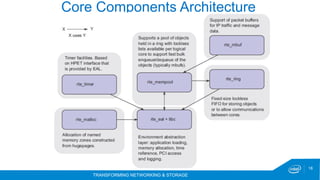
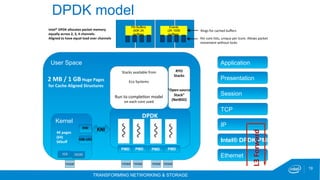
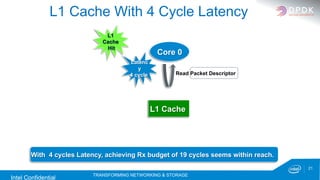
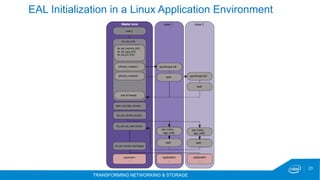
The document discusses the DPDK (Data Plane Development Kit) and its role in high-performance packet processing across multiple architectures. It covers the technology's capabilities, including optimizing cycles per packet and enhancing NFV/OVS infrastructure, as well as the performance gains achieved through various optimizations like huge pages and lockless queues. Additionally, it outlines DPDK's architecture, components, and benefits in managing network traffic efficiently.


![TRANSFORMING NETWORKING & STORAGE
2
Technology Disclaimer:
Intel technologies’ features and benefits depend on system configuration and may require enabled
hardware, software or service activation. Performance varies depending on system configuration. No
computer system can be absolutely secure. Check with your system manufacturer or retailer or learn
more at [intel.com].
Performance Disclaimers (include only the relevant ones):
Cost reduction scenarios described are intended as examples of how a given Intel- based product, in the
specified circumstances and configurations, may affect future costs and provide cost savings.
Circumstances will vary. Intel does not guarantee any costs or cost reduction.
Results have been estimated or simulated using internal Intel analysis or architecture simulation or
modeling, and provided to you for informational purposes. Any differences in your system hardware,
software or configuration may affect your actual performance.
General Disclaimer:
© Copyright 2017 Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, the Intel Inside
logo, Intel. Experience What’s Inside are trademarks of Intel. Corporation in the U.S. and/or other
countries. *Other names and brands may be claimed as the property of others.
Legal Disclaimer](https://image.slidesharecdn.com/mjaydpdkpresentationmarch12017mh-170307175759/85/DPDK-Multi-Architecture-High-Performance-Packet-Processing-2-320.jpg)


















![TRANSFORMING NETWORKING & STORAGE
43
Micro BenchMarks – The Best Kept Secret
0
100
200
300
400
500
600
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1 2 4 8 16 32 1 2 4 8 16 32 1 2 4 8 16 32 1 2 4 8 16 32 1 2 4 8 16 32 1 2 4 8 16 32
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Cycle Cost [Enqueue + Dequeue] in CPU cycles
Cycle Cost [Enqueue + Dequeue]
Single Producer/Single Consumer Multi Producer /Multi Consumer
Different Block sizes
1, 2, 4, 8, 16, 32
Bulk Enqueue /
Bulk Dequeue
Single Producer/
Single Consumer
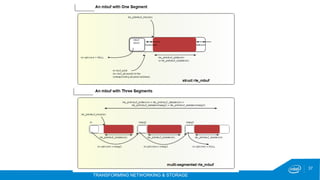
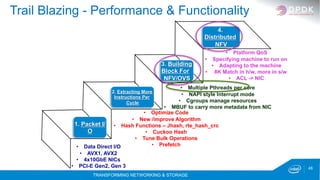
Next: 2. Extracting More Instructions Per
Cycle
1. Packet I/
O
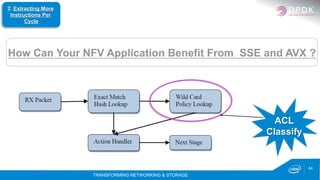
SSE – 4 Lookups in Parallel](https://image.slidesharecdn.com/mjaydpdkpresentationmarch12017mh-170307175759/85/DPDK-Multi-Architecture-High-Performance-Packet-Processing-43-320.jpg)

















































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)







![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

