Download as PDF, PPTX










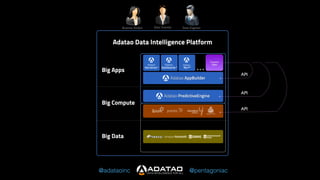

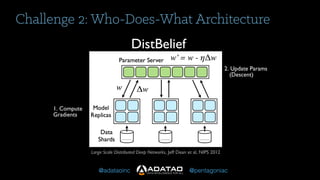




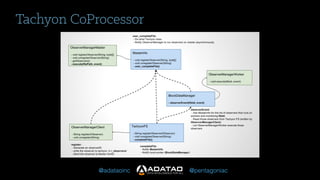
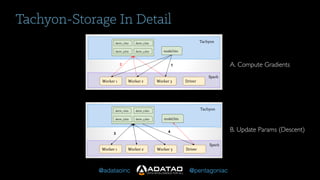
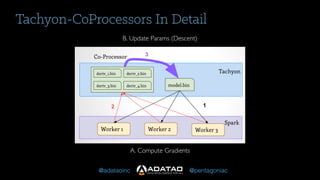


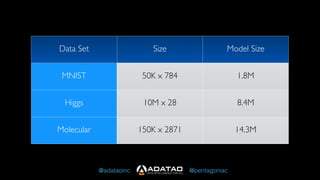
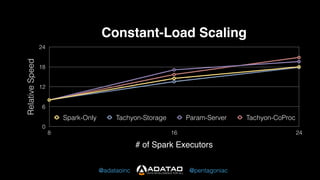
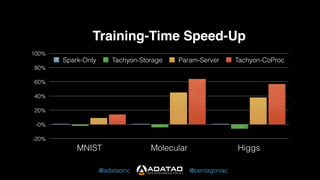
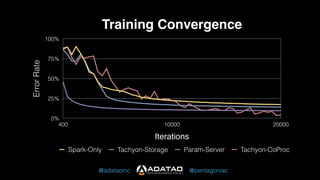








The document outlines Adatao's exploration of distributed deep learning using Spark and Tachyon, detailing various challenges faced and lessons learned during implementation. Key findings include the advantages of combining Spark with Tachyon coprocessing for improved deep learning performance and scalability. The document concludes with insights on architectural decisions, data partitioning, and memory tuning in the context of deep learning applications.











































































