Download as PDF, PPTX
















![経路列挙
Path enumeration
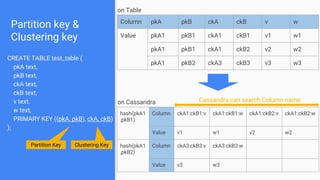
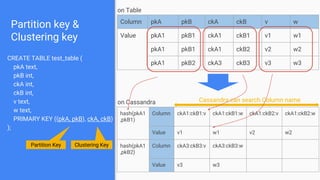
CREATE TABLE pathenum (
id text,
fqdn text,
child text,
code text,
PRIMARY KEY (id, fqdn)
);
id fqdn child code
test A [a,b] A
test A:a [1,2] a
test A:b [3,4,5] b
test A:a:1 1
test A:a:2 2
test A:b:3 3
test A:b:4 4
test A:b:5 5
A a
b
1
2
3
4
5](https://image.slidesharecdn.com/cassandracassandra-171019072822/85/Cassandra-cassandra-Data-Modeling-concepts-for-NoSQL-weak-point-25-320.jpg)




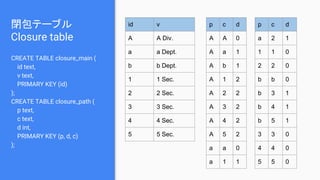
![閉包テーブル
Closure table
CREATE TABLE closure_main (
id text,
v text,
PRIMARY KEY (id)
);
CREATE TABLE closure_path (
p text,
c text,
d int,
PRIMARY KEY (p, d, c)
);
CREATE CUSTOM INDEX fn_c ON
test.closure_path (c) USING 'org.apache.
cassandra.index.sasi.SASIIndex';
p c d
A A 0
A a 1
A b 1
A 1 2
A 2 2
A 3 2
A 4 2
A 5 2
a a 0
a 1 1
p c d
a 2 1
1 1 0
2 2 0
b b 0
b 3 1
b 4 1
b 5 1
3 3 0
4 4 0
5 5 0
//show ancestors
select p from closure_path where c = '1';
select * from closure_main where id in [?];
//show children of a
select c from closure_path where p = 'a' and d
= 1;
select * from closure_main where id in [?];
//show descendants of A
select c from closure_path where p = 'A';
select * from closure_main where id in [?];
//show sibilings of a
//load a's parent = A
select * from closure_path where c = 'a';
select c from closure_path where p = 'A' and d
= 1;
select * from closure_main where id in [?];](https://image.slidesharecdn.com/cassandracassandra-171019072822/85/Cassandra-cassandra-Data-Modeling-concepts-for-NoSQL-weak-point-31-320.jpg)



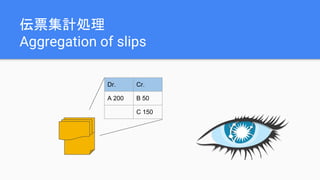





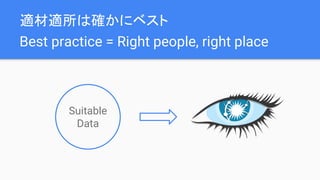
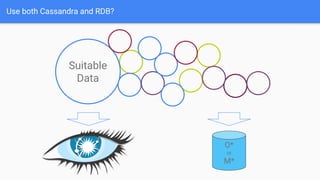
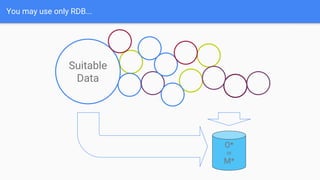
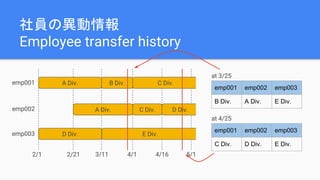
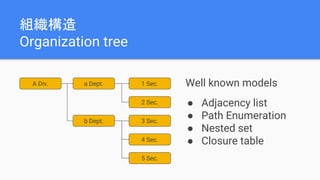
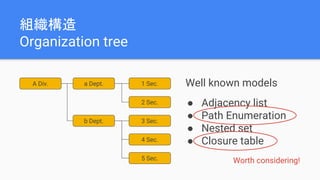
The document discusses best practices for data modeling in Cassandra, emphasizing the importance of understanding suitable and unsuitable data types for the database. It covers various data structures, including historical data management, organizational trees, and summarized data processes, detailing methods for using Cassandra efficiently. Additionally, the document provides examples of table creation and querying techniques and addresses the need for high-speed processing and data consistency.






![[D15] 最強にスケーラブルなカラムナーDBよ、Hadoopとのタッグでビッグデータの地平を目指せ!by Daisuke Hirama](https://cdn.slidesharecdn.com/ss_thumbnails/d15iti-140624011143-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











