Downloaded 210 times








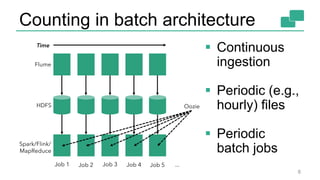

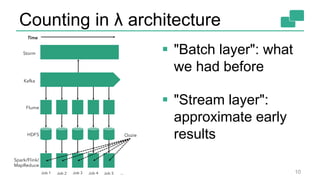

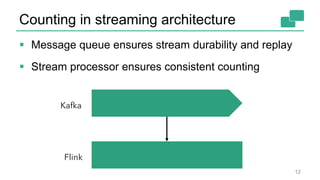

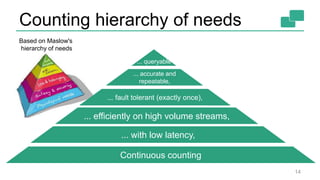

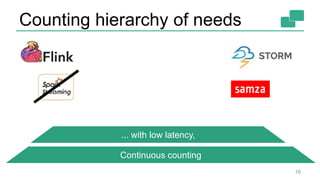
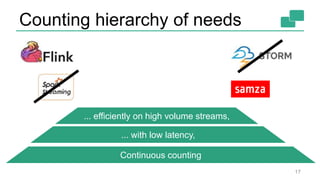
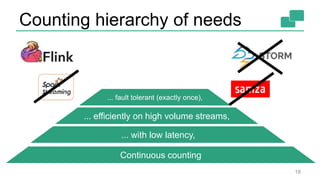
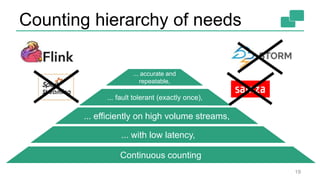


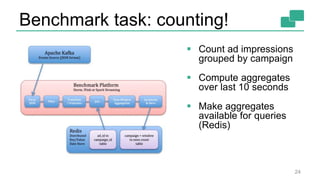
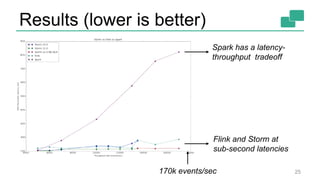


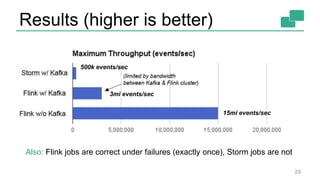
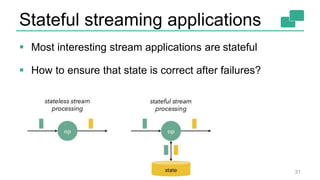


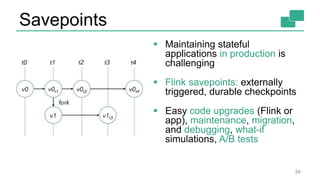
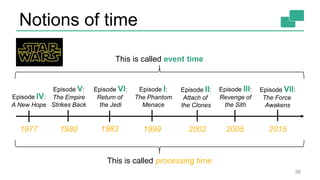
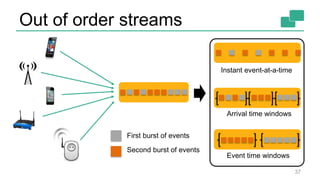




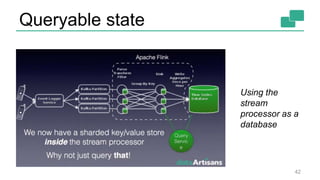

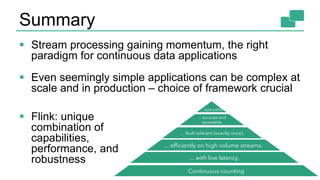



This document discusses continuous counting on data streams using Apache Flink. It begins by introducing streaming data and how counting is an important but challenging problem. It then discusses issues with batch-oriented and lambda architectures for counting. The document presents Flink's streaming architecture and DataStream API as solutions. It discusses requirements for low-latency, high-efficiency counting on streams, as well as fault tolerance, accuracy, and queryability. Benchmark results show Flink achieving sub-second latencies and high throughput. The document closes by overviewing upcoming features in Flink like SQL and dynamic scaling.



































































