Downloaded 525 times





























![BigTable – Bloom Filters
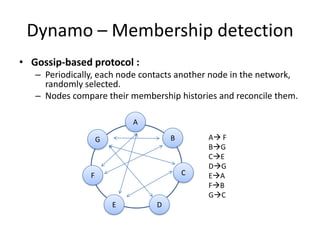
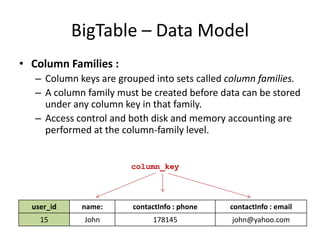
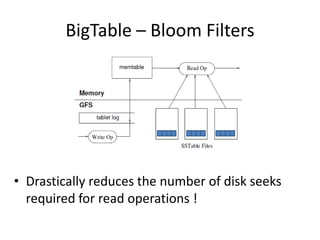
Bloom Filter :
1. Empty array a of m bits, all set to 0.
2. Hash function h, such that h hashes each element to one of
the m array positions with a uniform random distribution.
3. To add element e – a[h(e)] = 1
Example :
S1 = {“John Smith”, ”Lisa Smith”, ”Sam Doe”, ”Sandra Dee”}
0 1 1 0 1 0 0 0 0 0 0 0 0 0 1 0](https://image.slidesharecdn.com/cap-131117230434-phpapp02/85/Dynamo-and-BigTable-in-light-of-the-CAP-theorem-54-320.jpg)

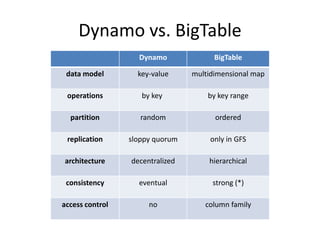


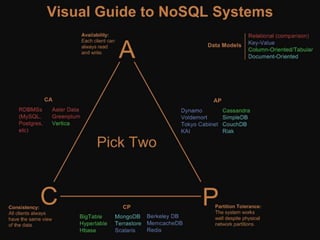

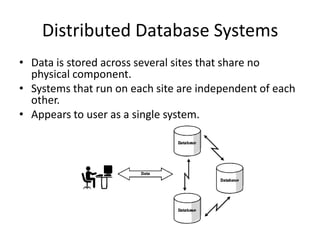
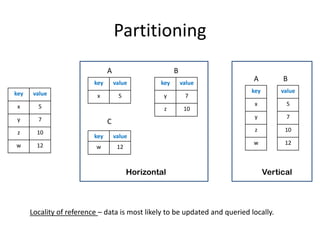
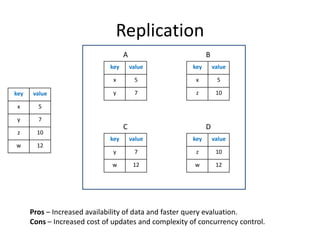
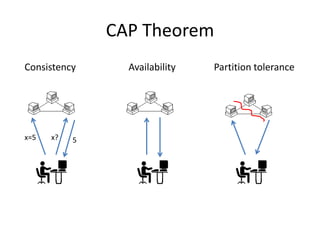
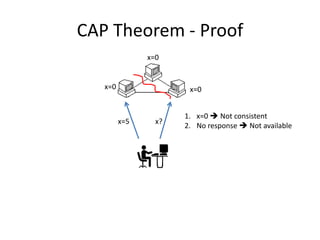
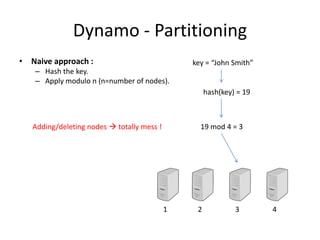
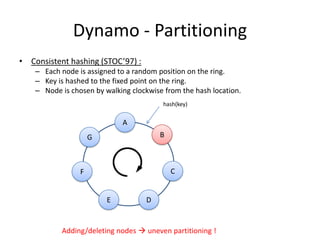
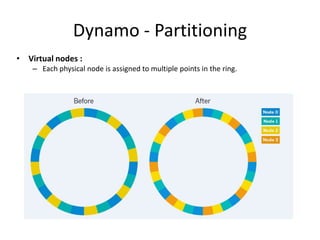
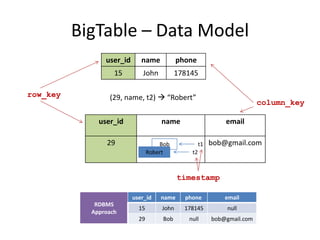
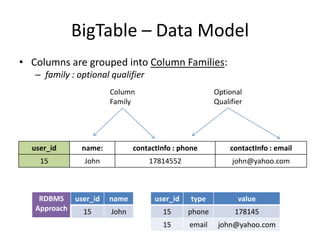
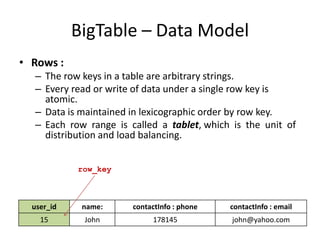
The document provides an overview of distributed database systems, focusing on the CAP theorem, which states that only two of the three properties: consistency, availability, and partition tolerance can be achieved simultaneously. It compares two systems, Dynamo (which favors availability and partition tolerance) and Bigtable (which aims for consistency and partition tolerance), detailing their architectures, data models, and operational mechanisms. Key concepts include data replication, partitioning strategies, and the implications of these designs on availability and consistency in distributed systems.






















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












