머신러닝은 무엇인가?
머신러닝은 흑마법입니다.
소프트웨어엔지니어링/프로그래밍은 백마법입니다.
오늘은 이 두 마법 방법론이 어떻게 충돌하고 어떻게 서로를 돕는지에 대해서
얘기해보고자 합니다.
Yun (AWS) SE Challenges March 16th, 2017 3 / 38
7.
머신러닝은 무엇인가?
머신러닝은 흑마법입니다.
소프트웨어엔지니어링/프로그래밍은 백마법입니다.
오늘은 이 두 마법 방법론이 어떻게 충돌하고 어떻게 서로를 돕는지에 대해서
얘기해보고자 합니다.
다분히 뭉뚱그려서 얘기하는 것을 양해해 주세요!
Yun (AWS) SE Challenges March 16th, 2017 3 / 38
8.
목표
우리의 목표는 자동화된시스템을 만드는 것입니다.
Yun (AWS) SE Challenges March 16th, 2017 4 / 38
9.
목표
우리의 목표는 자동화된시스템을 만드는 것입니다.
주어진 입력 x에 대해 우리가 원하는 결과 f(x)를 컴퓨터가 알아서
계산해주길 원합니다.
x → → f(x)
Yun (AWS) SE Challenges March 16th, 2017 4 / 38
10.
두가지 방법론
프로그래밍
어떤 입력들이들어올지
생각한다
모든 입력 x에 대해 f(x)를
계산하는 알고리즘을 생각한다
알고리즘을 구현한다
Since ENIAC (1946)
Yun (AWS) SE Challenges March 16th, 2017 5 / 38
11.
두가지 방법론
프로그래밍
어떤 입력들이들어올지
생각한다
모든 입력 x에 대해 f(x)를
계산하는 알고리즘을 생각한다
알고리즘을 구현한다
Since ENIAC (1946)
머신러닝
머신러닝 알고리즘을 고른다
알고리즘에게 예제들을
보여준다
(x1, f(x1)), (x2, f(x2)), . . .
알고리즘에게 일을 시킨다
Since Perceptron (1957)
Yun (AWS) SE Challenges March 16th, 2017 5 / 38
12.
프로그래밍이 좋을 때
수학적으로잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38
13.
프로그래밍이 좋을 때
수학적으로잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38
14.
프로그래밍이 좋을 때
수학적으로잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38
15.
프로그래밍이 좋을 때
수학적으로잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38
16.
머신러닝이 좋을 때
그렇지만수학적으로 잘 정의되지 않는 문제들도 풀어야 할 때가 있습니다.
예를 들면:
다음 중 방울이 아닌 이미지를 찾아보시오
방울이 뭔데요?
배경은 무시해야 하나요?
배경이 뭔데요?
. . .
Yun (AWS) SE Challenges March 16th, 2017 7 / 38
17.
머신러닝이 좋을 때
그렇지만수학적으로 잘 정의되지 않는 문제들도 풀어야 할 때가 있습니다.
예를 들면:
다음 중 방울이 아닌 이미지를 찾아보시오
방울이 뭔데요?
배경은 무시해야 하나요?
배경이 뭔데요?
. . .
Yun (AWS) SE Challenges March 16th, 2017 7 / 38
18.
머신러닝이 좋을 때
그렇지만수학적으로 잘 정의되지 않는 문제들도 풀어야 할 때가 있습니다.
예를 들면:
다음 중 방울이 아닌 이미지를 찾아보시오
방울이 뭔데요?
배경은 무시해야 하나요?
배경이 뭔데요?
. . .
Yun (AWS) SE Challenges March 16th, 2017 7 / 38
19.
머신러닝이 좋을 때
그렇지만수학적으로 잘 정의되지 않는 문제들도 풀어야 할 때가 있습니다.
예를 들면:
다음 중 방울이 아닌 이미지를 찾아보시오
방울이 뭔데요?
배경은 무시해야 하나요?
배경이 뭔데요?
. . .
Yun (AWS) SE Challenges March 16th, 2017 7 / 38
20.
머신러닝이 좋을 때
그렇지만수학적으로 잘 정의되지 않는 문제들도 풀어야 할 때가 있습니다.
예를 들면:
다음 중 방울이 아닌 이미지를 찾아보시오
방울이 뭔데요?
배경은 무시해야 하나요?
배경이 뭔데요?
. . .
Yun (AWS) SE Challenges March 16th, 2017 7 / 38
21.
머신러닝이 좋을 때
하지만예제들을 모으는 것은 어렵지 않은 경우들이 있습니다. 이런 경우에
머신러닝이 유용합니다.
Yun (AWS) SE Challenges March 16th, 2017 8 / 38
22.
머신러닝이 좋을 때
사람이잘 하는 일들
• 이미지에서 물체를 인식하기
• 한 자연어를 다른 자연어로 번역하기
• 말을 알아듣고 글로 옮기기
• 바둑 두기...?
• . . .
특별히 사람이 잘 하는 것은 아닌 일들
• 웹사이트 광고를 클릭할지 예측하기
• 내일의 주식 가격을 예측하기
• 결제 시스템 이용자가 사기꾼인지 판단하기
• . . .
Yun (AWS) SE Challenges March 16th, 2017 9 / 38
23.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
24.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
25.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
26.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
27.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
28.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
29.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
30.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
31.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
32.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
33.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
34.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
35.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
36.
머신러닝은 소프트웨어 엔지니어링의적!
머신러닝 알고리즘은 다른 소프트웨어 모듈들에게 약한 계약(weak contract)
만을 제공함
• 학습 데이터와 아주 다른 데이터를 가져오면 성능이 형편없을 수 있음
• ’아주 다른’게 무엇인지도 명확하게 정의되지 않음
• 시스템이 커지고 머신러닝 component가 늘어날수록 복잡도가 급증
CACE: Change Anything Changes Everything (Sculley et al, 2014)
• 입력이 조금이라도 달라지면 성능을 보장할 수 없으니 upstream data flow
전체를 주시해야 함.
• 예1: 이미지를 32x32로 rescale하는 알고리즘을 A에서 B로 바꾸면?
• 예2: 뉴스 사이트에서 사용자가 최근 일주일동안 읽은 뉴스들의 단어 카운트를
이용해 광고를 보여주는데, 단어 카운트를 계산하는 방법이 바뀌었다면? 단어
카운트 계산을 publish하는 팀이 우리가 그 데이터를 쓰고 있는지 몰랐다면?
그 외에도 여러가지로 소프트웨어 엔지니어링을 골치아프게 만듬
• 모든 시스템을 하나로 뭉치길 원함
예: dialog system: speech recognition → intent classification → understanding
→ response
• GPU 같은 특수한 리소스를 사용함, CPU 쓸 때도 꼭 native library 사용
• 비슷한 기능들이 다양한 라이브러리에 흩어져 구현되어 있음, 통합이 안 됨
• 스크립트 언어를 선호하고 자꾸 쓰다 버릴 코드를 짬
Yun (AWS) SE Challenges March 16th, 2017 10 / 38
37.
서로를 이해하려는 노력이필요
Two big challenges in machine learning (by Leon Bottou)
Machine Learning: The High-Interest Credit Card of Technical Debt (by
Sculley et al, 2014)
Yun (AWS) SE Challenges March 16th, 2017 11 / 38
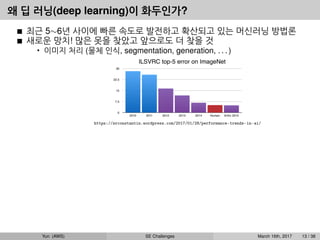
왜 딥 러닝(deeplearning)이 화두인가?
최근 5∼6년 사이에 빠른 속도로 발전하고 확산되고 있는 머신러닝 방법론
Yun (AWS) SE Challenges March 16th, 2017 13 / 38
40.
왜 딥 러닝(deeplearning)이 화두인가?
최근 5∼6년 사이에 빠른 속도로 발전하고 확산되고 있는 머신러닝 방법론
새로운 망치! 많은 못을 찾았고 앞으로도 더 찾을 것
Yun (AWS) SE Challenges March 16th, 2017 13 / 38
41.
왜 딥 러닝(deeplearning)이 화두인가?
최근 5∼6년 사이에 빠른 속도로 발전하고 확산되고 있는 머신러닝 방법론
새로운 망치! 많은 못을 찾았고 앞으로도 더 찾을 것
• 이미지 처리 (물체 인식, segmentation, generation, . . . )
https://srconstantin.wordpress.com/2017/01/28/performance-trends-in-ai/
Yun (AWS) SE Challenges March 16th, 2017 13 / 38
42.
왜 딥 러닝(deeplearning)이 화두인가?
최근 5∼6년 사이에 빠른 속도로 발전하고 확산되고 있는 머신러닝 방법론
새로운 망치! 많은 못을 찾았고 앞으로도 더 찾을 것
• 이미지 처리 (물체 인식, segmentation, generation, . . . )
https://srconstantin.wordpress.com/2017/01/28/performance-trends-in-ai/
• 음성 (speech recognition, natural language understanding, speech
synthesis, . . . )
Yun (AWS) SE Challenges March 16th, 2017 13 / 38
43.
왜 딥 러닝(deeplearning)이 화두인가?
최근 5∼6년 사이에 빠른 속도로 발전하고 확산되고 있는 머신러닝 방법론
새로운 망치! 많은 못을 찾았고 앞으로도 더 찾을 것
• 이미지 처리 (물체 인식, segmentation, generation, . . . )
https://srconstantin.wordpress.com/2017/01/28/performance-trends-in-ai/
• 음성 (speech recognition, natural language understanding, speech
synthesis, . . . )
• 번역, 게임 인공지능
Yun (AWS) SE Challenges March 16th, 2017 13 / 38
44.
Why Deep Learning,from Systems Perspective
Refer to Alex’s Quora answer: (link)
Today’s computing environment:
Disks are getting bigger. We can record pretty much everything we want.
Memory is comparably scarce. (you can still buy computers with 2GB like
it’s the 90s)
CPUs aren’t scaling as much as they used to but there’s a mass market
of computer gamers pushing GPUs forward (for $500 you can now buy a
5TFLOPS card)
(Yun: Network bandwidth also relatively low, <= 20Gbps)
Therefore: Do computationally very expensive stuff which aligns well with
GPUs within in a machine.
Yun (AWS) SE Challenges March 16th, 2017 14 / 38
45.
Running Example
How shallwe build a system that tells apples from oranges?
Yun (AWS) SE Challenges March 16th, 2017 15 / 38
46.
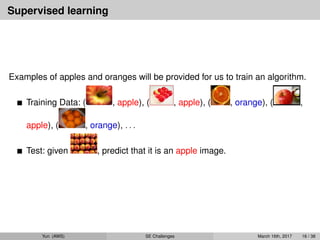
Supervised learning
Examples ofapples and oranges will be provided for us to train an algorithm.
Training Data: ( , apple), ( , apple), ( , orange), ( ,
apple), ( , orange), . . .
Test: given , predict that it is an apple image.
Yun (AWS) SE Challenges March 16th, 2017 16 / 38
47.
Image Data
Each imageis naturally described by three matrices
representing intensity of RGB colors (0∼255).
For example, if we undersampled the above image as 8 × 8, each color
channel would look like:
Yun (AWS) SE Challenges March 16th, 2017 17 / 38
48.
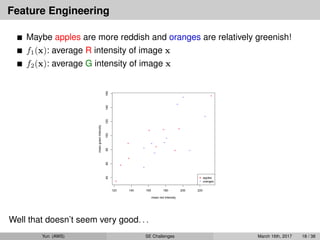
Feature Engineering
Maybe applesare more reddish and oranges are relatively greenish!
f1(x): average R intensity of image x
f2(x): average G intensity of image x
+
+
+
+
+
+
+
+
+
+
−
−
−
−
−
−
−
−
−
−
120 140 160 180 200 220
406080100120140160
mean red intensity
meangreenintensity
o
−
apples
oranges
Well that doesn’t seem very good. . .
Yun (AWS) SE Challenges March 16th, 2017 18 / 38
49.
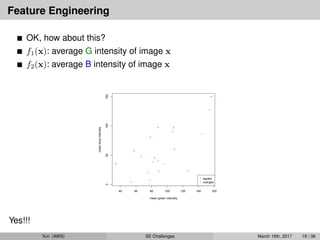
Feature Engineering
OK, howabout this?
f1(x): average G intensity of image x
f2(x): average B intensity of image x
+
+
+
+
+ +
+
+
+
+
−
−
−
−
−
−
−
−
−
−
40 60 80 100 120 140 160
050100150
mean green intensity
meanblueintensity
+
−
apples
oranges
Yes!!!
Yun (AWS) SE Challenges March 16th, 2017 19 / 38
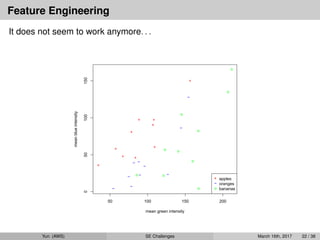
Feature Engineering
It doesnot seem to work anymore. . .
+
+
+
+
+ +
+
+
+
+
−
−
−
−
−
−
−
−
−
−
o
o
o
o
o
o
o
oo
o
50 100 150 200
050100150
mean green intensity
meanblueintensity
+
−
o
apples
oranges
bananas
Yun (AWS) SE Challenges March 16th, 2017 22 / 38
53.
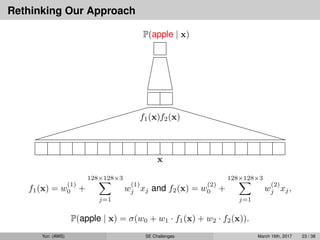
Rethinking Our Approach
x
f1(x)f2(x)
P(apple| x)
f1(x) = w
(1)
0 +
128×128×3
j=1
w
(1)
j xj and f2(x) = w
(2)
0 +
128×128×3
j=1
w
(2)
j xj,
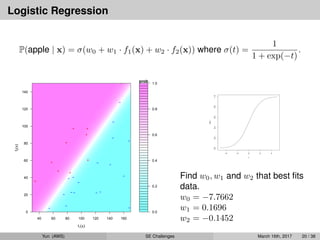
P(apple | x) = σ(w0 + w1 · f1(x) + w2 · f2(x)).
Yun (AWS) SE Challenges March 16th, 2017 23 / 38
54.
Representation Learning
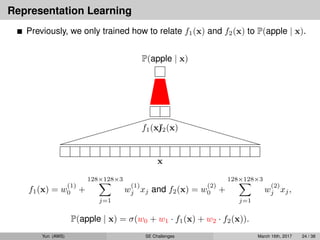
Previously, weonly trained how to relate f1(x) and f2(x) to P(apple | x).
x
P(apple | x)
f1(x)f2(x)
f1(x) = w
(1)
0 +
128×128×3
j=1
w
(1)
j xj and f2(x) = w
(2)
0 +
128×128×3
j=1
w
(2)
j xj,
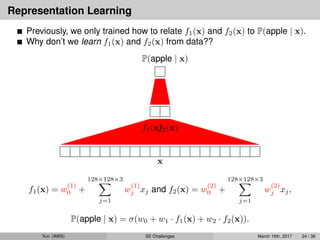
P(apple | x) = σ(w0 + w1 · f1(x) + w2 · f2(x)).
Yun (AWS) SE Challenges March 16th, 2017 24 / 38
55.
Representation Learning
Previously, weonly trained how to relate f1(x) and f2(x) to P(apple | x).
Why don’t we learn f1(x) and f2(x) from data??
x
P(apple | x)
f1(x)f2(x)
f1(x) = w
(1)
0 +
128×128×3
j=1
w
(1)
j xj and f2(x) = w
(2)
0 +
128×128×3
j=1
w
(2)
j xj,
P(apple | x) = σ(w0 + w1 · f1(x) + w2 · f2(x)).
Yun (AWS) SE Challenges March 16th, 2017 24 / 38
56.
Reducing the gapto between the toy example and the
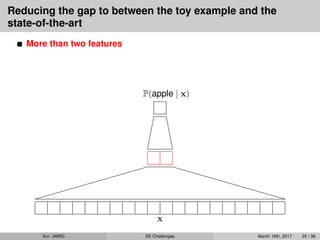
state-of-the-art
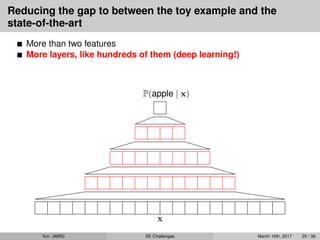
More than two features
x
P(apple | x)
Yun (AWS) SE Challenges March 16th, 2017 25 / 38
57.
Reducing the gapto between the toy example and the
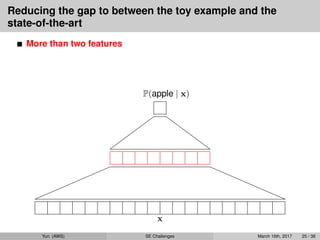
state-of-the-art
More than two features
x
P(apple | x)
Yun (AWS) SE Challenges March 16th, 2017 25 / 38
58.
Reducing the gapto between the toy example and the
state-of-the-art
More than two features
More layers, like hundreds of them (deep learning!)
x
P(apple | x)
Yun (AWS) SE Challenges March 16th, 2017 25 / 38
59.
Reducing the gapto between the toy example and the
state-of-the-art
More than two features
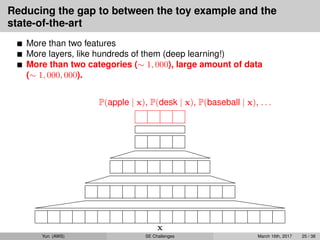
More layers, like hundreds of them (deep learning!)
More than two categories (∼ 1, 000), large amount of data
(∼ 1, 000, 000).
x
P(apple | x), P(desk | x), P(baseball | x), . . .
Yun (AWS) SE Challenges March 16th, 2017 25 / 38
60.
Reducing the gapto between the toy example and the
state-of-the-art
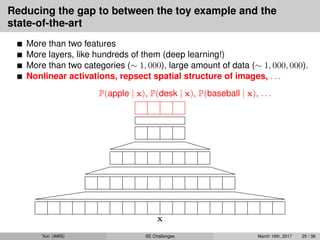
More than two features
More layers, like hundreds of them (deep learning!)
More than two categories (∼ 1, 000), large amount of data (∼ 1, 000, 000).
Nonlinear activations, repsect spatial structure of images, . . .
x
P(apple | x), P(desk | x), P(baseball | x), . . .
Yun (AWS) SE Challenges March 16th, 2017 25 / 38
61.
ImageNet Large ScaleVisual Recognition Challenge in 2012
1.2 million training images, 1000 categories
Krizhevsky et al (NIPS 2012) achieved 15.3% Top 5 error rate with deep
representation learning
In comparison, other teams achieved 26.2%, 26.9%, 27.1%, 29.6%
based on traditional feature engineering methods (SIFT, Fisher Vector,
. . .)
Yun (AWS) SE Challenges March 16th, 2017 26 / 38
Software Engineering Requirement
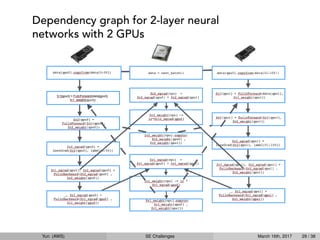
State-of-the-artnetworks have tens to hundreds of layers
Need an interface for economically expressing the computation graph
Need to exploit opportunities for parallelization
Yun (AWS) SE Challenges March 16th, 2017 28 / 38
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
66.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
67.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
68.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
69.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
70.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
71.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
72.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
73.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
74.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
75.
구세주
딥러닝을 쉽게 만들어주는소프트웨어들이 딥러닝의 대중화에 엄청난 공헌
Backend는 CUDA kernel이나 MKL 이용해 C++로 작성
Frontend는 Python, R, Lua, Julia 등 다양
주요 소프트웨어들
• Torch/PyTorch (유서 깊은 머신러닝 라이브러리, now supported by Facebook)
• theano (from U of Montreal, 2010년부터 이미 강력한 GPU 지원)
• MXnet (now in Apache incubator, supported by AWS)
• TensorFlow (supported by Google)
• Caffe (supported by Facebook?)
• CNTK (by Microsoft)
• Keras (by Google?)
Yun (AWS) SE Challenges March 16th, 2017 30 / 38
76.
Imperative Programs
import numpyas np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
# d = [ 3. 3. 3. 3. 3. 3. 3. 3. 3. 3.]
Pros
Straightforward and flexible
Can use language native features (loop, condition, debugger, . . .)
Cons
Hard to optimize
Yun (AWS) SE Challenges March 16th, 2017 31 / 38
77.
Imperative Programs
import numpyas np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
while True:
d = c + 1
print(d)
if d[0] > 10:
break
Pros
Straightforward and flexible
Can use language native features (loop, condition, debugger, . . .)
Cons
Hard to optimize
Yun (AWS) SE Challenges March 16th, 2017 32 / 38
78.
Declarative Programs
A =mx.symbol.Variable('A')
B = mx.symbol.Variable('B')
C = B * A
D = C + 1
a = mx.nd.ones(10)
b = mx.nd.ones(10) * 2
executor = D.bind(ctx=mx.cpu(), args={'A':a, 'B': b})
executor.forward()
Pros
More chances for optimization
Can be made language-independent
Cons
Less flexible (ex: you cannot do while True: and if d[0] > 10: break)
Yun (AWS) SE Challenges March 16th, 2017 33 / 38
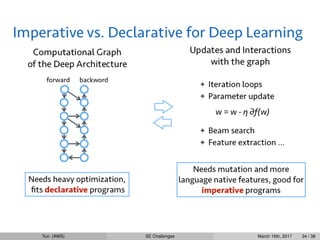
MXNet supports mixedstyle
executor = neuralnetwork.bind()
args = executor.arg_dict
grads = executor.grad_dict
for i in range(3):
train_iter.reset()
for dbatch in train_iter:
args["data"][:] = dbatch.data[0]
args["softmax_label"][:] = dbatch.label[0]
executor.forward(is_train=True)
executor.backward()
for key in update_keys:
args[key] -= learning_rate * grads[key]
Yun (AWS) SE Challenges March 16th, 2017 35 / 38
81.
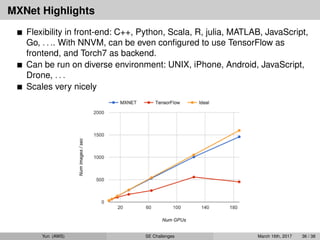
MXNet Highlights
Flexibility infront-end: C++, Python, Scala, R, julia, MATLAB, JavaScript,
Go, . . .. With NNVM, can be even configured to use TensorFlow as
frontend, and Torch7 as backend.
Can be run on diverse environment: UNIX, iPhone, Android, JavaScript,
Drone, . . .
Scales very nicely
Yun (AWS) SE Challenges March 16th, 2017 36 / 38
82.
Future Directions
딥러닝 라이브러리들이점점 컴파일러화 되어가고 있음.
• computation graph를 분석해 해당 하드웨어에 최적화 (kernel fusion 등)
• 다양한 하드웨어를 지원해야 함 (PC, iPhone, embedded device, . . . )
• dynamic computation graph
최적화된 하드웨어들이 등장하기 시작함 (Google’s Tensor Processing Unit,
Nervana, . . . )
여전히 소프트웨어 엔지니어링이 기여할 부분이 많음
Yun (AWS) SE Challenges March 16th, 2017 37 / 38










![프로그래밍이 좋을 때
수학적으로 잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-12-320.jpg)
![프로그래밍이 좋을 때
수학적으로 잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-13-320.jpg)
![프로그래밍이 좋을 때
수학적으로 잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-14-320.jpg)
![프로그래밍이 좋을 때
수학적으로 잘 정의된 문제를 풀 때는 프로그래밍이 좋습니다.
def bubblesort(input_list):
for i in range(len(input_list)):
for j in range(len(input_list) - 1, i, -1):
if input_list[j] < input_list[j - 1]:
swap(input_list, j, j - 1)
모든 입력에 대해
분석 가능한 시간 내에
정확한 답을 반환한다 (randomized algorithm들도 있긴 하지만...)
Yun (AWS) SE Challenges March 16th, 2017 6 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-15-320.jpg)









































![Imperative Programs
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
# d = [ 3. 3. 3. 3. 3. 3. 3. 3. 3. 3.]
Pros
Straightforward and flexible
Can use language native features (loop, condition, debugger, . . .)
Cons
Hard to optimize
Yun (AWS) SE Challenges March 16th, 2017 31 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-76-320.jpg)
![Imperative Programs
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
while True:
d = c + 1
print(d)
if d[0] > 10:
break
Pros
Straightforward and flexible
Can use language native features (loop, condition, debugger, . . .)
Cons
Hard to optimize
Yun (AWS) SE Challenges March 16th, 2017 32 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-77-320.jpg)
![Declarative Programs
A = mx.symbol.Variable('A')
B = mx.symbol.Variable('B')
C = B * A
D = C + 1
a = mx.nd.ones(10)
b = mx.nd.ones(10) * 2
executor = D.bind(ctx=mx.cpu(), args={'A':a, 'B': b})
executor.forward()
Pros
More chances for optimization
Can be made language-independent
Cons
Less flexible (ex: you cannot do while True: and if d[0] > 10: break)
Yun (AWS) SE Challenges March 16th, 2017 33 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-78-320.jpg)
![MXNet supports mixed style
executor = neuralnetwork.bind()
args = executor.arg_dict
grads = executor.grad_dict
for i in range(3):
train_iter.reset()
for dbatch in train_iter:
args["data"][:] = dbatch.data[0]
args["softmax_label"][:] = dbatch.label[0]
executor.forward(is_train=True)
executor.backward()
for key in update_keys:
args[key] -= learning_rate * grads[key]
Yun (AWS) SE Challenges March 16th, 2017 35 / 38](https://image.slidesharecdn.com/hyokunyoon-170404043939/85/slide-80-320.jpg)



















![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)







![[독서광] 모던 소프트웨어 엔지니어링 - 소프트웨어 개발의 복잡함과 난해함 속에서 길을 찾으려는 엔지니어를 위한...](https://cdn.slidesharecdn.com/ss_thumbnails/20254-250408132937-ef889d44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[워크숍] Get to know AI, Meet your new teammate!](https://cdn.slidesharecdn.com/ss_thumbnails/gettoknowaimeetyournewteammate-241209073551-a677c30c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[강연] 학생에서 현업 개발자로의 성공적인 변신을 위하여](https://cdn.slidesharecdn.com/ss_thumbnails/random-130329101221-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=640&height=640&fit=bounds)




![[OKdevTV] 2024년 8월 21일 개발 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/2024821-240821223438-6cdf5cf2-thumbnail.jpg?width=640&height=640&fit=bounds)
