Download as PDF, PPTX


![● Developers often show emotions (joy, anger, etc) in their communications.
Motivation
Toxic 🤬
Appreciation 🙏
2
“@[USER] Thank you, Stephen. I hope in
the future Angular will become even better
and easier to understand. However, first of
all, I am grateful to Angular for making me
grow as a developer.”
Soooooooooooo you’re setting Angular on
fire and saying bold shit in bold like the
Angular team don’t care about you cause you
found relative pathing has an issue is an odd
area](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-2-320.jpg)
![Motivation
● General purpose emotion classification tools are not effective to Software
Engineering corpora.
● Researchers developed SE-specific tools to recognize emotions.
○ These tools do not perform very well [1]. On a StackOverflow dataset:
■ Joy: F1-score ranges between 0.37 to 0.47.
■ Fear: F1-score ranges between 0.22 to 0.40.
● Most likely problem: lack of large high-quality datasets on software developers
emotions in communication channel.
[1] Chen et al. “Emoji-powered sentiment and emotion detection from software developers' communication data.” TOSEM, 2021
3](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-3-320.jpg)
![Data Collection
● Selected 4 popular OSS repositories with over 50k GitHub stars.
4
[1] Biswas et al., “Achieving reliable sentiment analysis in the software engineering domain using bert.” ICSME, 2020.
● Total 2000 comments (1000 positive & 1000 negative)](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-4-320.jpg)

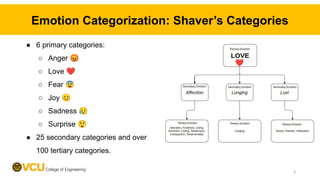
![Shaver’s Categories Are Not a Perfect Match
● “I’m curious about this - can you give more context on what exactly goes
wrong? Perhaps if that causes bugs this should be prohibited instead?"
○ Expresses Curiosity 🤔
● “And, I am a little confused, if there is not any special folder, according to the
module resolution [URL] How could file find the correct modules? Did I miss
something?”
○ Expresses Confusion 😕
7](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-7-320.jpg)

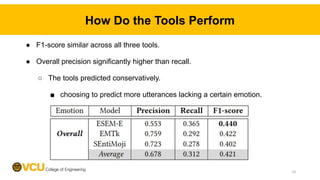
![Studied Tools for Emotion Classification in SE
ESEM-E [1] SVM Unigram, bigram
EMTk [2] SVM Unigram, bigram, emotion lexicon, polarity, mood
SEntiMoji [3] Transfer learning DeepMoji representation model
[1] Murgia et al., “An exploratory qualitative and quantitative analysis of emotions in issue report comments of open source systems.”, ESEM, 2018
[2] Calefato et al., “Emtk-the emotion mining toolkit.” SEmotion, 2019
[3] Chen et al. “Emoji-powered sentiment and emotion detection from software developers' communication data.” TOSEM, 2021
9](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-9-320.jpg)
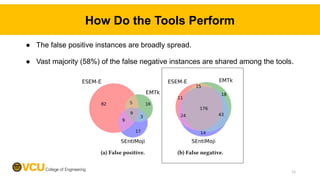
![Error Analysis of FNs
● Analyzed 176 FN instances using Novielli et al.’s categorization [1].
[1] Novielli, Nicole et al. "A benchmark study on sentiment analysis for software engineering research." 2018 MSR. 12](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-12-320.jpg)


![Data Augmentation: Unconstrained Strategy
● Four operators: insert, substitute, delete and shuffle.
● Used BART [1] generative model for insert and substitute operations.
15
[1] Lewis et al., “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and
Comprehension.” ACL, 2020](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-15-320.jpg)

![Data Augmentation: Lexicon-based Strategy
● Insert or Substitute word using an SE-specific emotion lexicon.
○ Emotion of the word is same as the annotation of the utterance.
● The SE-specific emotion lexicon comes from Mäntylä et al. [1].
[1] Mäntylä et al., “Bootstrapping a lexicon for emotional arousal in software engineering.” MSR, 2017
“This looks good,
thanks for clarifying
the docs.”
“This looks
wonderful, thanks
for clarifying the
docs.”
word from ‘Joy’ Lexicon
17](https://image.slidesharecdn.com/ase-2022slides-221018173208-9e121118/85/Data-Augmentation-for-Improving-Emotion-Recognition-in-Software-Engineering-Communication-17-320.jpg)
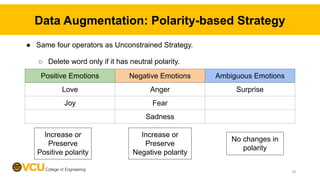
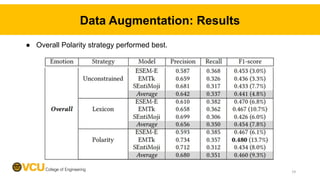



This paper explores improving emotion recognition in software engineering communication through data augmentation. It summarizes that developers often express emotions in communications, but current tools perform poorly at emotion recognition due to a lack of large, high-quality datasets. The paper manually annotates 2000 comments with emotions, extends an emotion taxonomy, and analyzes errors in existing tools. It then evaluates three data augmentation strategies and finds that augmenting data while preserving sentiment polarity improves tool performance the most. The paper contributes annotated data and data augmentation source codes to aid future emotion recognition research.

























































