Downloaded 37 times












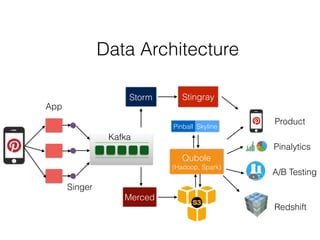


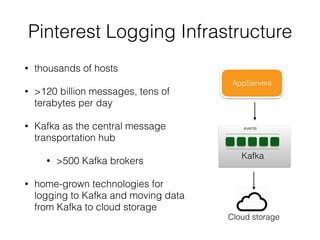
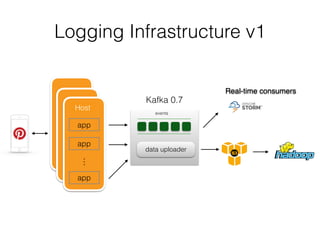


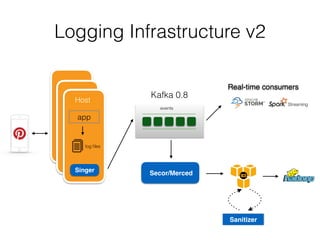


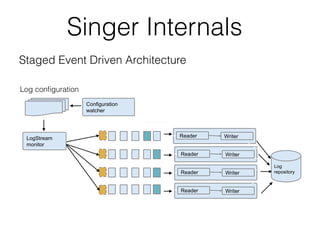


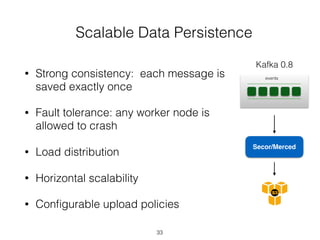
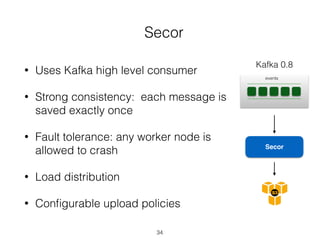

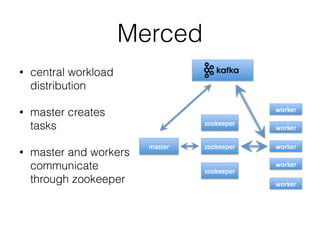



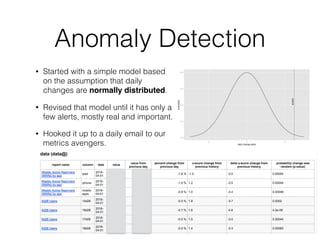






Pinterest uses Kafka as the central logging system to collect over 120 billion messages per day from thousands of hosts. They developed Singer, a lightweight logging agent, to reliably upload application logs to Kafka with low latency. Data is then moved from Kafka to cloud storage using systems like Secor and Merced that ensure exactly-once processing. Maintaining high log quality requires monitoring for anomalies, auditing new features, and catching issues both before and after releases through automated tooling.



























































![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)







