Downloaded 39 times















![Striking the balance
22
Relevance Popularity
● Names, Descriptions, Tags, [owners, frequent
users]
● Querying activity
● Dashboarding
● Different weights for automated vs adhoc
querying](https://image.slidesharecdn.com/meetupsf-amundsenpresentation-190516010721/85/Meetup-SF-Amundsen-22-320.jpg)


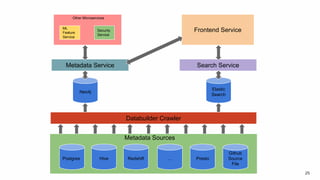

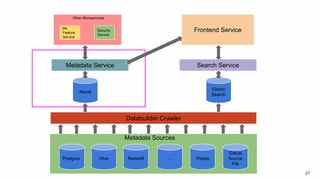
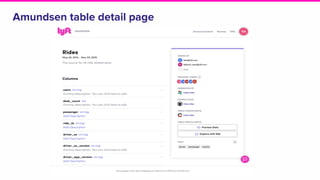

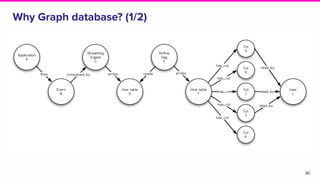
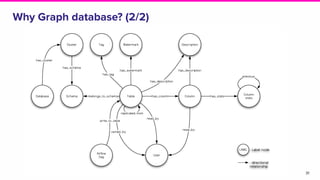


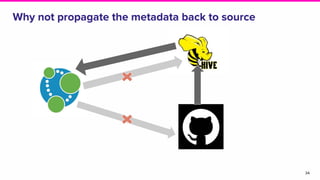

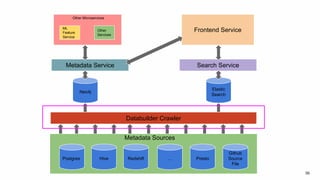



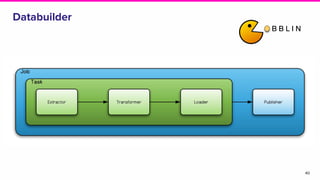
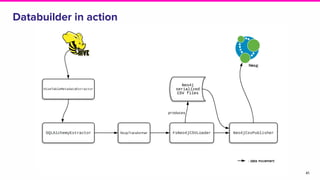
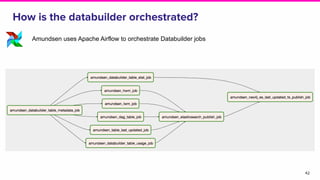

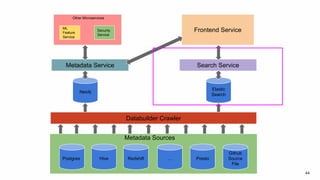




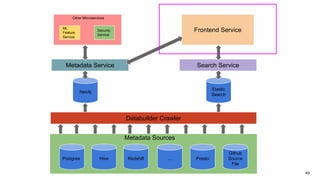

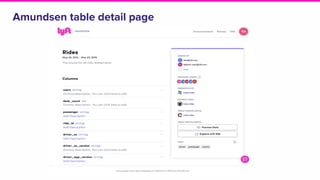



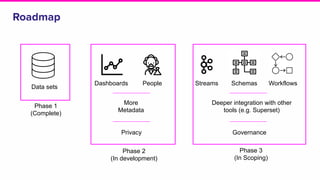








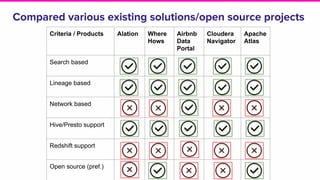


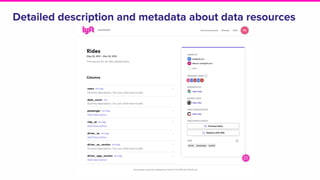
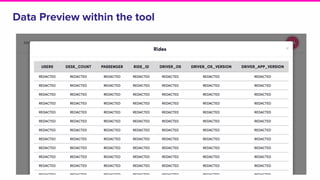

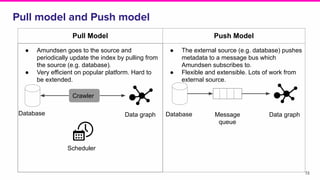



Amundsen is a metadata-driven application developed by Lyft to solve data discovery challenges. It provides a search-based UI and uses a distributed architecture with various microservices to index and serve metadata from multiple sources. Key components include a metadata service using Neo4j, a search service using Elasticsearch, and a frontend. The tool has been hugely successful at Lyft and is now open source. Future work includes expanding metadata coverage and integrating with other tools.





























![[Strata NYC 2019] Turning big data into knowledge: Managing metadata and data...](https://cdn.slidesharecdn.com/ss_thumbnails/dkpstratanyc2019presentation-191004091826-thumbnail.jpg?width=640&height=640&fit=bounds)





































