Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
MLSE
13,735 views
機械学習研究の現状とこれから
日本ソフトウェア科学会 キックオフシンポジウム 基調講演2 Speaker: 杉山将(理研AIP/東京大学)
Science
◦
Read more
33
Save
Share
Embed
Embed presentation
Download
Downloaded 297 times
1
/ 29
2
/ 29
Most read
3
/ 29
4
/ 29
5
/ 29
6
/ 29
7
/ 29
8
/ 29
9
/ 29
10
/ 29
11
/ 29
12
/ 29
13
/ 29
14
/ 29
15
/ 29
16
/ 29
17
/ 29
18
/ 29
19
/ 29
20
/ 29
21
/ 29
22
/ 29
23
/ 29
24
/ 29
25
/ 29
26
/ 29
27
/ 29
28
/ 29
29
/ 29
More Related Content
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
機械学習モデルの判断根拠の説明
by
Satoshi Hara
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
マルチモーダル深層学習の研究動向
by
Koichiro Mori
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
What's hot
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
PDF
最適輸送入門
by
joisino
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
ブースティング入門
by
Retrieva inc.
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PDF
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
工学系大学4年生のための論文の読み方
by
ychtanaka
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
最適輸送入門
by
joisino
Attentionの基礎からTransformerの入門まで
by
AGIRobots
ブースティング入門
by
Retrieva inc.
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
Bayesian Neural Networks : Survey
by
tmtm otm
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
バンディットアルゴリズム入門と実践
by
智之 村上
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
Active Learning 入門
by
Shuyo Nakatani
工学系大学4年生のための論文の読み方
by
ychtanaka
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
DQNからRainbowまで 〜深層強化学習の最新動向〜
by
Jun Okumura
Transformer メタサーベイ
by
cvpaper. challenge
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
Similar to 機械学習研究の現状とこれから
PPTX
機械学習技術の現在
by
maruyama097
PPTX
プロジェクトマネージャのための機械学習工学入門
by
Nobukazu Yoshioka
PPTX
第11回 KAIM 金沢人工知能勉強会 改めて機械学習を広く浅く知る
by
tomitomi3 tomitomi3
PDF
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PDF
「人工知能」をあなたのビジネスで活用するには
by
Takahiro Kubo
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PPTX
機械学習でなにしたいの?
by
Keita Neriai
PPTX
エンタープライズと機械学習技術
by
maruyama097
PDF
Toward Research that Matters
by
Ryohei Fujimaki
PDF
バイオサイエンス分野における機械学習応用研究の最新動向
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
PPTX
機械学習 - MNIST の次のステップ
by
Daiyu Hatakeyama
PPTX
機械学習の基礎
by
Ken Kumagai
PPTX
機械学習
by
Song Yeongjin
PDF
機械学習工学と機械学習応用システムの開発@SmartSEセミナー(2021/3/30)
by
Nobukazu Yoshioka
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
PDF
【初学者向け】AI・機械学習・深層学習の概観と深層学習による暗号通貨価格予測トライアル
by
Masaharu Kinoshita
PDF
機械学習の全般について
by
Masato Nakai
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
研究・企業・生き方について 情報科学若手の会2011
by
Preferred Networks
PPTX
Machine learning
by
TakahiroBaba3
機械学習技術の現在
by
maruyama097
プロジェクトマネージャのための機械学習工学入門
by
Nobukazu Yoshioka
第11回 KAIM 金沢人工知能勉強会 改めて機械学習を広く浅く知る
by
tomitomi3 tomitomi3
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
「人工知能」をあなたのビジネスで活用するには
by
Takahiro Kubo
1028 TECH & BRIDGE MEETING
by
健司 亀本
機械学習でなにしたいの?
by
Keita Neriai
エンタープライズと機械学習技術
by
maruyama097
Toward Research that Matters
by
Ryohei Fujimaki
バイオサイエンス分野における機械学習応用研究の最新動向
by
ハイシンク創研 / Laboratory of Hi-Think Corporation
機械学習 - MNIST の次のステップ
by
Daiyu Hatakeyama
機械学習の基礎
by
Ken Kumagai
機械学習
by
Song Yeongjin
機械学習工学と機械学習応用システムの開発@SmartSEセミナー(2021/3/30)
by
Nobukazu Yoshioka
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
【初学者向け】AI・機械学習・深層学習の概観と深層学習による暗号通貨価格予測トライアル
by
Masaharu Kinoshita
機械学習の全般について
by
Masato Nakai
機械学習の理論と実践
by
Preferred Networks
研究・企業・生き方について 情報科学若手の会2011
by
Preferred Networks
Machine learning
by
TakahiroBaba3
More from MLSE
PDF
『鼎談:新しいプログラミングパラダイムとしての深層学習』 資料(萩谷 昌己)
by
MLSE
PDF
K. Czarnecki and R. Salay, Towards a Framework to Manage Perceptual Uncertain...
by
MLSE
PDF
Jsai2018
by
MLSE
PDF
深層学習の品質保証
by
MLSE
PDF
ソフトウェア工学は機械学習の夢を見るか ー ソフトウェア工学の振り返りとアーキテクト的観点からの問題提起
by
MLSE
PDF
ソフトウェア工学における問題提起と機械学習の新たなあり方
by
MLSE
PDF
開催の辞
by
MLSE
PDF
機械学習工学への期待〜機械学習が工学となるために〜
by
MLSE
『鼎談:新しいプログラミングパラダイムとしての深層学習』 資料(萩谷 昌己)
by
MLSE
K. Czarnecki and R. Salay, Towards a Framework to Manage Perceptual Uncertain...
by
MLSE
Jsai2018
by
MLSE
深層学習の品質保証
by
MLSE
ソフトウェア工学は機械学習の夢を見るか ー ソフトウェア工学の振り返りとアーキテクト的観点からの問題提起
by
MLSE
ソフトウェア工学における問題提起と機械学習の新たなあり方
by
MLSE
開催の辞
by
MLSE
機械学習工学への期待〜機械学習が工学となるために〜
by
MLSE
機械学習研究の現状とこれから
1.
2018年5月17日 機械学習研究の 現状とこれから 機械学習研究の 現状とこれから 理化学研究所 革新知能統合研究センター 東京大学 大学院新領域創成科学研究科 杉山
将 日本ソフトウェア科学会 機械学習工学研究会
2.
2 自己紹介 現職: 理化学研究所・センター長:研究者とともに 東京大学・教授:学生とともに
企業・技術顧問:エンジニアとともに 専門分野: 機械学習の理論・アルゴリズム開発 機械学習の実世界応用 (音声,画像,言語,脳波,ロボット, 自動車,光学,広告,医療,生命など)
3.
機械学習の国際会議の動向 参加者数が激増: ICML:
International Conference on Machine Learning NIPS: Neural Information Processing Systems 企業のスポンサーも非常に活発: 00年代前半:アメリカのIT企業(Google, IBM, Yahoo, Microsoft...) 00年代後半:世界中のIT企業 (Amazon, Facebook, Linkedin, Tencent, Baidu, Huawei, Yandex…) 10年代:製造・金融など様々な業種のスタートアップ~大企業 3 2013 2014 2015 2016 2017 ICML 900 1200 1600 3000+ 2400 (Sydney) NIPS 1200 2400 3800 6000+ 7500+ (California)
4.
ICML2016の採択論文の分布 4 アメリカ 企業 .com フランス イギリス イスラエル スイス 日本(10件≒3%) ドイツ
カナダ • アメリカ一強 (多数の中・韓・印・欧を含む) • 日本人は非常に少ない • 中国が猛烈な勢いで追い上げ
5.
機械学習研究の現状と課題 現状の機械学習によって, 音声認識,画像理解,言語翻訳 などはヒトと同等以上の性能を達成 しかし,更なる飛躍には課題がある: 機械学習技術の研究開発に多大なコスト: 世界中の企業が研究者・技術者を青田買い
ビッグデータの収集に多大なコスト: ネットからビッグデータが取れない問題は, 現状の機械学習技術では精度が悪い 様々な規制がネック: 個人情報保護,倫理規定・・・ 5
6.
講演の流れ 1. 機械学習技術の研究開発に多大なコスト 2. ビッグデータの収集に多大なコスト 3.
まとめと今後の展望 6
7.
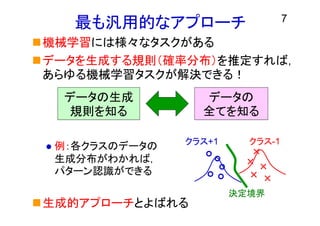
7 最も汎用的なアプローチ 機械学習には様々なタスクがある データを生成する規則(確率分布)を推定すれば, あらゆる機械学習タスクが解決できる! 例:各クラスのデータの 生成分布がわかれば, パターン認識ができる 生成的アプローチとよばれる 決定境界 クラス+1 クラス-1 データの生成 規則を知る データの 全てを知る
8.
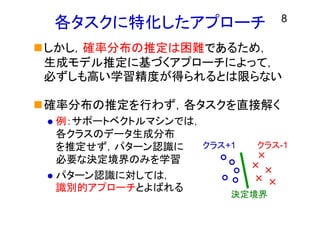
各タスクに特化したアプローチ しかし,確率分布の推定は困難であるため, 生成モデル推定に基づくアプローチによって, 必ずしも高い学習精度が得られるとは限らない 確率分布の推定を行わず,各タスクを直接解く 例:サポートベクトルマシンでは, 各クラスのデータ生成分布 を推定せず,パターン認識に 必要な決定境界のみを学習 パターン認識に対しては, 識別的アプローチとよばれる 8 クラス+1
クラス-1 決定境界
9.
各タスクに特化したアプローチ 各タスクに特化したアルゴリズムを 開発した方が,原理的には 生成的アプローチよりも性能が良い しかし,様々なタスクに対して個別に 研究開発を行うのは大変: アルゴリズム考案 理論的性能評価
高速かつメモリ効率の良い実装 エンジニアの技術習得 9
10.
中間的なアプローチ あるクラスのタスク群に対して,研究開発を行う 汎用性と有効性のトレードオフを取る 10 生成的アプローチ 中間アプローチ
タスク特化アプローチ
11.
11 確率密度比に基づく機械学習 多くの機械学習タスク群は 複数の確率分布を含む しかし,これらのタスクを解くのに,それぞれ の確率分布そのものは必要ない 確率密度関数の比が分かれば十分である 各確率分布は推定せず, 密度比を直接推定する r(x) = p(x) q(x) 非定常環境下での適応学習,ドメイン適応, マルチタスク学習,二標本検定,異常値検出, 変化点検知,クラスバランス推定,相互情報 量推定,独立性検定,特徴選択,十分次元削 減,独立成分分析,因果推論,クラスタリング, オブジェクト適合,条件付き確率推定,確率的 パターン認識 Sugiyama, Suzuki
& Kanamori, Density Ratio Estimation in Machine Learning, Cambridge University Press, 2012
12.
12 最小二乗密度比適合 データ: , 真の密度比 との二乗誤差を最小にする ように密度比モデル
を学習: Kanamori, Hido & Sugiyama (JMLR2009) r(x) min ® J(®) J(®) = 1 2 r®(x) ¡ r(x) 2 q(x)dx r(x) = p(x) q(x) fxq j g nq j=1 i:i:d: » q(x)fxp i g np i=1 i:i:d: » p(x)
13.
ここまでのまとめ 密度比は,単純な最小二乗法で最適推定できる 多くの学習タスクが実は最小二乗法で解ける: 重点サンプリング: ダイバージェンス推定:
相互情報量推定: 条件付き確率推定: 各機械学習タスクを直接解くのではなく,抽象化 したタスクの集合に対する解法を開発する 13
14.
講演の流れ 1. 機械学習技術の研究開発に多大なコスト: 密度比推定の理論と応用 2. ビッグデータの収集に多大なコスト: 限られた情報からの機械学習 3.
まとめと今後の展望 14
15.
ビッグデータを用いた機械学習 画像認識,音声認識,機械翻訳などで, 人間と同等かそれ以上の性能を達成 しかし,応用分野によっては, 教師付きビッグデータを簡単に取れない 医療データ解析 インフラの管理
自然災害の防災・減災 機能材料の開発 限られた情報からの学習が重要! 15
16.
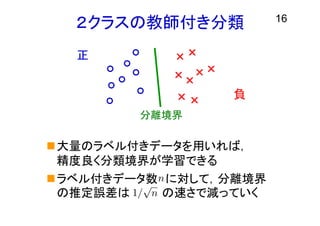
2クラスの教師付き分類 大量のラベル付きデータを用いれば, 精度良く分類境界が学習できる ラベル付きデータ数 に対して,分離境界 の推定誤差は の速さで減っていく 16 正 負 分離境界
17.
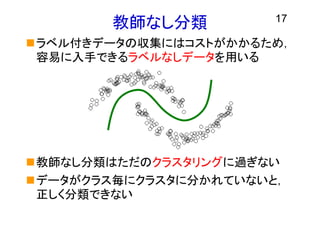
教師なし分類 17 ラベル付きデータの収集にはコストがかかるため, 容易に入手できるラベルなしデータを用いる 教師なし分類はただのクラスタリングに過ぎない データがクラス毎にクラスタに分かれていないと, 正しく分類できない
18.
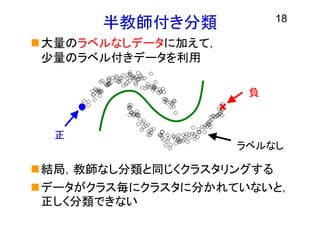
半教師付き分類 大量のラベルなしデータに加えて, 少量のラベル付きデータを利用 結局,教師なし分類と同じくクラスタリングする データがクラス毎にクラスタに分かれていないと, 正しく分類できない 18 正 負 ラベルなし
19.
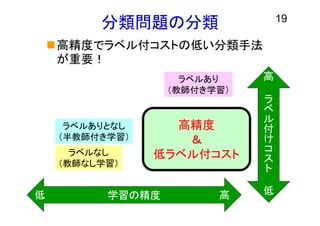
分類問題の分類 19 高精度でラベル付コストの低い分類手法 が重要! ラベルあり (教師付き学習) ラベルなし (教師なし学習) ラベルありとなし (半教師付き学習) ラ ベ ル 付 け コ ス ト 高 低学習の精度 高 高低 高精度 & 低ラベル付コスト
20.
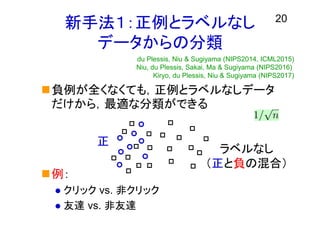
新手法1:正例とラベルなし データからの分類 20 負例が全くなくても,正例とラベルなしデータ だけから,最適な分類ができる 例: クリック vs.
非クリック 友達 vs. 非友達 正 ラベルなし (正と負の混合) du Plessis, Niu & Sugiyama (NIPS2014, ICML2015) Niu, du Plessis, Sakai, Ma & Sugiyama (NIPS2016) Kiryo, du Plessis, Niu & Sugiyama (NIPS2017)
21.
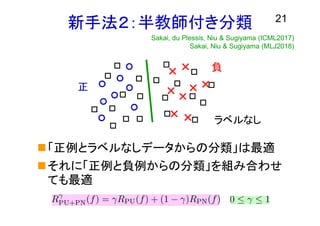
新手法2:半教師付き分類 21 「正例とラベルなしデータからの分類」は最適 それに「正例と負例からの分類」を組み合わせ ても最適 正 負 ラベルなし Sakai, du
Plessis, Niu & Sugiyama (ICML2017) Sakai, Niu & Sugiyama (MLJ2018)
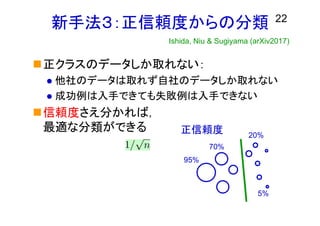
22.
新手法3:正信頼度からの分類 正クラスのデータしか取れない: 他社のデータは取れず自社のデータしか取れない 成功例は入手できても失敗例は入手できない 信頼度さえ分かれば, 最適な分類ができる 22 Ishida,
Niu & Sugiyama (arXiv2017) 正信頼度 95% 70% 5% 20%
23.
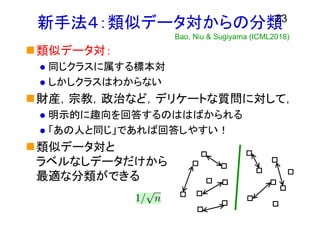
新手法4:類似データ対からの分類 類似データ対: 同じクラスに属する標本対 しかしクラスはわからない 財産,宗教,政治など,デリケートな質問に対して,
明示的に趣向を回答するのははばかられる 「あの人と同じ」であれば回答しやすい! 類似データ対と ラベルなしデータだけから 最適な分類ができる 23 Bao, Niu & Sugiyama (ICML2018)
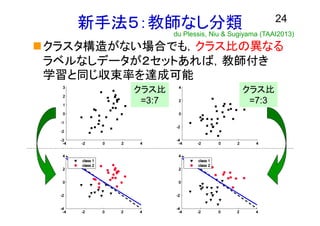
24.
新手法5:教師なし分類 24 クラスタ構造がない場合でも,クラス比の異なる ラベルなしデータが2セットあれば,教師付き 学習と同じ収束率を達成可能 クラス比 =3:7 クラス比 =7:3 du Plessis,
Niu & Sugiyama (TAAI2013)
25.
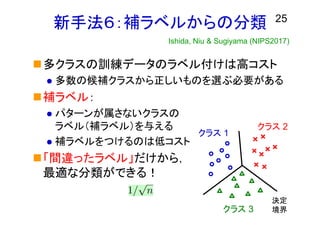
新手法6:補ラベルからの分類 多クラスの訓練データのラベル付けは高コスト 多数の候補クラスから正しいものを選ぶ必要がある 補ラベル: パターンが属さないクラスの ラベル(補ラベル)を与える
補ラベルをつけるのは低コスト 「間違ったラベル」だけから, 最適な分類ができる! 25 Ishida, Niu & Sugiyama (NIPS2017) クラス 1 クラス 2 決定 境界クラス 3
26.
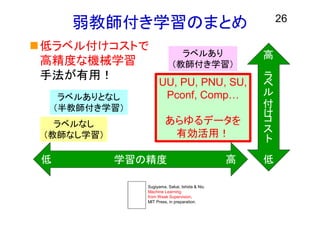
弱教師付き学習のまとめ 低ラベル付けコストで 高精度な機械学習 手法が有用! 26 UU, PU, PNU,
SU, Pconf, Comp… あらゆるデータを 有効活用! ラベルあり (教師付き学習) ラベルなし (教師なし学習) ラベルありとなし (半教師付き学習) 高 低学習の精度 高 高低 Sugiyama, Sakai, Ishida & Niu Machine Learning from Weak Supervision, MIT Press, in preparation. ラ ベ ル 付 け コ ス ト
27.
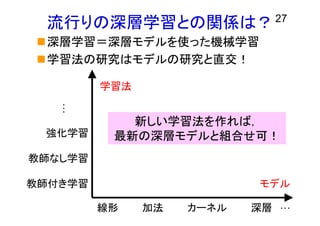
流行りの深層学習との関係は? 深層学習=深層モデルを使った機械学習 学習法の研究はモデルの研究と直交! 27 線形 カーネル 深層
… モデル 加法 教師付き学習 教師なし学習 … 強化学習 学習法 新しい学習法を作れば, 最新の深層モデルと組合せ可!
28.
講演の流れ 1. 機械学習技術の研究開発に多大なコスト: 密度比推定の理論と応用 2. ビッグデータの収集に多大なコスト: 限られた情報からの機械学習 3.
まとめと今後の展望 28
29.
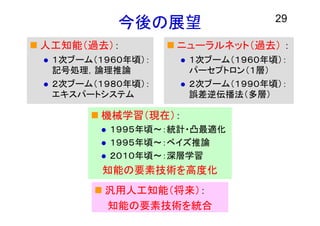
今後の展望 人工知能(過去): 1次ブーム(1960年頃): 記号処理,論理推論
2次ブーム(1980年頃): エキスパートシステム ニューラルネット(過去) : 1次ブーム(1960年頃): パーセプトロン(1層) 2次ブーム(1990年頃): 誤差逆伝播法(多層) 29 機械学習(現在): 1995年頃~:統計・凸最適化 1995年頃~:ベイズ推論 2010年頃~:深層学習 知能の要素技術を高度化 汎用人工知能(将来): 知能の要素技術を統合
Download















![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)










![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)



























