Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
TN
Uploaded by
Takanori Nakai
PDF, PPTX
1,889 views
WSDM2018 読み会 Latent cross making use of context in recurrent recommender systems.slide
WSDM2018 読み会 Latent cross making use of context in recurrent recommender systems.slide
Data & Analytics
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 15
2
/ 15
3
/ 15
4
/ 15
5
/ 15
6
/ 15
7
/ 15
8
/ 15
9
/ 15
10
/ 15
11
/ 15
12
/ 15
13
/ 15
14
/ 15
15
/ 15
More Related Content
PDF
機械学習システムのアーキテクチャアラカルト
by
BrainPad Inc.
PPTX
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
PPTX
分散深層学習 @ NIPS'17
by
Takuya Akiba
PDF
Cosine Based Softmax による Metric Learning が上手くいく理由
by
tancoro
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
PDF
遺伝的アルゴリズム (Genetic Algorithm)を始めよう!
by
Kazuhide Okamura
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
機械学習システムのアーキテクチャアラカルト
by
BrainPad Inc.
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
分散深層学習 @ NIPS'17
by
Takuya Akiba
Cosine Based Softmax による Metric Learning が上手くいく理由
by
tancoro
マルチモーダル深層学習の研究動向
by
Koichiro Mori
遺伝的アルゴリズム (Genetic Algorithm)を始めよう!
by
Kazuhide Okamura
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
What's hot
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)
by
Deep Learning JP
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PPTX
Active Learning と Bayesian Neural Network
by
Naoki Matsunaga
PDF
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
PPTX
[DL輪読会]V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete...
by
Deep Learning JP
PPTX
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
PPTX
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
PDF
「統計的学習理論」第1章
by
Kota Matsui
PPTX
A3C解説
by
harmonylab
PDF
SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用
by
SSII
PDF
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)
by
Deep Learning JP
Transformer メタサーベイ
by
cvpaper. challenge
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
GAN(と強化学習との関係)
by
Masahiro Suzuki
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
Active Learning と Bayesian Neural Network
by
Naoki Matsunaga
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
[DL輪読会]V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete...
by
Deep Learning JP
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
「統計的学習理論」第1章
by
Kota Matsui
A3C解説
by
harmonylab
SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用
by
SSII
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
Stanコードの書き方 中級編
by
Hiroshi Shimizu
Similar to WSDM2018 読み会 Latent cross making use of context in recurrent recommender systems.slide
PDF
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PDF
Recurrent Neural Networks
by
Seiya Tokui
PDF
Learning to forget continual prediction with lstm
by
Fujimoto Keisuke
PDF
【DeepLearning研修】Transformerの基礎と応用 -- 第1回 Transformerの基本
by
Sony - Neural Network Libraries
PDF
拡がるディープラーニングの活用
by
NVIDIA Japan
PDF
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
PDF
ChainerによるRNN翻訳モデルの実装+@
by
Yusuke Oda
PDF
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
PDF
論文紹介:OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Unde...
by
Toru Tamaki
PDF
Query and output generating words by querying distributed word representatio...
by
ryoma yoshimura
PDF
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
PPTX
A simple neural network mnodule for relation reasoning
by
harmonylab
PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
PDF
論文紹介 Star-Transformer (NAACL 2019)
by
広樹 本間
PDF
[ML論文読み会資料] Teaching Machines to Read and Comprehend
by
Hayahide Yamagishi
PPTX
When will you do what? - Anticipating Temporal Occurrences of Activities (CVP...
by
TakuyaKobayashi12
PPTX
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
PDF
Multivariate Time series analysis via interpretable RNNs
by
ohken
PDF
Attention-Based Recurrent Neural Network Models for Joint Intent Detection a...
by
Shunsuke Ono
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
LSTM (Long short-term memory) 概要
by
Kenji Urai
Recurrent Neural Networks
by
Seiya Tokui
Learning to forget continual prediction with lstm
by
Fujimoto Keisuke
【DeepLearning研修】Transformerの基礎と応用 -- 第1回 Transformerの基本
by
Sony - Neural Network Libraries
拡がるディープラーニングの活用
by
NVIDIA Japan
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
ChainerによるRNN翻訳モデルの実装+@
by
Yusuke Oda
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
論文紹介:OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Unde...
by
Toru Tamaki
Query and output generating words by querying distributed word representatio...
by
ryoma yoshimura
Linguistic Knowledge as Memory for Recurrent Neural Networks_論文紹介
by
Masayoshi Kondo
A simple neural network mnodule for relation reasoning
by
harmonylab
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
論文紹介 Star-Transformer (NAACL 2019)
by
広樹 本間
[ML論文読み会資料] Teaching Machines to Read and Comprehend
by
Hayahide Yamagishi
When will you do what? - Anticipating Temporal Occurrences of Activities (CVP...
by
TakuyaKobayashi12
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
Multivariate Time series analysis via interpretable RNNs
by
ohken
Attention-Based Recurrent Neural Network Models for Joint Intent Detection a...
by
Shunsuke Ono
More from Takanori Nakai
PDF
GBDTを使ったfeature transformationの適用例
by
Takanori Nakai
PDF
PUCKモデルの適用例:修論を仕上げた後、個人的にやっていたリサーチ
by
Takanori Nakai
PDF
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
PDF
Analysis of Learning from Positive and Unlabeled Data
by
Takanori Nakai
PPTX
Sentence-State LSTM for Text Representation
by
Takanori Nakai
PDF
Unsupervised Graph-based Topic Labelling using DBpedia
by
Takanori Nakai
PDF
Query driven context aware recommendation
by
Takanori Nakai
PPTX
Topic discovery through data dependent and random projections
by
Takanori Nakai
PDF
Modeling Mass Protest Adoption in Social Network Communities using Geometric ...
by
Takanori Nakai
PDF
Preference-oriented Social Networks_Group Recommendation and Inference
by
Takanori Nakai
PDF
高次元データの統計:スパース正則化の近似誤差と推定誤差
by
Takanori Nakai
PDF
Similarity component analysis
by
Takanori Nakai
PDF
Positive Unlabeled Learning for Deceptive Reviews Detection
by
Takanori Nakai
PDF
Learning Better Embeddings for Rare Words Using Distributional Representations
by
Takanori Nakai
PDF
Psychological Advertising_Exploring User Psychology for Click Prediction in S...
by
Takanori Nakai
PDF
金利期間構造について:Forward Martingale Measureの導出
by
Takanori Nakai
PDF
Adaptive subgradient methods for online learning and stochastic optimization ...
by
Takanori Nakai
PDF
Note : Noise constastive estimation of unnormalized statictics methods
by
Takanori Nakai
GBDTを使ったfeature transformationの適用例
by
Takanori Nakai
PUCKモデルの適用例:修論を仕上げた後、個人的にやっていたリサーチ
by
Takanori Nakai
ICLR2017読み会 Data Noising as Smoothing in Neural Network Language Models @Dena
by
Takanori Nakai
Analysis of Learning from Positive and Unlabeled Data
by
Takanori Nakai
Sentence-State LSTM for Text Representation
by
Takanori Nakai
Unsupervised Graph-based Topic Labelling using DBpedia
by
Takanori Nakai
Query driven context aware recommendation
by
Takanori Nakai
Topic discovery through data dependent and random projections
by
Takanori Nakai
Modeling Mass Protest Adoption in Social Network Communities using Geometric ...
by
Takanori Nakai
Preference-oriented Social Networks_Group Recommendation and Inference
by
Takanori Nakai
高次元データの統計:スパース正則化の近似誤差と推定誤差
by
Takanori Nakai
Similarity component analysis
by
Takanori Nakai
Positive Unlabeled Learning for Deceptive Reviews Detection
by
Takanori Nakai
Learning Better Embeddings for Rare Words Using Distributional Representations
by
Takanori Nakai
Psychological Advertising_Exploring User Psychology for Click Prediction in S...
by
Takanori Nakai
金利期間構造について:Forward Martingale Measureの導出
by
Takanori Nakai
Adaptive subgradient methods for online learning and stochastic optimization ...
by
Takanori Nakai
Note : Noise constastive estimation of unnormalized statictics methods
by
Takanori Nakai
WSDM2018 読み会 Latent cross making use of context in recurrent recommender systems.slide
1.
Latent Cross: Making
Use of Context in Recurrent Recommender Systems by Alex Beutel, etc 担当: @Quasi_quant2010 WSDM2018読み会1 【WSDM2018読み会】
2.
概要 - コンテキストは結合せずattentionとして扱う -
行列分解系の予測をNNで近似する 変数間の相互作用について、明示的に相関関係を与えない設定 でNNはデータから相互作用を学習するのか 埋め込みベクトルの結合以外で予測を高める仕組みは? Latent Crossを提案 提案手法を考えた背景 コンテキストを単純に結合した埋め込みベクトルを用いるとモデルサ イズが大きくなるので非効率 コンテキストを主たる特徴量を調整する情報源と捉える 主たる特徴量の埋め込みベクトル(x)とコンテキストの埋め込みベクトル (c)の要素積をとる。つまり、xにcというattentionを作用させる 操作自体はノイズ処理に対応 WSDM2018読み会2
3.
実験① - 行列分解系の予測をNNで近似する -
行列分解系 Matrix Factorization : 2変数間の相関 𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑖𝑜𝑛𝑖𝑗 = < 𝒖𝒊, 𝒗𝒋 > Tensor Factorization : 3変数間の相関 𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑖𝑜𝑛𝑖𝑗𝑡 = < 𝒖𝒊, 𝒗𝒋, 𝒘𝒕 > NNでもPredictionを予測する 行列分解系の予測を近似するとは、異なるモデル(行列分解系・ NN)で同じ値(Prediction)を予測 行列分解系は2 or 3変数間の相関を通じ相互作用を加味 NNで行列分解系と同程度の予測ができれば、 NNが変数間の 相互作用を学習できていると解釈する WSDM2018読み会3
4.
実験① - 行列分解系の予測をNNで近似する -
m個特徴量をN回レコードとして観測する デザイン行列 : m * N ただし、m個が各々独立した特徴量とは限らない 独立した特徴量を見つけたいという行列分解系の動機がある あらかじめランクr(<m)と分かっている状況で、 NNは行列分解系の予測結果を再現できるか データ:m * H * N m:特徴量の種類, H:埋め込みベクトルの次元, N:レコード数 再現するにはどのようなパラメータが必要か 本検証では隠れ層1層で幅CのNNを検証モデルとする 埋め込みベクトルのサイズについて試行実験をし、サイズの大小 によって結果はあまり変わらなかった4 𝒖 ~ 𝑁(0, 1/𝑟1/2𝑚 𝐼)
5.
実験① - 検証モデル :
隠れ層1・幅CのNN - Input Layer 𝑊𝑖𝑛 × 𝑒𝑗 ej : one-hot Hidden Layer Activation : ReLU 𝒉 𝒄 = 𝑔 𝑉 𝒂; 𝒃 + 𝑏 結合したあとReLUを通じ相互 作用を獲得するらしい Transform and Aggregation 𝒉 = 𝑐=1 𝐶 𝛼 𝑐 𝒉 𝒄 Ouput Layer 𝑦 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑊𝑜𝑢𝑡 𝒉 + 𝑐) Reference Split, Transform, and Aggregation are based on [Xie.S]WSDM2018読み会5 Activati on 1 Activati on 2 Activati on C Input Layer Output Layer split transform aggregation
6.
実験① - NNが変数間の相互作用を学習したと解釈- 結果
ランク数一定で特徴量(m)が2から3に増えたとき、行列分解と同 等の性能を出すために、幅が4倍(=20/5)必要 独立な特徴量が1で観測特徴量が2の場合を指す。つまり、 不必要な特徴量が多い場合、各隠れ層の幅を大きくとる必要がある 特徴量一定でランク数が1から2に増えたとき、行列分解と同等の 性能を出すために、幅が3倍(=30/10)必要 観測した特徴量の内、 独立成分がより多い場合も各隠れ層の幅を大きくとる必要がある WSDM2018読み会6 引用[Beutel.A, etc]
7.
問題設定 - 動画推薦タスク -
データ 各ユーザーの動画視聴履歴をセッションとして保持 セッションは30分とかではなく、全セッションを繋げたものだと思われる 言語モデルで言えば単語が動画IDに対応 その他に、コンテキストとして以下のデータがある 直前見終わった時間と見始める時間間隔 デバイスタイプ(iOS, Android,etc) Referer:ユーザーが自発的に流入したかレコメンドから流入したか 予測値:動画ID 前処理 5Mの人気動画のみを計算対象 少なくともセッション中、50種類の動画をみているユーザに限る 7
8.
Simple Technique for
RNN - コンテキストを結合せずattentionとして扱う - 実験①から、不必要な特徴量が多い場合、各隠れ層の幅 を大きくとる必要がある 例えばRNNの隠れ層に幅を導入することも可能ではあるが、モデ ルサイズが肥大することが実験①から分かる コンテキストは種類が多くなる傾向があり、結合でない観点から新 たな計算方法(それがLatentCross)を考える必要がある 本論文では以下のような調整(LatentCross)を行う 𝒉 = 1 + 𝑐=1 𝐶 𝒂 𝒄 ∗ 𝒉 h : 隠れ層の埋め込みベクトル ac : c-thコンテキストの埋め込みベクトル 結合する場合、𝑔(𝑉 𝒙; 𝒂 𝟏; 𝒂 𝟐 … ; 𝒂 𝒄 + 𝒃)とかになる WSDM2018読み会8
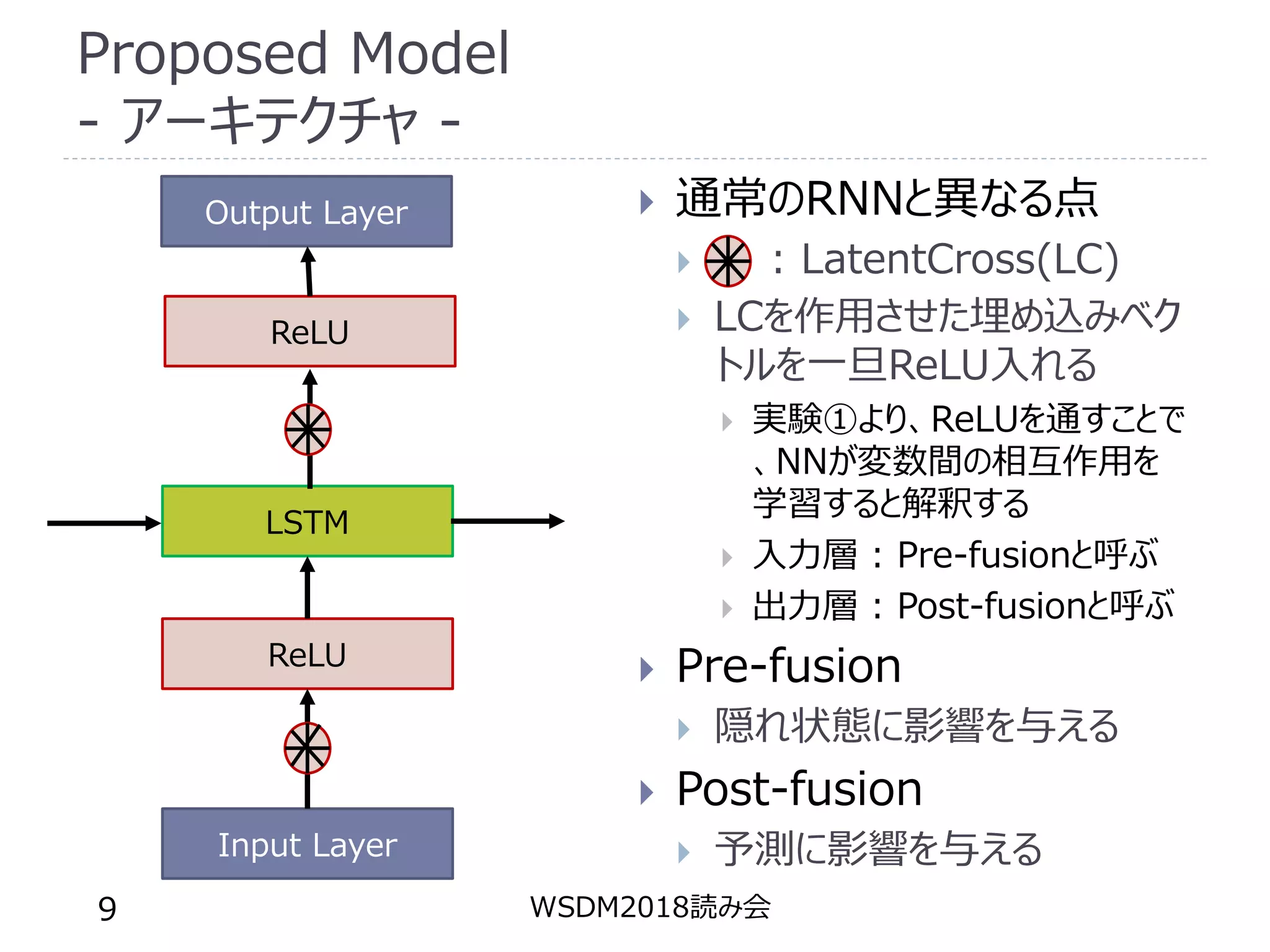
9.
Proposed Model - アーキテクチャ
- 通常のRNNと異なる点 : LatentCross(LC) LCを作用させた埋め込みベク トルを一旦ReLU入れる 実験①より、ReLUを通すことで 、NNが変数間の相互作用を 学習すると解釈する 入力層 : Pre-fusionと呼ぶ 出力層 : Post-fusionと呼ぶ Pre-fusion 隠れ状態に影響を与える Post-fusion 予測に影響を与える WSDM2018読み会9 Input Layer LSTM ReLU ReLU Output Layer
10.
実験② - ProposedModel vs
SOTA - RNNwithConcatenated < RNNwithLC RNNwithoutConcatenated < RNNwithConcatenated WSDM2018読み会10 引用[Beutel.A, etc]
11.
実験③ - ProposedModel with
various context - 実験②より提案モデルがSOTAより性能が高い ただし、使用したコンテキストは時間のみ よって、より多くのコンテキストを使用する事で予測性能が向 上するかを追加実験 追加実験① コンテキストを時間からリファラーに変更 追加実験② Pre-fusion 時間間隔・リファラー Post-fusion デバイス・リファラー WSDM2018読み会11
12.
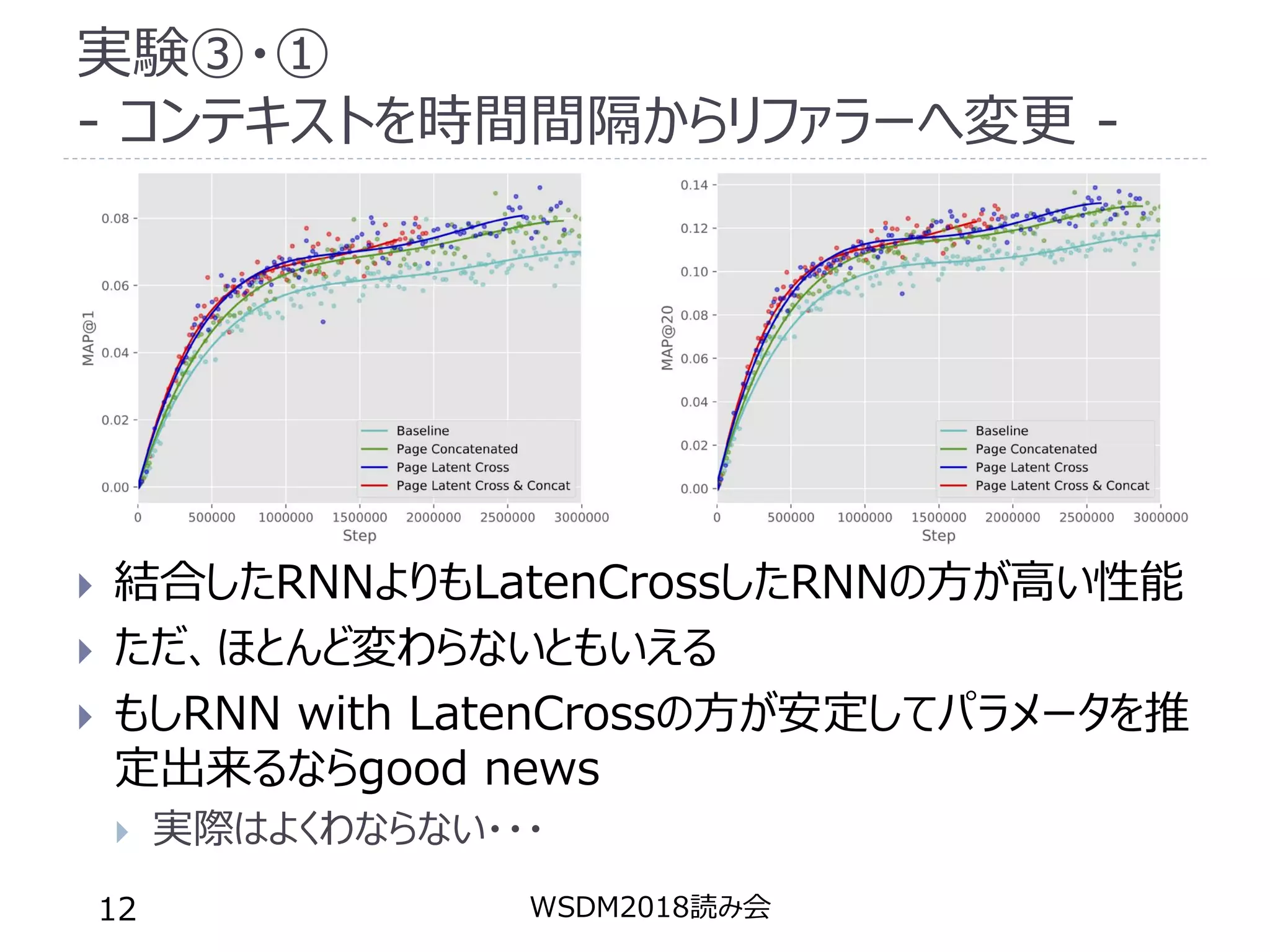
実験③・① - コンテキストを時間間隔からリファラーへ変更 -
結合したRNNよりもLatenCrossしたRNNの方が高い性能 ただ、ほとんど変わらないともいえる もしRNN with LatenCrossの方が安定してパラメータを推 定出来るならgood news 実際はよくわならない・・・ WSDM2018読み会12
13.
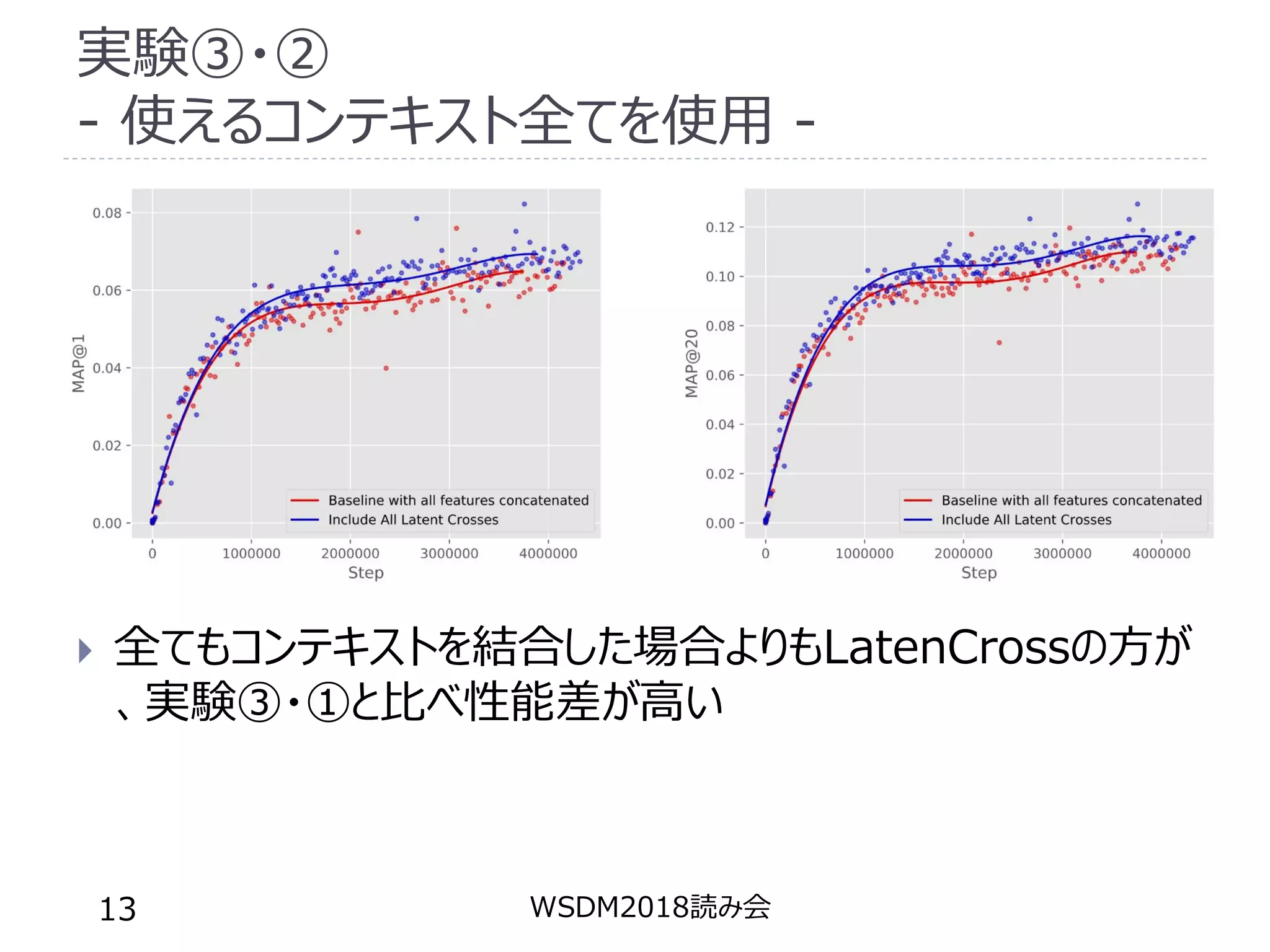
実験③・② - 使えるコンテキスト全てを使用 -
全てもコンテキストを結合した場合よりもLatenCrossの方が 、実験③・①と比べ性能差が高い WSDM2018読み会13
14.
感想 - 変数間相互作用とノイズ処理をNNで -
NNが変数の相互作用を学習するか 行列分解系の予測をNNで再現出来れば分からなくもない ノイズ処理 LatentCrossの背景 モデルサイズの効率性という点もあろうが、隠れ層の埋め込みを調整し、ノ イズ処理をしたいんだろう Pre(Post)-fusionは、明示的なノイズ処理 CNNでノイズ処理を行い、RNNの入力とする最近の流行を連想する 筆者はこれにより変数間相互作用を獲得できると主張しているが ノイズ処理についてはCNN+RNN との比較実験をした方がよいのでは WSDM2018読み会14
15.
参考文献 [Beutel.A, etc]
Latent Cross : Making Use of Context in Recurrent Recommender Systems, WSDM 2018 [Xie.S, etc] Aggregated Residual Transformations for Deep Neural Networks, arXiv:1611.05431 WSDM2018読み会15
Download




![実験①
- 検証モデル : 隠れ層1・幅CのNN -
Input Layer
𝑊𝑖𝑛 × 𝑒𝑗 ej : one-hot
Hidden Layer
Activation : ReLU
𝒉 𝒄 = 𝑔 𝑉 𝒂; 𝒃 + 𝑏
結合したあとReLUを通じ相互
作用を獲得するらしい
Transform and Aggregation
𝒉 = 𝑐=1
𝐶
𝛼 𝑐 𝒉 𝒄
Ouput Layer
𝑦 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑊𝑜𝑢𝑡 𝒉 + 𝑐)
Reference
Split, Transform, and Aggregation
are based on [Xie.S]WSDM2018読み会5
Activati
on 1
Activati
on 2
Activati
on C
Input Layer
Output Layer
split
transform
aggregation](https://image.slidesharecdn.com/latentcrossmakinguseofcontextinrecurrentrecommendersystems-180414070449/75/WSDM2018-Latent-cross-making-use-of-context-in-recurrent-recommender-systems-slide-5-2048.jpg)
![実験①
- NNが変数間の相互作用を学習したと解釈-
結果
ランク数一定で特徴量(m)が2から3に増えたとき、行列分解と同
等の性能を出すために、幅が4倍(=20/5)必要
独立な特徴量が1で観測特徴量が2の場合を指す。つまり、
不必要な特徴量が多い場合、各隠れ層の幅を大きくとる必要がある
特徴量一定でランク数が1から2に増えたとき、行列分解と同等の
性能を出すために、幅が3倍(=30/10)必要
観測した特徴量の内、
独立成分がより多い場合も各隠れ層の幅を大きくとる必要がある
WSDM2018読み会6
引用[Beutel.A, etc]](https://image.slidesharecdn.com/latentcrossmakinguseofcontextinrecurrentrecommendersystems-180414070449/75/WSDM2018-Latent-cross-making-use-of-context-in-recurrent-recommender-systems-slide-6-2048.jpg)


![実験②
- ProposedModel vs SOTA -
RNNwithConcatenated < RNNwithLC
RNNwithoutConcatenated < RNNwithConcatenated
WSDM2018読み会10
引用[Beutel.A, etc]](https://image.slidesharecdn.com/latentcrossmakinguseofcontextinrecurrentrecommendersystems-180414070449/75/WSDM2018-Latent-cross-making-use-of-context-in-recurrent-recommender-systems-slide-10-2048.jpg)


![参考文献
[Beutel.A, etc] Latent Cross : Making Use of Context in
Recurrent Recommender Systems, WSDM 2018
[Xie.S, etc] Aggregated Residual Transformations for Deep
Neural Networks, arXiv:1611.05431
WSDM2018読み会15](https://image.slidesharecdn.com/latentcrossmakinguseofcontextinrecurrentrecommendersystems-180414070449/75/WSDM2018-Latent-cross-making-use-of-context-in-recurrent-recommender-systems-slide-15-2048.jpg)






![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190920dlhack-190920011134-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete...](https://cdn.slidesharecdn.com/ss_thumbnails/20200904furuta-200904014839-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)





















