시작하기전…
• 빙/MS 제품중심으로 머신러닝 예제를 설명하고자 합니다.
(제가 다른 회사 내용은 몰라서 그러는거 맞습니다)
• 실제 제품은 훨~씬 더 복잡하지만, 우리는 간단한 개념만 알아볼게요.
• 제가 잘못 알고 있거나, 모르는 부분도 많습니다. 제 의견은 회사의 입장과는 무관합니다 ;)
• 질문 및 피드백은 아무때나 해주세요.
문서 검색 속머신러닝
• 우선 우리는 웹 인덱스가 있다고 가정합니다.
• 질의에 대해서 후보 문서들을 준비합니다. (1차 검색 혹은 Fetch)
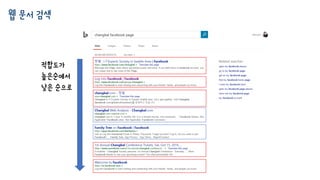
질의 = changbal facebook page
후보1 = www.facebook.com/changbal
후보2 = www.changbal.com
등등
• 사람(!)에게 후보 문서가 얼마나 적합한지 물어봅니다.
후보1 = 100점, 후보2 = 90점 등등
• {x=(질의, 후보1), y=100점}와 같은 데이터를 가지고 새로운 y=f(x)를 예측하는
모델을 학습합니다. 머신러닝에서 이것을 “회귀 Regression”이라고 부릅니다.
질의 응답 속머신러닝
• 질의 응답 ~ 백과사전 찾기
• 백과사전의 어떤 카테고리 (인물, 지명, 스포츠 등등)를 봐야 하는지가 첫번째로 풀 문제
• 검색과 마찬가지로 질의 데이터를 준비합니다. 그리고 또 사람에게 물어봐야겠죠.
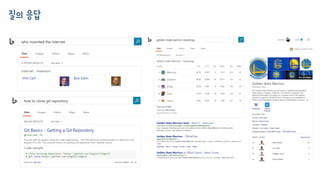
x=who invented the internet, y=인물
x=golden state warriors, y=스포츠
등등
• 학습 데이터를 가지고 y=f(x) 모델을 만들고, 새로운 질의에 대해서 카테고리를 예측해
냅니다. 이를 머신러닝에서 “분류 Classification”라고 부릅니다.
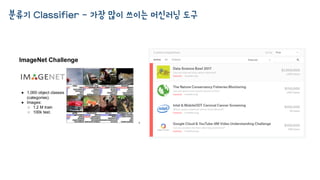
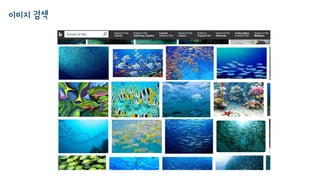
이미지 검색 속머신러닝
• 문서 검색과 마찬가지로 랭킹 방법을 이용하면 될 것 같습니다.
• 그런데, 이미지 인덱스는 어떻게 만들까요?
문서와는 다르게 텍스트가 있을수도 없을 수도 있구요
하이퍼링크도 없습니다
• 가장 기본적인 인덱스는 다음과 같이 만듭니다. (실제로는 다단계 인덱스)
모든 이미지를 수집합니다.
비슷한 이미지들을 모아서 같은 “번호”를 부여해 둡니다.
• 머신러닝에서는 이렇게 레이블이 없는 경우를 “군집화 Clustering”라고 부릅니다.
(더 일반적으로는 Unsupervised Learning)
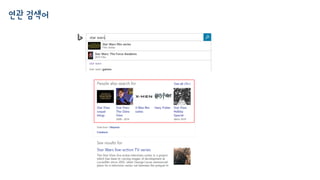
연관 검색어 속머신러닝
• 어떻게 내가 입력하지도 않은 검색어를 추천해 줄 수 있는거죠?
• 검색엔진은 다행이(?) 모든 유저들이 입력한 질의를 기억하고 있습니다.
물론 익명화되어 있으니 걱정하지 마세요.
브라우저가 열렸다가 닫힐때까지 혹은 검색엔진에서 머무르는 최대 30분을 세션이라고 합니다.
한 세션에서 입력된 모든 질의 그리고 클릭된 문서를 살핍니다.
(질의1 -> 클릭A, 질의2 -> 클릭A, 질의3 -> 클릭B 등등) => 질의1, 질의2 는 연관되어 있다!
몇가지 트릭: wiki나 imdb와 같은 문서(url)로 제한, #클릭 > 5000
• (조금 간소화 되었지만) 머신러닝에서는 “협력 필터링 Collaborative
Filtering”이라고 합니다.
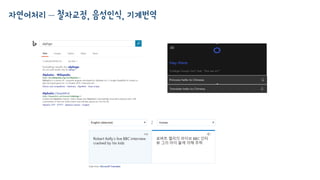
자연어처리 속 머신러닝
•우리가 하는 말 (자연어)는 단어 혹은 음성 신호의 연속으로 나타납니다.
• 많은 경우 자연어처리는 연속된 입력 (문자, 단어, 음성신호)를 다른 연속된 출력으로
생성해 냅니다.
입력된 철자 -> 교정된 철자
영어 문장 -> 한국어 문장
음성 신호 -> 텍스트 문장
단어 열 (문장) -> 문법 구조 트리
• 머신러닝에서는 이러한 문제를 “시계열 데이터 Sequential data”라고 합니다.
• 최근 딥러닝에서는 seq2seq가 대유행!
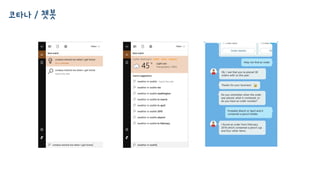
코타나 / 챗봇속 머신러닝
• 로봇이 사람과 어떻게 대화를 할까요? (정답: 아직 대화할 수 없습니다)
• 코타나나 알렉사와 같은 비서형 로봇만 생각해 볼게요.
• Ver0.1 로봇을 만들고 대화를 시도합니다.
시작 -> 주인 -> 로봇 -> 주인 -> 로봇 -> 주인 (고마워) -> 끝
시작 -> 주인 -> 로봇 -> 주인 (그게 아니야) -> 끝 그리고 다시 처음으로
• 대화 도중에는 로봇은 잘 모르지만, 마지막에는 주인님을 행복한지 아닌지 알게 됩니다.
(게임과 비슷하다고 생각하시면 됩니다. 마지막에 You Win/Lose?)
• 머신러닝에서는 이렇게 피드백을 통해 학습하는 방법을 “강화 학습 Reinforcement
Learning”이라고 합니다.
(지극히 주관적이고 개인적인)머신러닝 응용에 관한 팁
• 80:20 룰 (80%는 데이터 수집/정제, 20%는 실제 머신러닝 적용)
대부분의 경우 데이터가 품질을 좌우. 슈퍼 팬시 딥러닝 알고리즘은 마지막에.
• 사람의 손을 거쳐야 하는 데이터 -> 크라우드 소싱, 나머지는 최대한 자동화
에러를 줄이기 위해 가능하면 쉬운 태스크 (4지선다 vs 주관식)
• 규칙기반 + 머신러닝을 함께 사용
머신러닝은 비싸다. 오래 걸린다. Live Site에 대응하기 위해서 플랜B를 만들자
• 데이터/모델 파이프라인을 동료들에게 공유하자
코드와 달리 모든 데이터/파이프라인을 Git에서 관리할 순 없다. (특히 실험은)
실험 플랫폼 (예 Azure/Amazon ML)을 적극 활용해서 결과를 공유. 재현성!
21.
머신러닝이 개발과 조직에미치는 영향
• 머신러닝은 데이터로 시작해서 데이터로 끝맺음
-> 데이터가 자산 -> 데이터 중심 의사결정
• 대부분의 시스템이 모델과 로직(코드)을 분리
-> 유닛테스트를 통한 코드 무결성 검증이 어려움 -> A/B Test 가 더 중요해짐
• 많은 머신러닝 툴이 오픈소스
-> 탈 윈도우
• 서비스 개발에 머신러닝 지식이 필요 -> 새로운 직군 -> 일자리 창출
-> 머신러닝 개발자/과학자의 몸값이 치솟고 있음
-> 그런데 왜 내 몸값은 그대로죠 -_-
























![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)
















