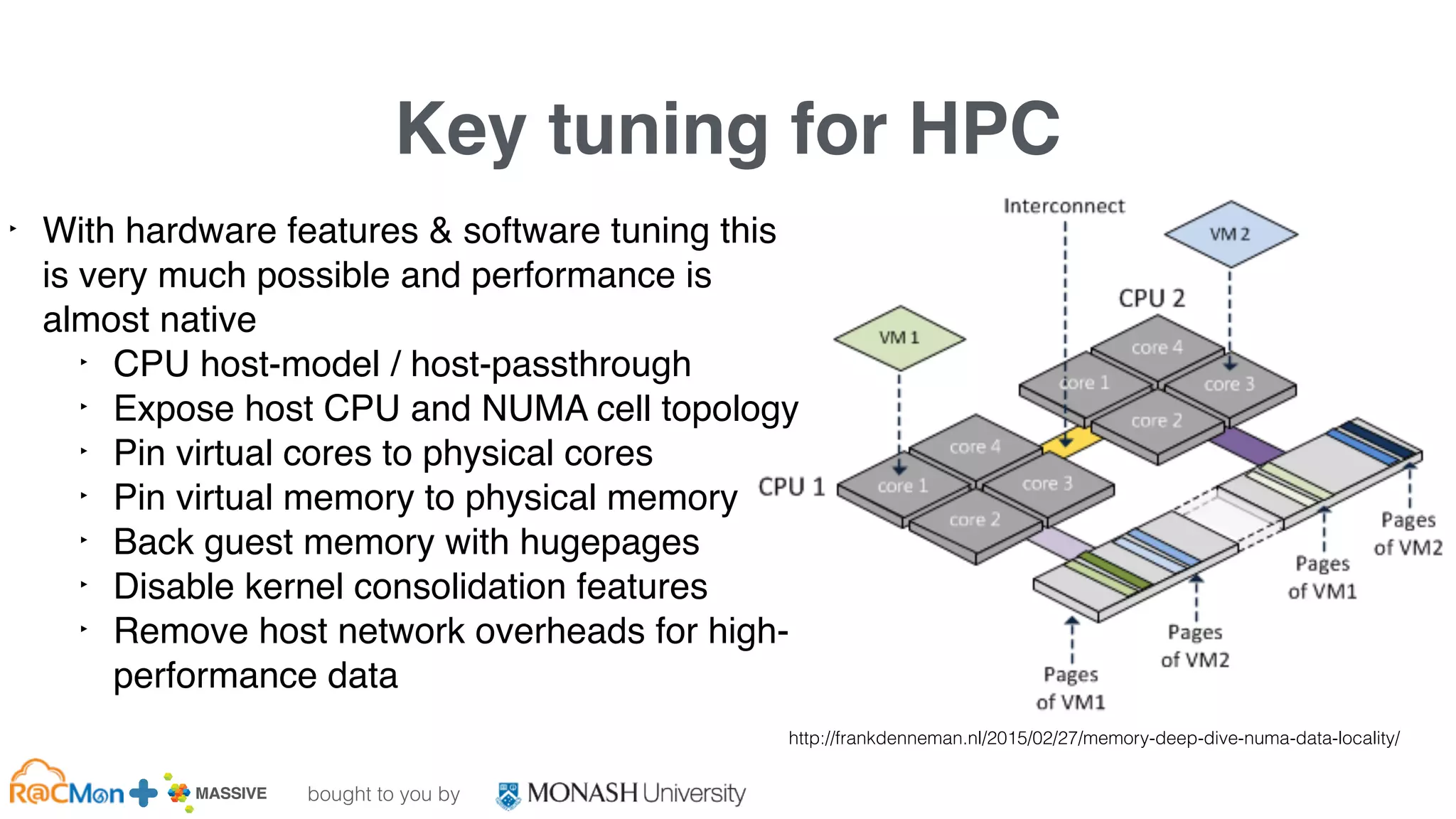
2. Prep compute hosts/hypervisors
1. ensure IOMMU is enabled in BIOS
2. enable IOMMU in Linux, e.g., for Intel:
3. ensure no other drivers/modules claim GPUs, e.g., blacklist
nouveau
4. Configure nova-compute.conf pci_passthrough_whitelist:
# in /etc/default/grub:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash intel_iommu=on iommu=pt rd.modules-
load=vfio-pci”
~$ update-grub
~$ lspci -nn | grep NVIDIA
03:00.0 3D controller [0302]: NVIDIA Corporation Device [10de:15f8] (rev a1)
82:00.0 3D controller [0302]: NVIDIA Corporation Device [10de:15f8] (rev a1)
# in /etc/nova/nova.conf:
pci_passthrough_whitelist=[{"vendor_id":"10de", "product_id":"15f8"}]](https://image.slidesharecdn.com/openstack-gpu-hpc-openstackdaymelbourneblairmonash-190624050233/75/Building-a-GPU-enabled-OpenStack-Cloud-for-HPC-Blair-Bethwaite-Monash-University-20-2048.jpg)







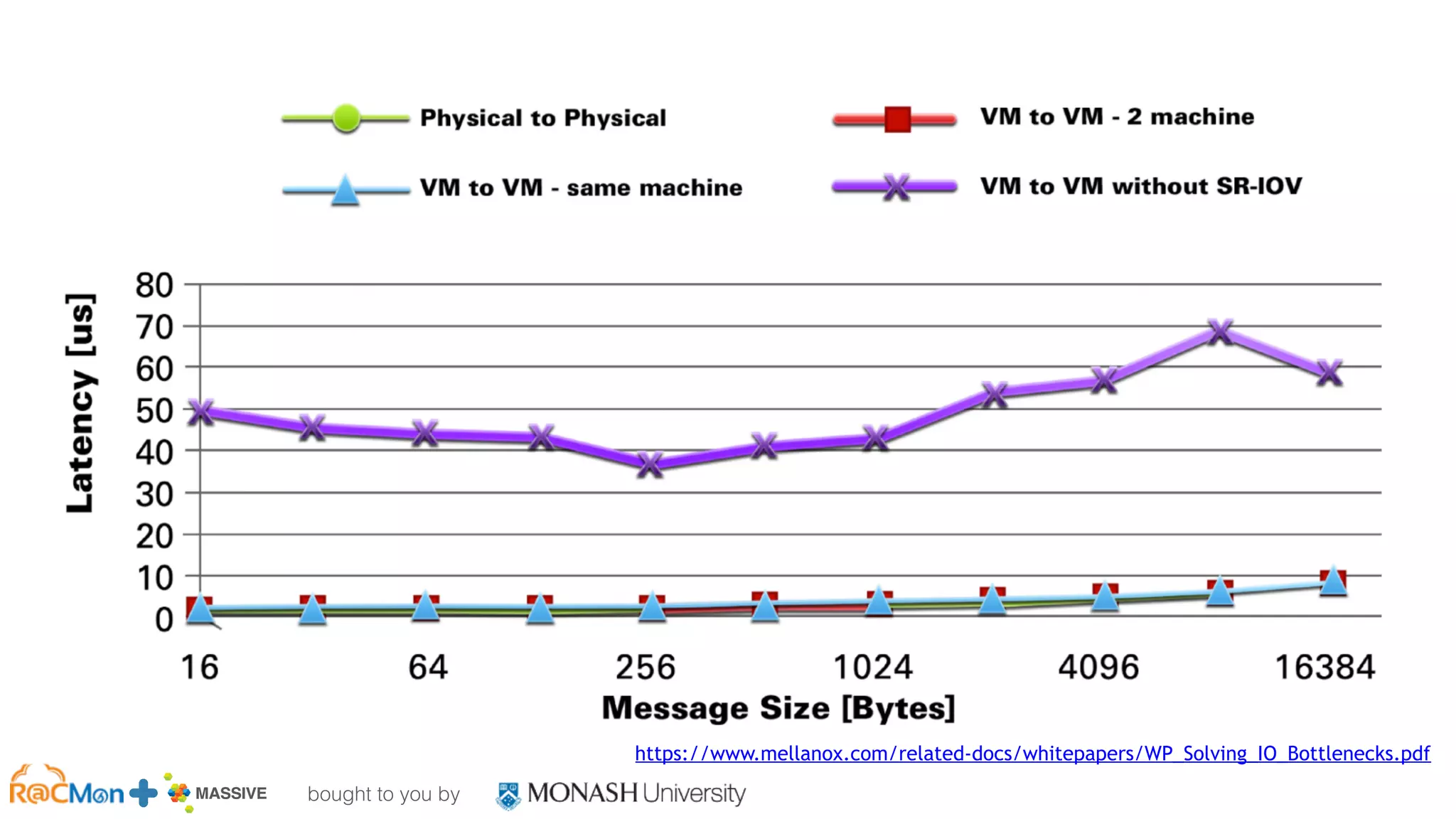
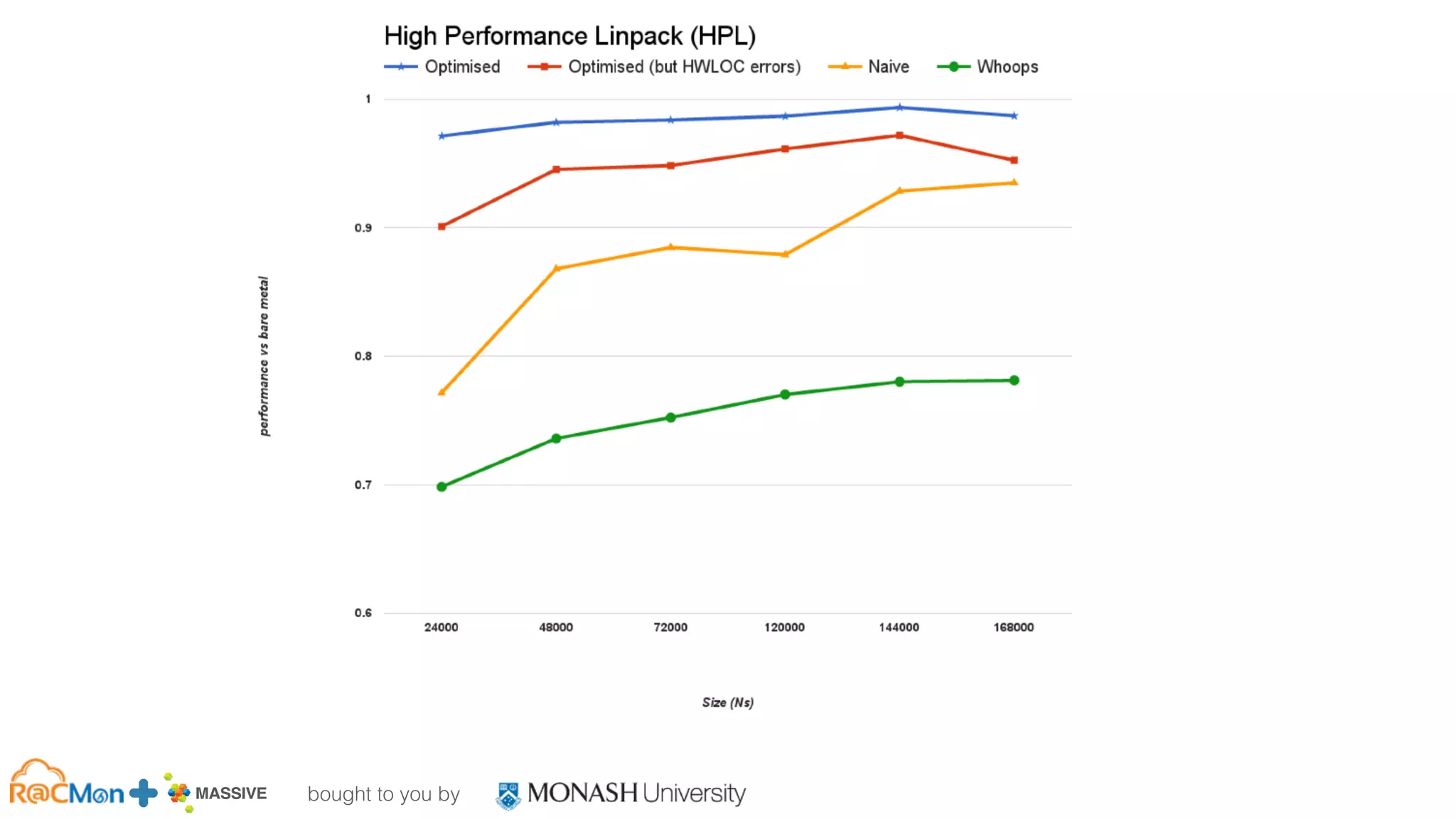
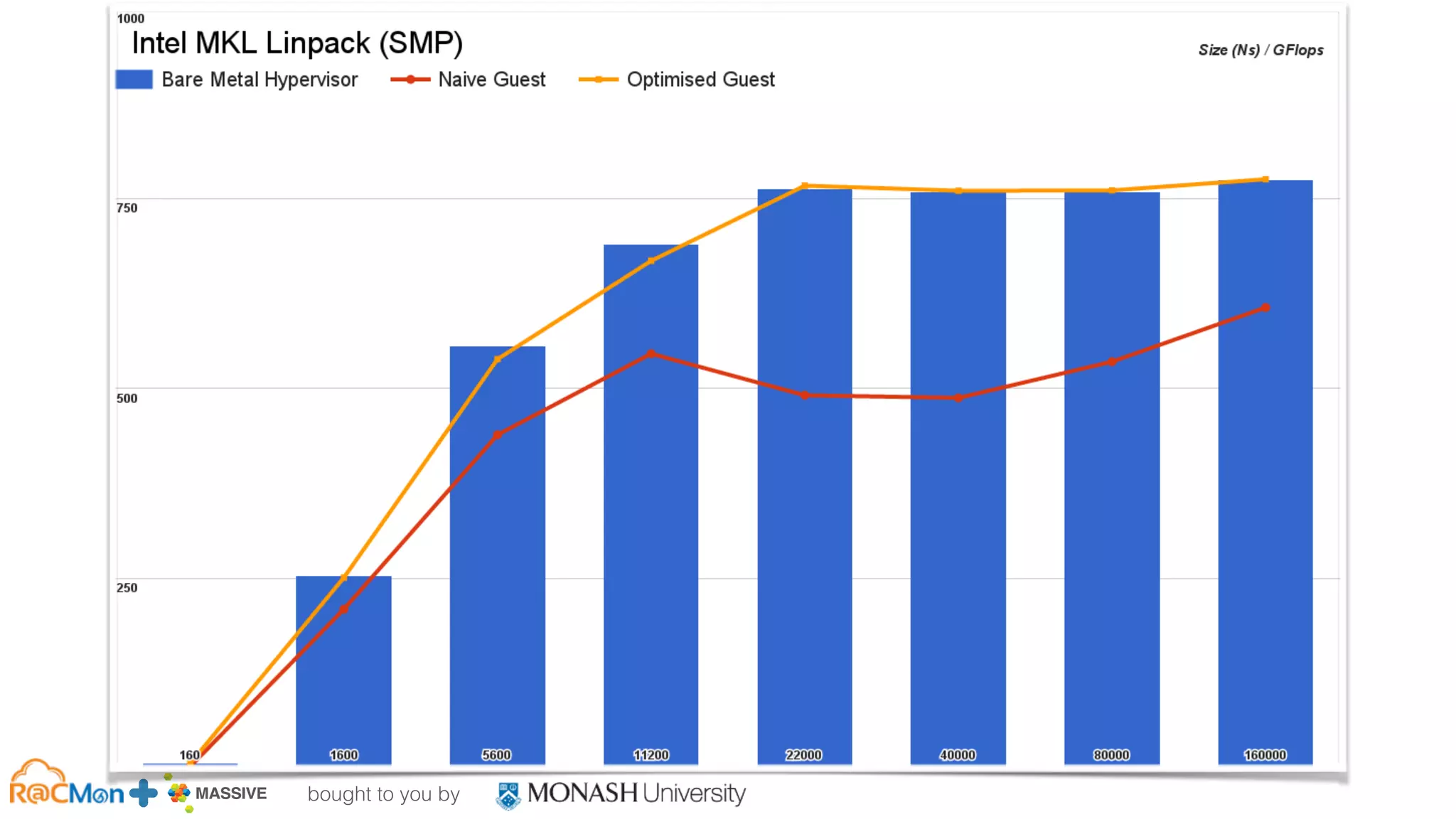
The document outlines the establishment of a GPU-enabled OpenStack cloud at Monash University for high-performance computing (HPC) and data analytics, featuring around 40,000 cores across multiple nodes and designed to support a variety of research workflows. It discusses the implementation details, hardware specifications, and early user experiences with the HPC cloud system, including performance benchmarks and integration challenges. The project aims to facilitate advanced computing capabilities for the Australian research community through a co-designed infrastructure that integrates GPU acceleration and OpenStack technology.























![[OpenStack Day in Korea 2015] Track 2-3 - 오픈스택 클라우드에 최적화된 네트워크 가상화 '누아지(Nuage)'](https://cdn.slidesharecdn.com/ss_thumbnails/23-150213052422-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)



![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








