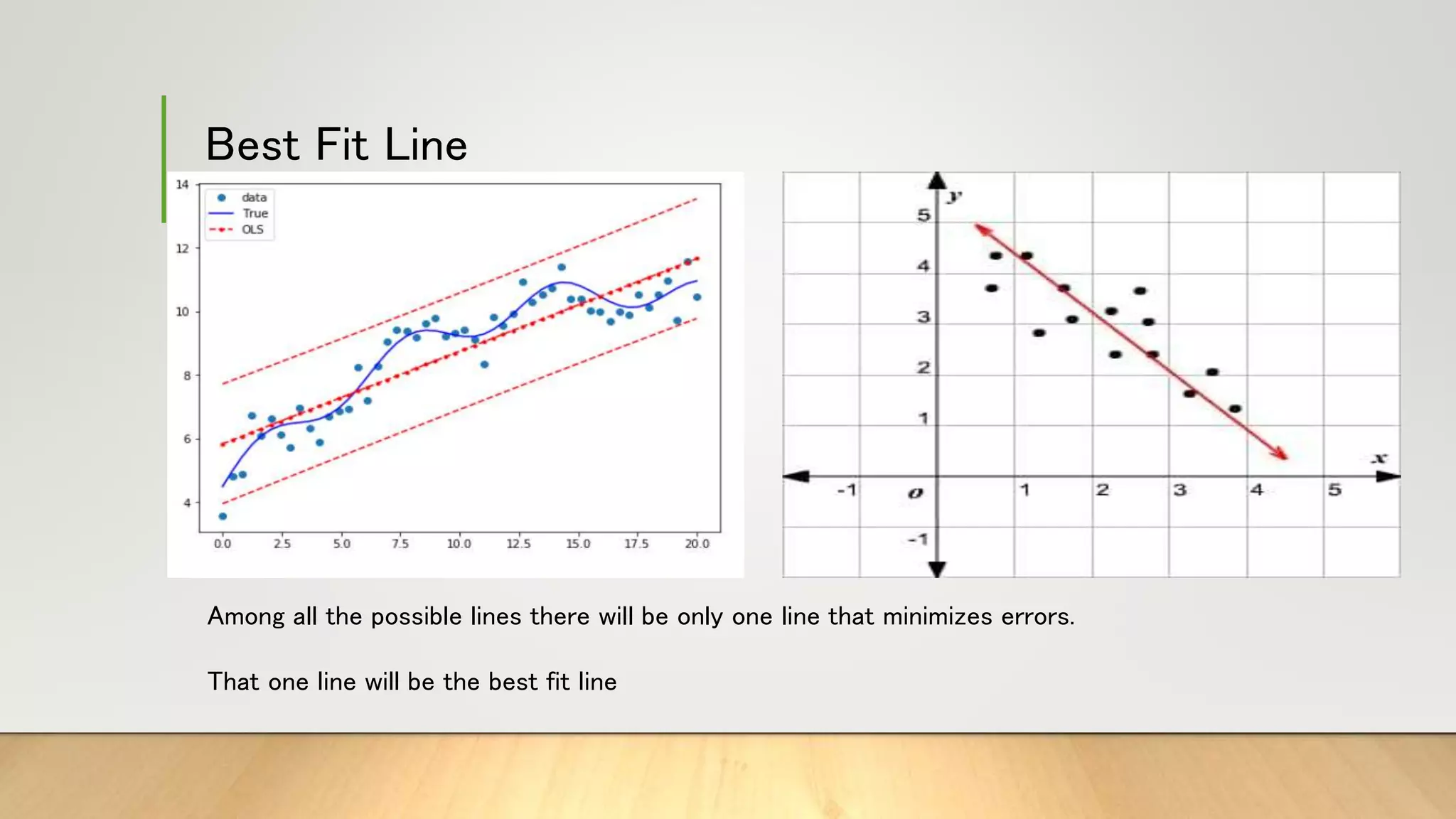
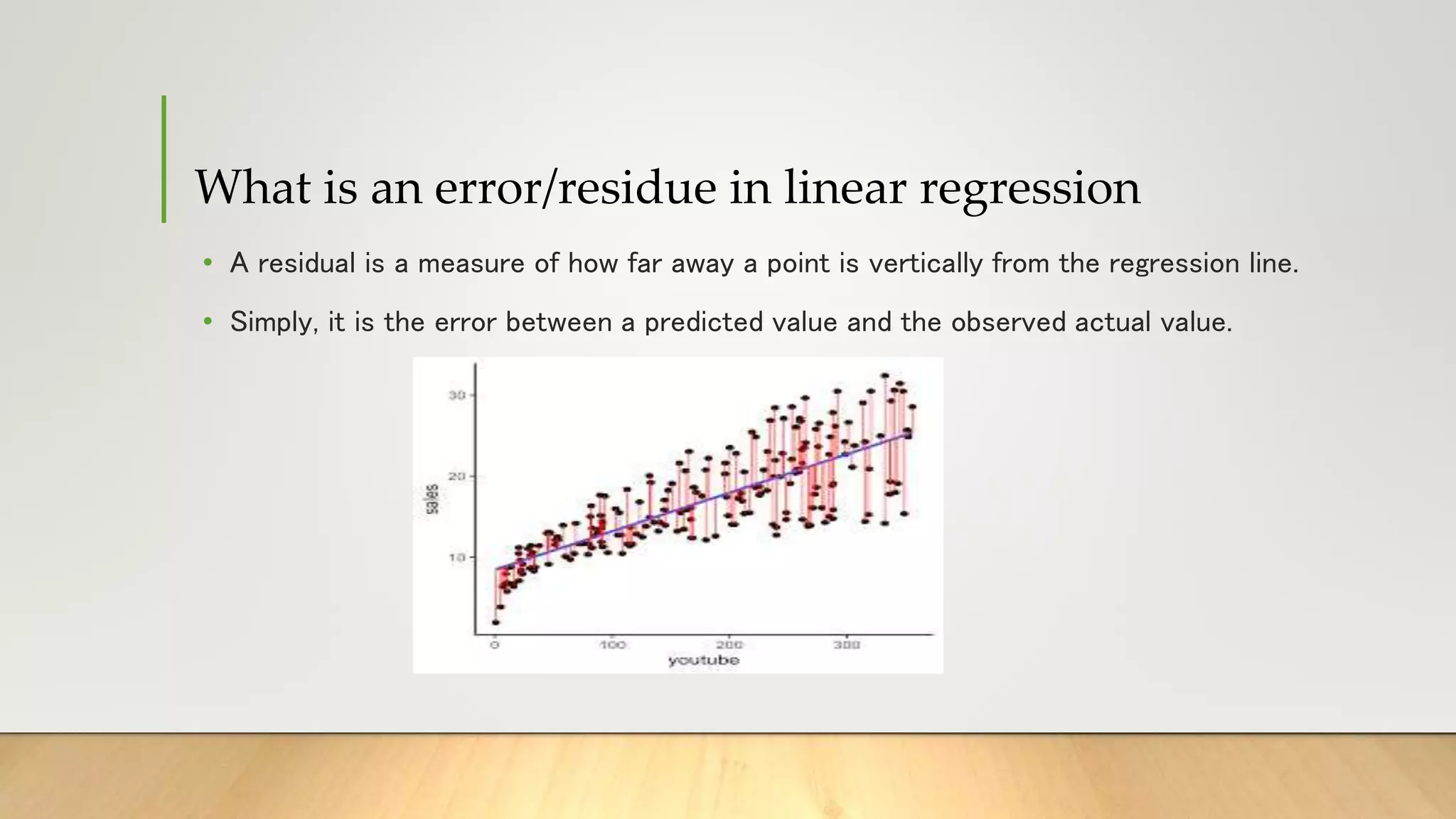
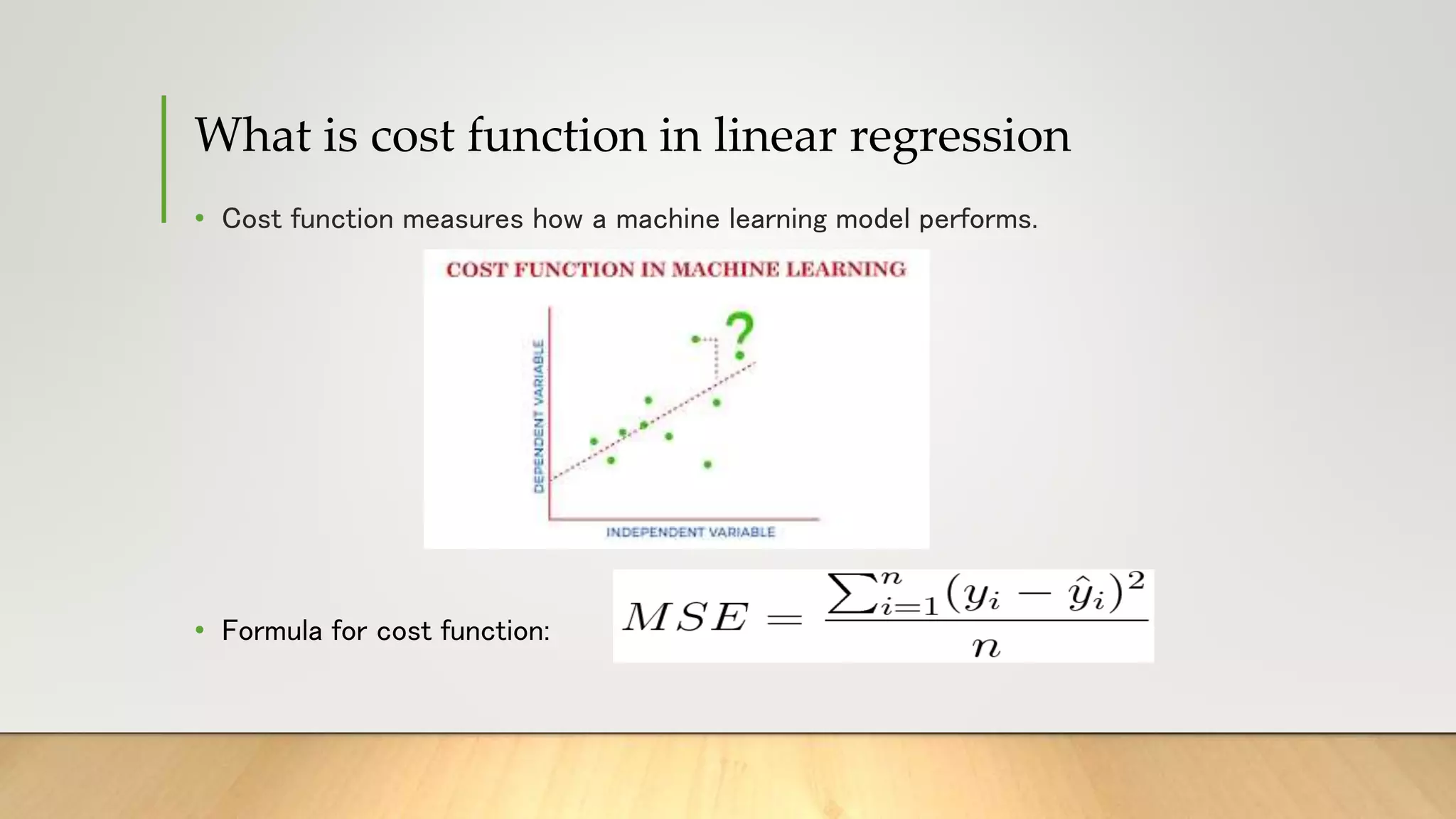
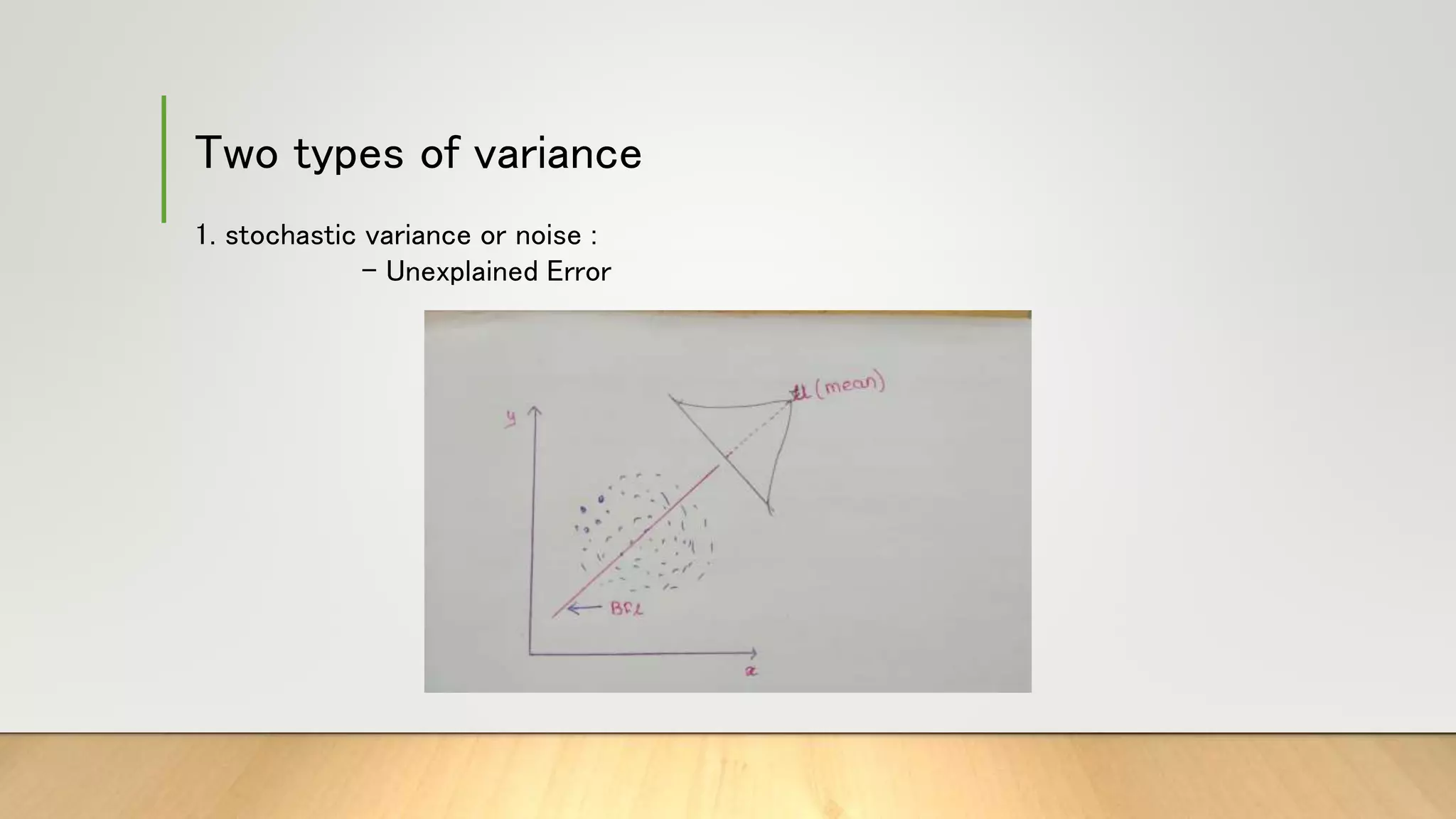
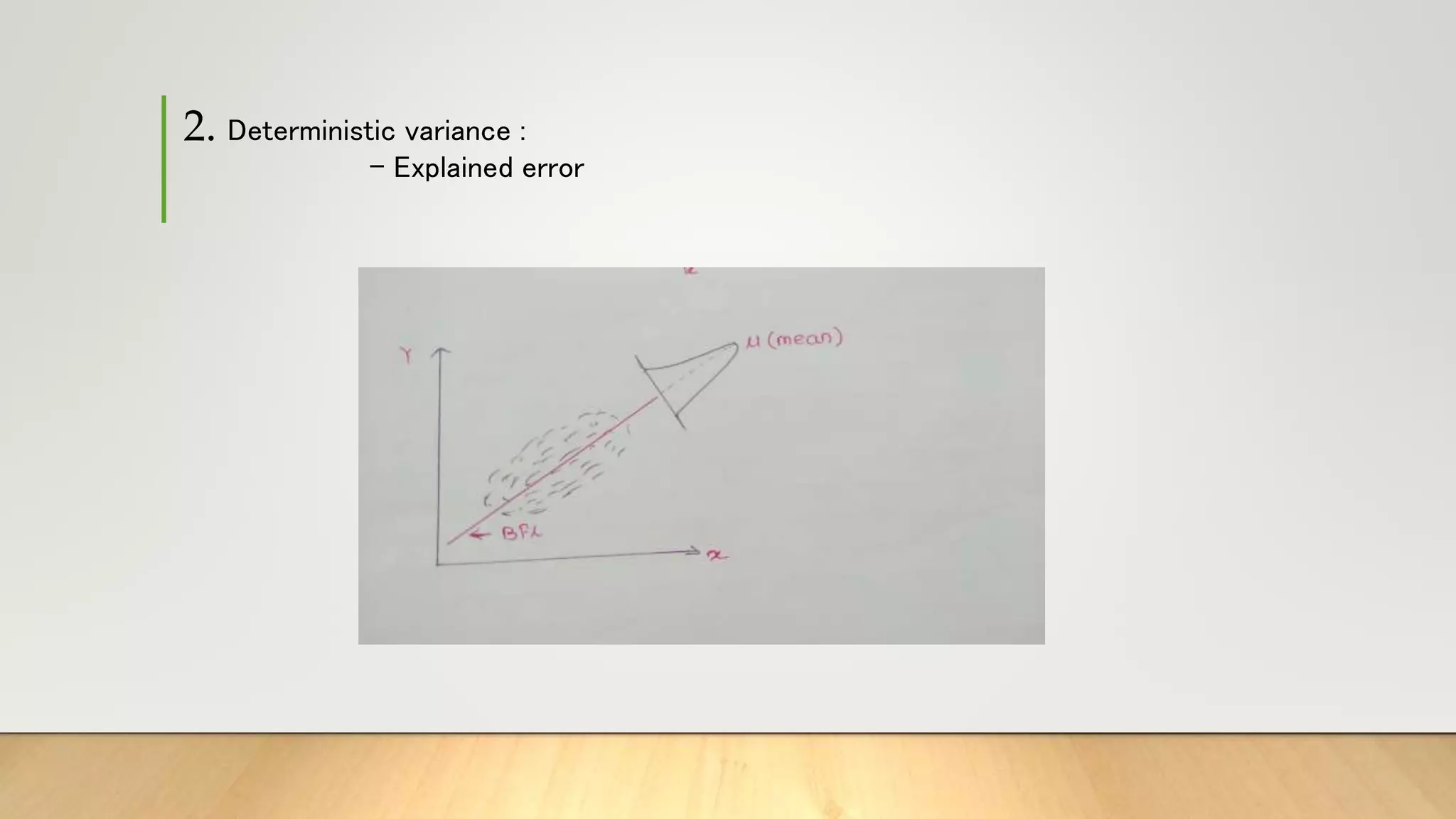
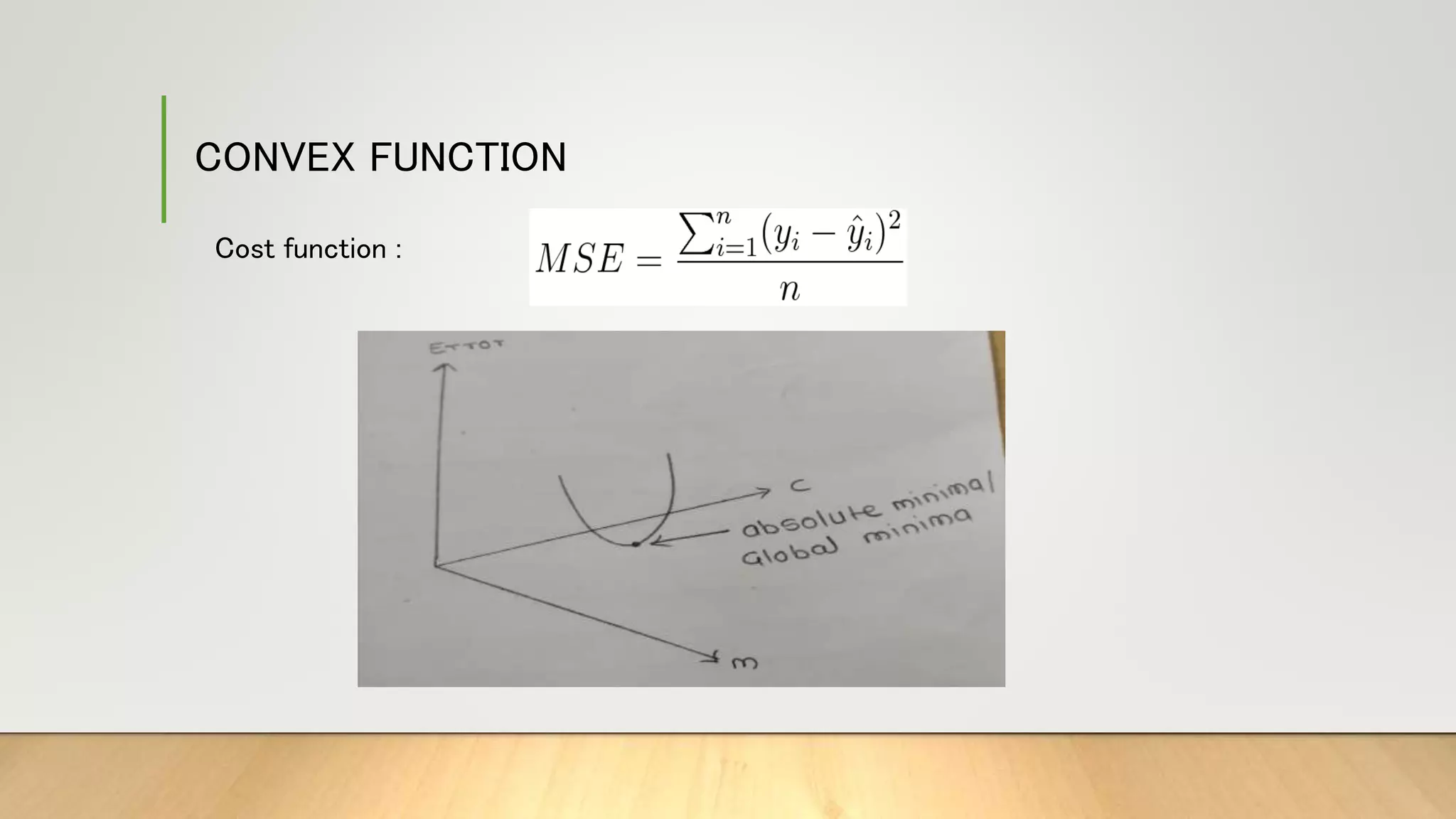
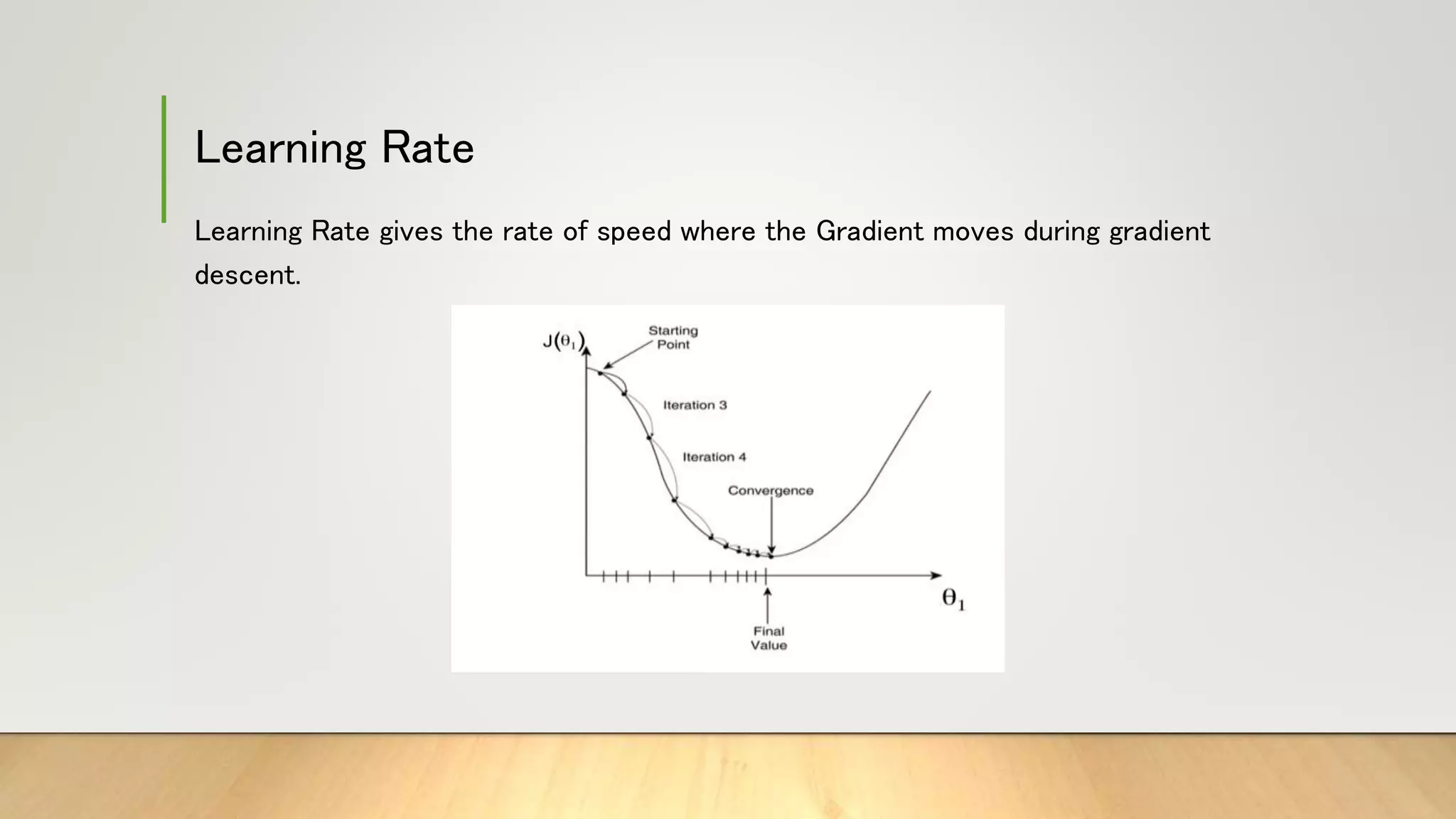
This document provides information about gradient descent and linear regression. It defines gradient descent as an optimization algorithm used to find the optimal value of a cost function. It discusses finding the best fit line by minimizing errors. It also defines key concepts like residuals, loss functions, cost functions, variance, partial differentiation, learning rate, and how gradient descent is used in machine learning and deep learning.






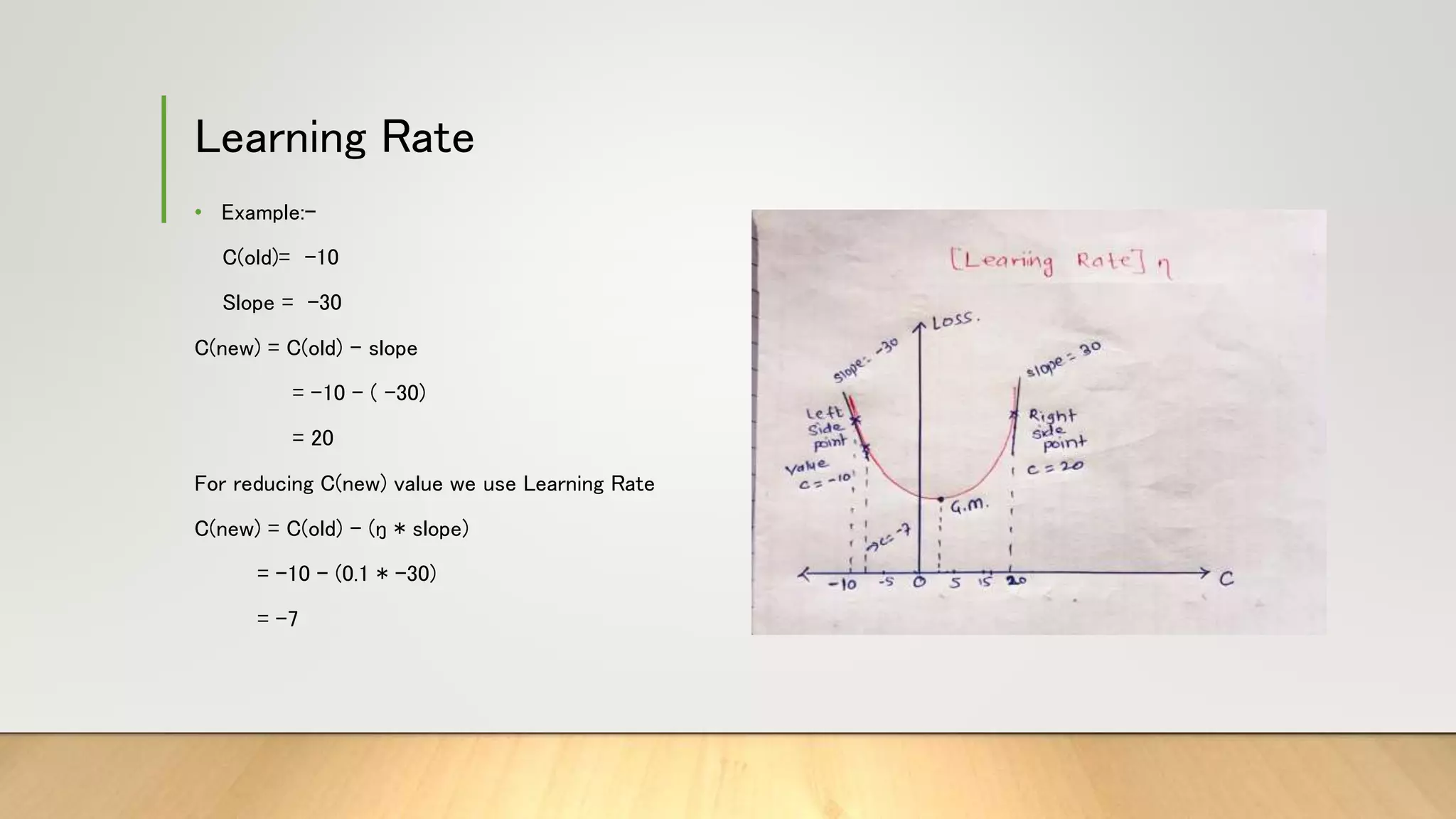
![Learning Rate
1. Setting a high value makes your path unstable, and too low makes convergence slow.
2. If we put the Learning rate value Zero, then there is no movement.
• C(new)= C(old) – [ŋ*(slope)]](https://image.slidesharecdn.com/gradientdescent-230323181520-f429044b/75/GradientDescent-pptx-14-2048.jpg)