Download as PDF, PPTX






























![Usage From Command
Line
Run Deep Learning on Hadoop
yarn jar iterativereduce-0.1-SNAPSH O T.jar [props file]
Evaluate model
./score_m odel.sh [props file]](https://image.slidesharecdn.com/introductiontoparalleliterativedeeplearningonhadoopsnext-generationyarnframeworkpresentation2-140903203135-phpapp01/85/Introduction-to-parallel-iterative-deep-learning-on-hadoop-s-next-generation-yarn-framework-presentation-2-32-320.jpg)






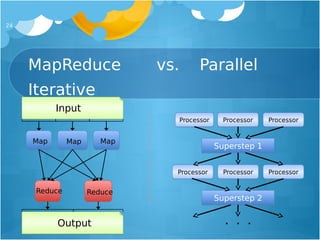
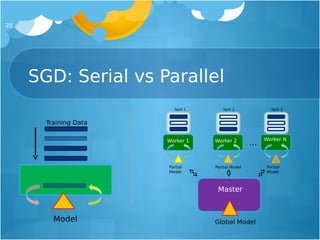
The document provides an overview of deep learning, focusing on its implementation on Hadoop and YARN using the Deeplearning4j (DL4J) library, which is designed for non-specialists and allows for efficient processing of large datasets. It explains various neural network architectures, their applications in tasks such as recommendation engines and anomaly detection, and highlights the scalability and performance advantages of using DL4J on distributed systems like Hadoop. Future directions include integrating GPU capabilities and improving data processing pipelines.
































































