Contacts
Haesun Park
Email :haesunrpark@gmail.com
Meetup: https://www.meetup.com/Hongdae-Machine-Learning-Study/
Facebook : https://facebook.com/haesunrpark
Blog : https://tensorflow.blog
2
3.
Book
파이썬 라이브러리를 활용한머신러닝, 박해선.
(Introduction to Machine Learning with Python, Andreas
Muller & Sarah Guido의 번역서입니다.)
번역서의 1장과 2장은 블로그에서 무료로 읽을 수 있습니다.
원서에 대한 프리뷰를 온라인에서 볼 수 있습니다.
Github:
https://github.com/rickiepark/introduction_to_ml_with_python/
3
머신러닝이란
데이터에서 지식을 추출하는작업
통계학, 인공지능, 컴퓨터 과학이 어우러진 연구분야
예측 분석이나 통계적 머신러닝으로도 불림
위키피디아 “인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과
기술을 개발하는 분야”
Arthur Samuel “Field of study that gives computers the ability to learn without
being explicitly programmed”
5
6.
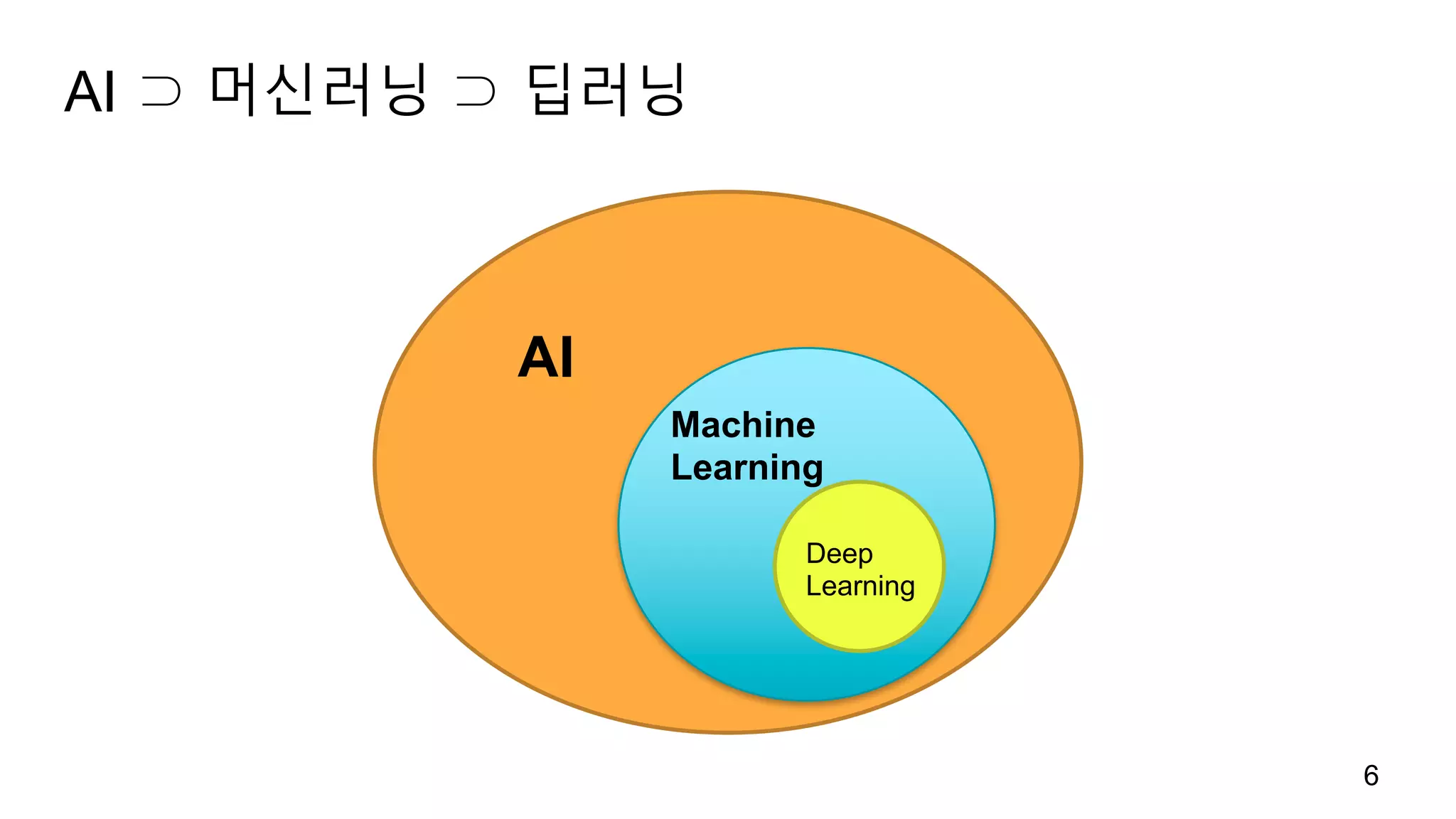
AI ⊃ 머신러닝⊃ 딥러닝
6
Deep
Learning
Machine
Learning
AI
7.
왜 머신러닝인가?
규칙기반 전문가시스템(Rule based expert system)의 문제점
결정에 필요한 로직이 한 분야나 작업에 국한, 작업 변경에 따라 시스템 개발을
다시 수행할 수도 있음
규칙을 설계하려면 분야의 전문가들의 결정 방식에 대해 잘 알아야 함
2001년 이전까지 얼굴 인식 문제를 풀지 못함
컴퓨터의 픽셀 단위는 사람이 인식하는 방식과 다름, 얼굴이 무엇인지 일련의
규칙을 만들기 어려움
머신러닝으로 많은 얼굴 이미지를 제공하면 얼굴을 특정하는 요소를 찾을 수 있음
7
8.
지도 학습(Supervised Learning)
알고리즘에입력과 기대하는 출력을 제공
알고리즘은 입력으로 부터 기대하는 출력을 만드는 방법을 찾음
스팸 문제의 경우 이메일(입력)과 스팸 여부(기대 출력)을 제공해야 함
지도 학습의 예
손글씨 숫자 판별: 데이터 수집에 수작업이 많음. 비교적 쉽고 적은 비용 소모.
의료 영상에 기반한 암진단: 도덕적/개인정보 문제 고가의 장비, 전문가 의견 필요
신용카드 부정거래 감지: 고객에게 신고가 올 때까지 기다리면 됨.
8
9.
비지도 학습(Unsupervised Learning)
알고리즘에입력은 주어지지만 출력은 제공되지 않음
따라서 비지도 학습의 성공을 평가하기 어려움
비지도 학습의 예
블로그 글의 주제: 사전에 어떤 주제가 있는지 얼마나 많은 주제가 있는지 모름
고객의 취향 그룹: 부모, 독서광, 게이머 등 어떤 그룹이 얼마나 많이 있는지 모름
웹사이트 비정상적 접근: 부정행위나 버그 감지를 위한 비정상적인 패턴은 각기
다르고 가지고 있는 비정상 데이터가 없을 수 있음.
9
10.
데이터, 특성
특성 추출,특성 공학: 입력 특성을 만들어 내는 일
10
나이 성별 구매빈도 이메일 ...
37 남 10 xxx@gmail
33 여 15 yyy@gmail
특성(features), 속성,
샘플,
데이터 포인트
11.
문제와 데이터 이해
알고리즘마다잘 들어맞는 데이터나 문제의 종류가 다름
어떤 질문에 대답을 원하는가? 원하는 답을 만들 수 있는 데이터를 가지고 있는가?
어떻게 머신러닝의 문제로 가장 잘 기술할 수 있는가?
충분한 데이터가 있는가?
좋은 예측을 위한 특성을 가지고 있는가?
애플리케이션의 성과를 어떻게 측정할 것인가?
다른 연구나 제품에 어떤 영향이 있는가?
11
파이썬(Python)
과학 분야를 위한표준 프로그래밍 언어
MATLAB, R 같은 도메인 특화 언어와 Java, C 같은 범용 언어의 장점을 갖춤
통계, 머신러닝, 자연어, 이미지, 시각화 등을 포함한 풍부한 라이브러리
브라우저 기반 인터랙티브 프로그래밍 환경인 Jupyter Notebook
파이썬 주도 딥러닝 라이브러리: TensorFlow, PyTorch, Theano, ...
13
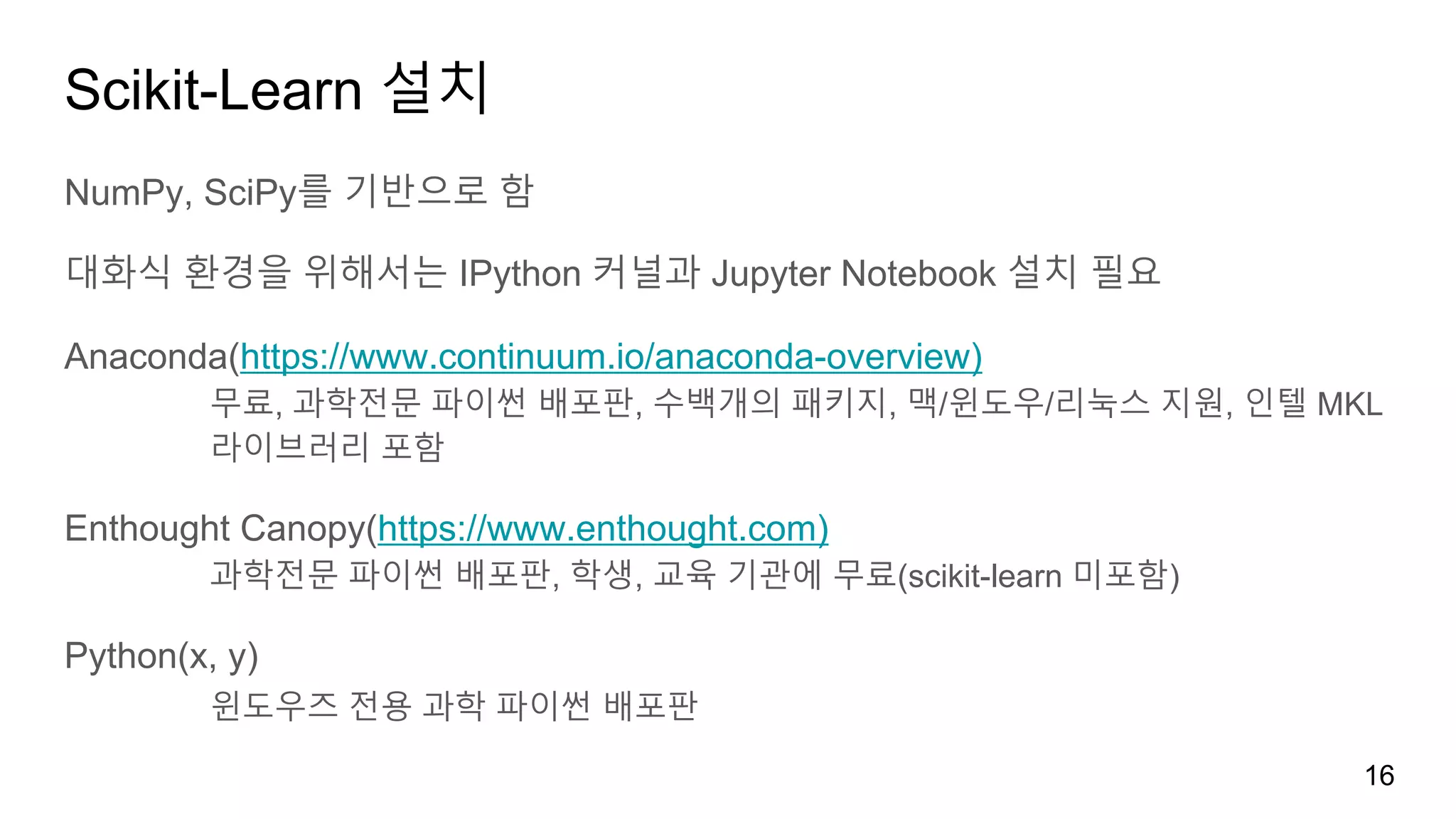
Scikit-Learn 설치
NumPy, SciPy를기반으로 함
대화식 환경을 위해서는 IPython 커널과 Jupyter Notebook 설치 필요
Anaconda(https://www.continuum.io/anaconda-overview)
무료, 과학전문 파이썬 배포판, 수백개의 패키지, 맥/윈도우/리눅스 지원, 인텔 MKL
라이브러리 포함
Enthought Canopy(https://www.enthought.com)
과학전문 파이썬 배포판, 학생, 교육 기관에 무료(scikit-learn 미포함)
Python(x, y)
윈도우즈 전용 과학 파이썬 배포판
16
Jupyter Notebook
프로그램 코드+ 결과 + 문서를 위한
대화식 개발 환경
탐색적 데이터 분석에 유리하여
많은 과학자 엔지니어들이 사용
https://jupyter.org
18
19.
NumPy
다차원 배열, 선형대수, 다양한 수학 함수, 난수 생성기 포함
scikit-learn의 기본 데이터 구조
http://www.numpy.org
http://www.scipy-lectures.org/ 의 1장
19
20.
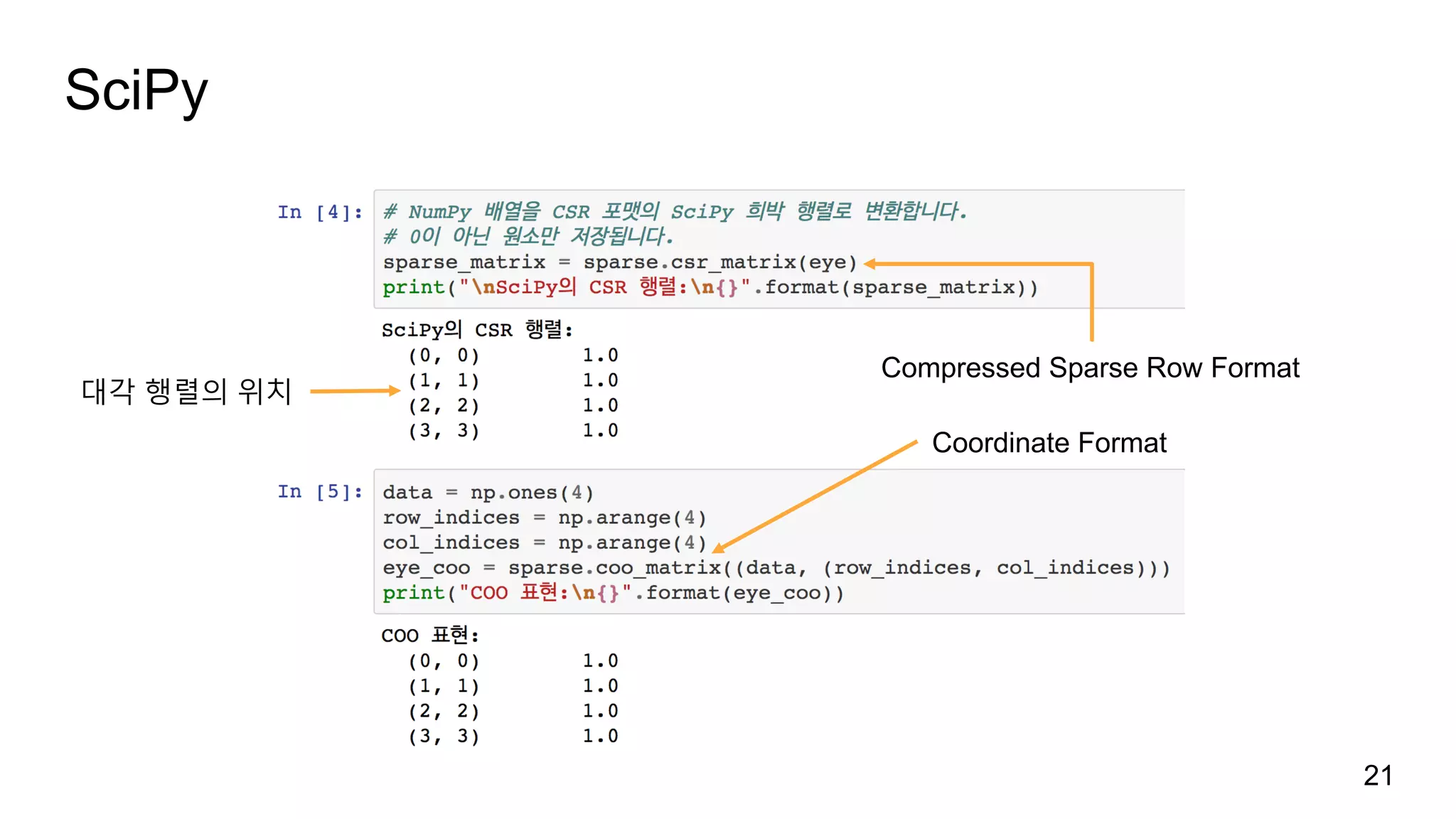
SciPy
선형 대수, 최적화,통계 등 많은 과학 계산 함수를 모아놓은 파이썬 패키지
scikit-learn은 알고리즘 구현에 SciPy에 많이 의존함
0이 많이 포함된 행렬을 효율적으로 표현하기 위한 희소 행렬 scipy.sparse 패키지
주요하게 사용
https://www.scipy.org/scipylib
http://www.scipy-lectures.org/
의 2.5절
20
단위 행렬
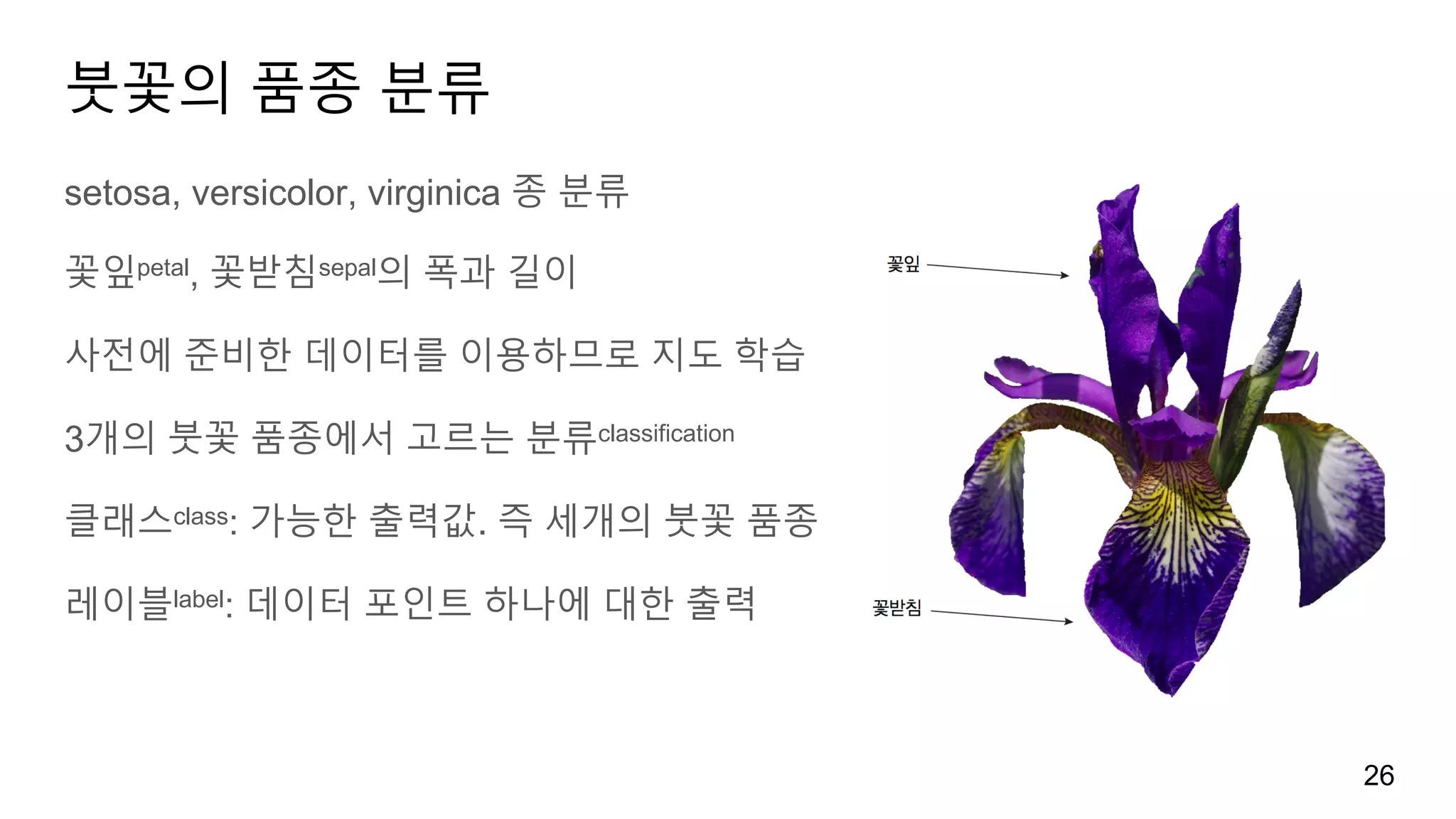
붓꽃의 품종 분류
setosa,versicolor, virginica 종 분류
꽃잎petal, 꽃받침sepal의 폭과 길이
사전에 준비한 데이터를 이용하므로 지도 학습
3개의 붓꽃 품종에서 고르는 분류classification
클래스class: 가능한 출력값. 즉 세개의 붓꽃 품종
레이블label: 데이터 포인트 하나에 대한 출력
26
27.
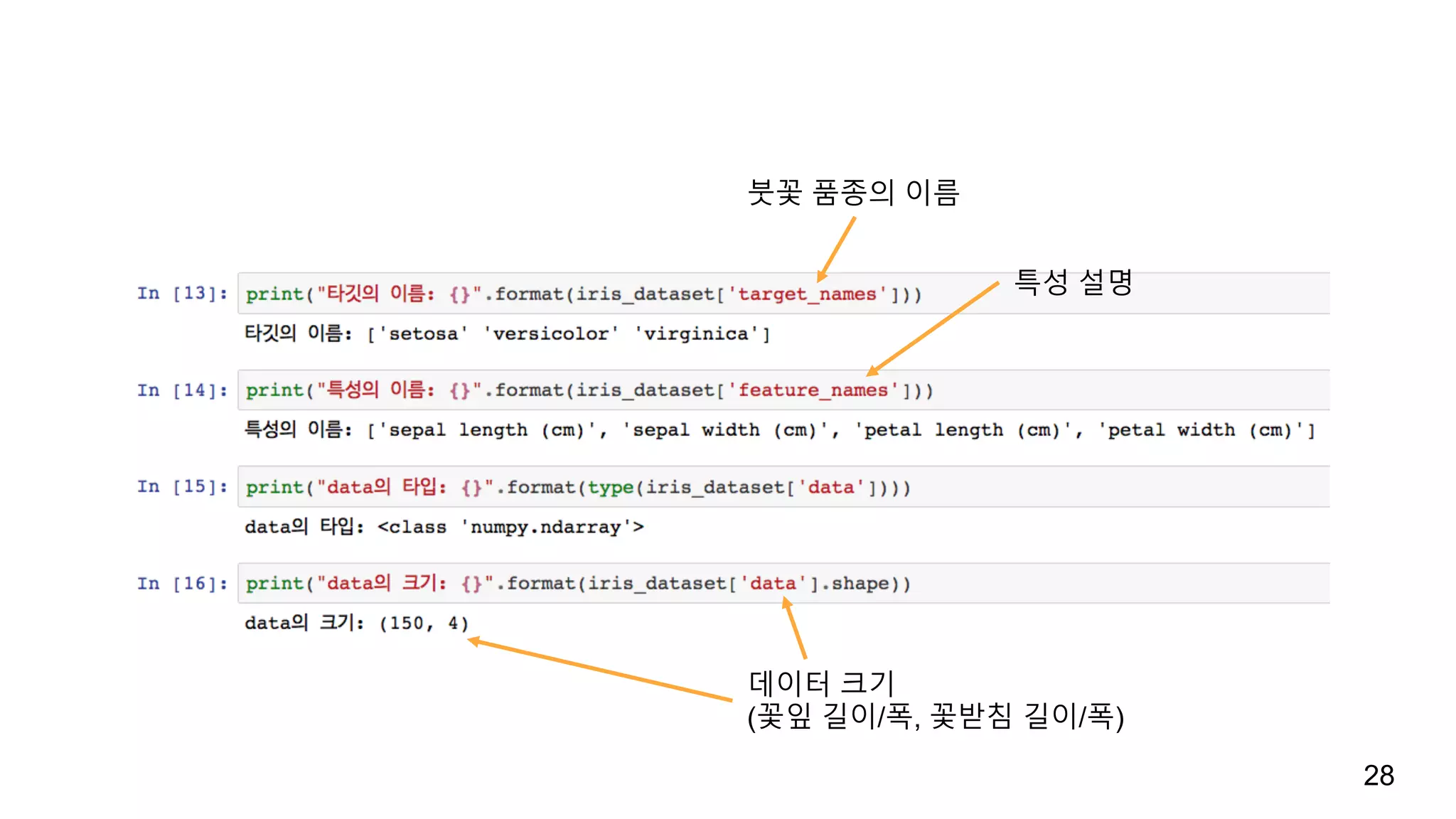
데이터 적재
붓꽃 데이터:sklearn.datasets.load_iris()
load_digits(), load_boston(), load_breast_cancer(), load_diabetes()
27
Bunch
클래스
데이터셋에 대한 설명
iris_dataset.DESCR[:193] 도 가능
3:1 비율 (test_size매개변수에서 변경 가능)
훈련 데이터와 테스트 데이터
훈련에 사용한 데이터는 테스트 (일반화) 에 사용하지 않음
데이터 분리: 훈련 세트, 테스트 세트(홀드아웃holdout 세트),
X(2차원 배열-행렬, 대문자), y(1차원 배열-벡터, 소문자)
30
31.
산점도Scatter Plot
두 개의특성을 이용 점으로 데이터 표시(3차원 이상은 표현이 어려움)
각 특성의 조합에 대해 모두 그리는 pandas의 산점도 행렬Scatter Matrix 이용
31
데이터프레임으로 변경























![데이터 적재
붓꽃 데이터: sklearn.datasets.load_iris()
load_digits(), load_boston(), load_breast_cancer(), load_diabetes()
27
Bunch
클래스
데이터셋에 대한 설명
iris_dataset.DESCR[:193] 도 가능](https://image.slidesharecdn.com/1-170725041019/75/1-introduction-27-2048.jpg)


















































![[코세나, kosena] 금융권의 머신러닝 활용사례](https://cdn.slidesharecdn.com/ss_thumbnails/skytree-171103160507-thumbnail.jpg?width=640&height=640&fit=bounds)


![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PYCON KOREA 2017] Python 입문자의 Data Science(Kaggle) 도전](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2017fianl-170810071737-thumbnail.jpg?width=640&height=640&fit=bounds)












![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 9장 텐서플로 시작하기](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181127072259-thumbnail.jpg?width=640&height=640&fit=bounds)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181010080045-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)




