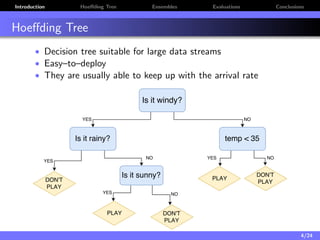
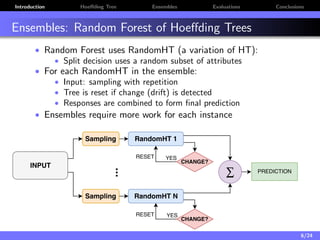
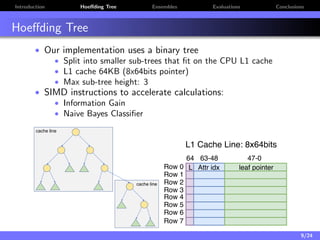
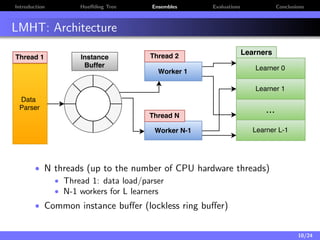
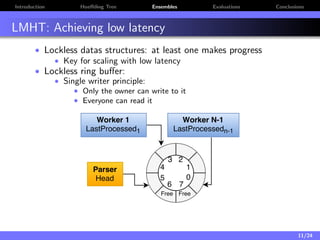
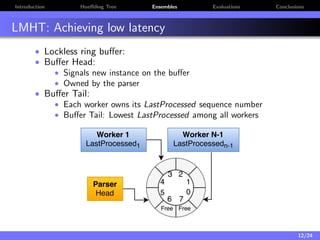
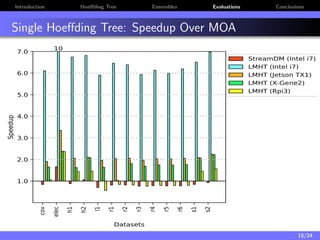
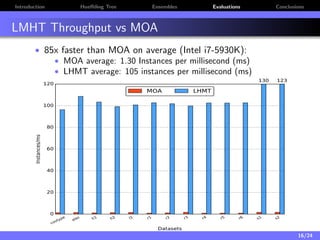
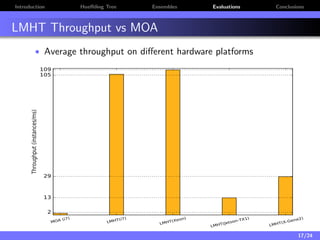
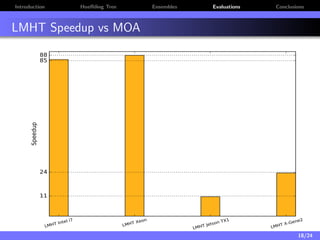
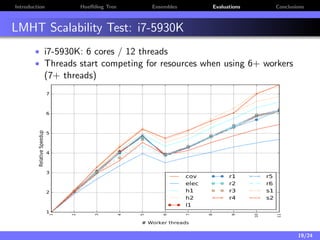
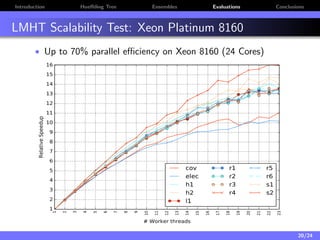
The document discusses a low-latency, multi-threaded algorithm for ensemble learning applied to dynamic big data streams, which accounts for real-time classification challenges such as velocity and concept drift. It highlights the implementation of Hoeffding tree ensembles that maintain high accuracy while achieving significant speed improvements, making them well-suited for various hardware platforms. The solution shows a performance increase of up to 85 times faster than existing state-of-the-art implementations, accommodating both server and edge computing environments.