1) The document proposes a training algorithm to deceive anti-spoofing verification for DNN-based speech synthesis. It trains acoustic models through an iterative process of updating the models and anti-spoofing discriminator.
2) The algorithm aims to improve speech quality by compensating for differences between natural and generated speech parameter distributions using adversarial training.
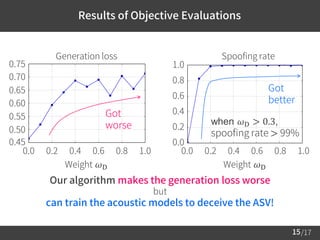
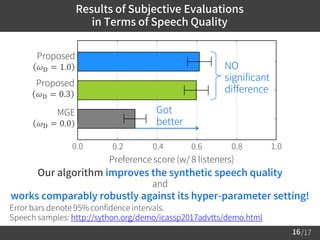
3) Evaluation results show the algorithm improves speech quality over conventional training, while also training the models to effectively deceive the anti-spoofing system. The quality gains are robust against hyperparameter settings.


![/17
Issue: quality degradation in statistical parametric speech
synthesis due to over-smoothing of the speech params.
Countermeasures: reproducing natural statistics
– 2nd moment (a.k.a. Global Variance: GV) [Toda et al., 2007.]
– Histogram[Ohtani et al., 2012.]
Proposed: training algorithm to deceive an Anti-Spoofing
Verification (ASV) for DNN-based speech synthesis
– Tries to deceive the ASV which distinguishes natural / synthetic speech.
– Compensates distribution difference betw. natural / synthetic speech.
Results:
– Improves the synthetic speech quality.
– Works comparably robustly against its hyper-parameter setting.
1
Outline of This Talk](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-2-320.jpg)
![/17
Conventional Training Algorithm:
Minimum Generation Error (MGE) Training
2
Generation
error
𝐿G 𝒄, ො𝒄
Linguistic
feats.
[Wu et al., 2016.]
Natural
speech
params.
𝐿G 𝒄, ො𝒄 =
1
𝑇
ො𝒄 − 𝒄 ⊤ ො𝒄 − 𝒄 → Minimize
𝒄
ML-based
parameter
generation
Generated
speech
params.ො𝒄
Acoustic models
⋯
⋯
⋯
Frame
𝑡 = 1
Static-dynamic
mean vectors
Frame
𝑡 = 𝑇](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-3-320.jpg)
![/173
Issue of MGE Training:
Over-smoothing of Generated Speech Parameters
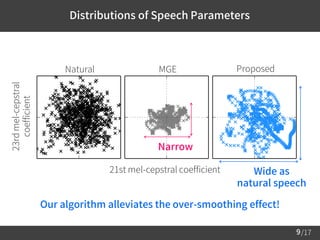
Natural MGE
21st mel-cepstral coefficient
23rdmel-cepstral
coefficient
These distributions are significantly different...
(GV [Toda et al., 2007.] explicitly compensates the 2nd moment.)
Narrow](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-4-320.jpg)

![/17
Anti-Spoofing Verification (ASV):
Discriminator to Prevent Spoofing Attacks w/ Speech
5
[Wu et al., 2016.] [Chen et al., 2015.]
𝐿D,1 𝒄 𝐿D,0 ො𝒄
𝐿D 𝒄, ො𝒄 = → Minimize−
1
𝑇
𝑡=1
𝑇
log 𝐷 𝒄 𝑡 −
1
𝑇
𝑡=1
𝑇
log 1 − 𝐷 ො𝒄 𝑡
ො𝒄
Cross entropy
𝐿D 𝒄, ො𝒄
1: natural
0: generated
Generated
speech params.
𝒄Natural
speech params.
Feature
function
𝝓 ⋅
Here, 𝝓 𝒄 𝑡 = 𝒄 𝑡 ASV 𝐷 ⋅
or
Loss to recognize
generated speech as generated
Loss to recognize
natural speech as natural](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-6-320.jpg)
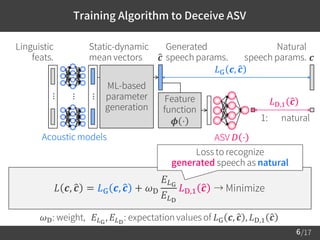
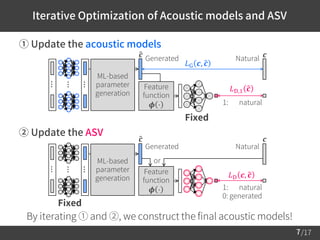
![/17
Compensations of speech feats. through the feature function:
– Automatically-derived feats. such as auto-encoded feats.
– Conventional analytically-derived feats. such as GV
Loss function for training the acoustic models:
– Combination of MGE and adversarial training [Goodfellow et al., 2014.]
The effect of the adversarial training:
– Minimizes the Jensen-Shannon divergence betw. the distributions of
the natural data / generated data.
8
Discussions of Proposed Algorithm](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-9-320.jpg)
![/17
Global Variance (GV): [Toda et al., 2007.]
– 2nd moment of the parameter distribution
10
Compensation of Global Variance
Feature index
0 5 10 15 20
10-3
10-1
101
Globalvariance
Proposed
Natural
MGE
10-2
100
10-4
GV is NOT used for training, but compensated by the ASV!](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-11-320.jpg)
![/17
Maximal Information Coefficient (MIC): [Reshef et al., 2011.]
– Values to quantify a nonlinear correlation b/w two variables
– Natural speech params. tend to have weak correlation [Ijima et al., 2016.]
11
Additional Effect:
Alleviation of Unnaturally Strong Correlation
Natural MGE
0 6 12 18 24
0.0
0.2
0.4
0.6
0.8
1.0
Strong
Weak
Proposed
0 6 12 18 24 0 6 12 18 24
Proposed algorithm not only compensates the GV,
but also makes the correlations among speech params. natural!](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-12-320.jpg)

![/17
Experimental Conditions
13
Dataset
ATR Japanese speech database
(phonetic balanced 503 sentences)
Train / evaluate data 450 sentences / 53 sentences (16 kHz sampling)
Linguistic feats.
274-dimensional vector
(phoneme, accent type, frame position, etc...)
Speech params.
Mel-cepstral coefficients (0th-through-24th),
𝐹0, 5-band aperiodicity
Prediction params.
Mel-cepstral coefficients
(the others were NOT predicted)
Optimization algorithm AdaGrad [Duchi et al., 2011.] (learning rate: 0.01)
Acoustic models Feed-Forward 274 – 3x400 (ReLU) – 75 (linear)
ASV Feed-Forward 25 – 2x200 (ReLU) – 1 (sigmoid)](https://image.slidesharecdn.com/saito2017icassppub-170307221315/85/Saito2017icassp-14-320.jpg)






![129966864160453838[1]](https://cdn.slidesharecdn.com/ss_thumbnails/1299668641604538381-130806105228-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















![ICASSP2017読み会 (Deep Learning III) [電通大 中鹿先生]](https://cdn.slidesharecdn.com/ss_thumbnails/icayominakashika-170628021331-thumbnail.jpg?width=640&height=640&fit=bounds)





































































