Downloaded 29 times




![Visual Studio [Code] Tools for AI
VS & VS Code extensions to
streamline computations in
servers, Azure ML, Batch AI, …
End to end development
environment, from new project
through training
Support for remote training & job
management
On top of all of the goodness of
VS (Python, Jupyter, Git, etc)
THR3129 Getting Started with Visual Studio Tools for AI, Chris Lauren](https://image.slidesharecdn.com/brk3709smith-180508160604/85/Migrating-Existing-Open-Source-Machine-Learning-to-Azure-9-320.jpg)



![Series RAM vCPU GPU Approx Cost
Standard_B1s 1 Gb 1 None Free [*]
DS3_v2 14Gb 4 None $0.23 / hr
DS4_v2 28Gb 8 None $0.46 / hr
A8v2 16Gb 8 None $0.82 / hr
Standard_NC6 56 Gb 6 0.5 NV Tesla K80 $0.93 / hr
Standard_ND6s 112 Gb 6 1x Tesla P40 $2.14 / hr
[*] Not recommended: Standard_B1s (free, but too small to be useful)](https://image.slidesharecdn.com/brk3709smith-180508160604/85/Migrating-Existing-Open-Source-Machine-Learning-to-Azure-15-320.jpg)





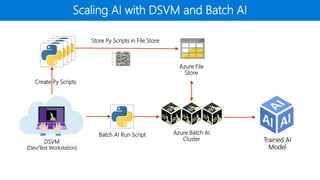

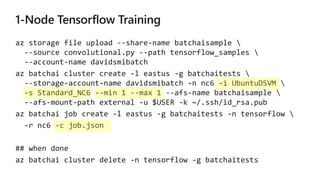

















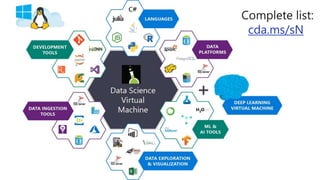
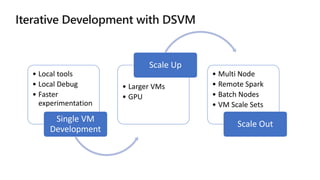
The document outlines the use of Microsoft Visual Studio tools for AI and Azure Batch AI for streamlined computational tasks across different operating systems. It highlights the flexibility and scalability of cloud computing, allowing custom cluster creation for specific jobs, leading to cost savings and efficient resource utilization. Additionally, it mentions practical applications, such as utilizing Apache Spark for analytics and machine learning tasks.



















































































