Download to read offline










![INTRODUCTION HOPSWORKS DISTRIBUTED DEEP LEARNING PARALLEL BLACK-BOX OPTIMIZATION SUMMARY
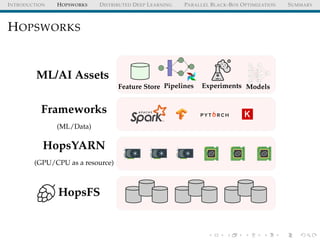
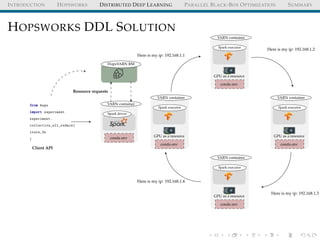
HOPSWORKS
HopsFS
HopsYARN
(GPU/CPU as a resource)
Frameworks
(ML/Data)
Feature Store Pipelines Experiments Models
b0
x0,1
x0,2
x0,3
b1
x1,1
x1,2
x1,3
ˆy
ML/AI Assets
from hops import featurestore
from hops import experiment
featurestore.get_features([
"average_attendance",
"average_player_age"])
experiment.collective_all_reduce(features , model)
APIs](https://image.slidesharecdn.com/distributeddeeplearningwithhopsworkskimhammar25april2019-190426160258/85/Distributed-deep-learning_with_hopsworks_kim_hammar_25_april_2019-17-320.jpg)
![INTRODUCTION HOPSWORKS DISTRIBUTED DEEP LEARNING PARALLEL BLACK-BOX OPTIMIZATION SUMMARY
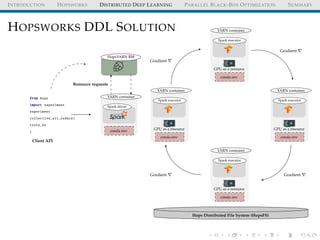
HOPSWORKS
HopsFS
HopsYARN
(GPU/CPU as a resource)
Frameworks
(ML/Data)
Distributed Metadata
(Available from REST API)
Feature Store Pipelines Experiments Models
b0
x0,1
x0,2
x0,3
b1
x1,1
x1,2
x1,3
ˆy
ML/AI Assets
from hops import featurestore
from hops import experiment
featurestore.get_features([
"average_attendance",
"average_player_age"])
experiment.collective_all_reduce(features , model)
APIs](https://image.slidesharecdn.com/distributeddeeplearningwithhopsworkskimhammar25april2019-190426160258/85/Distributed-deep-learning_with_hopsworks_kim_hammar_25_april_2019-18-320.jpg)



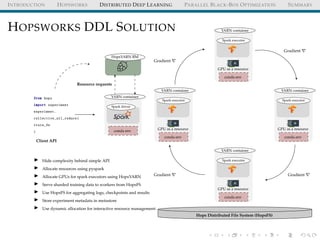




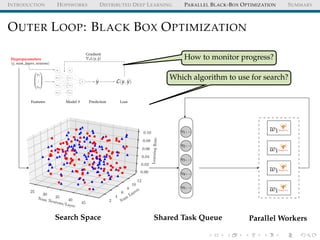
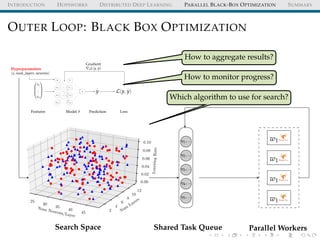
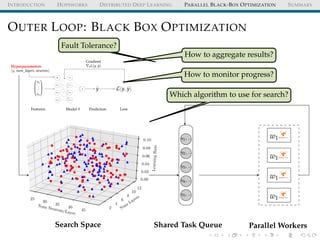
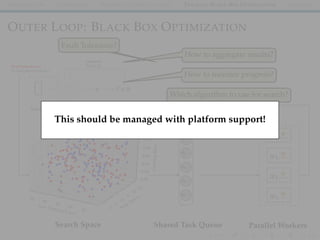







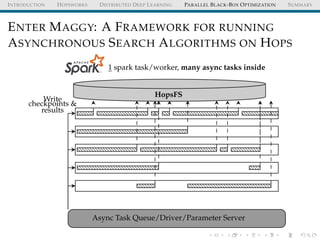
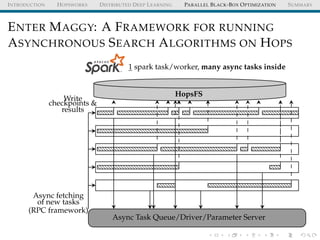






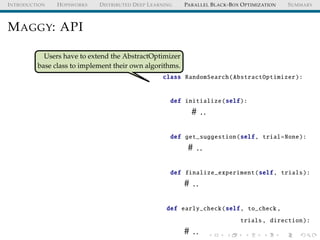




![INTRODUCTION HOPSWORKS DISTRIBUTED DEEP LEARNING PARALLEL BLACK-BOX OPTIMIZATION SUMMARY
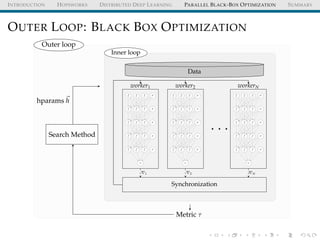
MAGGY: API
from maggy import experiment
from maggy.searchspace import Searchspace
from maggy.randomsearch import RandomSearch
sp = Searchspace(argument_param=(’DOUBLE’, [1, 5]))
rs = RandomSearch(5, sp)
result = experiment.launch(train_fn ,
sp, optimizer=rs,
num_trials=5, name=’test’,
direction="max")](https://image.slidesharecdn.com/distributeddeeplearningwithhopsworkskimhammar25april2019-190426160258/85/Distributed-deep-learning_with_hopsworks_kim_hammar_25_april_2019-67-320.jpg)


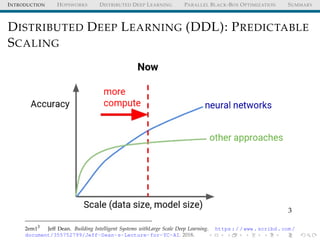
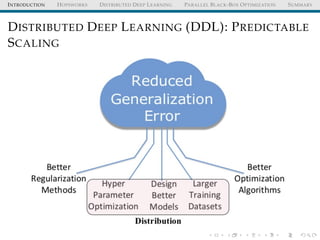
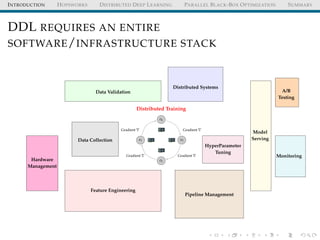
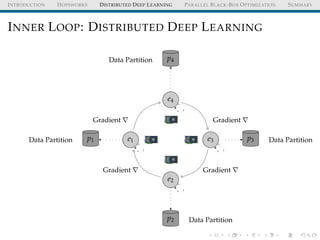
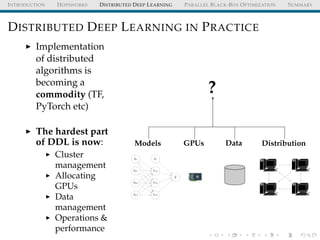
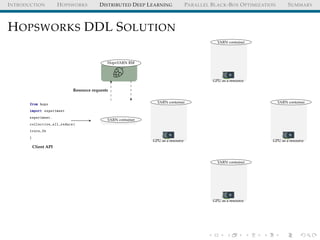
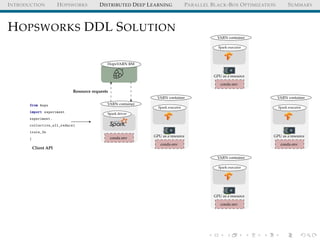
The document discusses the integration of distributed computing with deep learning in the context of the Hopsworks platform. It emphasizes the benefits of distributed deep learning (DDL), such as predictable scaling, and outlines challenges related to data management, cluster management, and optimization. Additionally, the document introduces various technologies and methodologies used in DDL, including TensorFlow and Spark.


![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)
































































