Downloaded 235 times








![[LINEAR REGRESSION]](https://image.slidesharecdn.com/deeplearningandcomputervision-190624084257/85/Deep-learning-and-computer-vision-10-320.jpg)


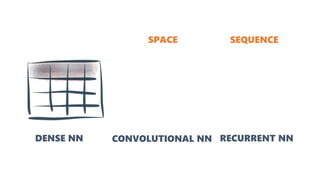

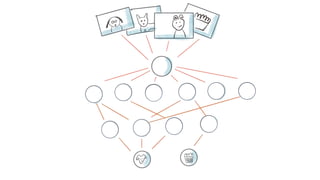


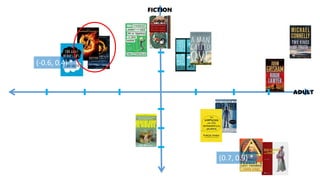
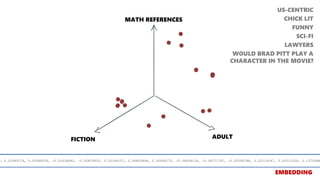
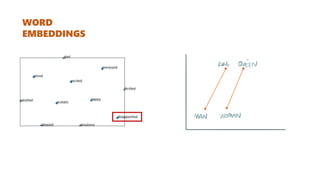

![[FACENET]
T-SNE
Projection of
128D to 2D](https://image.slidesharecdn.com/deeplearningandcomputervision-190624084257/85/Deep-learning-and-computer-vision-25-320.jpg)




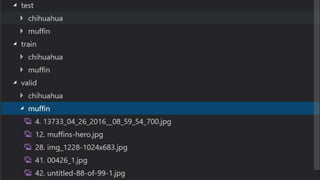

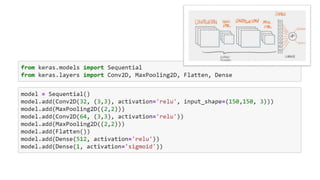
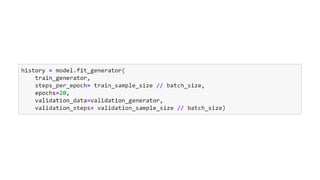
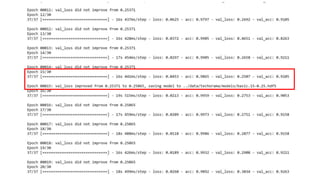
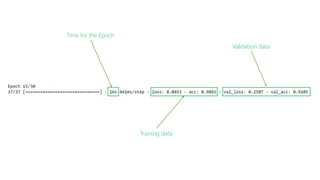

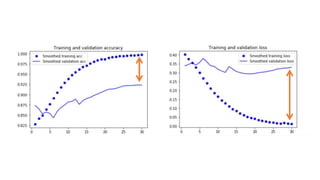

![Chihuahua the movie
[DATA AUGMENTATION]](https://image.slidesharecdn.com/deeplearningandcomputervision-190624084257/85/Deep-learning-and-computer-vision-41-320.jpg)
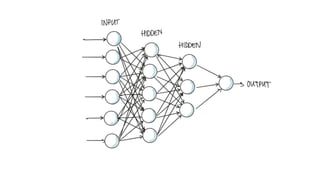
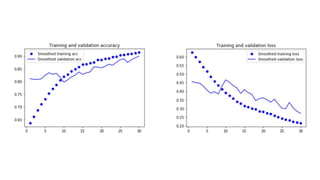
![[DROPOUT]](https://image.slidesharecdn.com/deeplearningandcomputervision-190624084257/85/Deep-learning-and-computer-vision-43-320.jpg)
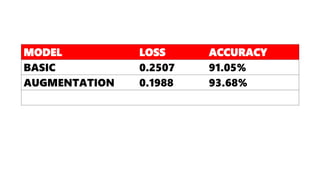
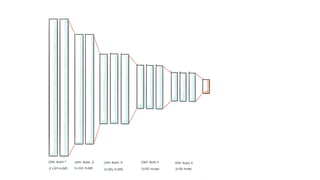
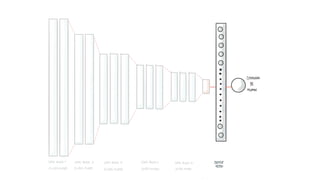
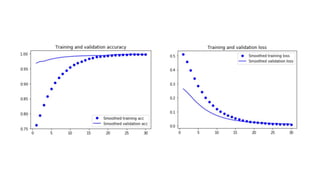
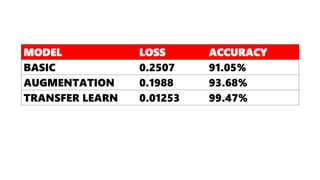











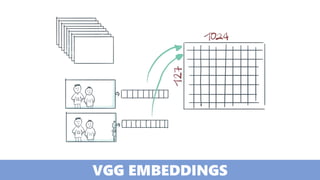

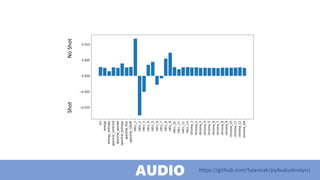






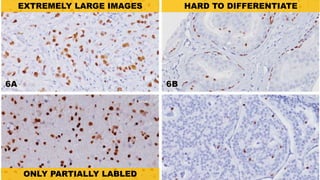
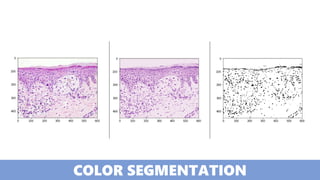












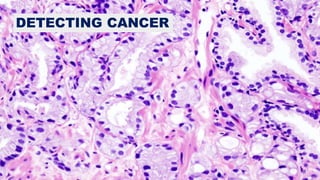
The document discusses practical applications of deep learning in various fields such as cancer detection and shoplifting prevention. It outlines techniques such as neural networks, model training, and data augmentation, while emphasizing the importance of understanding business needs and ethical concerns. Additionally, it highlights challenges posed by limited sample sizes and biases in machine learning models.















































































