Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Haesun Park
850 views
4.convolutional neural networks
Convolution Neural Networks
Software
◦
Related topics:
Deep Learning
•
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 105 times
1
/ 49
2
/ 49
3
/ 49
4
/ 49
5
/ 49
6
/ 49
7
/ 49
8
/ 49
9
/ 49
10
/ 49
11
/ 49
12
/ 49
13
/ 49
14
/ 49
15
/ 49
16
/ 49
17
/ 49
18
/ 49
19
/ 49
20
/ 49
21
/ 49
22
/ 49
23
/ 49
24
/ 49
25
/ 49
26
/ 49
27
/ 49
28
/ 49
29
/ 49
30
/ 49
31
/ 49
32
/ 49
33
/ 49
34
/ 49
35
/ 49
36
/ 49
37
/ 49
38
/ 49
39
/ 49
40
/ 49
41
/ 49
42
/ 49
43
/ 49
44
/ 49
45
/ 49
46
/ 49
47
/ 49
48
/ 49
49
/ 49
More Related Content
PDF
3.unsupervised learing
by
Haesun Park
PDF
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지
by
Haesun Park
PDF
2.supervised learning
by
Haesun Park
PDF
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류
by
Haesun Park
PPTX
2.supervised learning(epoch#2)-3
by
Haesun Park
PDF
2.linear regression and logistic regression
by
Haesun Park
PDF
5.model evaluation and improvement
by
Haesun Park
PDF
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신
by
Haesun Park
3.unsupervised learing
by
Haesun Park
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지
by
Haesun Park
2.supervised learning
by
Haesun Park
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류
by
Haesun Park
2.supervised learning(epoch#2)-3
by
Haesun Park
2.linear regression and logistic regression
by
Haesun Park
5.model evaluation and improvement
by
Haesun Park
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신
by
Haesun Park
What's hot
PDF
3.neural networks
by
Haesun Park
PPTX
4.representing data and engineering features(epoch#2)
by
Haesun Park
PDF
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련
by
Haesun Park
PDF
(Handson ml)ch.7-ensemble learning and random forest
by
Haesun Park
PDF
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝
by
Haesun Park
PDF
3.unsupervised learing(epoch#2)
by
Haesun Park
PPTX
해커에게 전해들은 머신러닝 #4
by
Haesun Park
PDF
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리
by
Haesun Park
PPTX
2.supervised learning(epoch#2)-2
by
Haesun Park
PDF
사이킷런 최신 변경 사항 스터디
by
Haesun Park
PPTX
해커에게 전해들은 머신러닝 #2
by
Haesun Park
PDF
밑바닥부터 시작하는 딥러닝_신경망학습
by
Juhui Park
PPTX
머신 러닝 입문 #1-머신러닝 소개와 kNN 소개
by
Terry Cho
PDF
6.algorithm chains and piplines(epoch#2)
by
Haesun Park
PDF
5.model evaluation and improvement(epoch#2) 2
by
Haesun Park
PDF
4.representing data and engineering features
by
Haesun Park
PDF
집단지성 프로그래밍 07-고급 분류 기법-커널 기법과 svm-01
by
Kwang Woo NAM
PDF
5.model evaluation and improvement(epoch#2) 1
by
Haesun Park
PDF
내가 이해하는 SVM(왜, 어떻게를 중심으로)
by
SANG WON PARK
PPTX
해커에게 전해들은 머신러닝 #1
by
Haesun Park
3.neural networks
by
Haesun Park
4.representing data and engineering features(epoch#2)
by
Haesun Park
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련
by
Haesun Park
(Handson ml)ch.7-ensemble learning and random forest
by
Haesun Park
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝
by
Haesun Park
3.unsupervised learing(epoch#2)
by
Haesun Park
해커에게 전해들은 머신러닝 #4
by
Haesun Park
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리
by
Haesun Park
2.supervised learning(epoch#2)-2
by
Haesun Park
사이킷런 최신 변경 사항 스터디
by
Haesun Park
해커에게 전해들은 머신러닝 #2
by
Haesun Park
밑바닥부터 시작하는 딥러닝_신경망학습
by
Juhui Park
머신 러닝 입문 #1-머신러닝 소개와 kNN 소개
by
Terry Cho
6.algorithm chains and piplines(epoch#2)
by
Haesun Park
5.model evaluation and improvement(epoch#2) 2
by
Haesun Park
4.representing data and engineering features
by
Haesun Park
집단지성 프로그래밍 07-고급 분류 기법-커널 기법과 svm-01
by
Kwang Woo NAM
5.model evaluation and improvement(epoch#2) 1
by
Haesun Park
내가 이해하는 SVM(왜, 어떻게를 중심으로)
by
SANG WON PARK
해커에게 전해들은 머신러닝 #1
by
Haesun Park
Similar to 4.convolutional neural networks
PPTX
Cnn 발표자료
by
종현 최
PDF
Dl from scratch(7)
by
Park Seong Hyeon
PPTX
텐서플로우 2.0 튜토리얼 - CNN
by
Hwanhee Kim
PDF
CNN을 이용한 MNIT dataset Classification 실습
by
Yeon Woo Jeong
PDF
[컴퓨터비전과 인공지능] 7. 합성곱 신경망 2
by
jdo
PPTX
해커에게 전해들은 머신러닝 #3
by
Haesun Park
PPTX
인공지능, 기계학습 그리고 딥러닝
by
Jinwon Lee
PDF
소프트웨어 2.0을 활용한 게임 어뷰징 검출
by
정주 김
PPTX
CNN
by
chs71
PPTX
Neural network (perceptron)
by
Jeonghun Yoon
PDF
Neural Networks Basics with PyTorch
by
Hyunwoo Kim
PPTX
Image classification
by
종현 김
PDF
[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기
by
JungHyun Hong
PDF
DL from scratch(6)
by
Park Seong Hyeon
PDF
Deep Learning from scratch 3장 : neural network
by
JinSooKim80
PPTX
Convolutional neural networks
by
HyunjinBae3
PDF
딥러닝을 위한 Tensor flow(skt academy)
by
Tae Young Lee
PDF
Deep Learning Into Advance - 1. Image, ConvNet
by
Hyojun Kim
PDF
GDG DevFest 2017 Seoul 블록과 함께하는 파이썬 딥러닝 케라스
by
Taeyoung Kim
PDF
Ai study - 2 layer feed-forward network, Backpropagation
by
DaeHeeKim31
Cnn 발표자료
by
종현 최
Dl from scratch(7)
by
Park Seong Hyeon
텐서플로우 2.0 튜토리얼 - CNN
by
Hwanhee Kim
CNN을 이용한 MNIT dataset Classification 실습
by
Yeon Woo Jeong
[컴퓨터비전과 인공지능] 7. 합성곱 신경망 2
by
jdo
해커에게 전해들은 머신러닝 #3
by
Haesun Park
인공지능, 기계학습 그리고 딥러닝
by
Jinwon Lee
소프트웨어 2.0을 활용한 게임 어뷰징 검출
by
정주 김
CNN
by
chs71
Neural network (perceptron)
by
Jeonghun Yoon
Neural Networks Basics with PyTorch
by
Hyunwoo Kim
Image classification
by
종현 김
[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기
by
JungHyun Hong
DL from scratch(6)
by
Park Seong Hyeon
Deep Learning from scratch 3장 : neural network
by
JinSooKim80
Convolutional neural networks
by
HyunjinBae3
딥러닝을 위한 Tensor flow(skt academy)
by
Tae Young Lee
Deep Learning Into Advance - 1. Image, ConvNet
by
Hyojun Kim
GDG DevFest 2017 Seoul 블록과 함께하는 파이썬 딥러닝 케라스
by
Taeyoung Kim
Ai study - 2 layer feed-forward network, Backpropagation
by
DaeHeeKim31
More from Haesun Park
PDF
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 9장 텐서플로 시작하기
by
Haesun Park
PDF
(Handson ml)ch.8-dimensionality reduction
by
Haesun Park
PDF
7.woring with text data(epoch#2)
by
Haesun Park
PPTX
2.supervised learning(epoch#2)-1
by
Haesun Park
PPTX
1.introduction(epoch#2)
by
Haesun Park
PDF
7.woring with text data
by
Haesun Park
PDF
6.algorithm chains and piplines
by
Haesun Park
PDF
1.introduction
by
Haesun Park
PDF
기계도 학교에 가나요?
by
Haesun Park
[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 9장 텐서플로 시작하기
by
Haesun Park
(Handson ml)ch.8-dimensionality reduction
by
Haesun Park
7.woring with text data(epoch#2)
by
Haesun Park
2.supervised learning(epoch#2)-1
by
Haesun Park
1.introduction(epoch#2)
by
Haesun Park
7.woring with text data
by
Haesun Park
6.algorithm chains and piplines
by
Haesun Park
1.introduction
by
Haesun Park
기계도 학교에 가나요?
by
Haesun Park
4.convolutional neural networks
1.
Convolutional Neural Networks
2.
Outlook • Part 1:
파이썬과 텐서플로우 소개 • Part 2: 회귀 분석과 로지스틱 회귀 • Part 3: 뉴럴 네트워크 알고리즘 • Part 4: 콘볼루션 뉴럴 네트워크 2
3.
지난 시간에... 3
4.
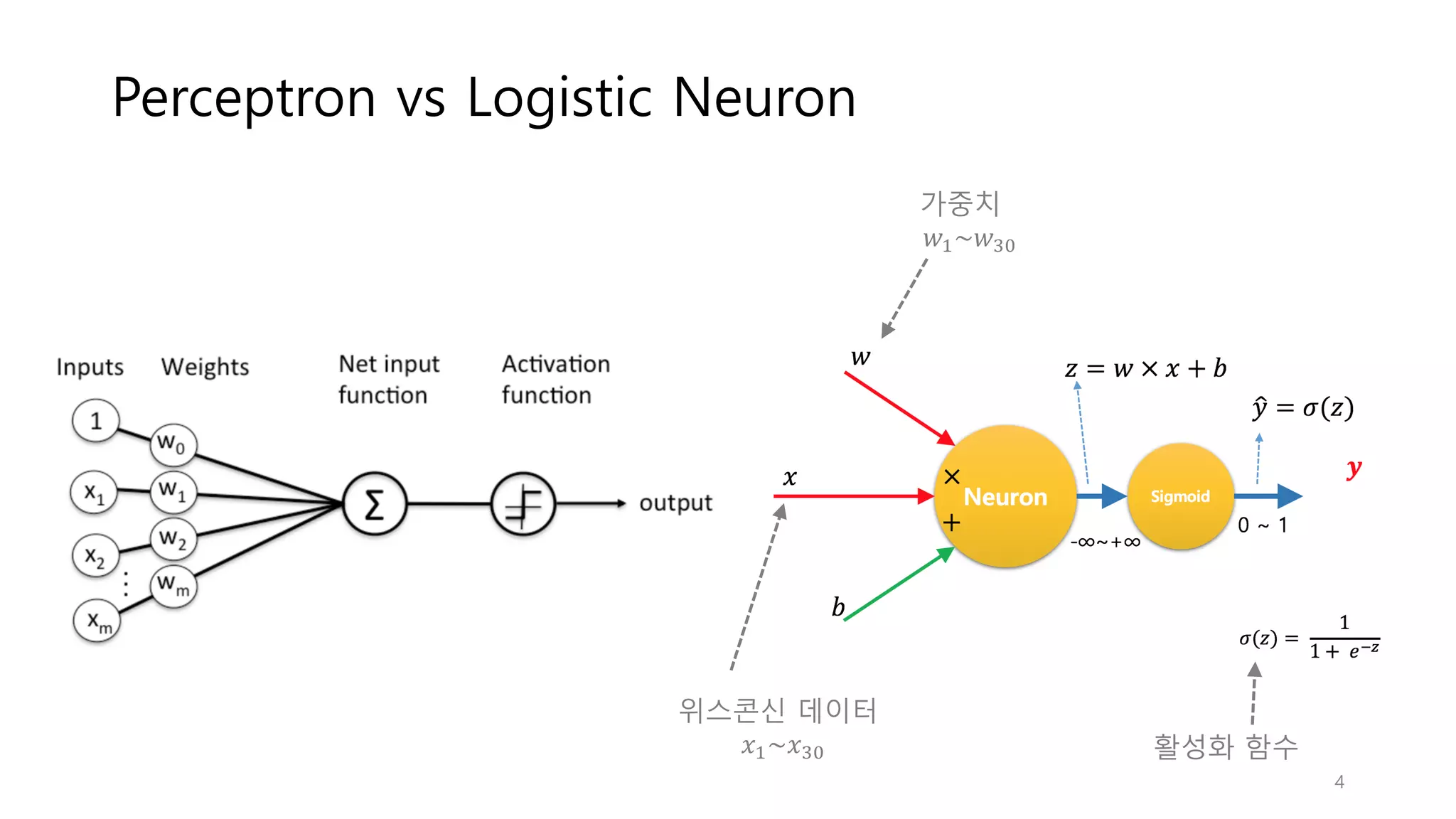
Perceptron vs Logistic
Neuron 활성화 함수 가중치 𝑤"~𝑤$% 위스콘신 데이터 𝑥"~𝑥$% 4
5.
레이어간 행렬 계산 5 𝑥" 0.6 ⋯ 𝑥$% 0.2 ⋮
⋱ ⋮ 0.5 ⋯ 0.4 ⋅ 𝑤" " ⋮ 𝑤$% " ⋱ 𝑤" "% ⋮ 𝑤$% "% = 1.5 5.9 ⋮ 0.7 ⋱ 1.1 0.2 ⋮ 0.5 + 𝑏" ⋯ 𝑏$% = 1.2 2.9 ⋮ 1.7 ⋱ 1.6 2.2 ⋮ 4.1 569 x 10 크기 569개 샘플 𝑥 × 𝑊 + 𝑏 = 𝑧 [569, 30] x [30, 10] = [569, 10] + [10] = [569, 10] 10개 편향(bias) 30개 특성 569 x 10개 결과 (logits) ... 𝑥% 𝑥" 𝑥$% 𝑏% 𝑏"% 30 x 10개 가중치
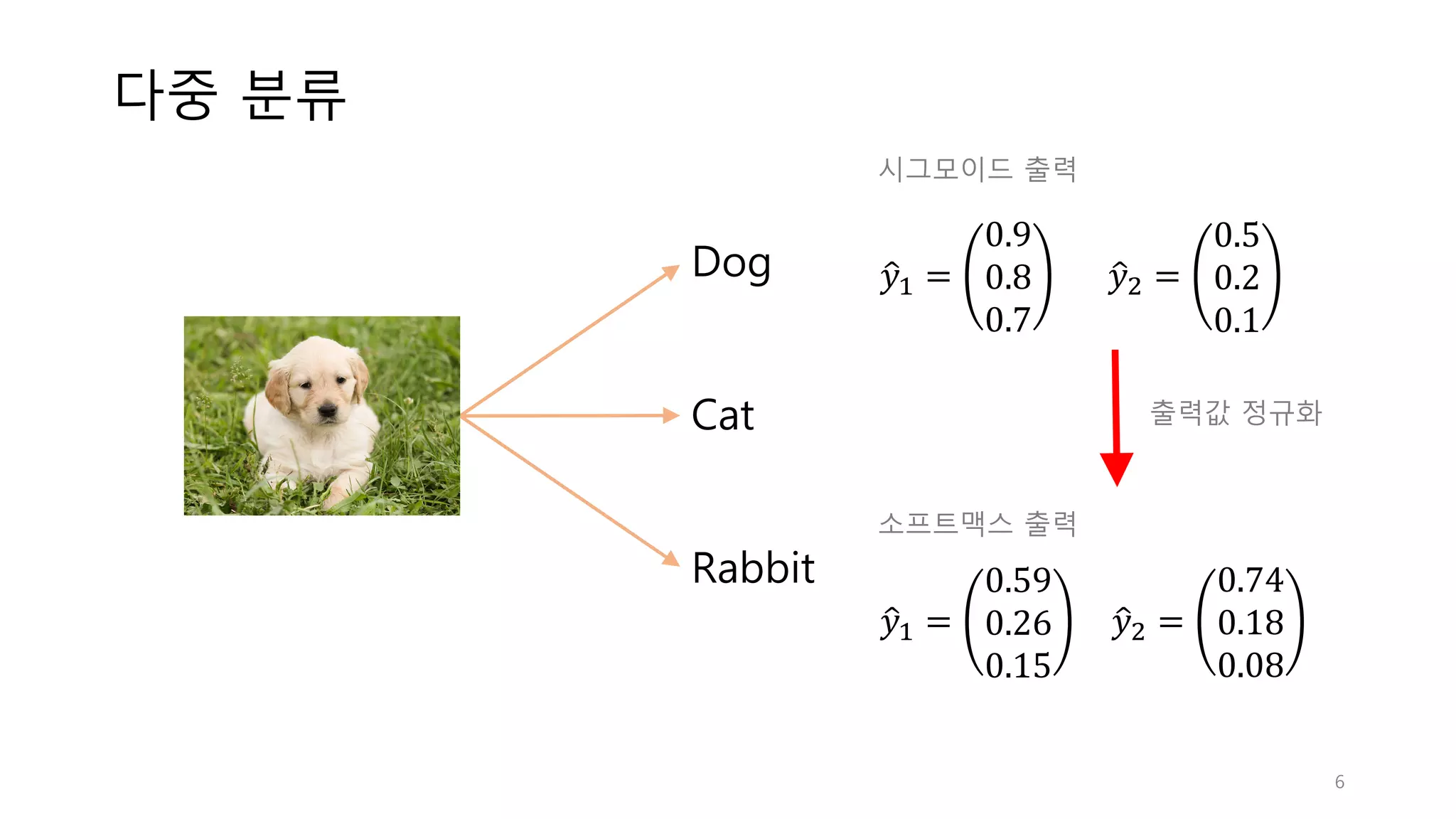
6.
다중 분류 Dog Cat Rabbit 𝑦<" = 0.9 0.8 0.7 𝑦<>
= 0.5 0.2 0.1 𝑦<" = 0.59 0.26 0.15 𝑦<> = 0.74 0.18 0.08 출력값 정규화 시그모이드 출력 소프트맥스 출력 6
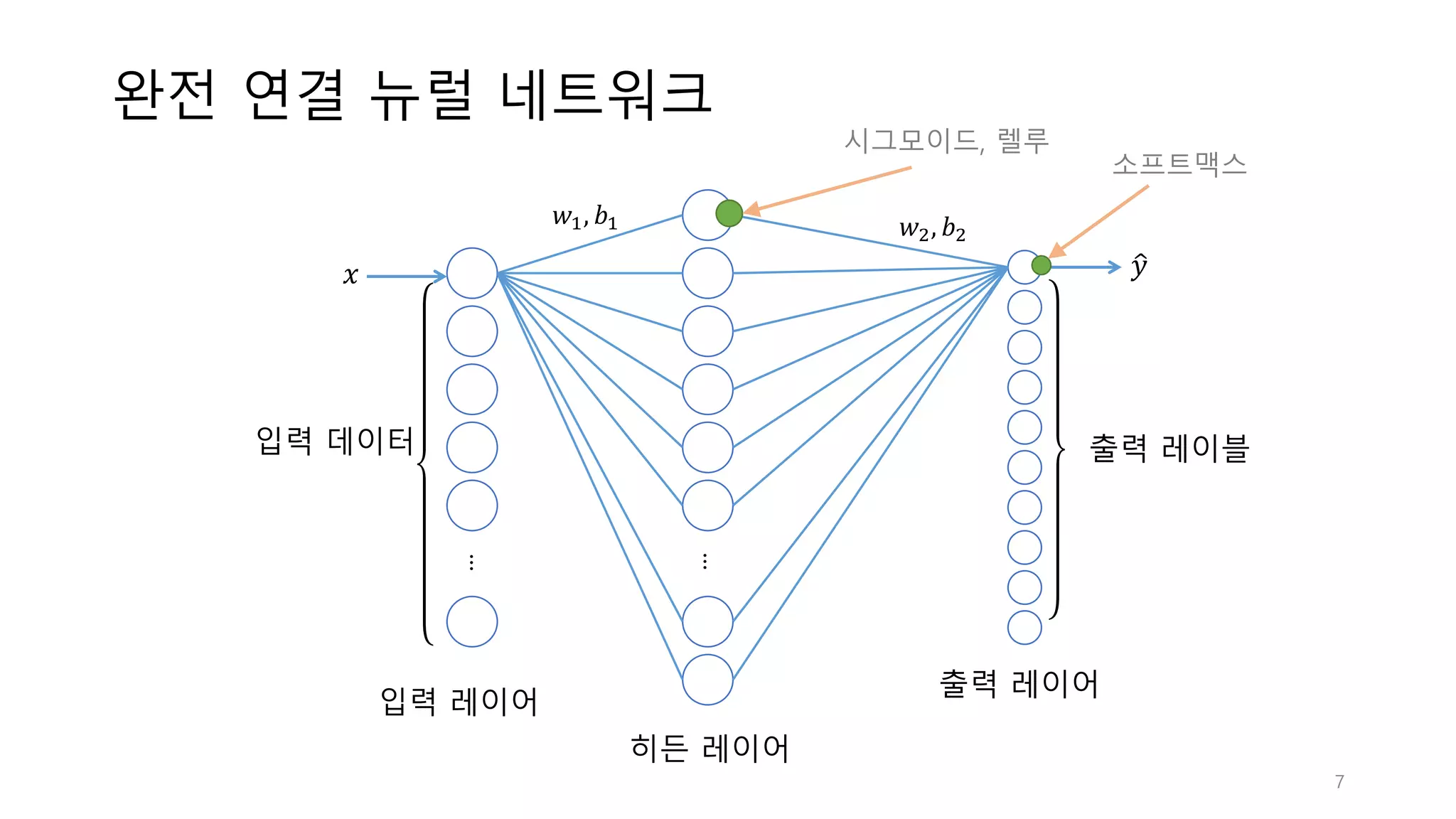
7.
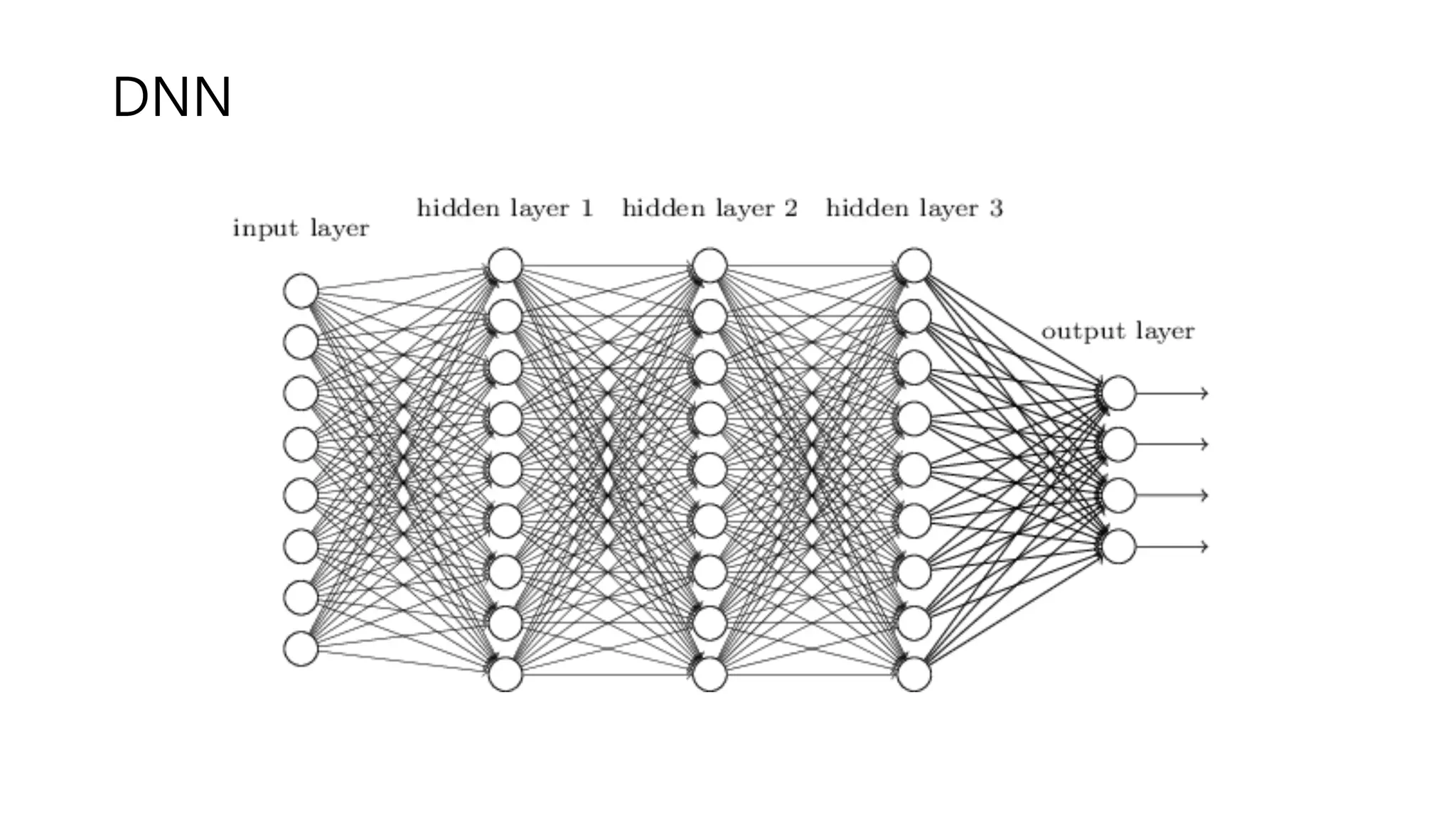
완전 연결 뉴럴
네트워크 ... ... 히든 레이어 입력 레이어 출력 레이어 입력 데이터 출력 레이블 𝑥 𝑦< 𝑤", 𝑏" 𝑤>, 𝑏> 시그모이드, 렐루 소프트맥스 7
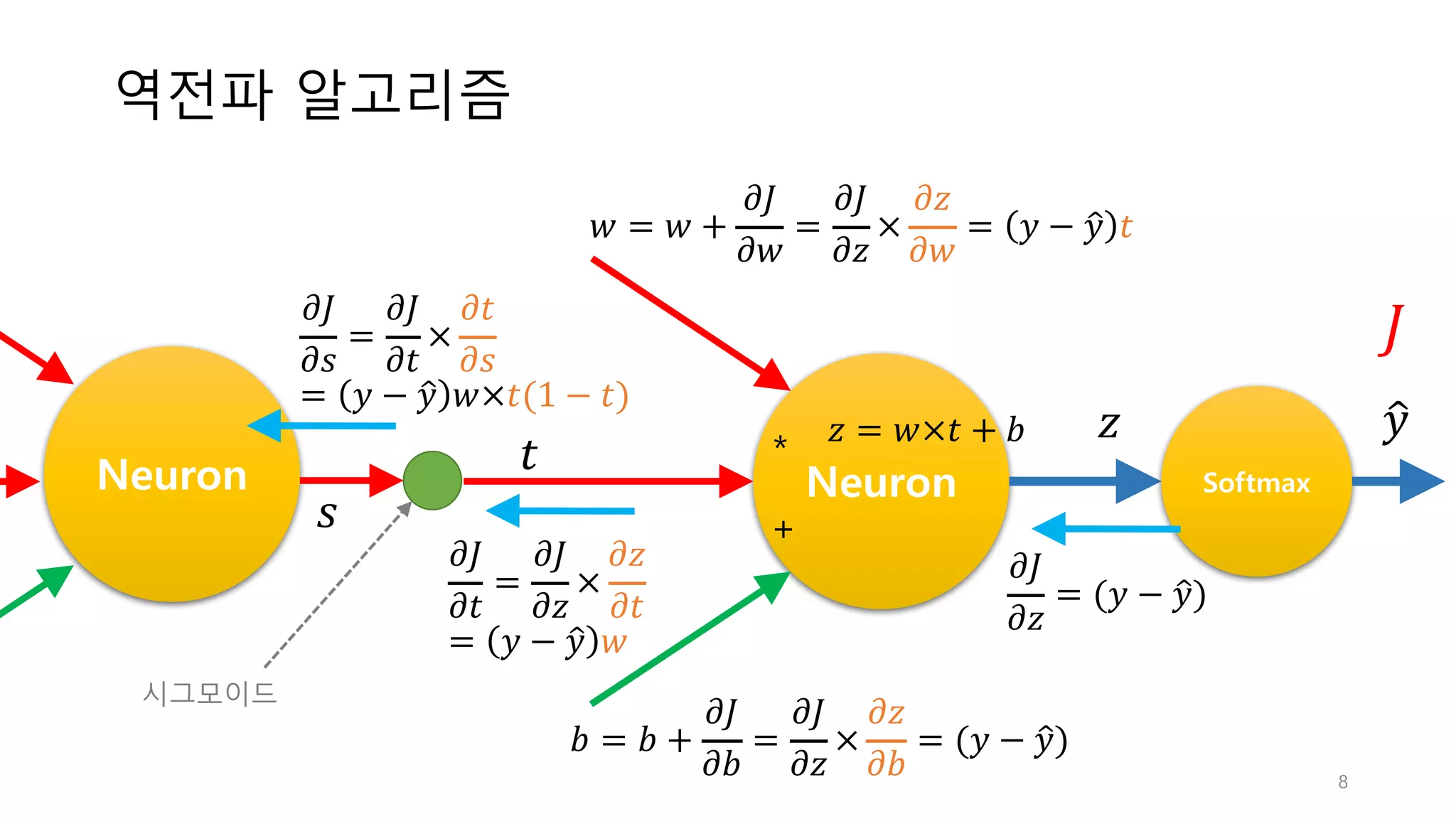
8.
역전파 알고리즘 8 Neuron * + Softmax 𝑡 𝑦< 𝜕𝐽 𝜕𝑧 = (𝑦
− 𝑦<) 𝑧 = 𝑤×𝑡 + 𝑏 𝑏 = 𝑏 + 𝜕𝐽 𝜕𝑏 = 𝜕𝐽 𝜕𝑧 × 𝜕𝑧 𝜕𝑏 = (𝑦 − 𝑦<) Neuron 𝑤 = 𝑤 + 𝜕𝐽 𝜕𝑤 = 𝜕𝐽 𝜕𝑧 × 𝜕𝑧 𝜕𝑤 = 𝑦 − 𝑦< 𝑡 𝑧 𝜕𝐽 𝜕𝑡 = 𝜕𝐽 𝜕𝑧 × 𝜕𝑧 𝜕𝑡 = 𝑦 − 𝑦< 𝑤 𝐽𝜕𝐽 𝜕𝑠 = 𝜕𝐽 𝜕𝑡 × 𝜕𝑡 𝜕𝑠 = 𝑦 − 𝑦< 𝑤×𝑡(1 − 𝑡) 𝑠 시그모이드
9.
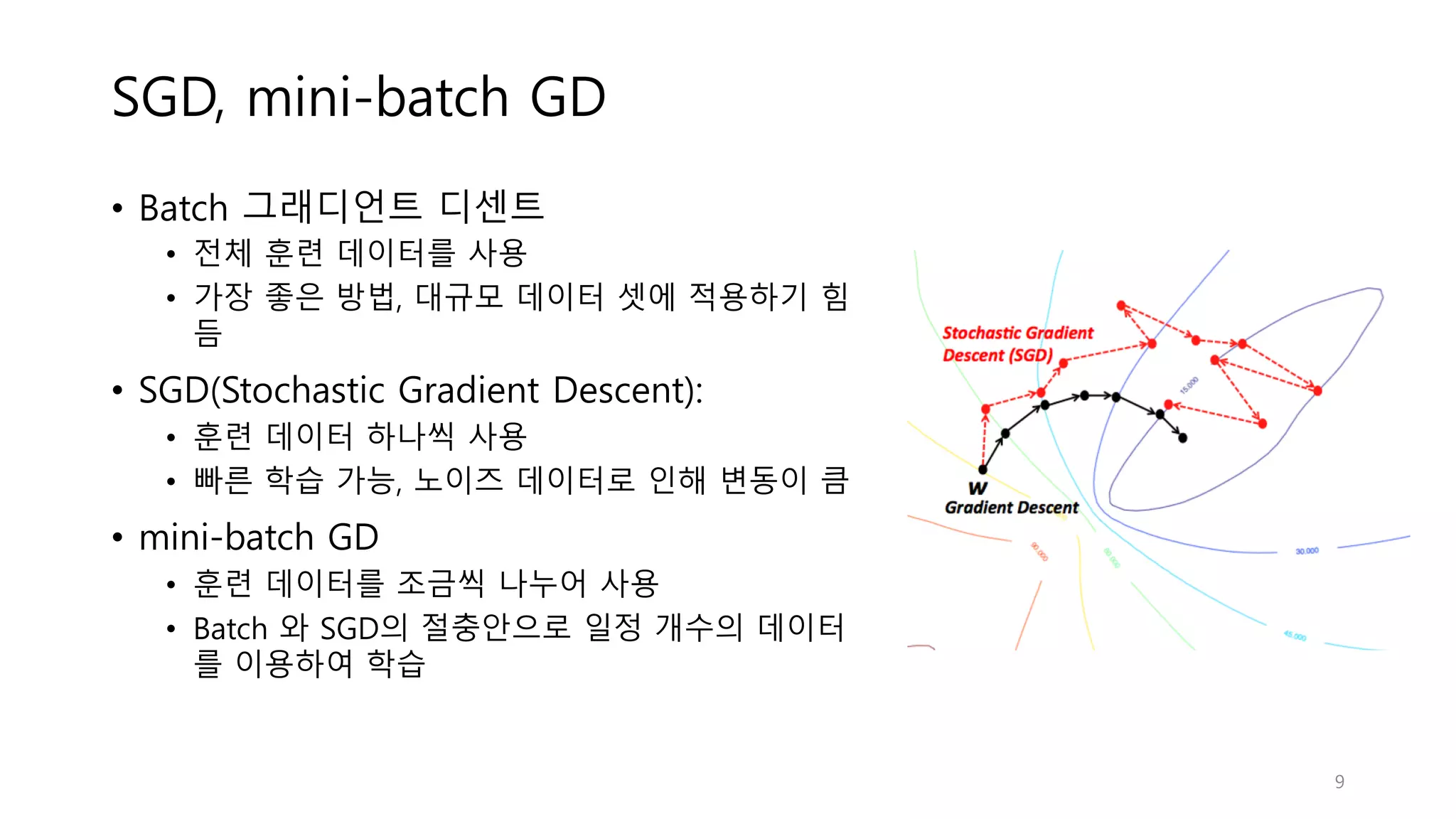
SGD, mini-batch GD •
Batch 그래디언트 디센트 • 전체 훈련 데이터를 사용 • 가장 좋은 방법, 대규모 데이터 셋에 적용하기 힘 듬 • SGD(Stochastic Gradient Descent): • 훈련 데이터 하나씩 사용 • 빠른 학습 가능, 노이즈 데이터로 인해 변동이 큼 • mini-batch GD • 훈련 데이터를 조금씩 나누어 사용 • Batch 와 SGD의 절충안으로 일정 개수의 데이터 를 이용하여 학습 9
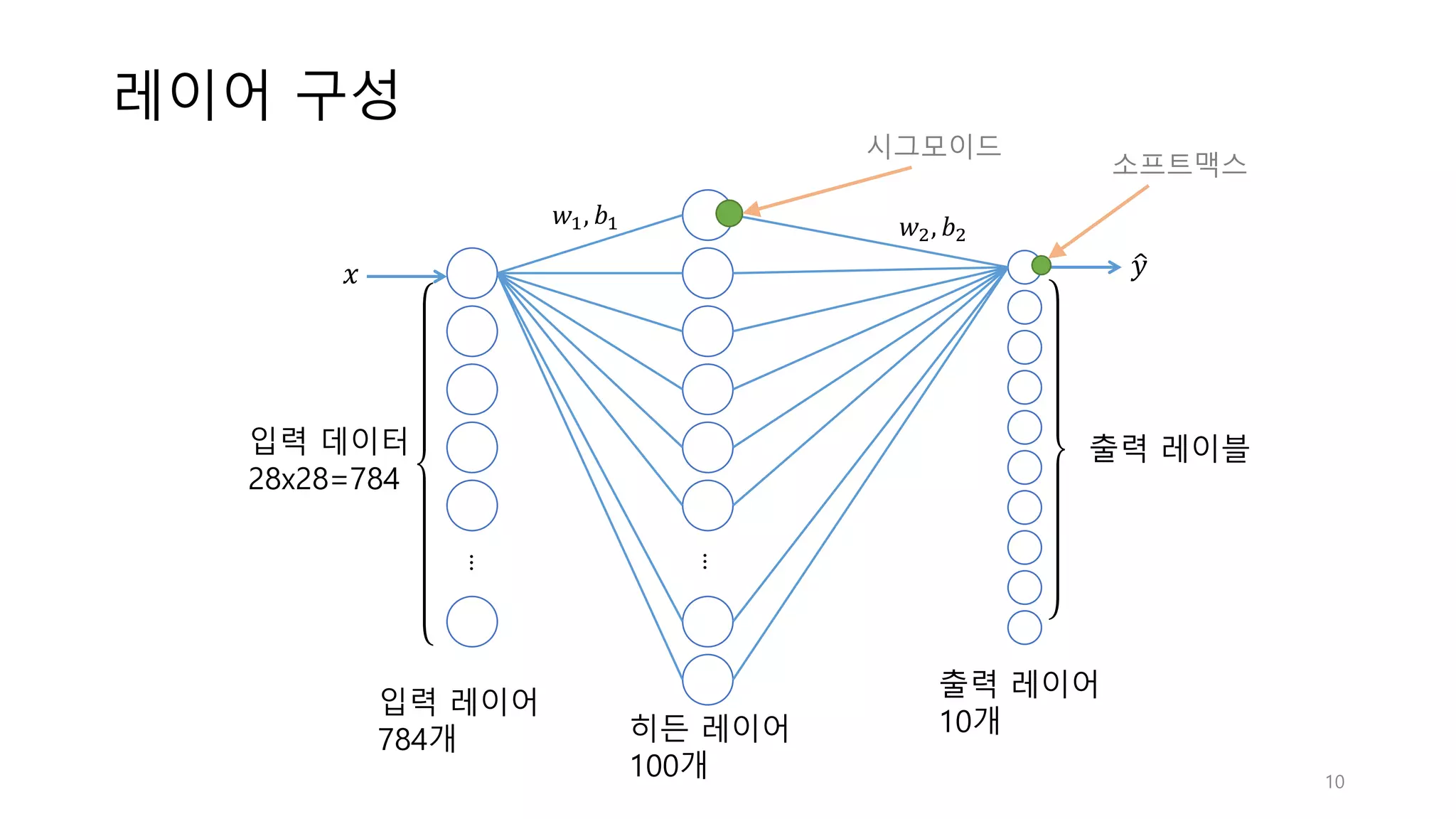
10.
레이어 구성 ... ... 히든 레이어 100개 입력
레이어 784개 출력 레이어 10개 입력 데이터 28x28=784 출력 레이블 𝑥 𝑦< 𝑤", 𝑏" 𝑤>, 𝑏> 시그모이드 소프트맥스 10
11.
뉴럴 네트워크 구현
12.
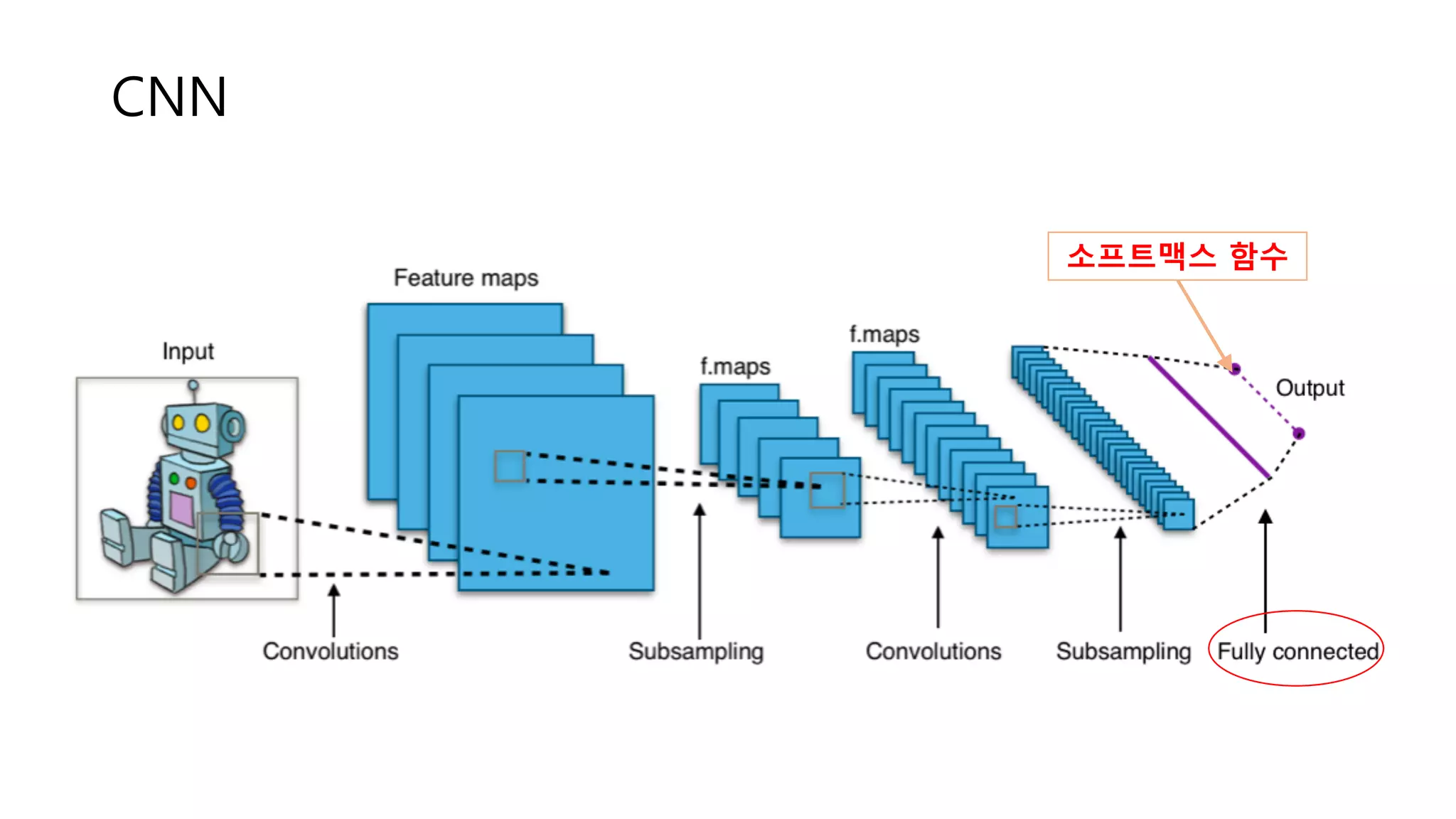
CNN
13.
Fully Connected • 이미지
픽셀을 일렬로 펼쳐서 네트워크에 주입합니다. ... 784×100 + [100] ...
14.
Convolution • 이미지의 2차원
구조를 그대로 이용합니다. • 가중치가 재활용되어 사이즈가 크게 줄어 듭니다. ... ... ... ... 3×3 + [1] ...
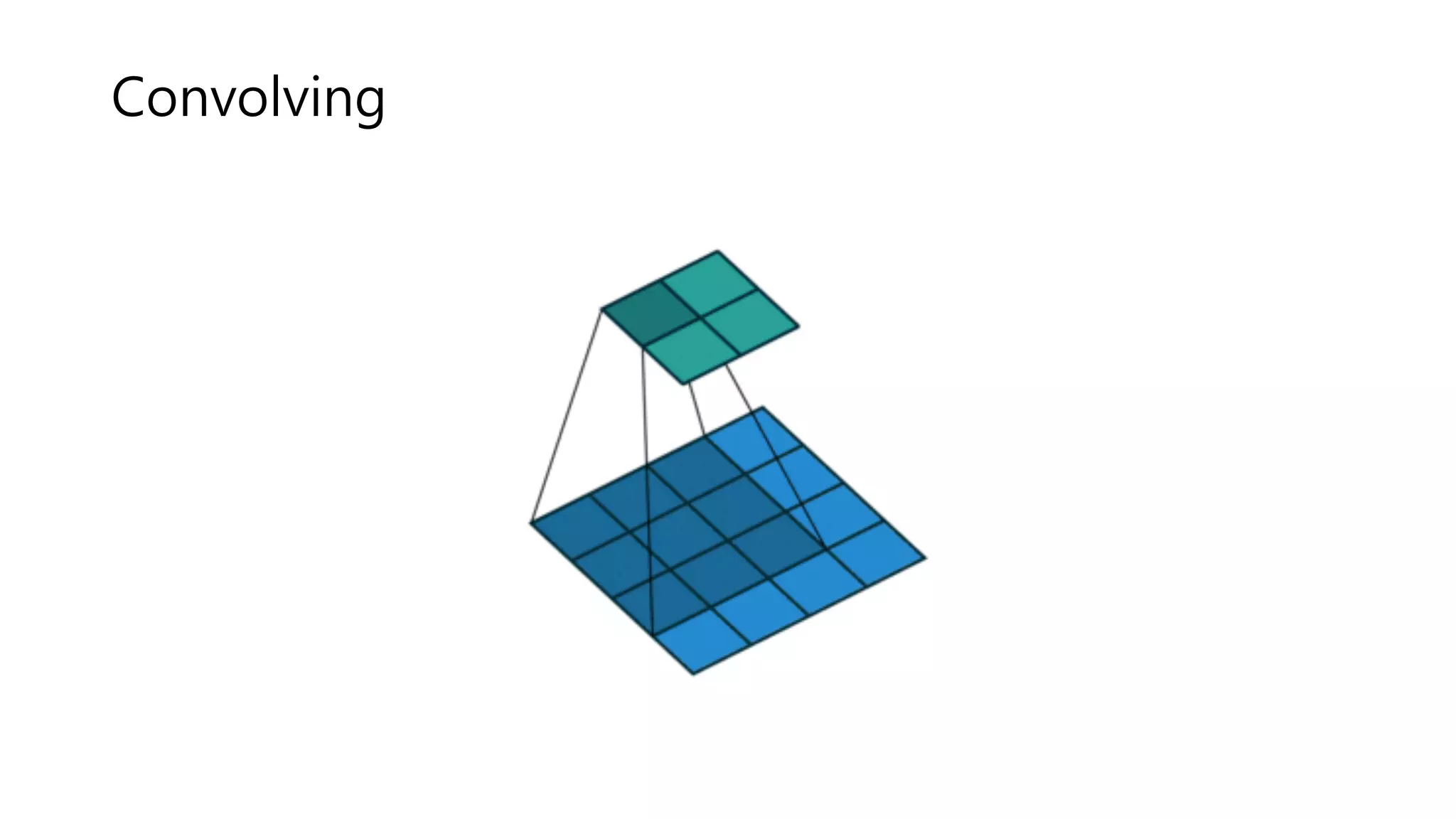
15.
Convolving
16.
Feature Map • 콘볼루션으로
만들어진 2차원 맵을 특성 맵이라고 부릅니다. • 보통 한 레이어에서 여러개의 특성 맵을 만듭니다. ... ... ... ... ⋅ 3×3 + [1] 특성 맵 (Feature Map)
17.
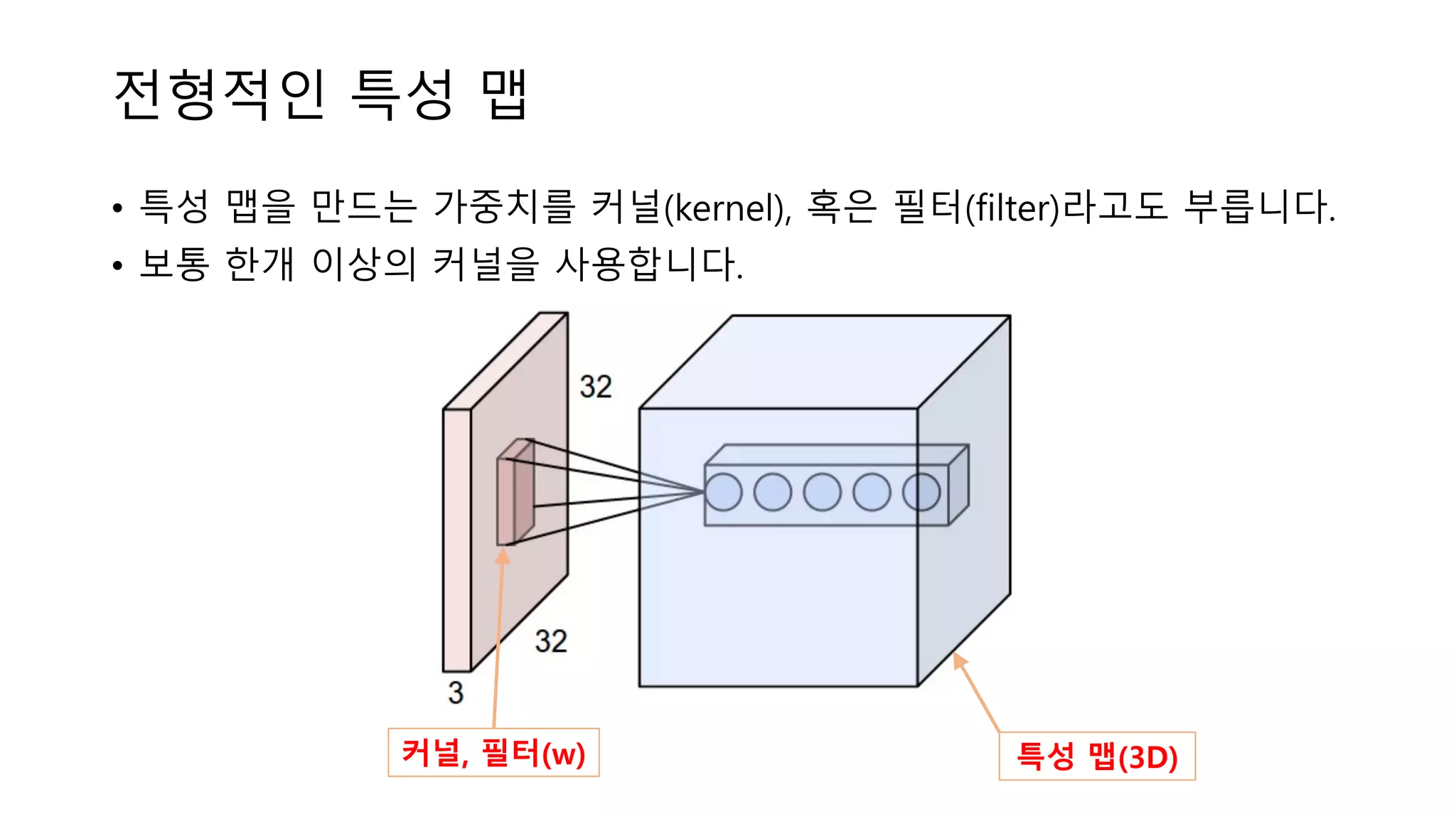
전형적인 특성 맵 •
특성 맵을 만드는 가중치를 커널(kernel), 혹은 필터(filter)라고도 부릅니다. • 보통 한개 이상의 커널을 사용합니다. 특성 맵(3D)커널, 필터(w)
18.
conv2d() • 가중치와 바이어스를
직접 생성해 전달 • tf.layers.conv2d()를 사용하면 편리함 ... ... ... ... ⋅ 3×3 + [1] W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1)) b = tf.Variable(tf.constant(0.1, shape=[10])) conv = tf.nn.conv2d(x, W) + b
19.
DNN
20.
CNN 소프트맥스 함수
21.
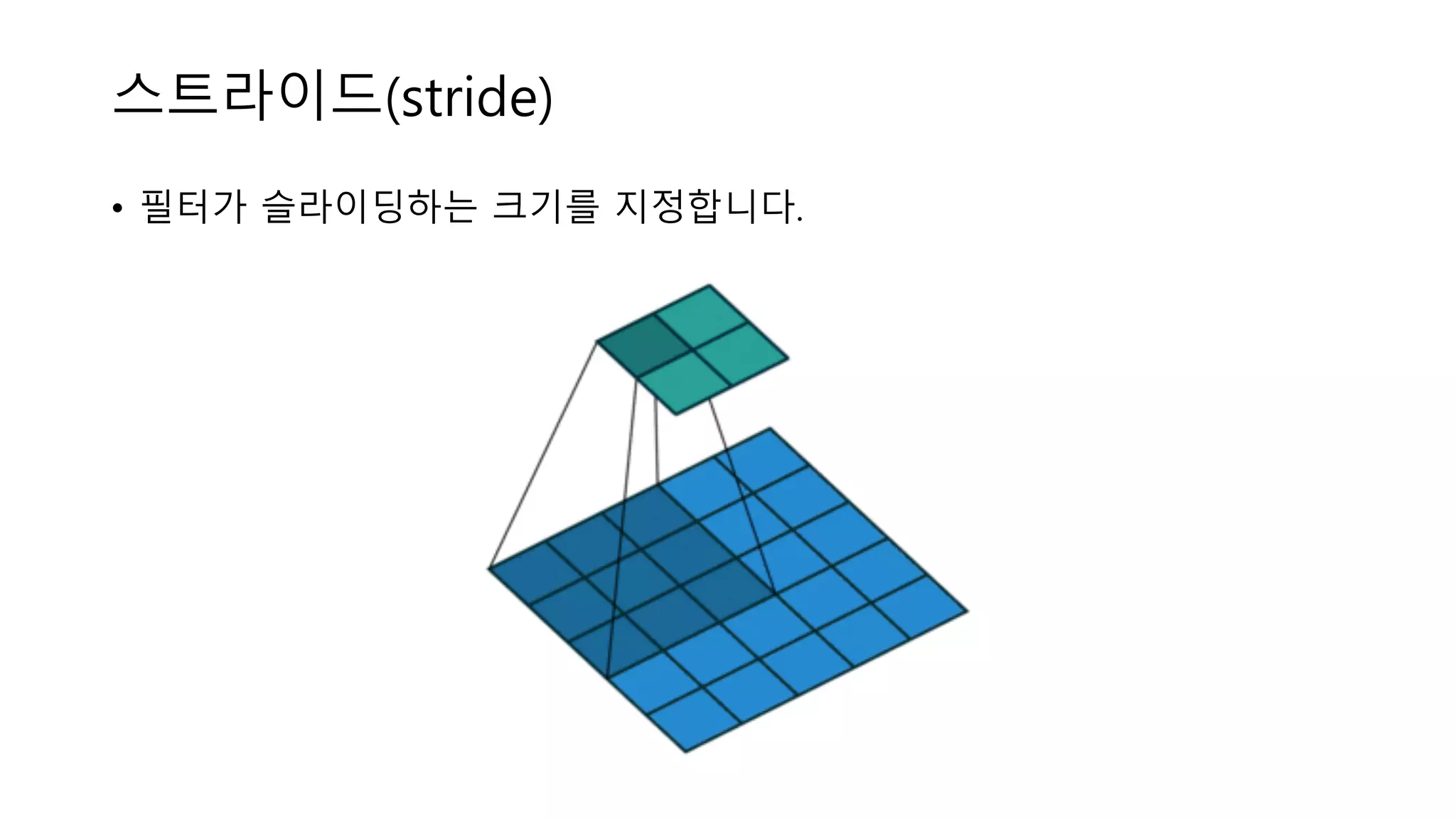
Stride, Padding
22.
스트라이드(stride) • 필터가 슬라이딩하는
크기를 지정합니다.
23.
스트라이드 계산 𝑜 = 𝑖
− 𝑓 𝑠 + 1 = 4 − 3 1 + 1 = 2 입력(i): 4x4 필터(f): 3x3 스트라이드(s): 1 W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1)) b = tf.Variable(tf.constant(0.1, shape=[10])) conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1]) + b
24.
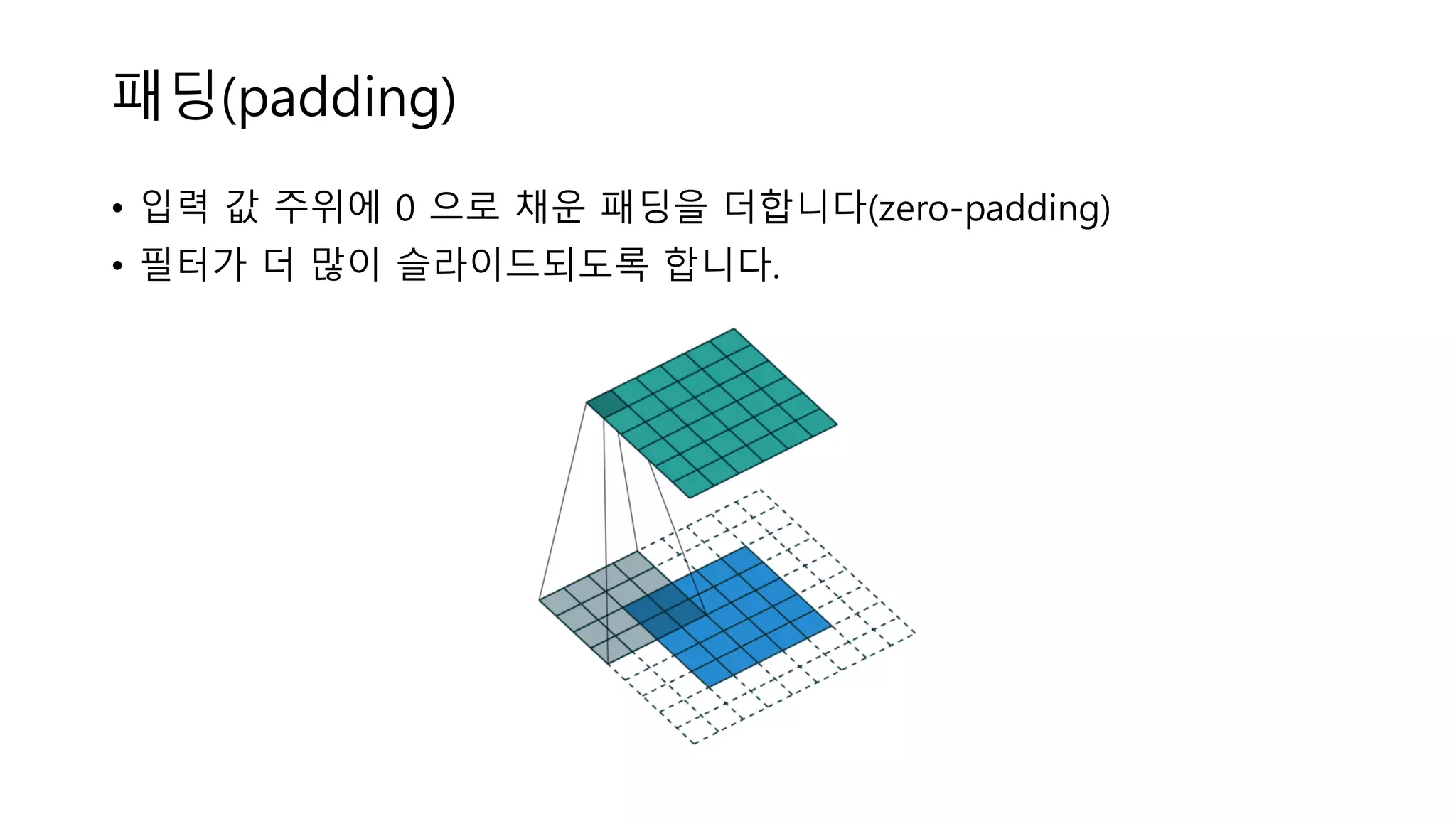
패딩(padding) • 입력 값
주위에 0 으로 채운 패딩을 더합니다(zero-padding) • 필터가 더 많이 슬라이드되도록 합니다.
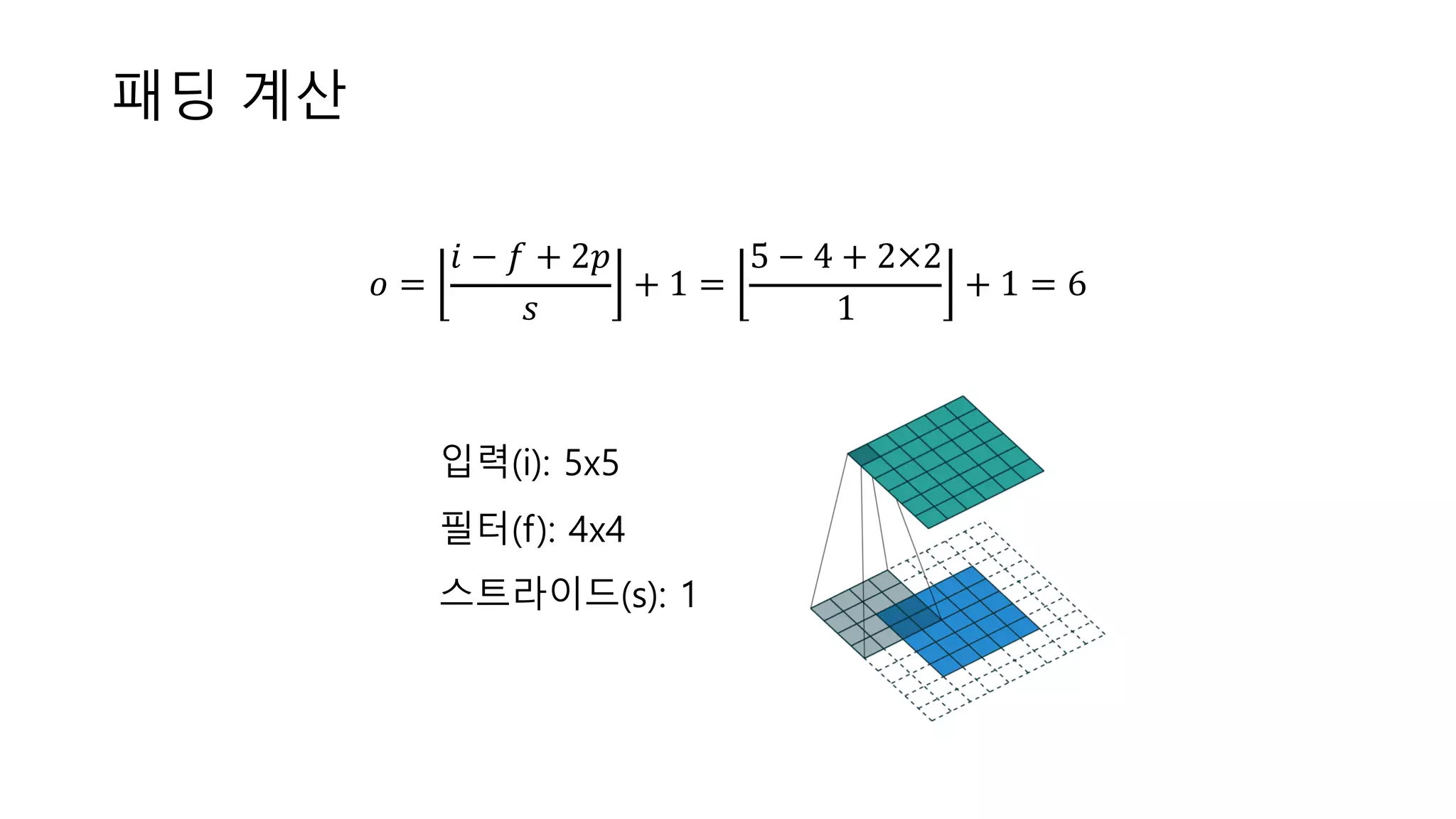
25.
패딩 계산 𝑜 = 𝑖
− 𝑓 + 2𝑝 𝑠 + 1 = 5 − 4 + 2×2 1 + 1 = 6 입력(i): 5x5 필터(f): 4x4 스트라이드(s): 1
26.
텐서플로우 패딩 계산 •
패딩크기를 직접 지정, tf.pad() • 패딩 타입(same/valid), 스트라이드 크기 à 패딩 크기 자동 결정 • same • 출력크기=입력크기/스트라이드 • tf.layer.conv2d(.., padding=‘same’, ..) • 패딩 크기가 필터의 절반 정도라 하프 패딩이라고도 부름 • valid • 패딩을 넣지 않음 • tf.layer.conv2d(.., padding=‘valid’, ..) W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1)) b = tf.Variable(tf.constant(0.1, shape=[10])) conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’) + b
27.
ReLU • Rectified Linear
Unit • -∞~+∞입력에 대해 0~+∞ 사이의 값을 출력합니다. 𝑦< = max (0, 𝑧) W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1)) b = tf.Variable(tf.constant(0.1, shape=[10])) conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’) + b acti = tf.nn.relu(conv)
28.
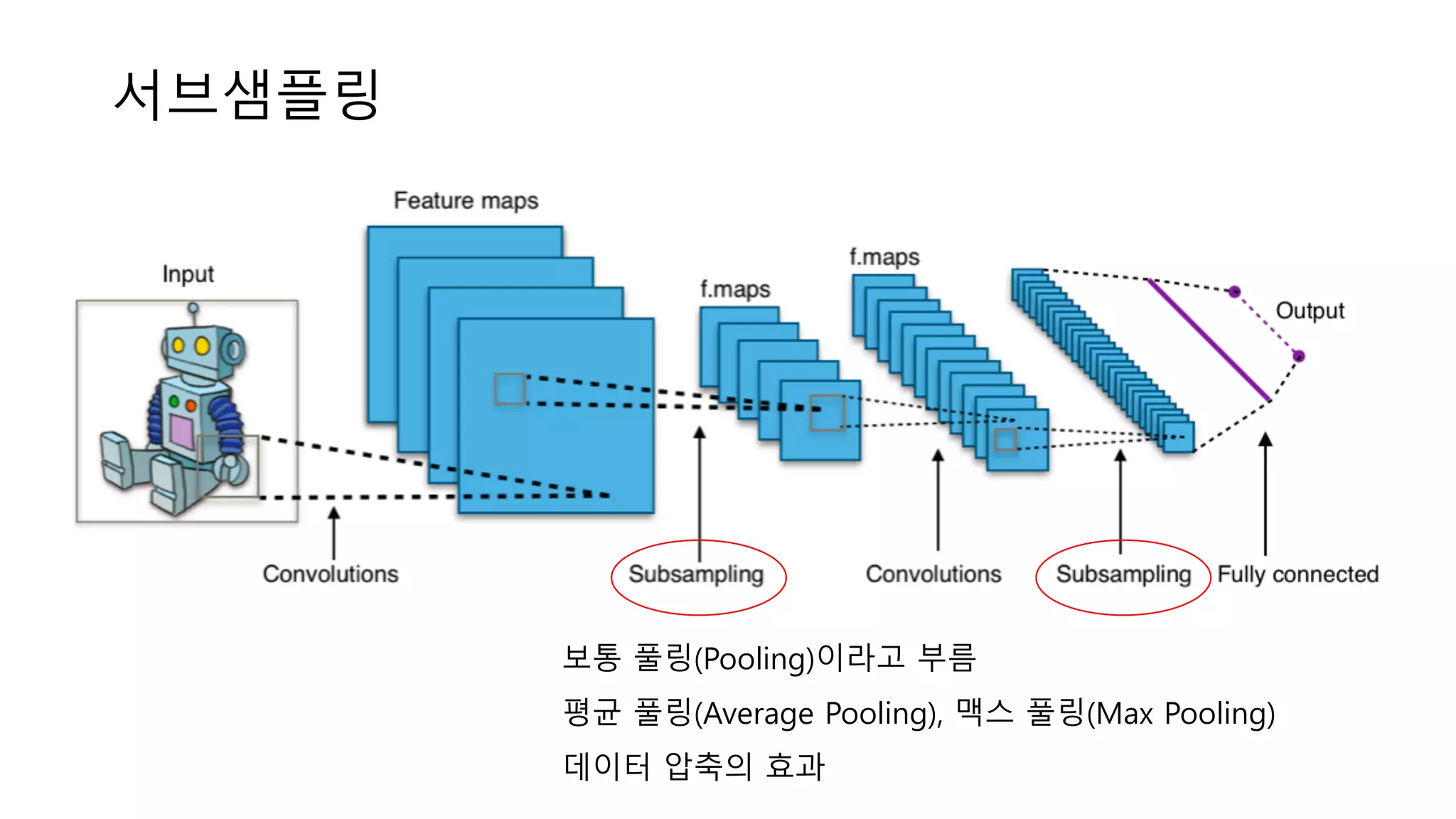
subsampling
29.
서브샘플링 보통 풀링(Pooling)이라고 부름 평균
풀링(Average Pooling), 맥스 풀링(Max Pooling) 데이터 압축의 효과
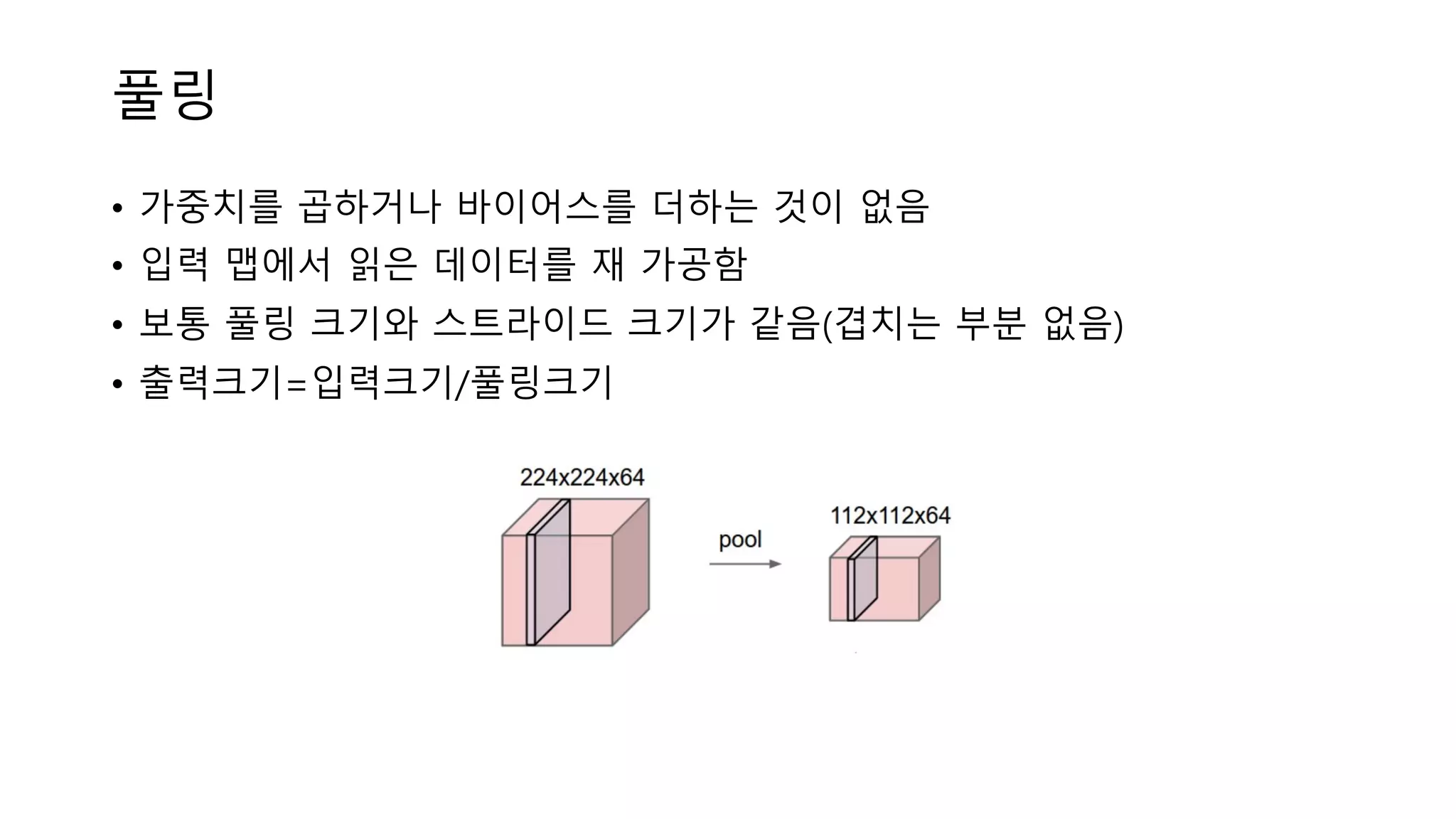
30.
풀링 • 가중치를 곱하거나
바이어스를 더하는 것이 없음 • 입력 맵에서 읽은 데이터를 재 가공함 • 보통 풀링 크기와 스트라이드 크기가 같음(겹치는 부분 없음) • 출력크기=입력크기/풀링크기
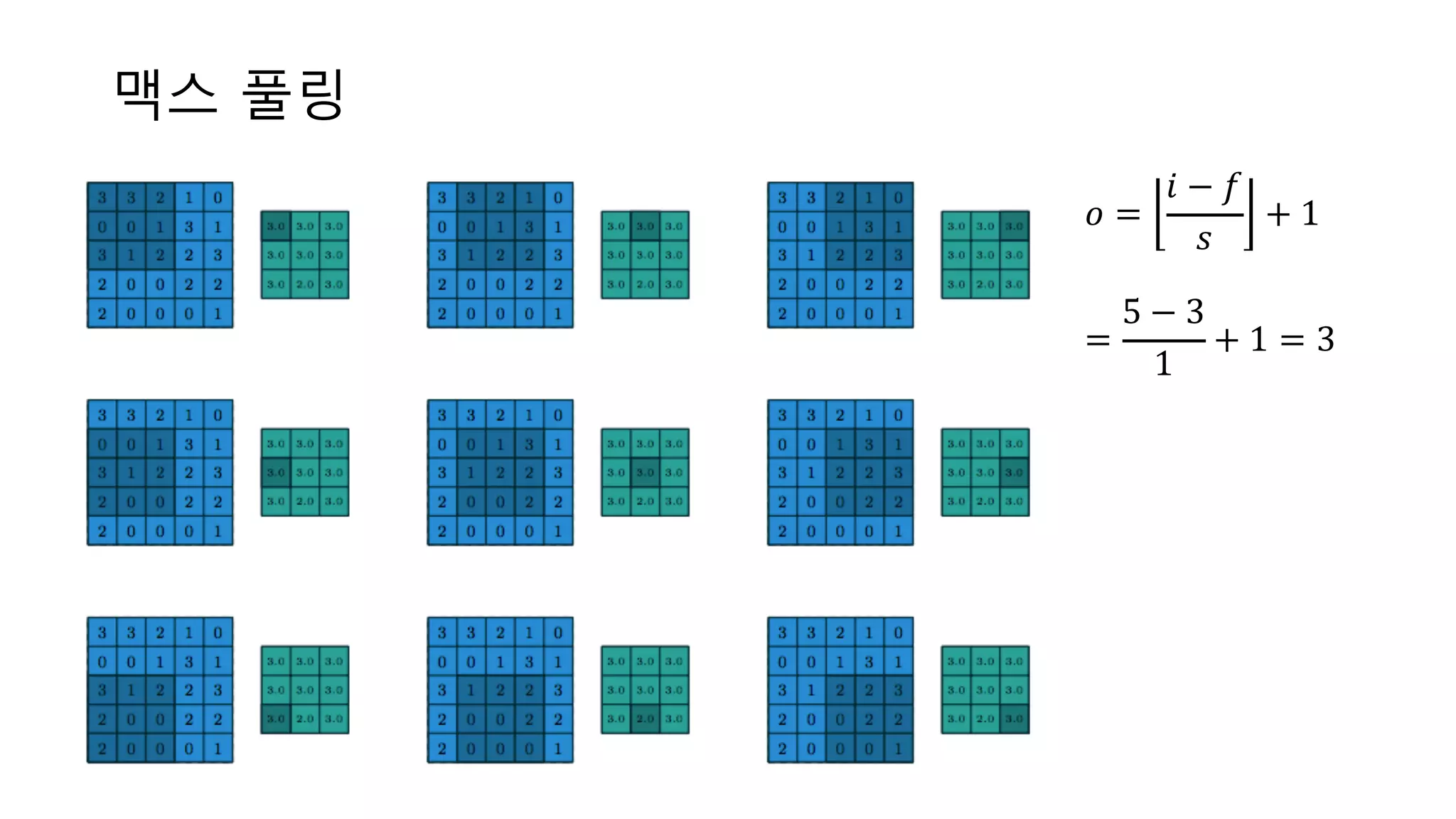
31.
맥스 풀링 𝑜 = 𝑖
− 𝑓 𝑠 + 1 = 5 − 3 1 + 1 = 3
32.
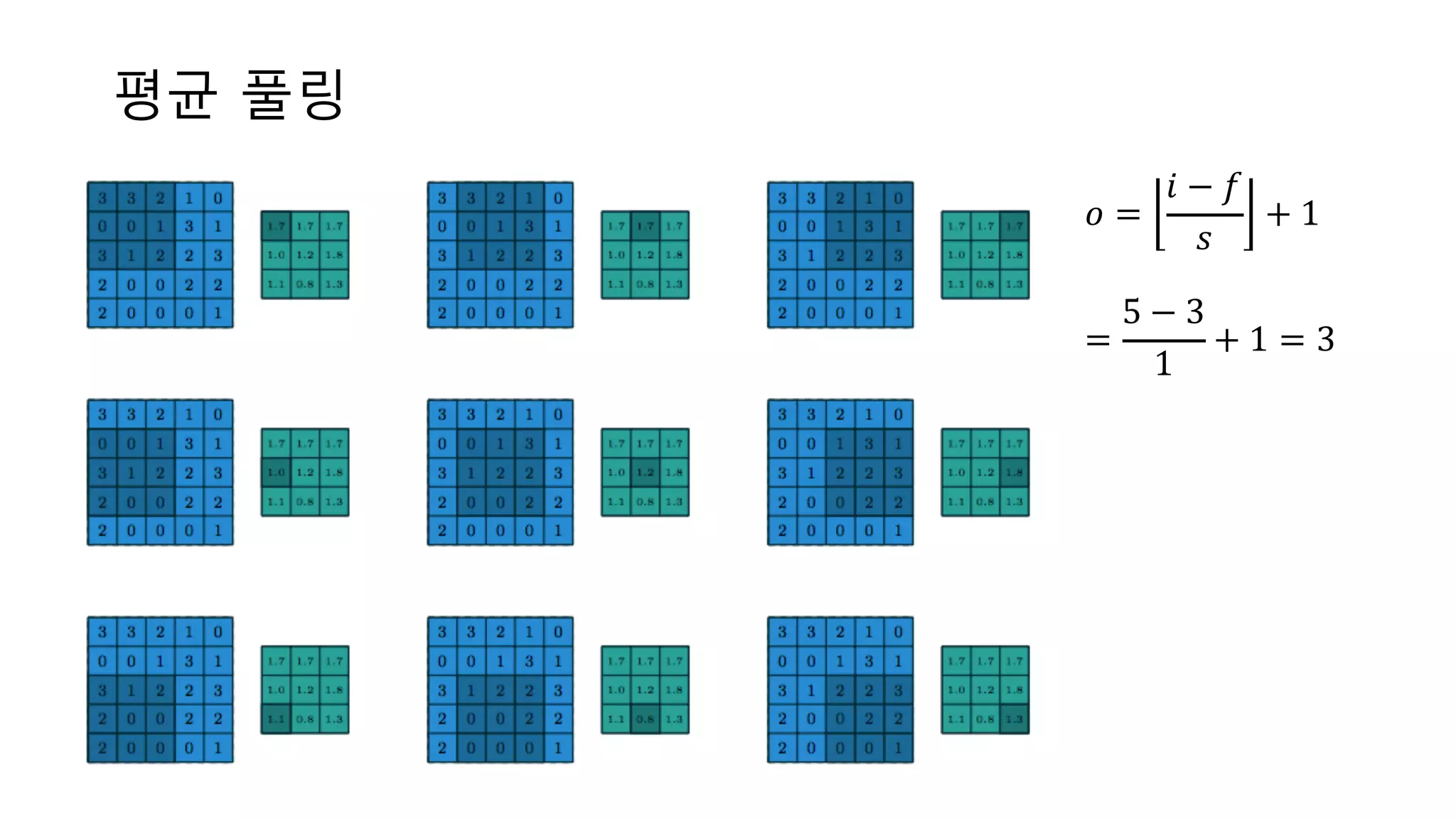
평균 풀링 𝑜 = 𝑖
− 𝑓 𝑠 + 1 = 5 − 3 1 + 1 = 3
33.
max_pool() • 커널 크기와
스트라이드 크기를 구체적으로 지시함 • tf.layers.max_pooling2d()를 사용하면 편리 W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1)) b = tf.Variable(tf.constant(0.1, shape=[10])) conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’) + b actv = tf.nn.relu(conv) pool = tf.nn.max_pool(actv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1])
34.
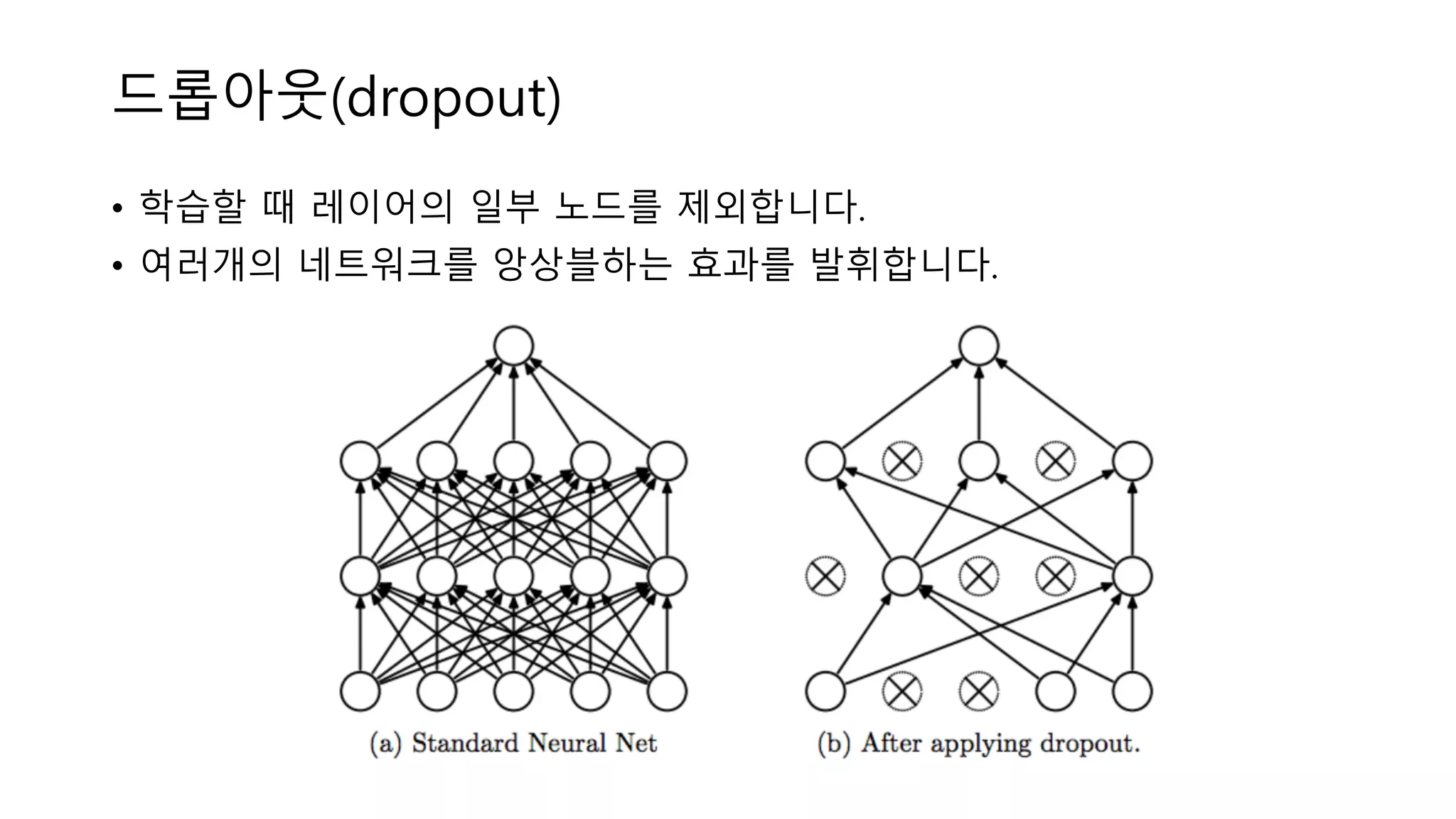
드롭아웃(dropout) • 학습할 때
레이어의 일부 노드를 제외합니다. • 여러개의 네트워크를 앙상블하는 효과를 발휘합니다.
35.
drop_out() • 드롭 아웃할
확률을 지정합니다. • 추론(inference)시에는 드롭아웃을 하면 안됩니다.(플레이스 홀더) • 예제에서는 tf.layers.dropout() 함수를 사용하겠습니다. drop = tf.nn.dropout(fc_output, keep_prob) drop = tf.layers.dropout(fc_output, drop_prob) 드롭시킬 비율 드롭시키지 않고 남길 비율
36.
콘볼루션 구현
37.
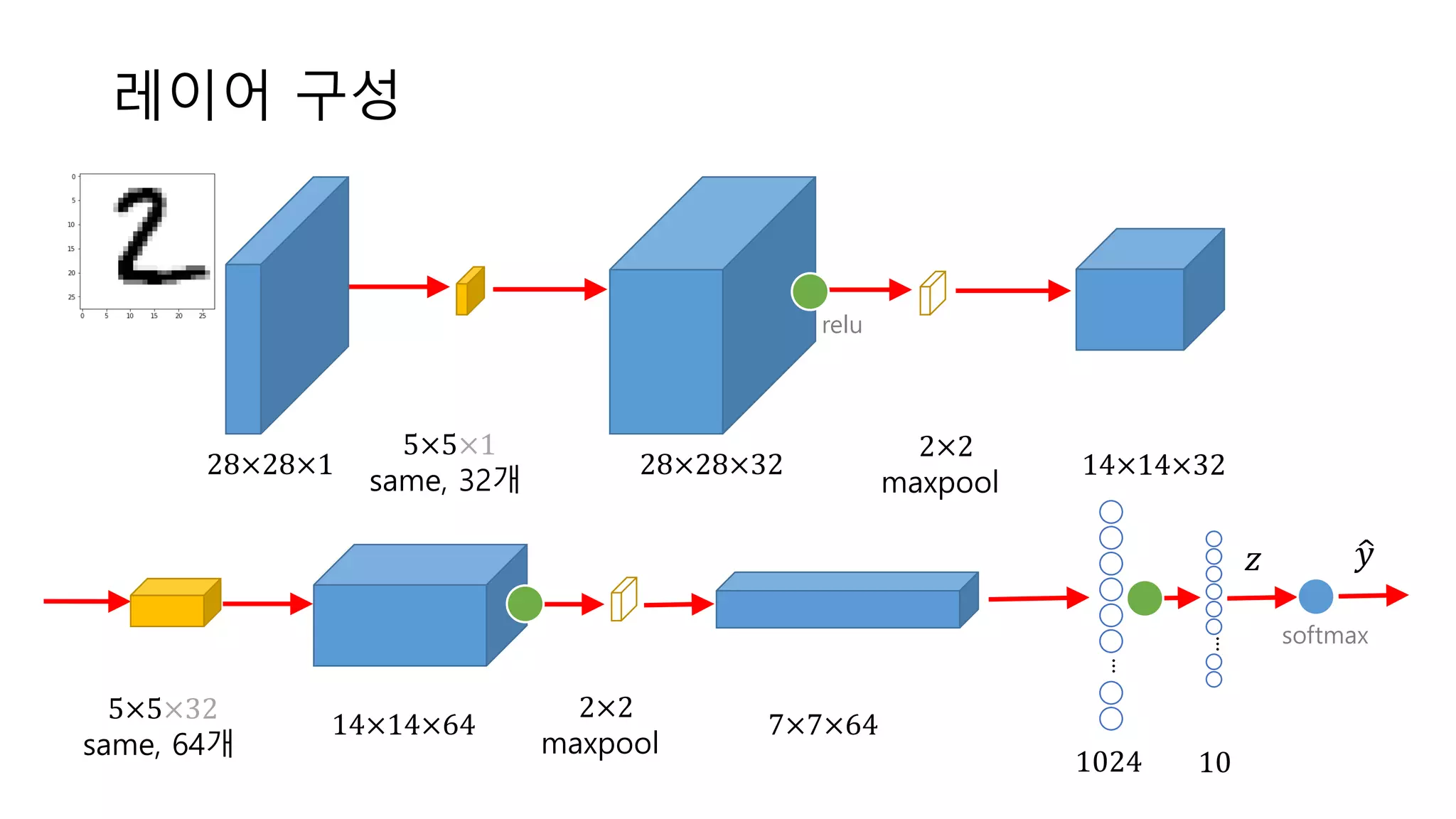
레이어 구성 ... ... 28×28×1 5×5×1 same, 32개 28×28×32 2×2 maxpool 14×14×32 5×5×32 same,
64개 14×14×64 2×2 maxpool 7×7×64 1024 10 𝑦<𝑧 softmax relu
38.
콘볼루션1 • 5x5 커널,
32개 • 스트라이드 1 • 패딩 same • ReLU 활성화 함수 28×28×1 5×5×1 same, 32개 28×28×32 relu
39.
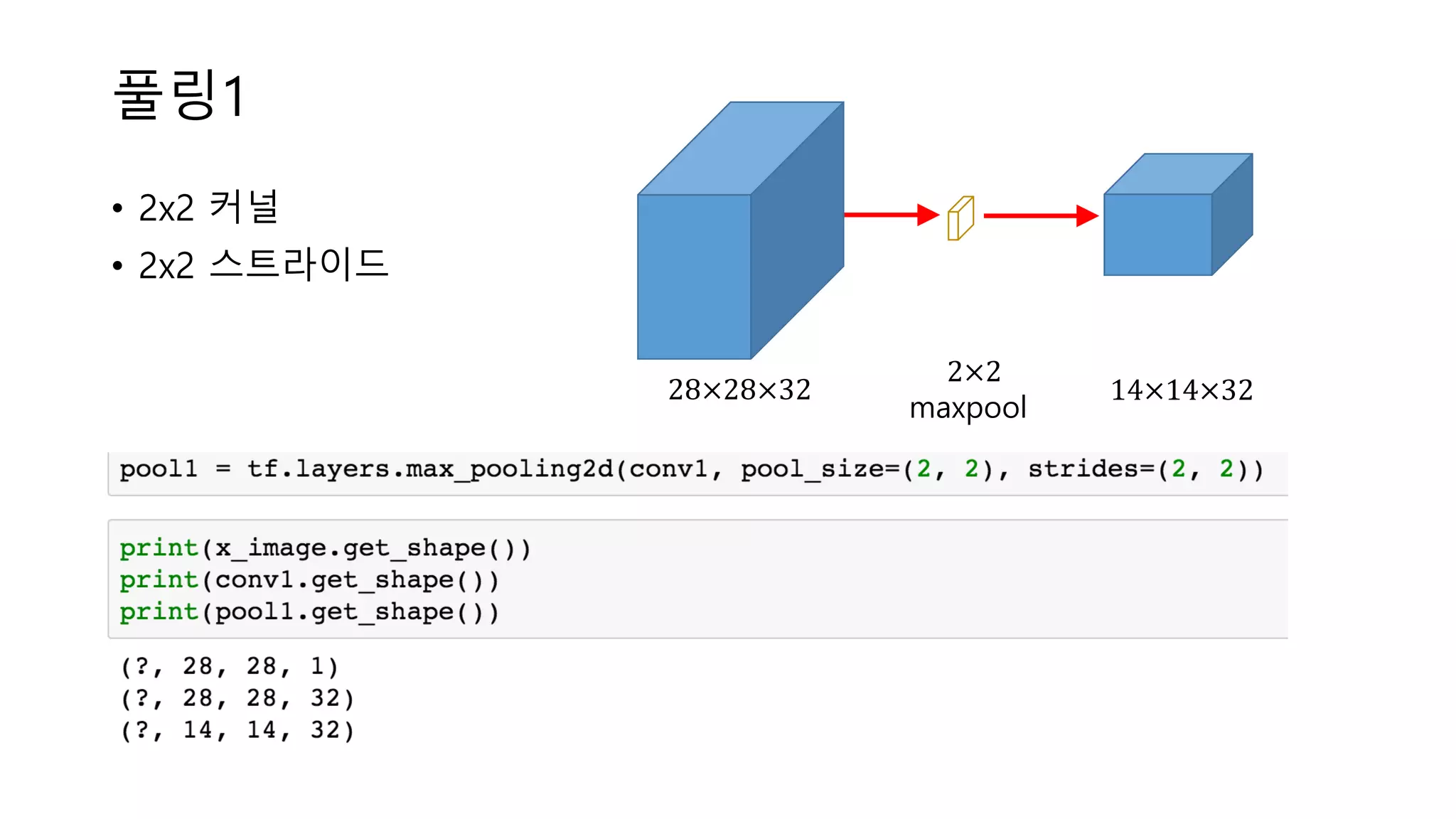
풀링1 • 2x2 커널 •
2x2 스트라이드 28×28×32 2×2 maxpool 14×14×32
40.
콘볼루션2 • 5x5 커널,
64개 • 스트라이드 1 • 패딩 same • ReLU 활성화 함수 5×5×32 same, 64개 14×14×6414×14×32
41.
풀링2 • 2x2 커널 •
2x2 스트라이드 14×14×64 2×2 maxpool 7×7×64
42.
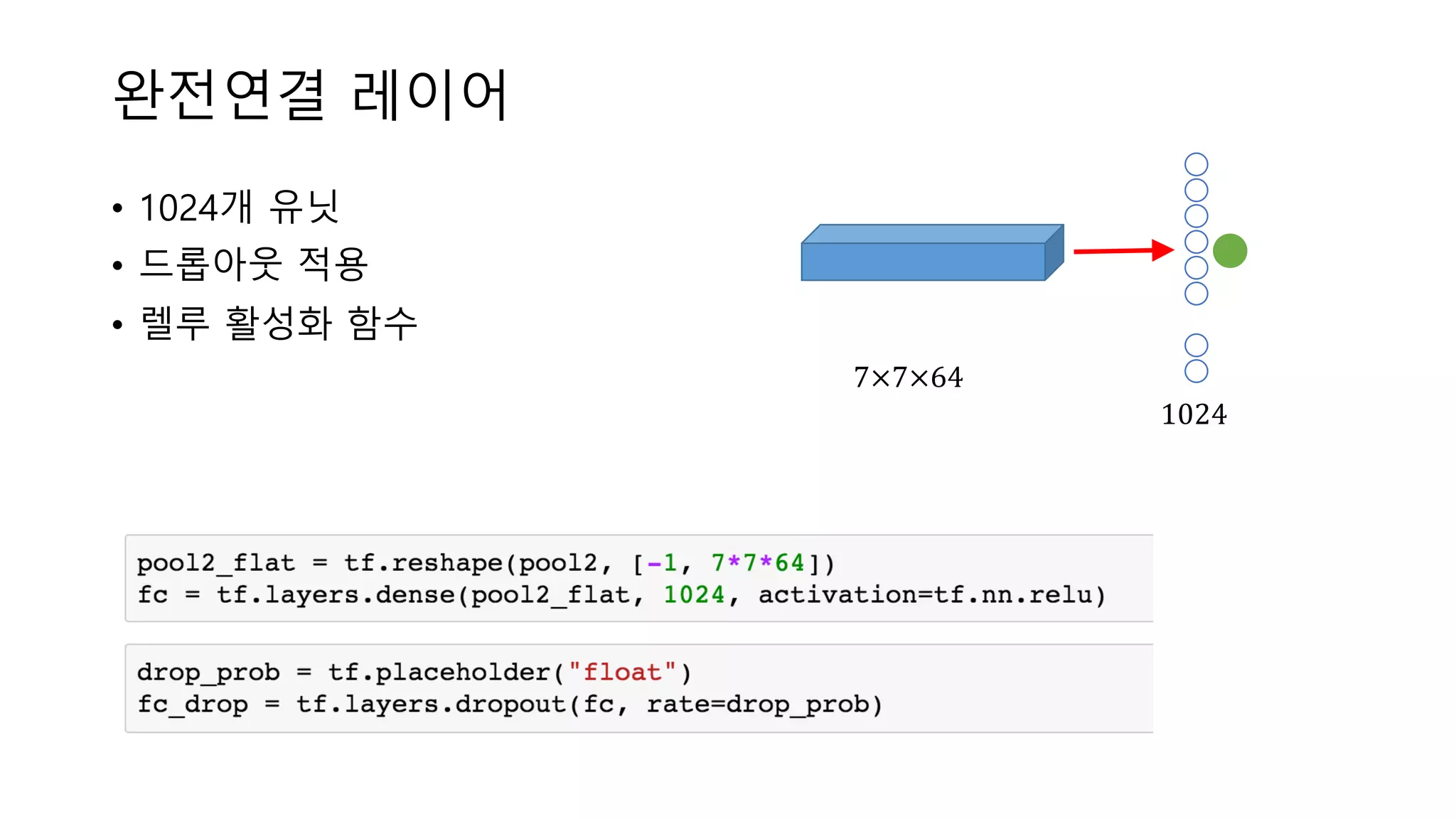
완전연결 레이어 • 1024개
유닛 • 드롭아웃 적용 • 렐루 활성화 함수 7×7×64 1024
43.
출력 레이어 • 10개의
유닛 • 소프트 맥스 활성화 함수 10 𝑦<𝑧 softmax 소프트맥스 통과전 : z 소프트맥스 통과후 : y_hat
44.
학습 설정 argmax(y) =
[?] argmax(y_hat) = [?] y = [?, 10] z = [?, 10] 불리언을 숫자로 바꾸고 평균을 냅니다. [True, False, True,... ] à [1.0, 0.0, 1.0, ...]
45.
미니 배치 훈련 100개씩
데이터 샘플링 x_data: [100, 784] y_data: [100, 10]
46.
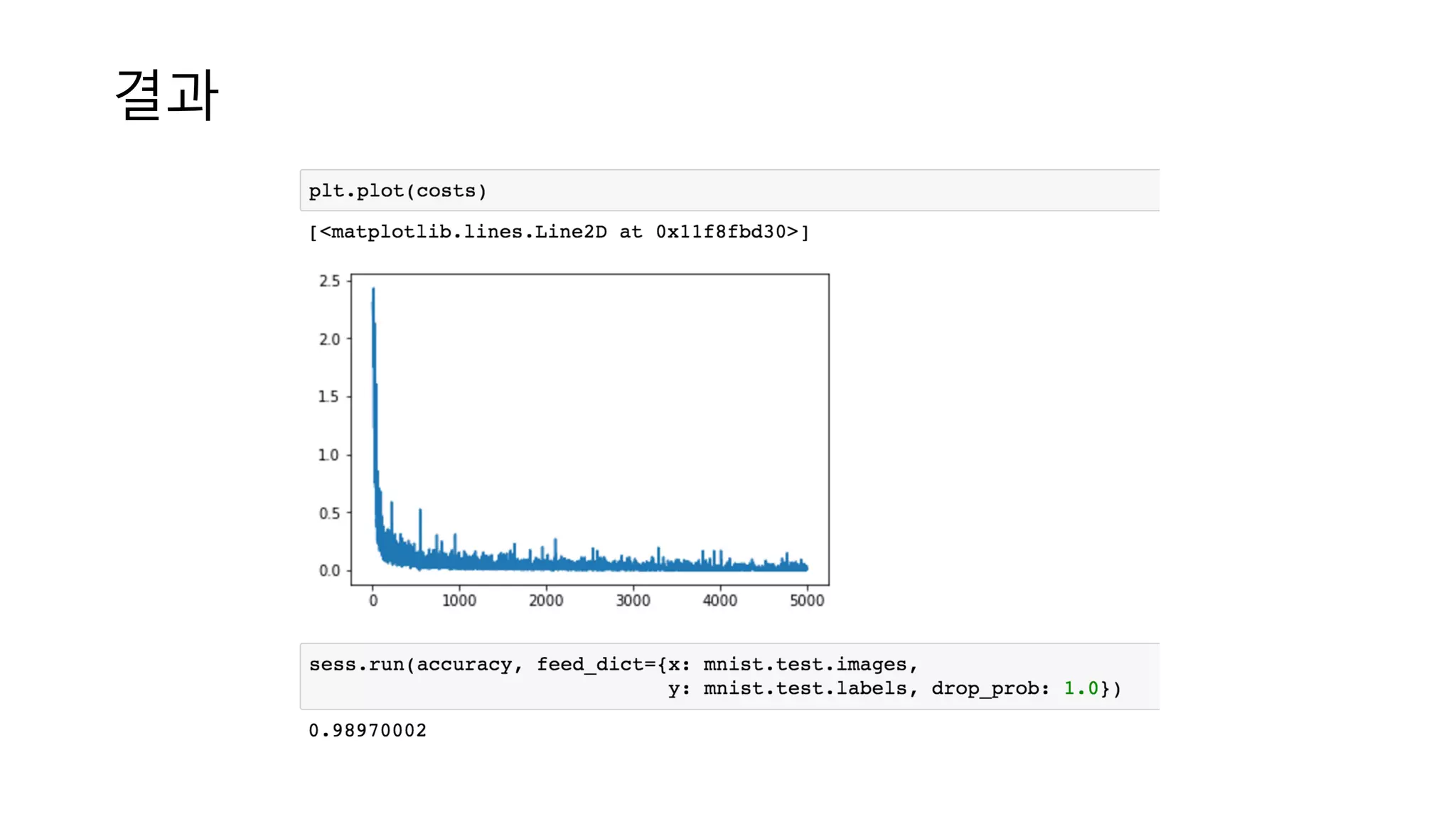
결과
47.
첫번째 콘볼루션 필터
32개
48.
Materials • Github : https://github.com/rickiepark/tfk-notebooks/tree/master/tensorflow_for_beginners •
Slideshare : https://www.slideshare.net/RickyPark3/ 48
49.
감사합니다. 49
Download




![레이어간 행렬 계산
5
𝑥"
0.6
⋯
𝑥$%
0.2
⋮ ⋱ ⋮
0.5 ⋯ 0.4
⋅
𝑤"
"
⋮
𝑤$%
"
⋱
𝑤"
"%
⋮
𝑤$%
"%
=
1.5
5.9
⋮
0.7
⋱
1.1
0.2
⋮
0.5
+ 𝑏" ⋯ 𝑏$% =
1.2
2.9
⋮
1.7
⋱
1.6
2.2
⋮
4.1
569 x 10 크기
569개
샘플
𝑥 × 𝑊 + 𝑏 = 𝑧
[569, 30] x [30, 10] = [569, 10] + [10] = [569, 10]
10개 편향(bias)
30개 특성
569 x 10개 결과
(logits)
...
𝑥%
𝑥"
𝑥$%
𝑏%
𝑏"%
30 x 10개
가중치](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-5-2048.jpg)


![Fully Connected
• 이미지 픽셀을 일렬로 펼쳐서 네트워크에 주입합니다.
...
784×100 + [100]
...](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-13-2048.jpg)
![Convolution
• 이미지의 2차원 구조를 그대로 이용합니다.
• 가중치가 재활용되어 사이즈가 크게 줄어 듭니다.
...
...
...
...
3×3 + [1]
...](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-14-2048.jpg)
![Feature Map
• 콘볼루션으로 만들어진 2차원 맵을 특성 맵이라고 부릅니다.
• 보통 한 레이어에서 여러개의 특성 맵을 만듭니다.
...
...
...
...
⋅ 3×3 + [1]
특성 맵
(Feature Map)](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-16-2048.jpg)
![conv2d()
• 가중치와 바이어스를 직접 생성해 전달
• tf.layers.conv2d()를 사용하면 편리함
...
...
...
...
⋅ 3×3 + [1]
W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1))
b = tf.Variable(tf.constant(0.1, shape=[10]))
conv = tf.nn.conv2d(x, W) + b](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-18-2048.jpg)

![스트라이드 계산
𝑜 =
𝑖 − 𝑓
𝑠
+ 1 =
4 − 3
1
+ 1 = 2
입력(i): 4x4
필터(f): 3x3
스트라이드(s): 1
W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1))
b = tf.Variable(tf.constant(0.1, shape=[10]))
conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1]) + b](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-23-2048.jpg)
![텐서플로우 패딩 계산
• 패딩크기를 직접 지정, tf.pad()
• 패딩 타입(same/valid), 스트라이드 크기 à 패딩 크기 자동 결정
• same
• 출력크기=입력크기/스트라이드
• tf.layer.conv2d(.., padding=‘same’, ..)
• 패딩 크기가 필터의 절반 정도라 하프 패딩이라고도 부름
• valid
• 패딩을 넣지 않음
• tf.layer.conv2d(.., padding=‘valid’, ..)
W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1))
b = tf.Variable(tf.constant(0.1, shape=[10]))
conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’) + b](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-26-2048.jpg)
![ReLU
• Rectified Linear Unit
• -∞~+∞입력에 대해 0~+∞ 사이의 값을
출력합니다.
𝑦< = max (0, 𝑧)
W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1))
b = tf.Variable(tf.constant(0.1, shape=[10]))
conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’) + b
acti = tf.nn.relu(conv)](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-27-2048.jpg)

![max_pool()
• 커널 크기와 스트라이드 크기를 구체적으로 지시함
• tf.layers.max_pooling2d()를 사용하면 편리
W = tf.Variable(tf.truncated_normal([3, 3, 1, 10], stddev=0.1))
b = tf.Variable(tf.constant(0.1, shape=[10]))
conv = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME’) + b
actv = tf.nn.relu(conv)
pool = tf.nn.max_pool(actv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1])](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-33-2048.jpg)






![학습 설정
argmax(y) = [?]
argmax(y_hat) = [?]
y = [?, 10]
z = [?, 10]
불리언을 숫자로 바꾸고
평균을 냅니다.
[True, False, True,... ] à [1.0, 0.0, 1.0, ...]](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-44-2048.jpg)
![미니 배치 훈련
100개씩 데이터 샘플링
x_data: [100, 784]
y_data: [100, 10]](https://image.slidesharecdn.com/4-170508110332/75/4-convolutional-neural-networks-45-2048.jpg)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)



![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)


![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)


![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181010080045-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[컴퓨터비전과 인공지능] 7. 합성곱 신경망 2](https://cdn.slidesharecdn.com/ss_thumbnails/lec7convolutionnetworks2-210213150820-thumbnail.jpg?width=640&height=640&fit=bounds)







![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)







![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 9장 텐서플로 시작하기](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181127072259-thumbnail.jpg?width=640&height=640&fit=bounds)







