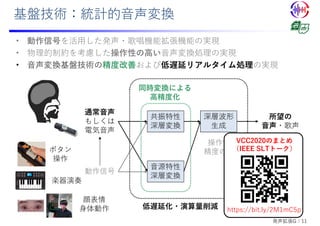
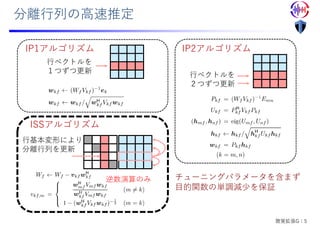
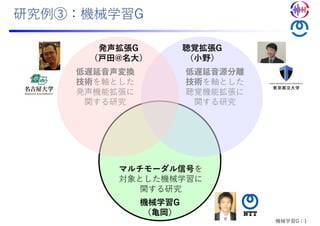
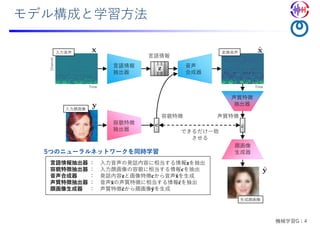
第135回音声言語情報処理研究会 招待講演 戸田 智基:CREST「共生インタラクション」共創型音メディア機能拡張プロジェクト,Feb. 2021 名古屋大学 情報学研究科 知能システム学専攻 戸田研究室











![⾝体動作を⽤いた歌唱表現制御
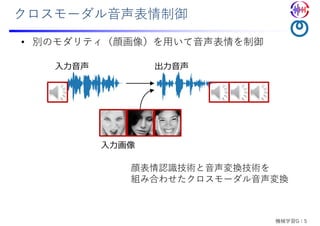
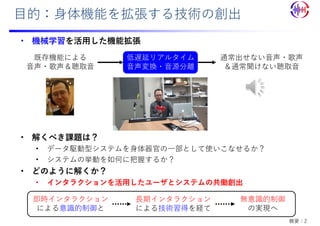
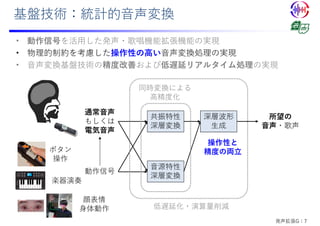
• カラオケ版歌唱⽀援システム
• 伴奏にあわせて歌唱(MIDI⾳⾼パターンは決め打ち)
• 腕の動作を利⽤したビブラート制御 [インタラクション2021にて発表予定]
発声拡張G:6](https://image.slidesharecdn.com/slidesslp20210218-210219010935/85/CREST-15-320.jpg)

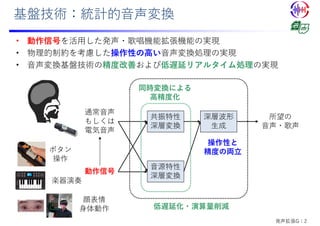
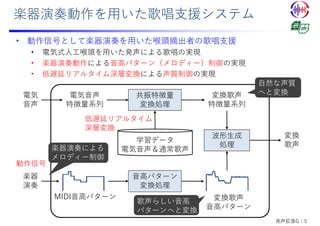
![Quasi-Periodic Parallel WaveGAN: QPPWG
• 準周期信号に特化したネットワーク構造の考案
• 基本周波数に応じてDilationサイズが動的に変化する畳み込み層
• ⾮⾃⼰回帰型ニューラルボコーダParallel WaveGAN[Yamamoto; 2020]に導⼊
雑⾳波形
F0適応型
Dilated CNNs
固定型
Dilated CNNs
⾳声波形
発声拡張G:9](https://image.slidesharecdn.com/slidesslp20210218-210219010935/85/CREST-18-320.jpg)