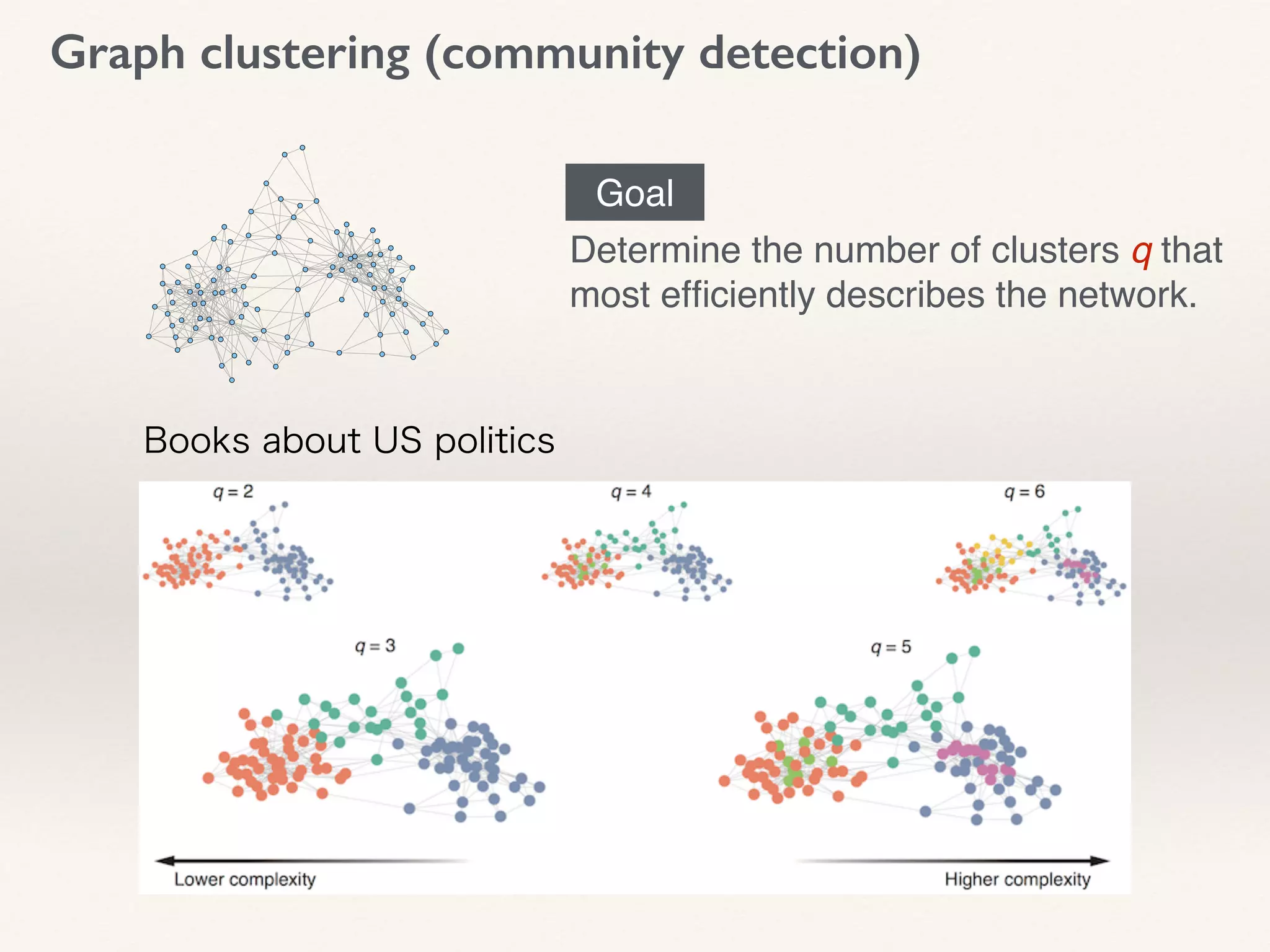
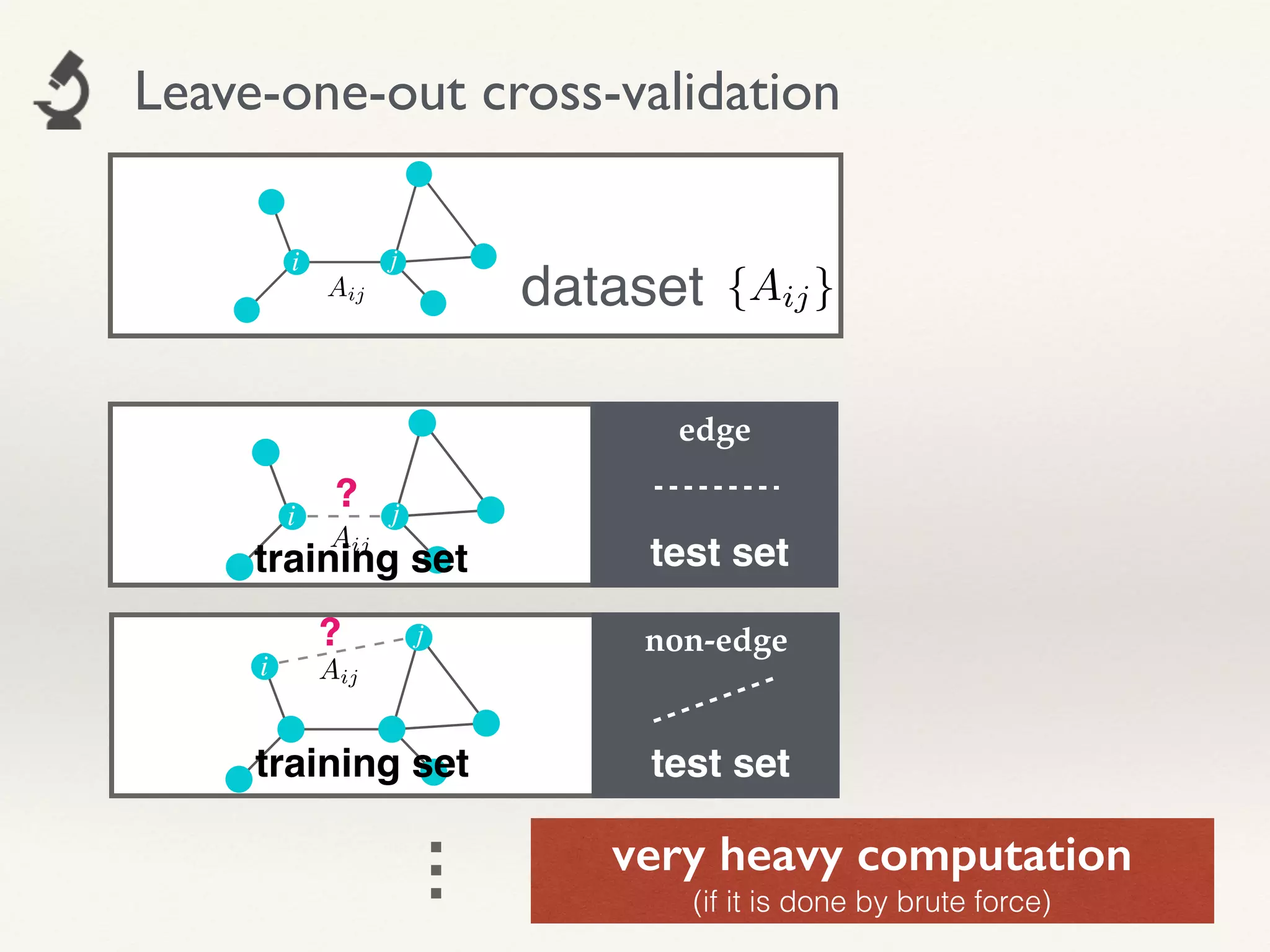
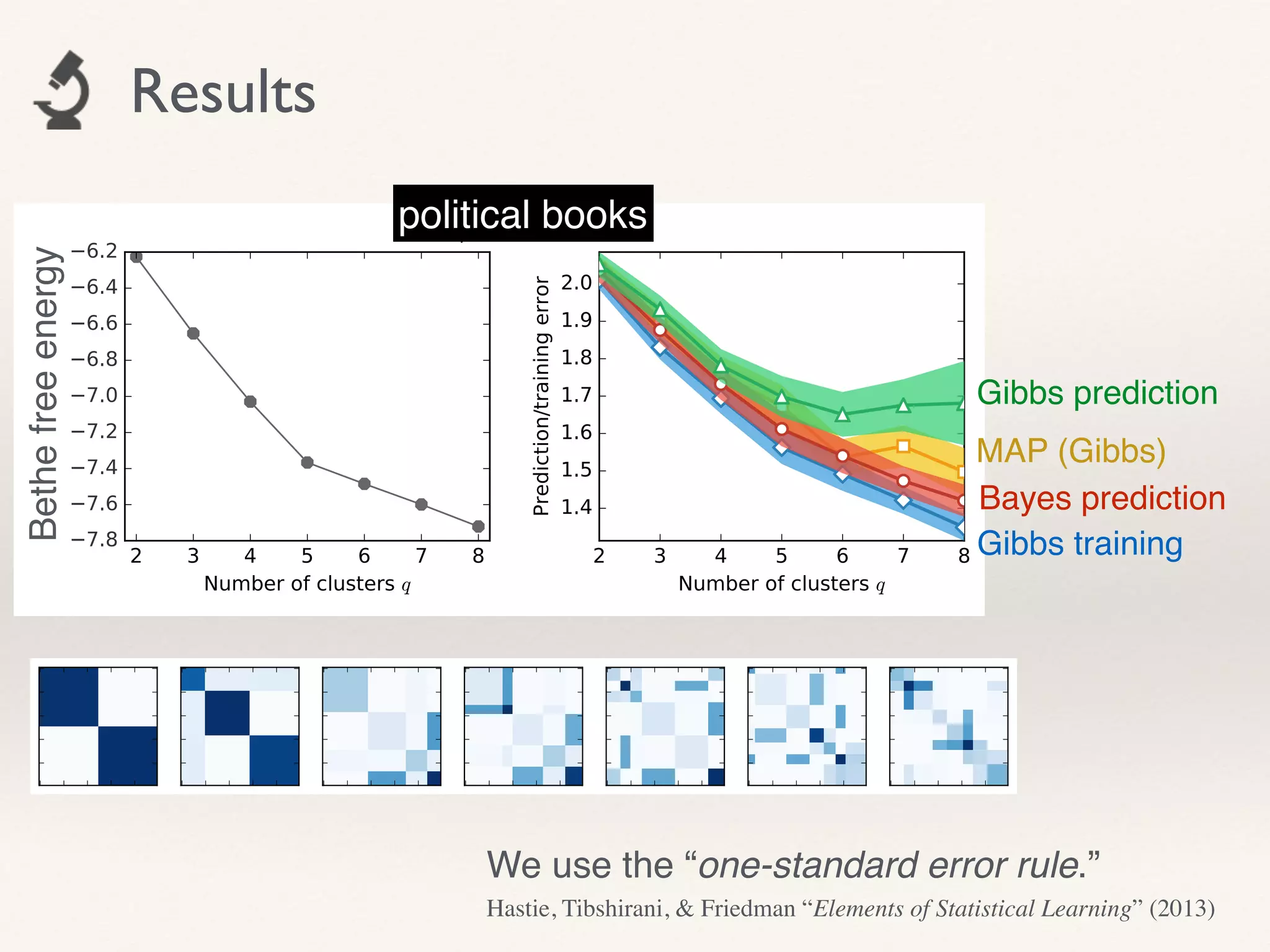
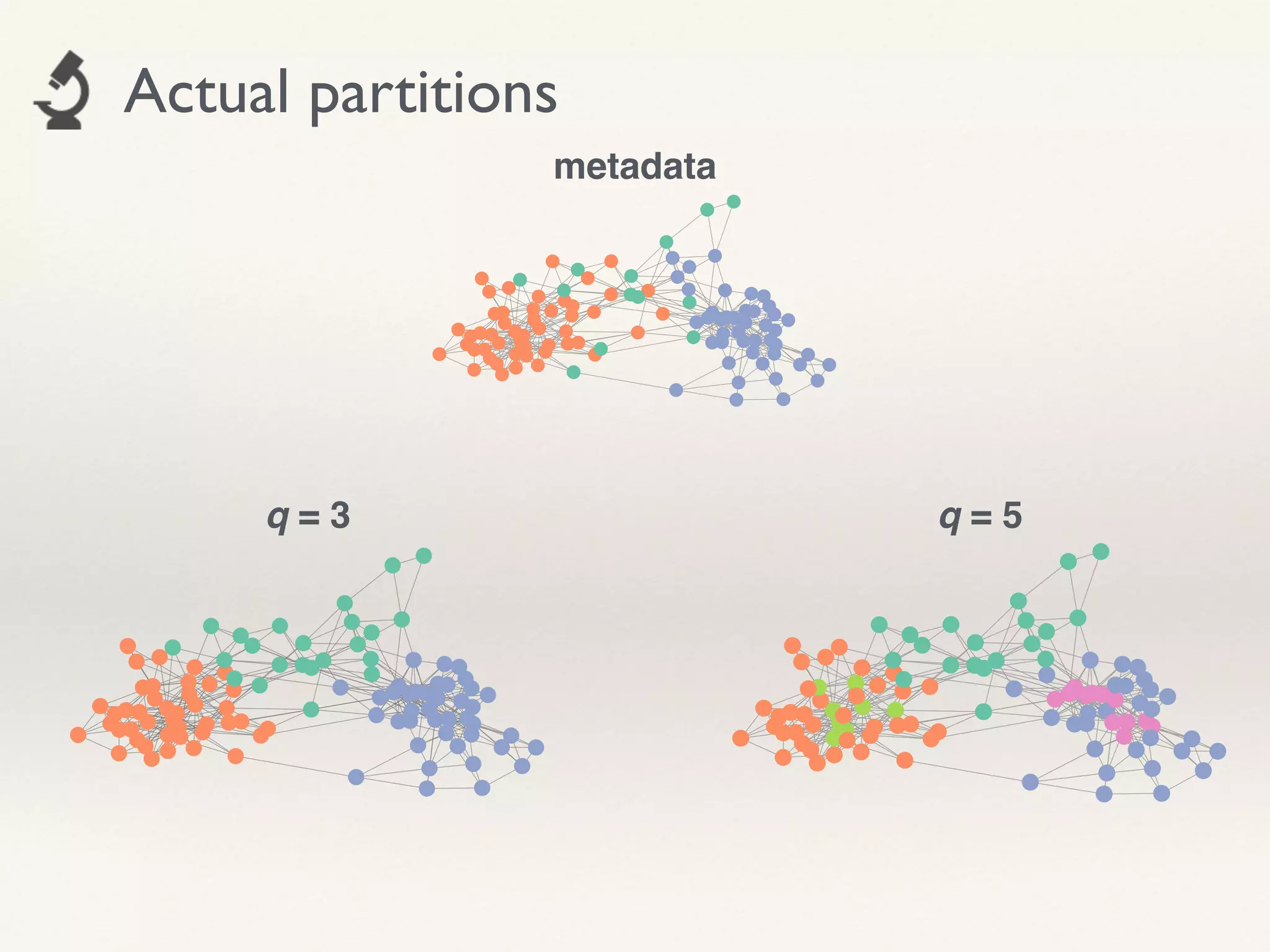
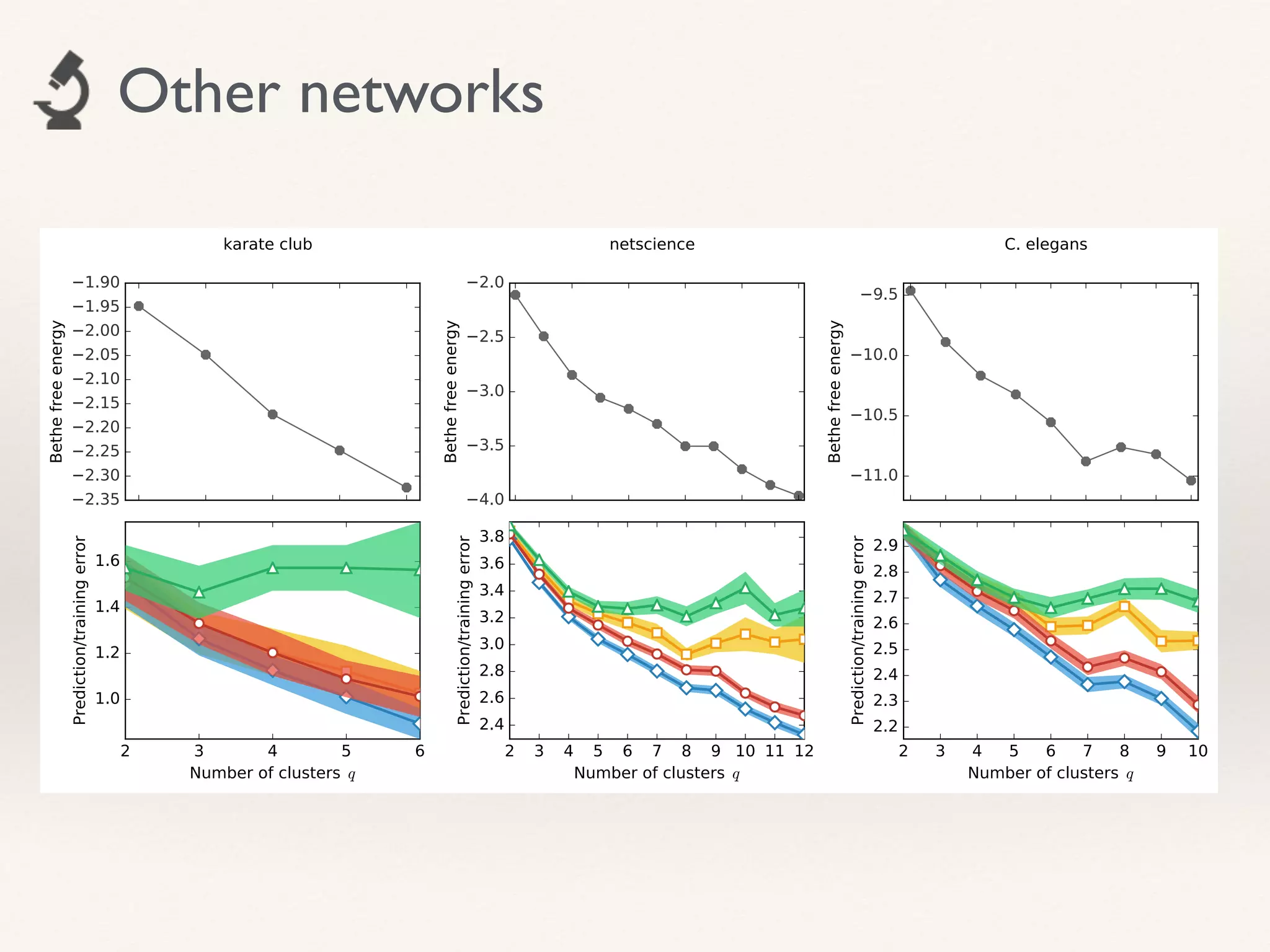
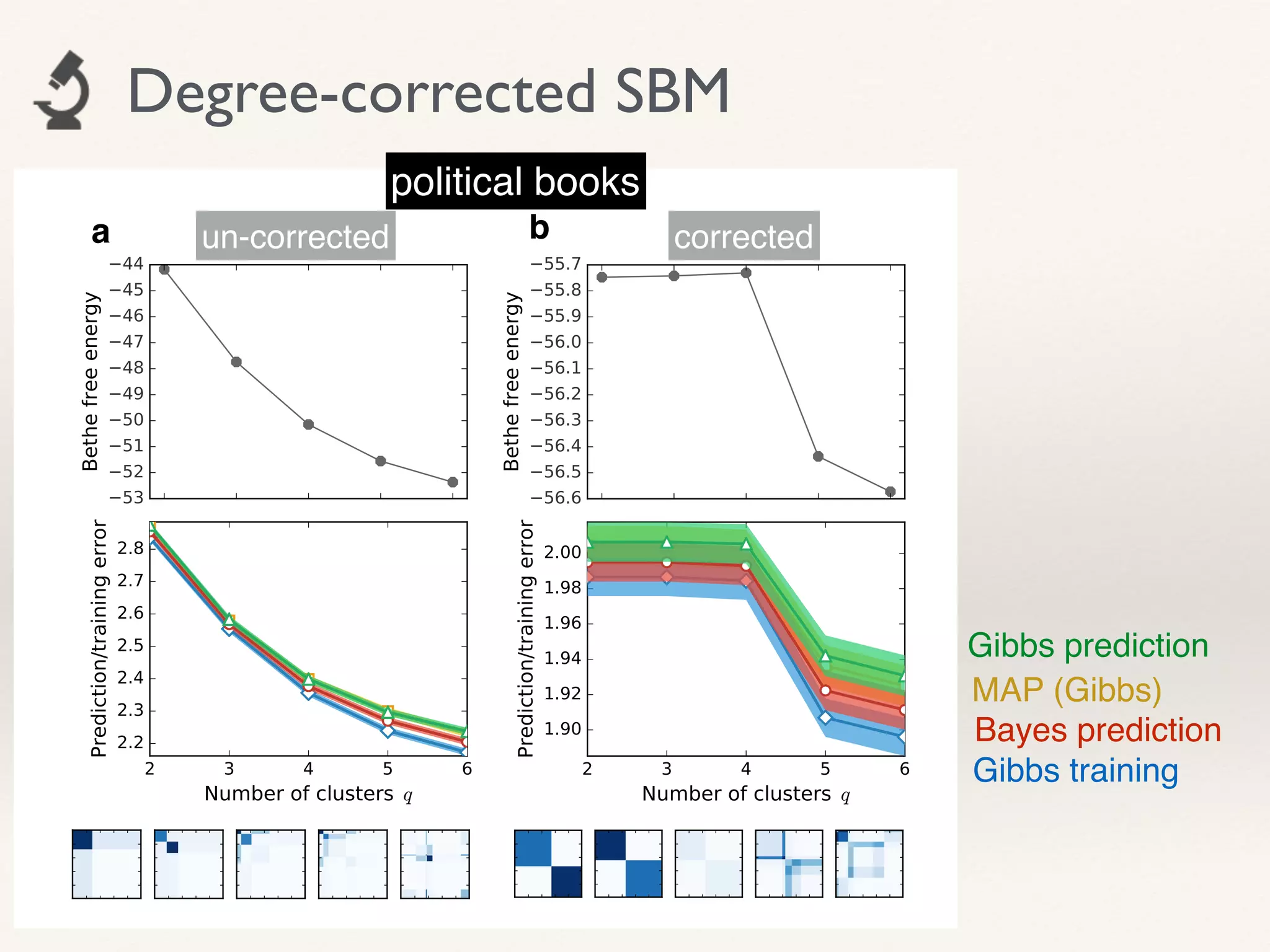
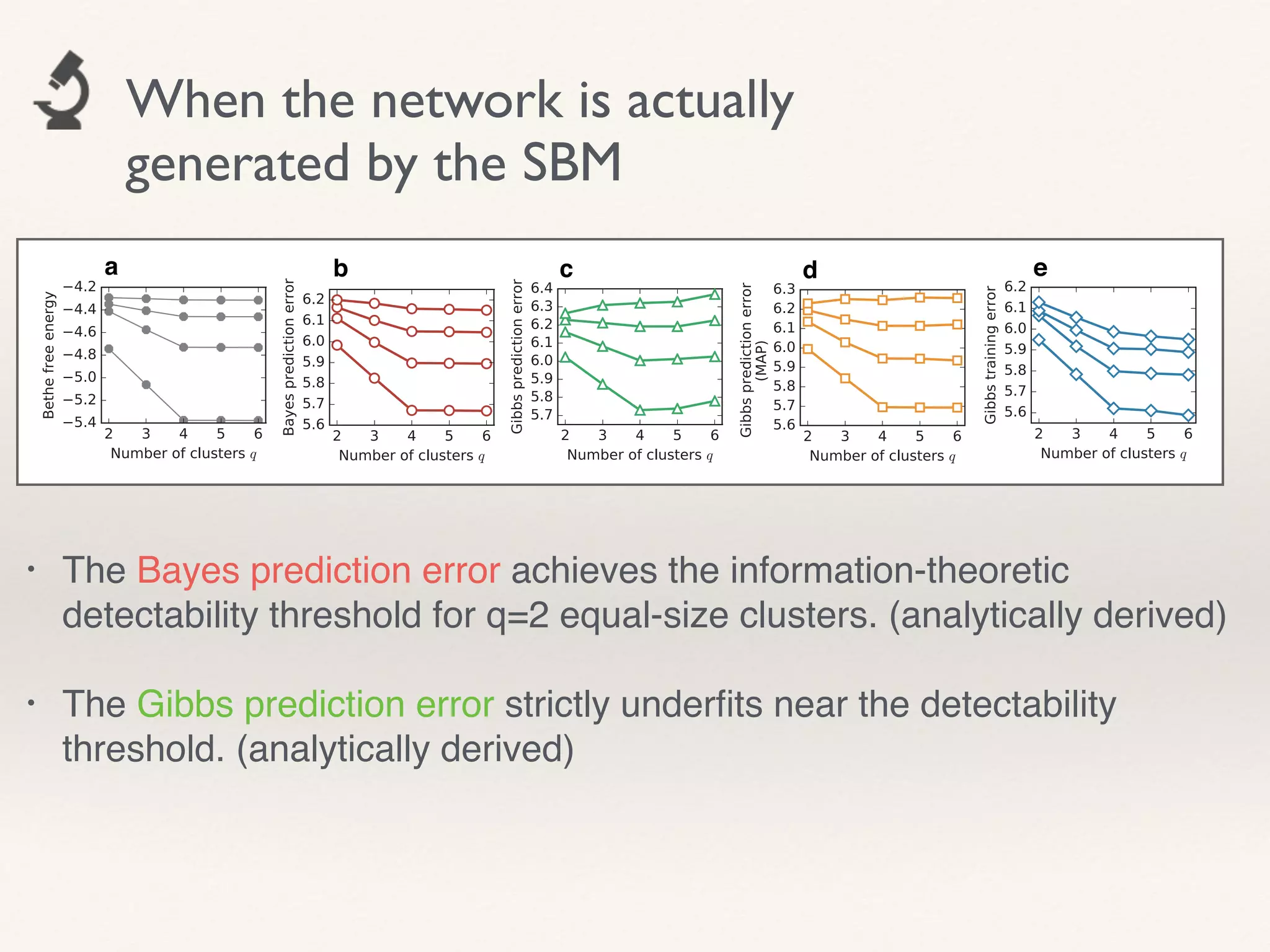
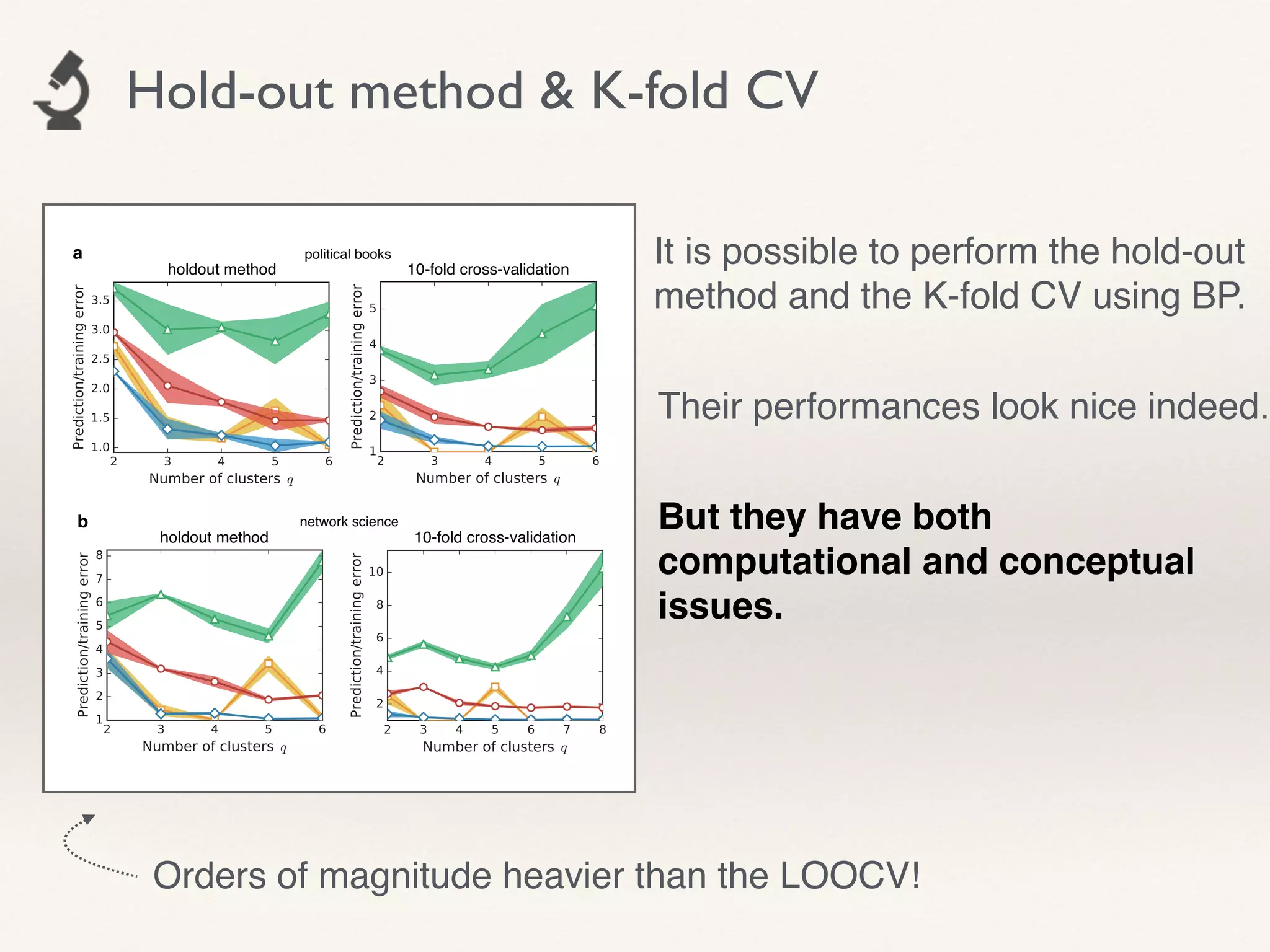
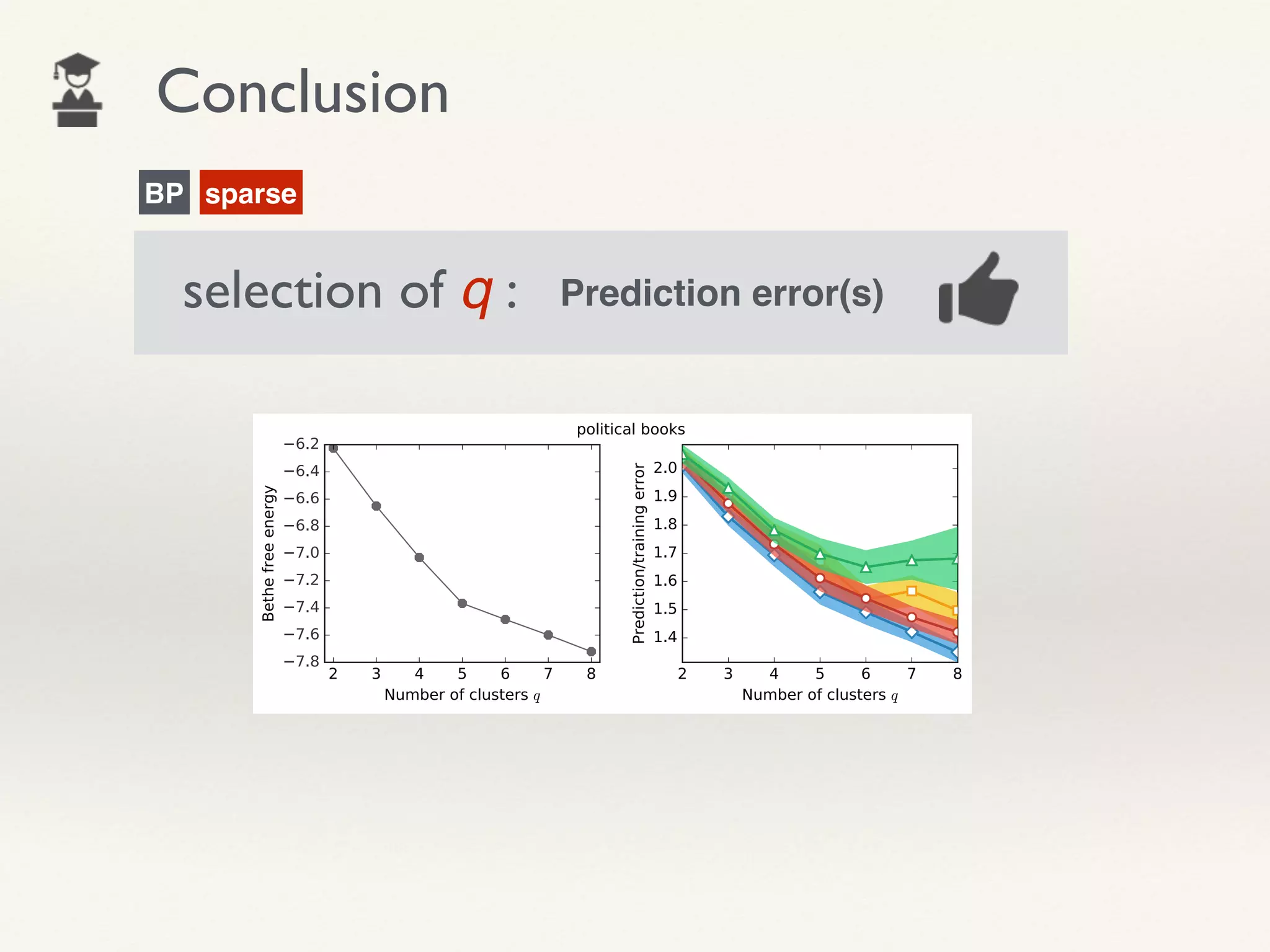
- The document proposes using leave-one-out cross-validation (LOOCV) estimates of prediction errors to select the number of clusters (q) in community detection on networks.
- It considers 4 types of LOOCV estimates calculated efficiently using Belief Propagation, and analyzes their theoretical properties.
- The approach is shown to perform reasonably in practice on example networks, providing a principled and scalable method for selecting q.