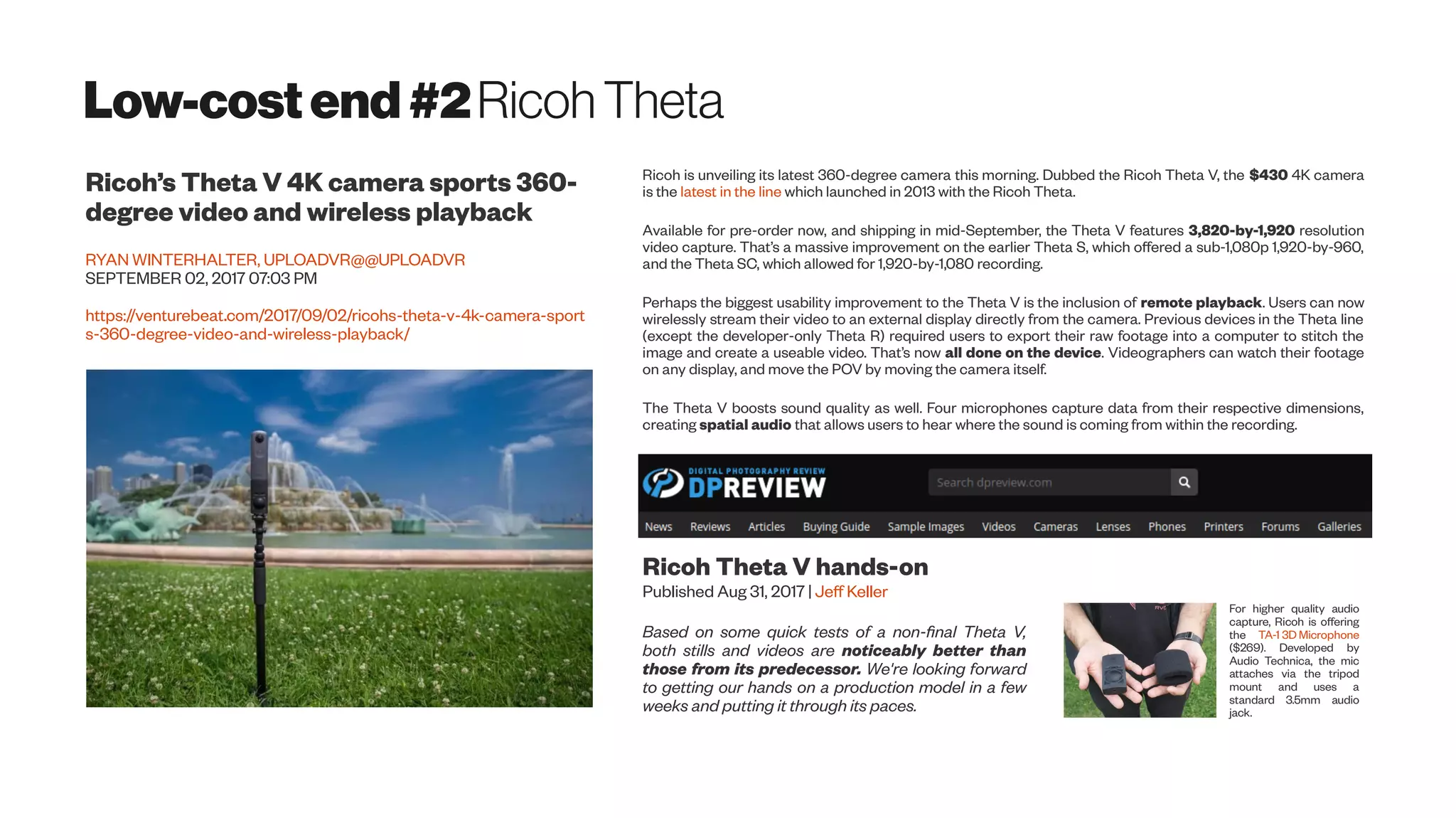
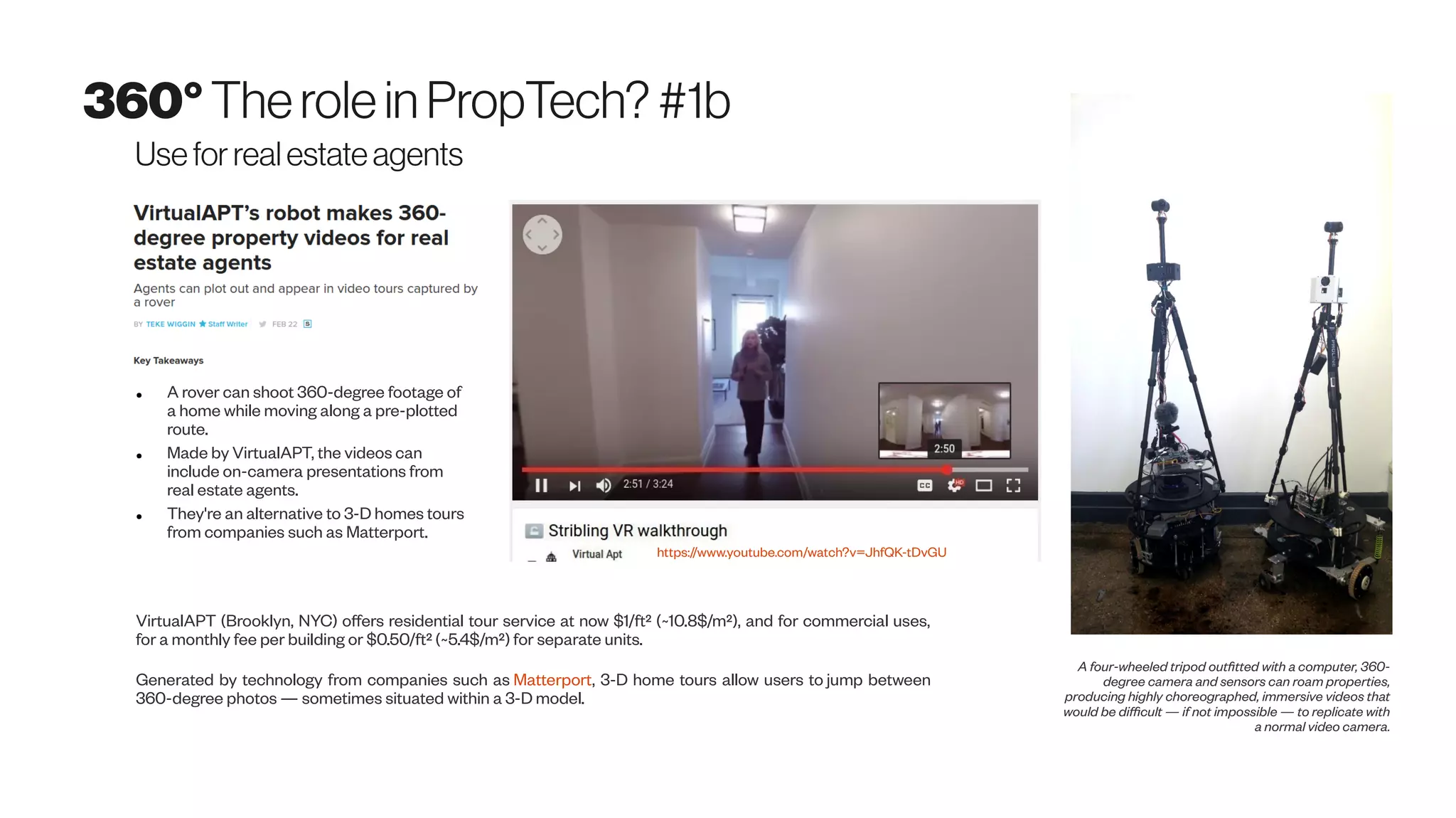
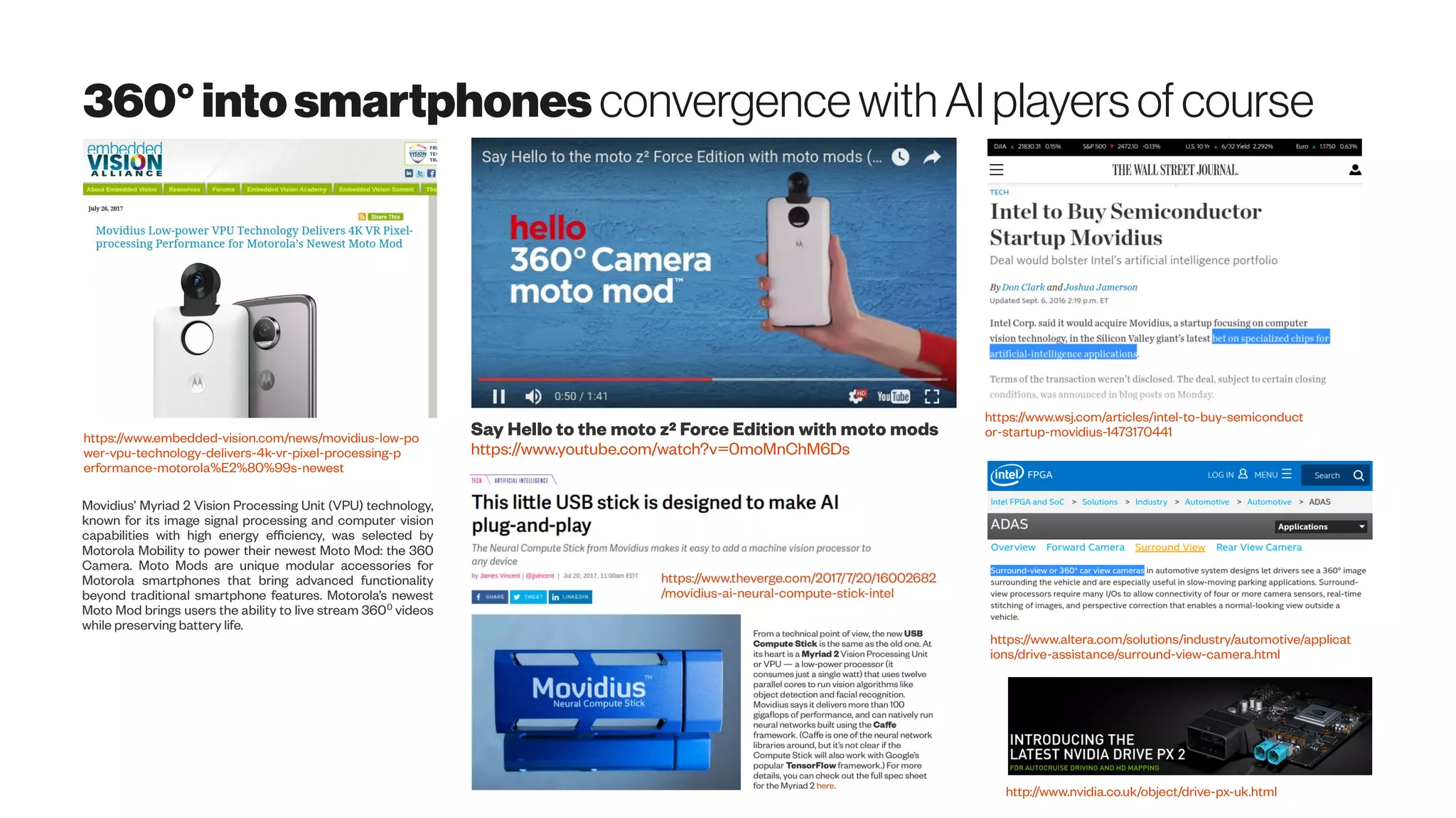
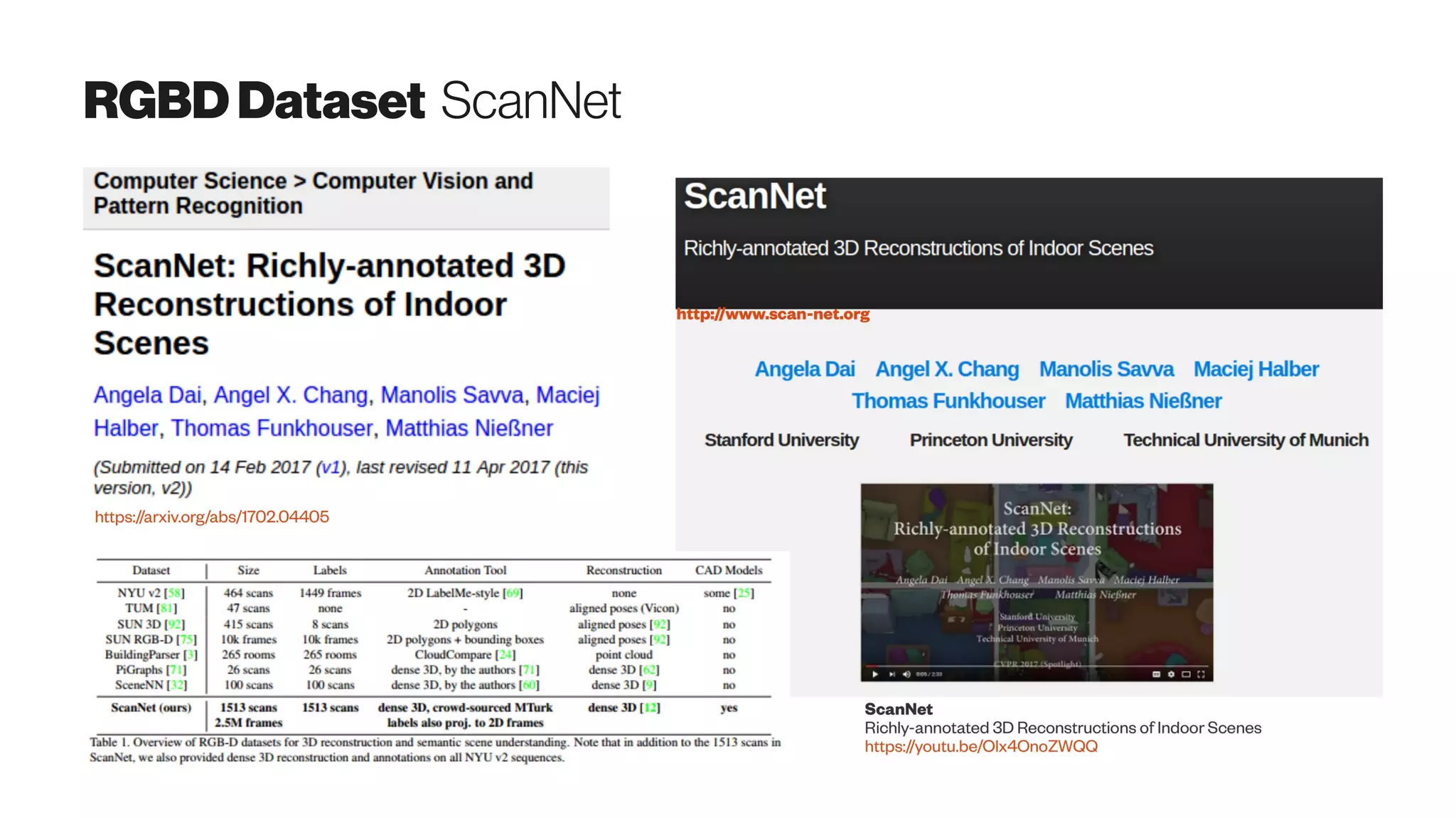
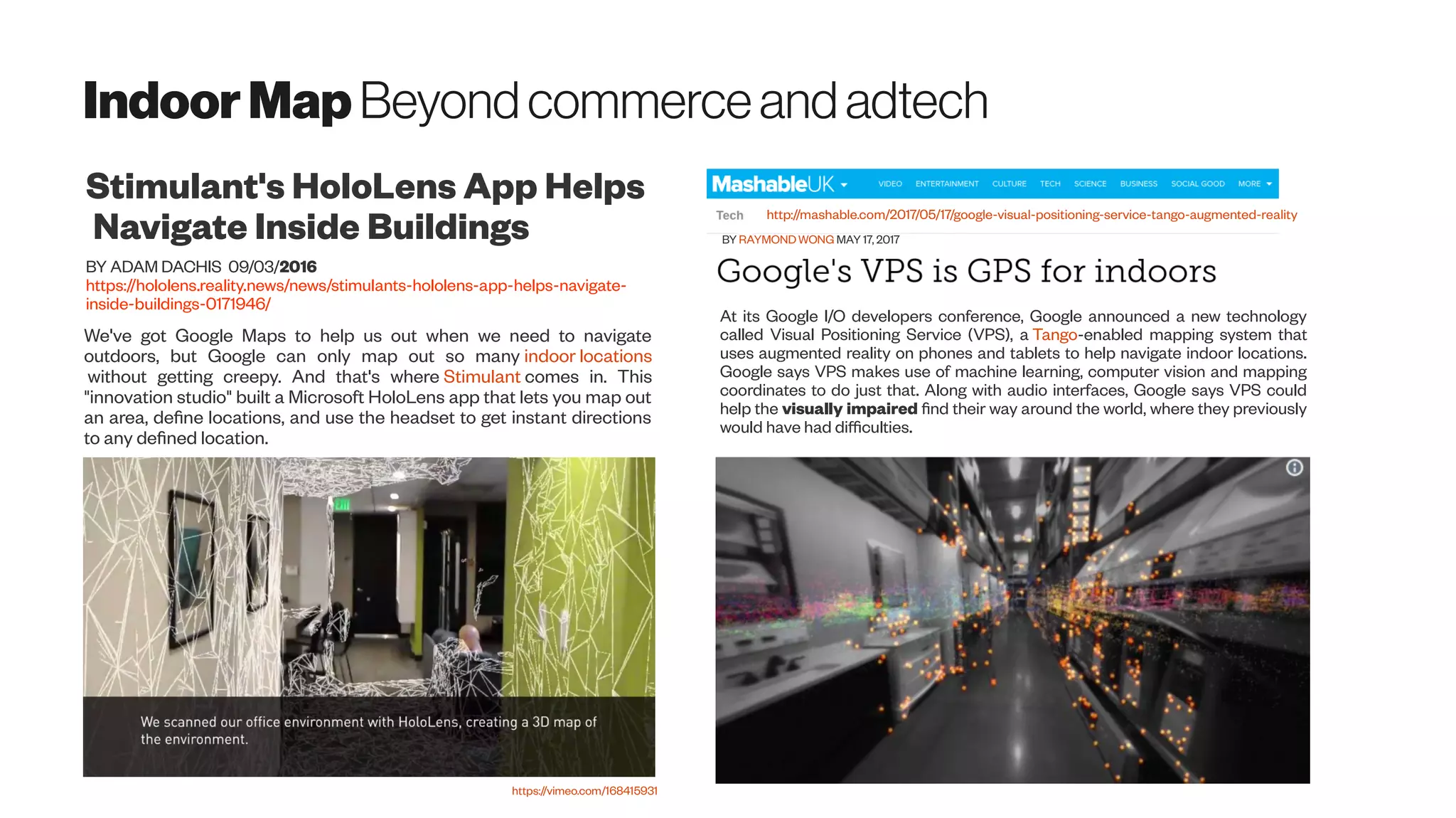
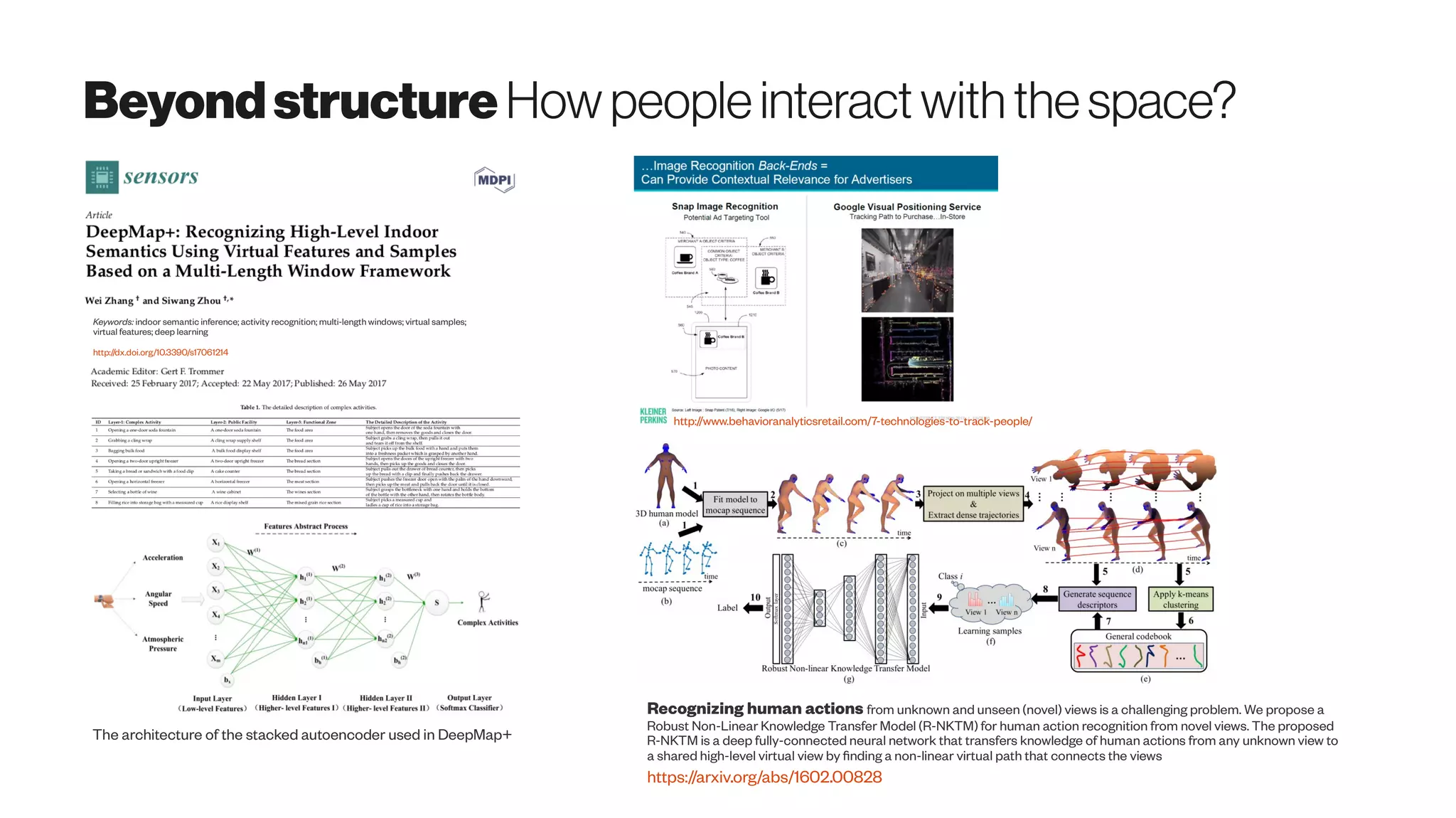
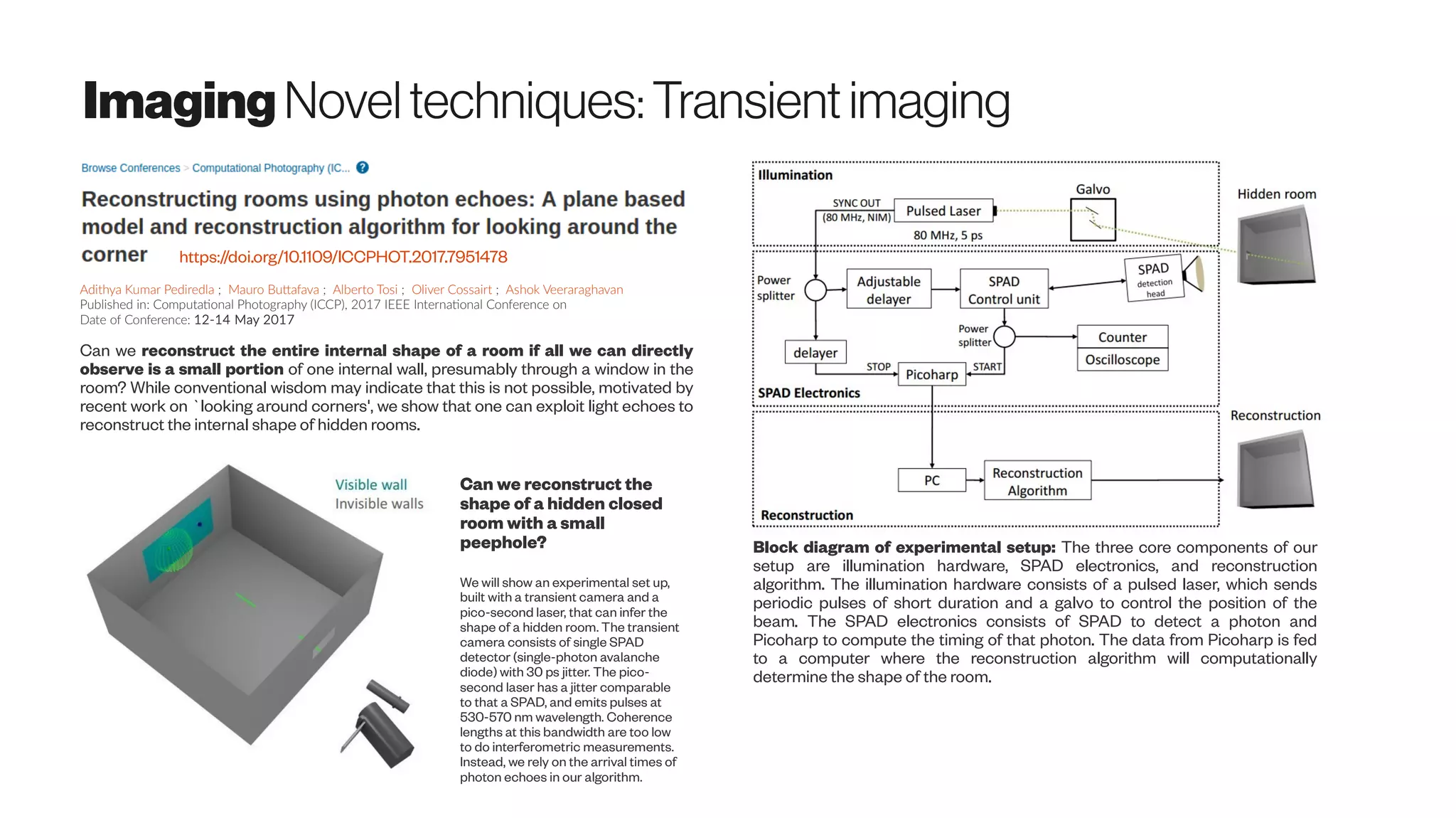
Download as PDF, PPTX








![VisualOdometry
Taketomi et al. (2017):
http://dx.doi.org/10.1186/s41074-017-0027-2
“Odometry is to estimate the sequential changes of
sensor positions over time using sensors such as
wheel encoder to acquire relative sensor movement.
Camera-based odometry called visual odometry
(VO) is also one of the active research fields in the
literature [16, 17].
From the technical point of views, vSLAM and VO
are highly relevant techniques because both
techniques basically estimate sensor positions.
According to the survey papers in robotics [18, 19],
the relationship between vSLAM and VO can be
represented as follows.
vSLAM = VO + global map optimization
The relationship between vSLAM and VO can also
be found from the papers [20, 21] and the papers [22,
23]. In the paper [20, 22], a technique on VO was first
proposed. Then, a technique on vSLAM was
proposed by adding the global optimization in VO [21,
23].”
Towards stable visual odometry & SLAM solutions
for autonomous vehicles
https://www.youtube.com/watch?v=T5Y6OPG-d08
NavStik Hackerspace | Projects at Hackerspace
Visual Odometry using Optic Flow](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-10-2048.jpg)














![360°(omnidirectionalimaging) Introduction
The Panoptic Camera platform developed
jointly by Microelectronic Systems
Laboratory (LSM) and Signal Processing
Laboratory (LTS2) of EPFL.*
http://lsm.epfl.ch/page-52820-en.html
Wikipedia: “360-degree videos, also known as immersive videos[1] or spherical videos ,[2] are video recordings where a view in every direction is recorded
at the same time, shot using an omnidirectional camera or a collection of cameras. During playback the viewer has control of the viewing direction like a
panorama.”
Consumer-level camera review
http://thewirecutter.com/reviews/best-360-degree-camera/
By DANIEL CULPANWednesday 12 August 2015
http://www.wired.co.uk/article/9-mind-blowing-360-degree-videos
Scuba Diving Short Film in 360° Green Island, Taiwan
https://youtu.be/2OzlksZBTiA](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-28-2048.jpg)


















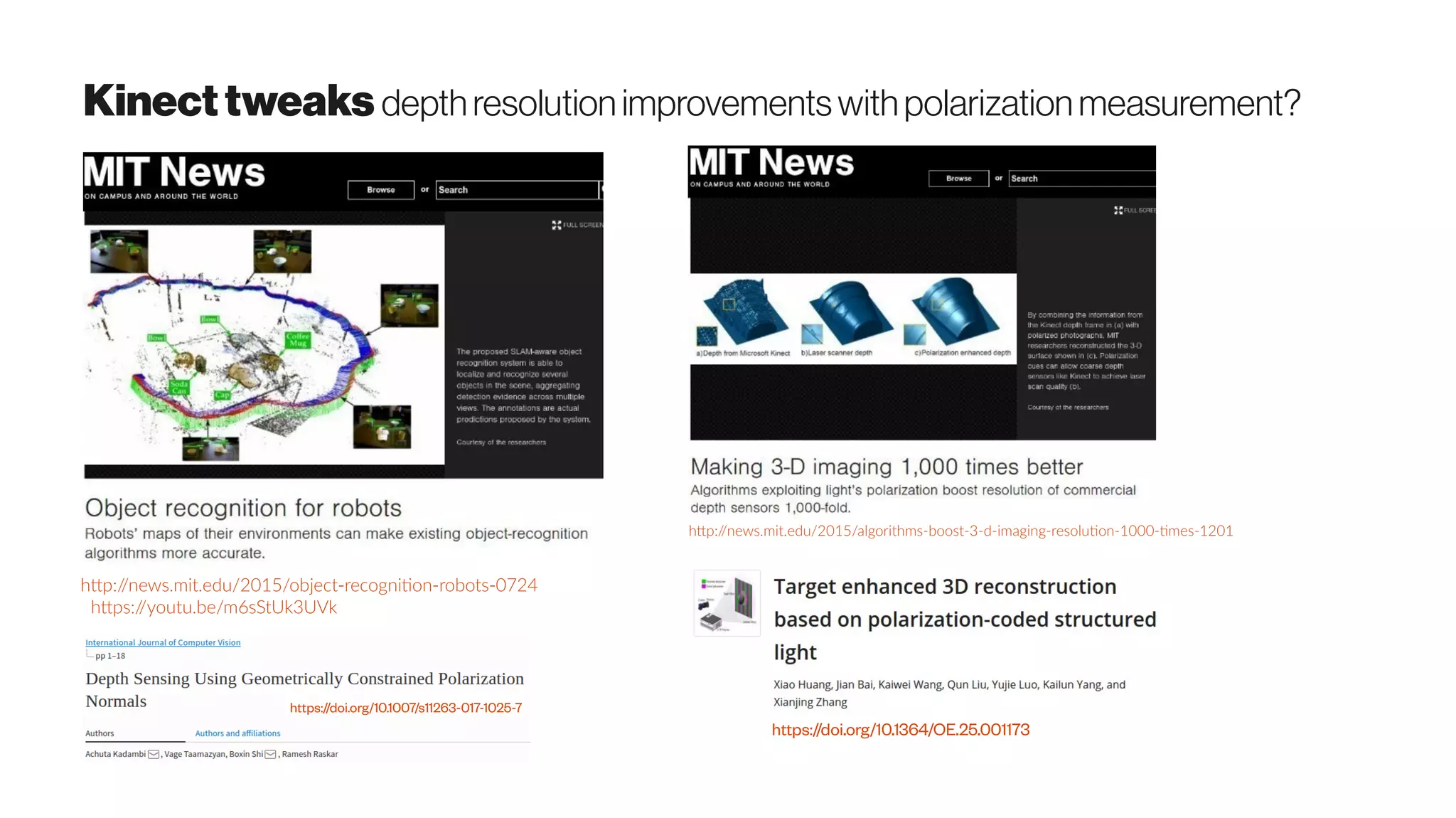
![MicrosoftKinect Democratizing structuredlightscanning
https://arxiv.org/abs/1505.05459
Structured light A sequence of known patterns is
sequentially projected onto an object, which gets
deformed by geometric shape of the object. The
object is then observed from a camera from a
different direction. By analyzing the distortion of
the observed pattern, i.e. the disparity from the
original projected pattern, depth information can
be extracted
The Time-of-Flight (ToF) technology is based on
measuring the time that light emitted by an illumination
unit requires to travel to an object and back to the sensor
array. The Kinec tToF camera applies this CW intensity
modulation approach. . Due to the distance between the
camera and the object (sensor and illumination are
assumed to be at the same location), and the finite speed
of light c, a time shift [s]φ is caused in the optical signal
which is equivalent to a phase shift in the periodic signal.
This shift is detected in each sensor pixel by a so-called
mixing process. The time shift can be easily transformed
into the sensor-object distance as the light has to travel
the distance twice,
Cited by 65 articles - see Related articles](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-50-2048.jpg)



















![DeepLearning3DFeatureDescriptors
https://arxiv.org/abs/1706.04496
We present a view-based convolutional network that produces local, point-based shape descriptors.
The network is trained such that geometrically and semantically similar points across different 3D
shapes are embedded close to each other in descriptor space (left). Our produced descriptors are
quite generic — they can be used in a variety of shape analysis applications, including dense
matching, prediction of human affordance regions, partial scan-to-shape matching, and shape
segmentation (right).
In contrast to findings in the image analysis community where learned 2D
descriptors are ubiquitous and general (e.g. LIFT), learned 3D descriptors have
not been as powerful as 2D counterparts because they (1) rely on limited training
data originating from small-scale shape databases, (2) are computed at low spatial
resolutions resulting in loss of detail sensitivity, and (3) are designed to operate on
specific shape classes, such as deformable shapes.
We generate training correspondences
automatically by leveraging highly structured
databases of consistently segmented shapes
with labeled parts. The largest such database
is the segmented ShapeNetCore dataset [
Yi et al. 2016, https://www.shapenet.org/] that
includes 17K man-made shapes distributed in
16 categories](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-83-2048.jpg)
![Meshgenerativeshapeswith GAN
https://arxiv.org/abs/1705.02090
Our key insight is that 3D shapes are effectively
characterized by their hierarchical organization of parts,
which reflects fundamental intra-shape relationships such as
adjacency and symmetry. We develop a recursive neural net
(RvNN) based autoencoder to map a flat, unlabeled, arbitrary
part layout to a compact code. The code effectively captures
hierarchical structures of man-made 3D objects of varying
structural complexities despite being fixed-dimensional: an
associated decoder maps a code back to a full hierarchy. The
learned bidirectional mapping is further tuned using an
adversarial setup to yield a generative model of plausible
structures, from which novel structures can be sampled.
It would be interesting to thoroughly investigate the effect
of code length on structure encoding. Finally, it is worth
exploring recent developments in GANs, e.g. Wasserstein
GAN [Arjovsky et al. 2017], in our problem setting. It would
also be interesting to compare with plain VAE and other
generative adaptations.](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-84-2048.jpg)




![Point-cloudsuper-resolution
Upsampling‘on-the-fly’toavoid“dataexplosion”?
Jason Schreier
4/17/17 12:05pm Horizon Zero Dawn, Kotaku
http://kotaku.com/horizon-zero-dawn-uses-all-sorts-
of-clever-tricks-to-lo-1794385026
Games like this don’t just look incredible because of ‘hyper-realism’
but because their engineers use all sorts of tricks [LOD’ing, or Level
of Detail; Mipmapping; frustum culling, etc.] to save memory.
The engine is designed to produce models in CityGML and does so in multiple
LODs. Besides the generation of multiple geometric LODs, we implement the
realisation of multiple levels of spatiosemantic coherence, geometric reference
variants, and indoor representations. The datasets produced by Random3Dcity
are suited for several applications, as we show in this paper with documented
uses. The developed engine is available under an open-source licence at Github
at http://github.com/tudelft3d/Random3Dcity
http://doi.org/10.5194/isprs-annals-IV-4-W1-51-2016
Filip Biljecki, Hugo Ledoux, Jantien Stoter
Level of detail texture filtering with dithering
and mipmaps US 5831624 A
Original Assignee 3Dfx Interactive Inc
https://www.google.com/patents/US5831624
Level-of-detail rendering: colors identify different
subdivision levels as stated in the top left corner.
Feature-Adaptive Rendering of Loop
Subdivision Surfaces on Modern GPUs
November 2014 DOI: 10.1007/s11390-014-1486-x
ManyLoDs: Parallel Many-View
Level-of-Detail Selection for Real-
Time Global Illumination
Matthias Hollander, Tobias Ritschel, Elmar Eisemann, Tamy Boubekeur
(2011) http://dx.doi.org/10.1111/j.1467-8659.2011.01982.x](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-89-2048.jpg)












![MeshCorrespondence “inPractice
You could for example had a 3D CAD model (or a whole architectural BIM model), and you would like to search for similar parts
from GrabCad, TraceParts, Thingiverse or Pinshape, and build more value on top of that for example via shape completion,
finite element analysis (FEM), generative design or manufacturability for CNC milling / 3D printing.
Learning Localized Geometric Features
Using 3D-CNN: An Application to
Manufacturability Analysis of Drilled Holes
Aditya Balu, Sambit Ghadai, Kin Gwn Lore, Gavin Young,
Adarsh Krishnamurthy, Soumik Sarkar
https://arxiv.org/abs/1612.02141
3D convolutional neural network for the classification of
whether or not a design is manufacturable [ design for
manufacturability (DFM)]. In this example, a block with
a drilled hole with specific diameter and depth is
considered.
Automated Design for Manufacturing and Supply Chain Using Geometric
Data Mining and Machine Learning
Hoefer, Michael Jeffrey Daniel. Iowa State University, Master’s thesis
https://search.proquest.com/openview/aaa80836db1abd17b6414d1f9c65349e/1
2015 14th International Conference on Computer-Aided Design and Computer Graphics (CAD/Graphics)
CAD Parts-Based Assembly Modeling by Probabilistic Reasoning
Kai-Ke Zhang ; Kai-Mo Hu ; Li-Cheng Yin ; Dong-Ming Yan ; Bin Wang, 26-28 Aug. 2015
https://doi.org/10.1109/CADGRAPHICS.2015.29](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-106-2048.jpg)














![CompressionConvergencewithartificialintelligence
http://dx.doi.org/10.1038/nature14541
Data compression and probabilistic modelling are two sides of the same coin, and Bayesian
machine-learning methods are increasingly advancing the state-of-the-art in compression. The
connection between compression and probabilistic modelling was established in the
mathematician Claude Shannon’s seminal work on the source coding theorem, which states that
the number of bits required to compress data in a lossless manner is bounded by the entropy of
the probability distribution of the data.
The link to Bayesian machine learning is that the better the probabilistic model one learns,
the higher the compression rate can be (MacKay, 2003). These models need to be flexible
and adaptive, since different kinds of sequences have very different statistical patterns (say,
Shakespeare’s plays or computer source code). It turns out that some of the world’s best
compression algorithms [for example, Sequence Memoizer (Wood et al. 2011) and PPM with
dynamic parameter updates (Steinruecken et al. 2015)] are equivalent to Bayesian non-
parametric models of sequences, and improvements to compression are being made through a
better understanding of how to learn the statistical structure of sequences.
Future advances in compression will come with advances in probabilistic machine learning,
including special compression methods for non-sequence data such as images, graphs and
other structured objects.
The key distinction between problems in which a probabilistic approach is important and
problems that can be solved using non-probabilistic machine-learning approaches is whether
uncertainty has a central role. Moreover, most conventional optimization-based machine-
learning approaches have probabilistic analogues that handle uncertainty in a more principled
manner. For example, Bayesian neural networks represent the parameter uncertainty in neural
networks (Neal, 1996), and mixture models are a probabilistic analogue for clustering methods (
MacKay, 2003).
http://dx.doi.org/10.1111/j.1467-8659.2006.00957.x
https://doi.org/10.1016/j.cag.2009.03.019
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.604.8269
Dropout is used as a
practical tool to obtain
uncertainty estimates
in large vision models and
reinforcement learning
(RL) tasks
https://arxiv.org/abs/1705.07832](https://image.slidesharecdn.com/proptechemergingscanningtech-170723012925/75/Emerging-3D-Scanning-Technologies-for-PropTech-125-2048.jpg)



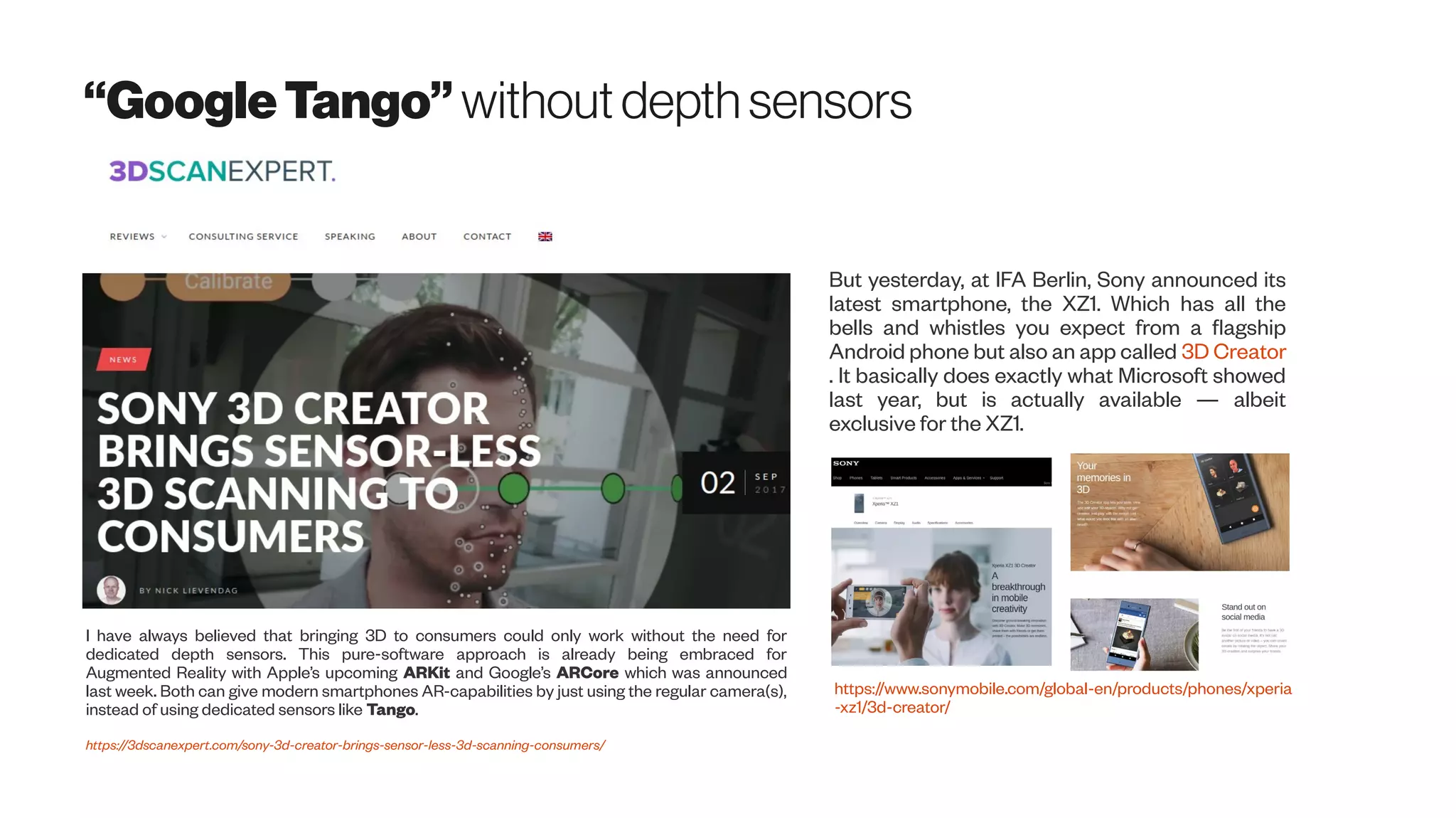
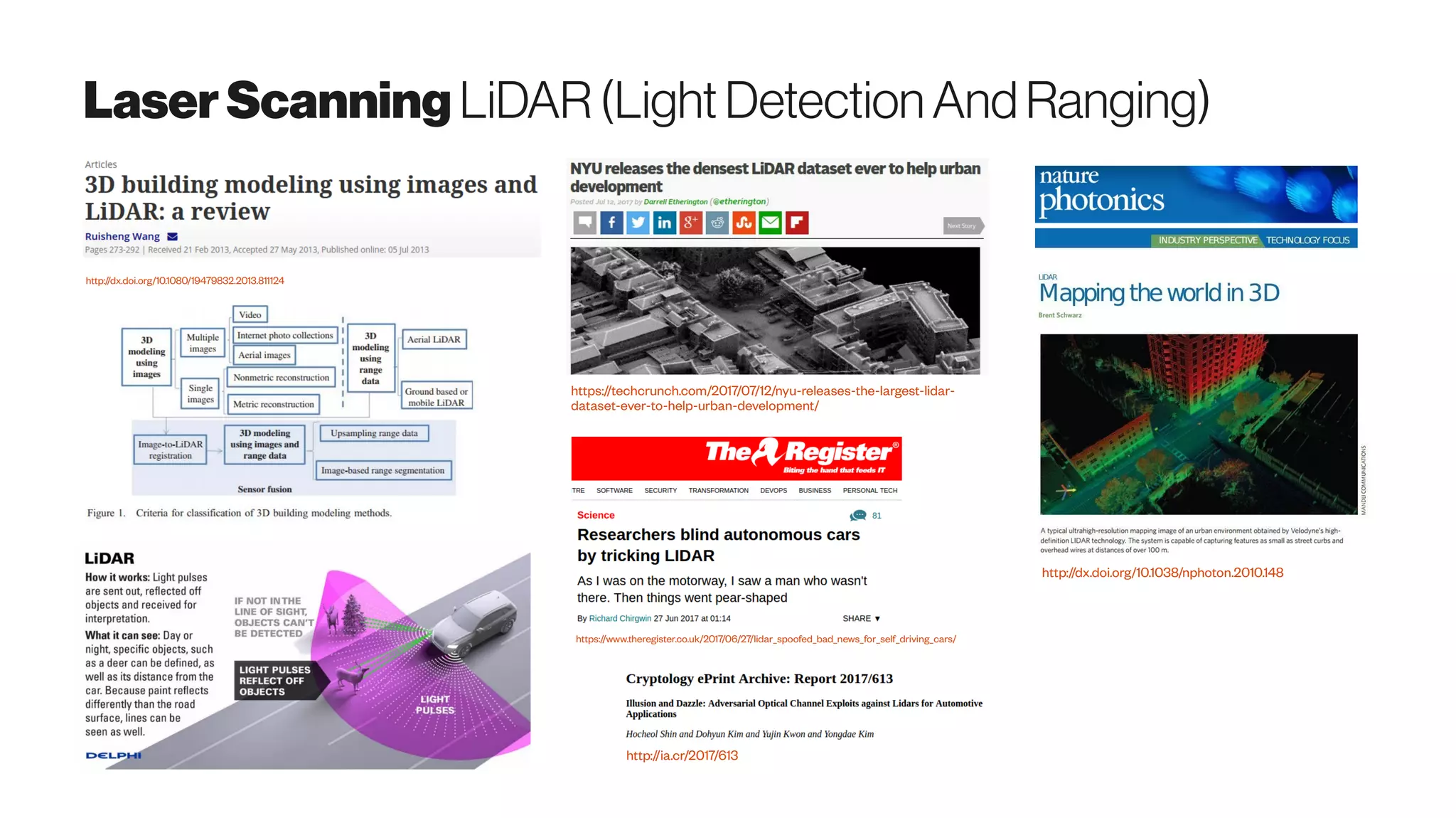
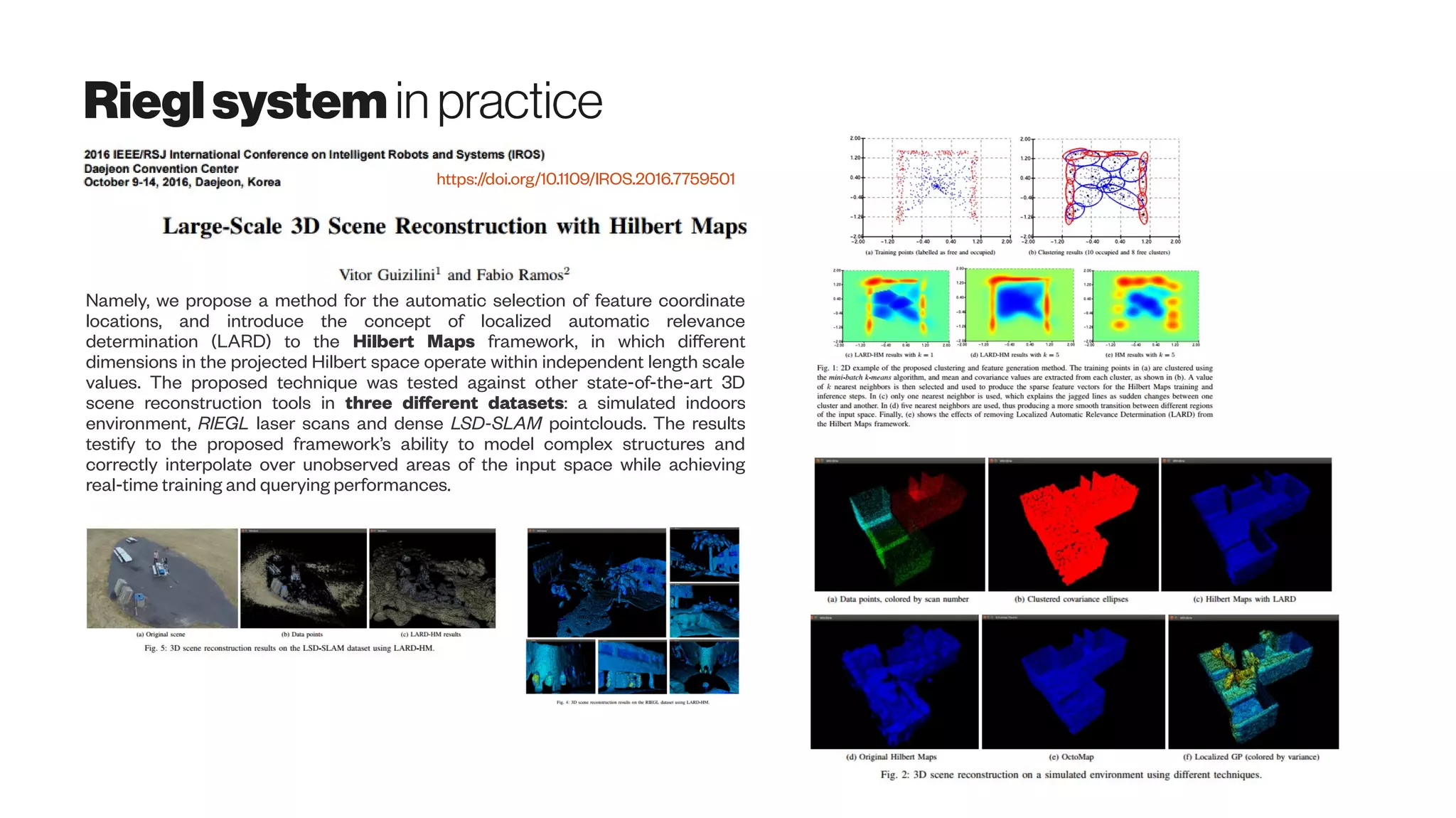
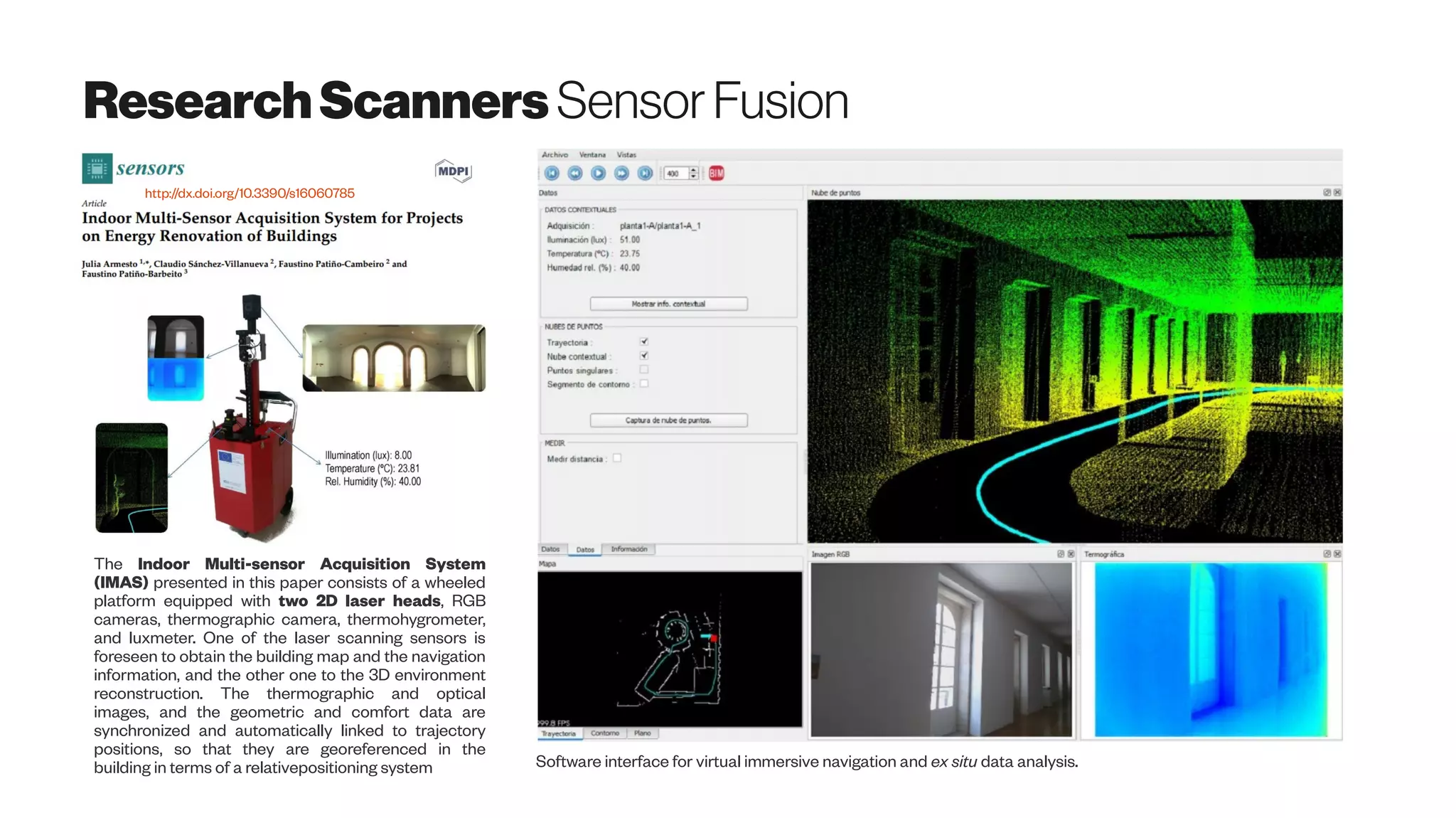
The document discusses emerging 3D scanning technologies for real estate and construction, highlighting advancements in structure from motion (SfM) and visual SLAM techniques. It covers related hardware innovations, deep learning applications for data processing, and practical tools for 3D modeling from images. Additionally, it includes resources for proptech insights and events aimed at enhancing knowledge and collaboration within the real estate technology community.






















































































