References
• C. Kaliszykand J. Urban, "MizAR 40 for Mizar 40," In Journal of Automated Reasoning, vol. 55,
no. 3, pp. 245-256, 2015. http://link.springer.com/article/10.1007/s10817-015-9330-8
• A. A. Alemi, F. Chollet, G. Irving, C. Szegedy, and J. Urban, "DeepMath - deep sequence models for
premise selection," Jun. 2016. http://arxiv.org/abs/1606.04442
• S. Loos, G. Irving, C. Szegedy, and C. Kaliszyk, "Deep network guided proof search," Jan. 2017.
[Online]. Available: http://arxiv.org/abs/1701.06972
• C. Kaliszyk, F. Chollet, and C. Szegedy, "HolStep: A machine learning dataset for higher-order logic
theorem proving," Mar. 2017. http://arxiv.org/abs/1703.00426
• D. Whalen, "Holophrasm: a neural automated theorem prover for higher-order logic," Aug. 2016.
http://arxiv.org/abs/1608.02644
• T. Rocktäschel and S. Riedel, "End-to-end differentiable proving," May 2017.
http://arxiv.org/abs/1705.11040
• T. Sekiyama, A. Imanishi, and K. Suenaga, "Towards proof synthesis guided by neural machine
translation for intuitionistic propositional logic," Jun. 2017. http://arxiv.org/abs/1706.06462
49
50.
References
• D. Silver,A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V.
Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K.
Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of go with deep neural networks and tree search,” Nature,
vol. 529, no. 7587, pp. 484-489, Jan. 2016
https://www.nature.com/nature/journal/v529/n7587/abs/nature16961.html?lang=en
• 山本一成, 下山晃, 齋藤真樹, 藤田康博, 秋葉拓哉, 土井裕介, 菊池悠太, 奥田遼介, 須藤武文 and 大川和仁, “第27回世界コン
ピュータ将棋選手権 Ponanza Chainer アピール文章,” 2017.
http://www2.computer-shogi.org/wcsc27/appeal/Ponanza_Chainer/Ponanza_Chainer.pdf
50









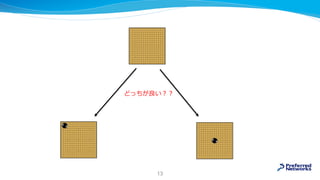



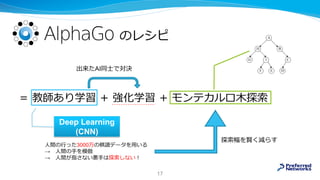

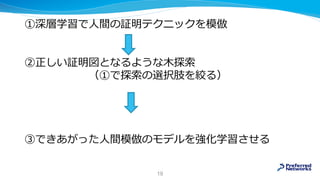







![MizAR 40 for Mizar 40
• [Cezary Kaliszyk and Josef Urban, 2015]
• Mizar で MML 4.181.1147に含まれる 57897 の定理などを対
象に、
• ナイーブベイズやk-NNといった古典的なモデル(+ TF-IDFや
LSI、アンサンブルやブースティング)でそれぞれの公理が必
要かを予測
• 予測スコアの⾼い公理 n 個に限定して自動定理証明器
(Vampire, E, Z3) を呼び出す
• 単一手法(モデル+証明器)で最⾼27.3%、複数手法で40%以上
証明できたなど
28](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-28-320.jpg)
![DeepMath
• DeepMath - Deep Sequence Models for Premise
Selection [arXiv:1606.04442]
• 同じくMizarとMMLを対象に、モデルを深層学習っぽい
モデルにすることを試みた論文
• 自動定理証明器には E を使用
• 複数のモデルを試しており、テスト用の 2,742 個の定理
中、単一モデルで最⾼62.95%、複数モデルで77%ほど
証明できた!
29](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-29-320.jpg)

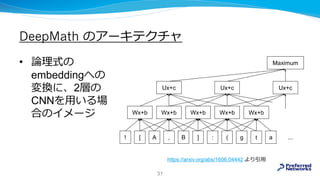
![DeepMath の再現の試み: データセット
C fof(l100_finseq_1, axiom, r2_hidden(7, k2_finseq_1(7))).
+ fof(cc8_ordinal1, axiom, (! [A] : (m1_subset_1(A, k4_ordinal1) => v7_or
+ fof(redefinition_k5_numbers, axiom, k5_numbers=k4_ordinal1).
+ fof(rqLessOrEqual__r1_xxreal_0__r1_r7, axiom, r1_xxreal_0(1, 7)).
+ fof(rqLessOrEqual__r1_xxreal_0__r7_r7, axiom, r1_xxreal_0(7, 7)).
+ fof(spc7_numerals, axiom, ( (v2_xxreal_0(7) & m2_subset_1(7, k1_num
+ fof(t1_finseq_1, axiom, (! [A] : (v7_ordinal1(A) => (! [B] : (v7_ordinal1(B)
- fof(l98_finseq_1, axiom, (r2_hidden(3, k2_finseq_1(7)) & r2_hidden(4, k
- fof(l99_finseq_1, axiom, (r2_hidden(5, k2_finseq_1(7)) & r2_hidden(6, k
- fof(l97_finseq_1, axiom, (r2_hidden(1, k2_finseq_1(7)) & r2_hidden(2, k
- fof(t5_finseq_1, axiom, (! [A] : (v7_ordinal1(A) => (! [B] : (v7_ordinal1(B)
データセット https://github.com/JUrban/deepmath
例: nndata/l100_finseq_1
必要
だった
公理
不要な
公理
証明した
い命題
32](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-32-320.jpg)
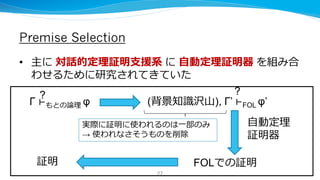
![次に処理すべき節の選択への適用:
Deep Network Guided Proof Search
• [arXiv:1701.06972]
• DeepMathがEに与える前提を絞るの
にNNを使っていたのに対し、
• 自動定理証明器(E Prover)中に次に処
理すべき節の選択のために、ある節が
証明中で使われるか否かを予測する
NNを学習し、そのスコアの⾼い節か
ら処理。
• 探索手のランキングにNNを使う
AlphaGo, Ponanza Chainer とも類似
• 対象は同じくMizarとMML
• アーキテクチャはDeepMathと同様
34
https://arxiv.org/abs/1701.06972より引用](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-34-320.jpg)
![中間ゴールの予測: HolStep
• HolStep: A Machine Learning Dataset for Higher-Order
Logic Theorem Proving
• [arXiv:1703.00426]
• (前提の集合、証明したい定理の主張)
→ 使えそうな中間ステップを予測する問題
35](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-35-320.jpg)

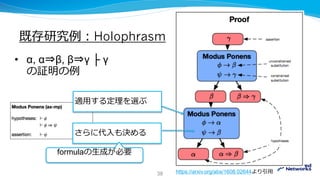
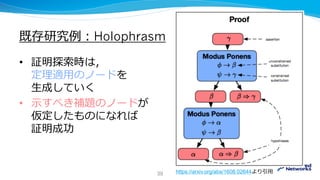
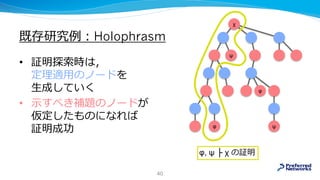
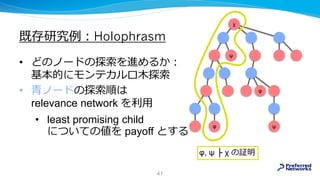
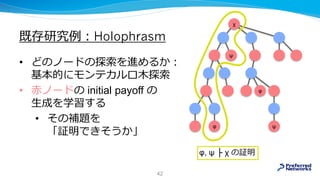
![既存研究例:Holophrasm
• [arXiv:1608.02644]
• 完全な証明を書きだすところまでやる
• payoff network: 探索の優先順を決める
• relevance network: 適用する定理の選択
• generative network: 代入の生成
37](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-37-320.jpg)
![既存研究の比較
論理 タスク
DeepMath Mizar を
FOL
(一階述語論理)
に変換
Premise Selection
Deep Network
Guided Proof
Search
探索のガイド
HolStep HOL 探索のガイド
Holophrasm FOL 証明の生成、探索のガイド、代入生成
DeepProlog
Tim Rocktäschel
et al. ‘17
FOL - 関数記号 帰納論理プログラミング
[arxiv.1706.06462]
Sekiyama et al. ‘17
命題論理 証明の生成
43](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-43-320.jpg)





![References
• C. Kaliszyk and J. Urban, "MizAR 40 for Mizar 40," In Journal of Automated Reasoning, vol. 55,
no. 3, pp. 245-256, 2015. http://link.springer.com/article/10.1007/s10817-015-9330-8
• A. A. Alemi, F. Chollet, G. Irving, C. Szegedy, and J. Urban, "DeepMath - deep sequence models for
premise selection," Jun. 2016. http://arxiv.org/abs/1606.04442
• S. Loos, G. Irving, C. Szegedy, and C. Kaliszyk, "Deep network guided proof search," Jan. 2017.
[Online]. Available: http://arxiv.org/abs/1701.06972
• C. Kaliszyk, F. Chollet, and C. Szegedy, "HolStep: A machine learning dataset for higher-order logic
theorem proving," Mar. 2017. http://arxiv.org/abs/1703.00426
• D. Whalen, "Holophrasm: a neural automated theorem prover for higher-order logic," Aug. 2016.
http://arxiv.org/abs/1608.02644
• T. Rocktäschel and S. Riedel, "End-to-end differentiable proving," May 2017.
http://arxiv.org/abs/1705.11040
• T. Sekiyama, A. Imanishi, and K. Suenaga, "Towards proof synthesis guided by neural machine
translation for intuitionistic propositional logic," Jun. 2017. http://arxiv.org/abs/1706.06462
49](https://image.slidesharecdn.com/proofsummit2017forslideshare-170726020355/85/Proof-summit-2017-for-slideshare-49-320.jpg)































![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)




