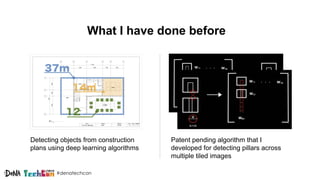
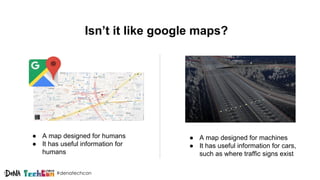
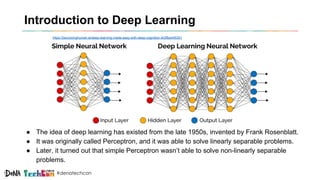
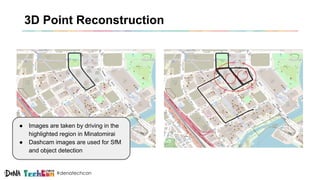
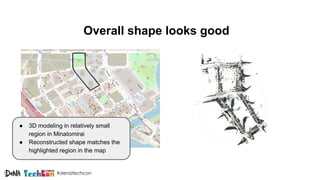
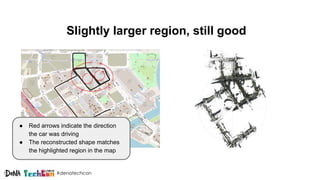
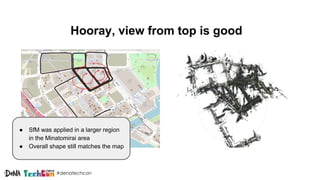
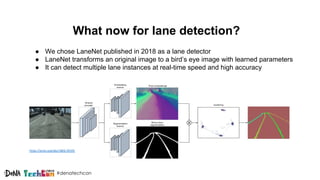
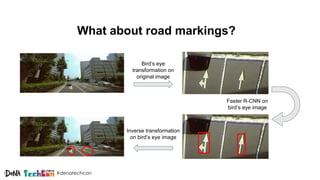
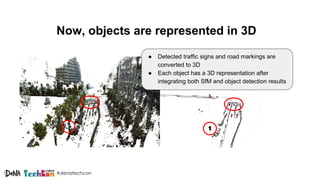
Kosuke Kuzuoka from Dena Co., Ltd. discusses the creation of high-definition maps using dashcam images through deep learning techniques, particularly focused on 3D point reconstruction and object detection. The process involves utilizing structure from motion (SfM) algorithms and object detection methods like Faster R-CNN to accurately map traffic signs and road markings in a cost-effective manner without expensive equipment like LiDAR. The integration of these techniques enables the development of detailed 3D representations that can improve localization and path planning for self-driving cars.



































![[Gree] グリーのソーシャルゲームにおける機械学習活用事例](https://cdn.slidesharecdn.com/ss_thumbnails/gree-170929124211-thumbnail.jpg?width=640&height=640&fit=bounds)










![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [TS2] 自律移動ロボットのためのロボットビジョン〜 オープンソースの自動運転ソフトAutowareを解説 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2ssii2022r4-220607054405-1c6b5fc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep Anomaly Detection Using Geometric Transformations](https://cdn.slidesharecdn.com/ss_thumbnails/deepanomalydetectionusinggeometrictransformations-190329122109-thumbnail.jpg?width=640&height=640&fit=bounds)







































