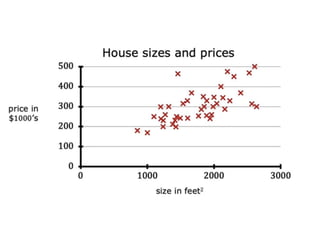
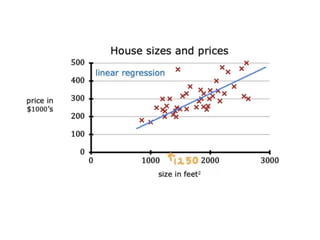
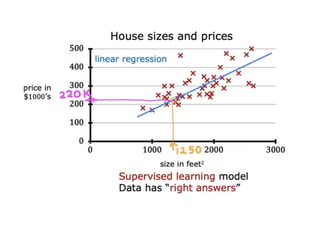
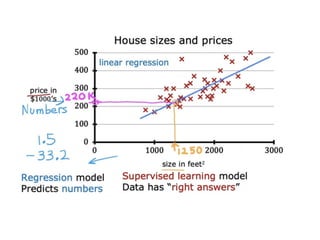
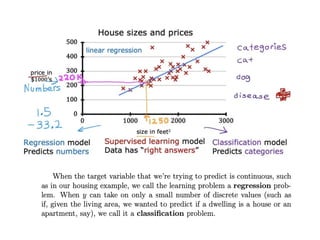
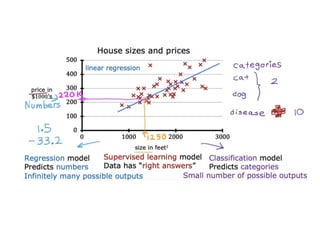
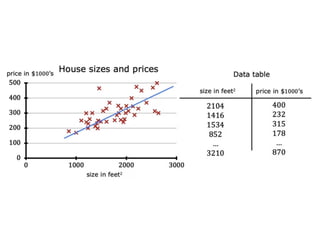
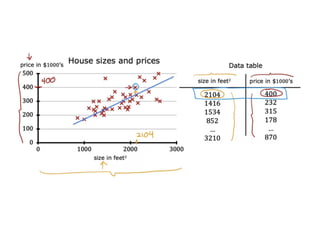
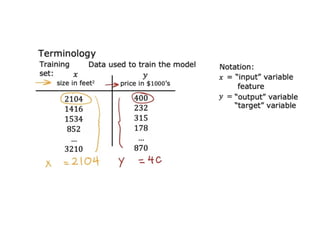
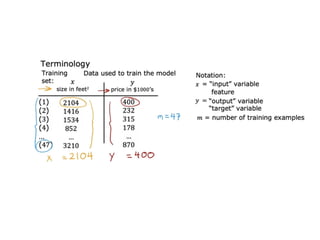
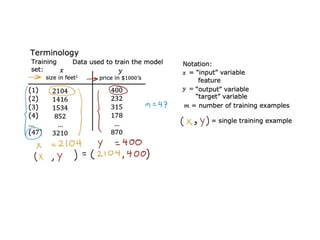
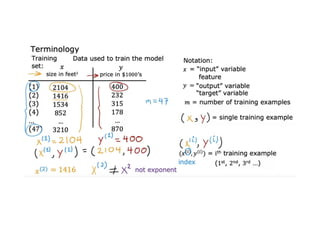
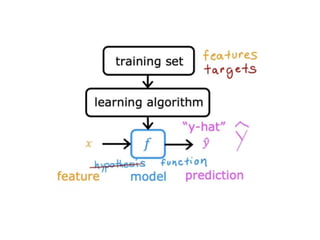
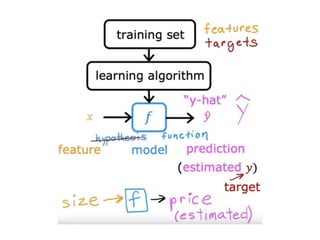
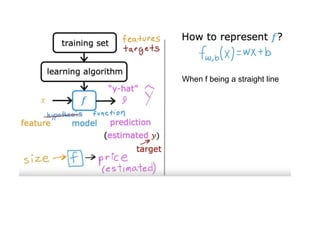
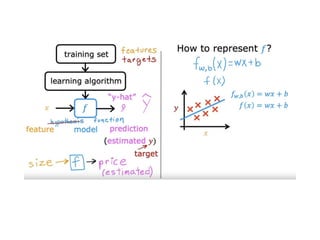
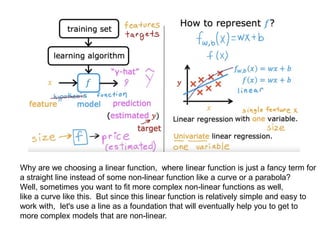
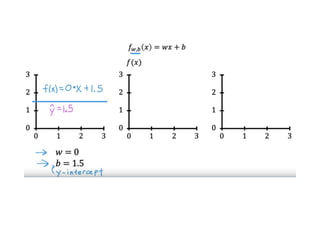
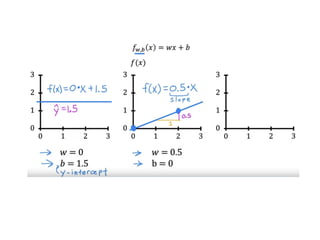
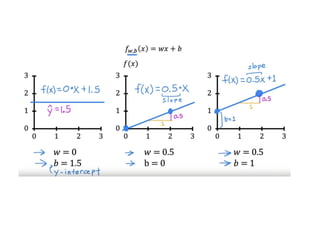
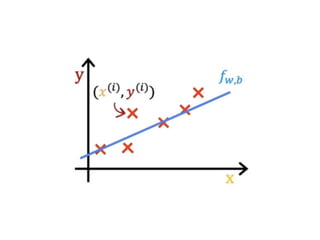
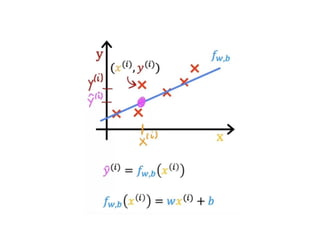
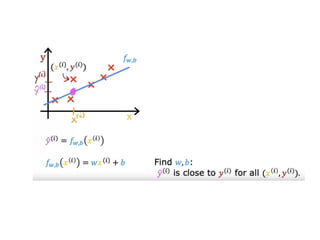
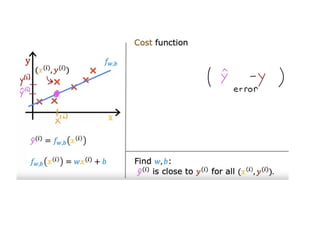
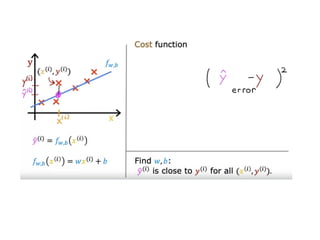
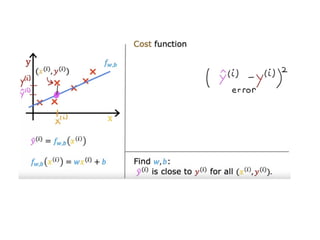
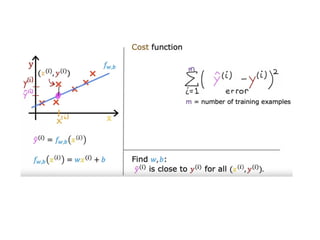
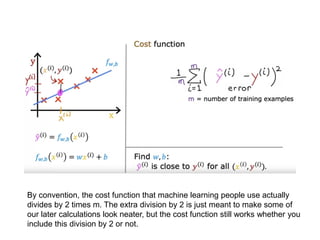
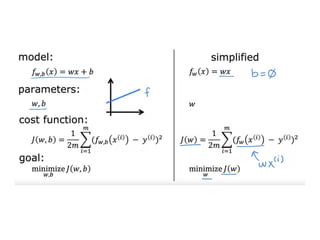
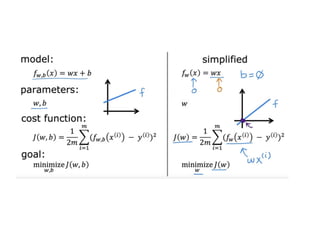
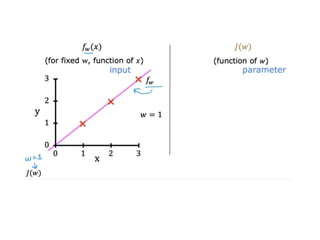
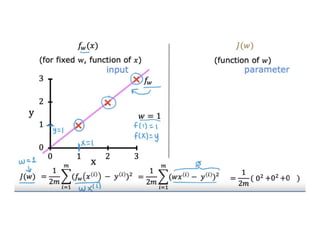
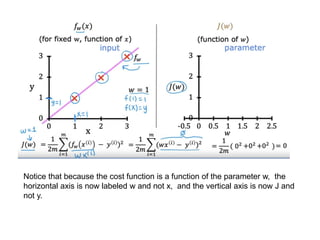
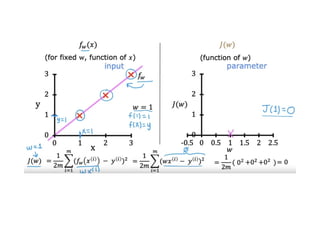
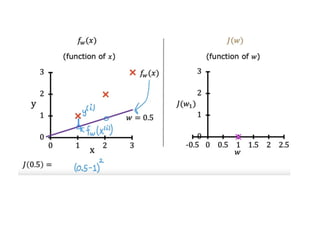
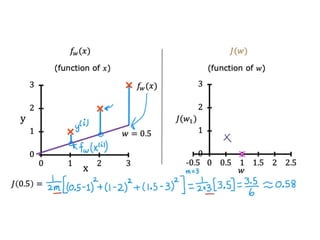
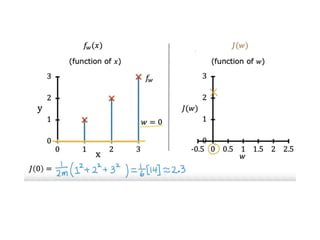
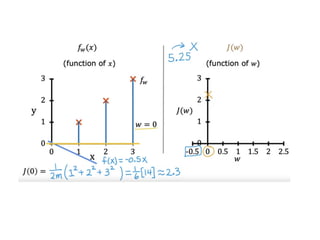
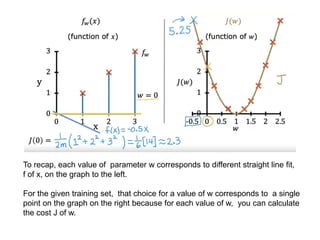
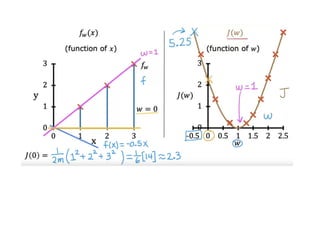
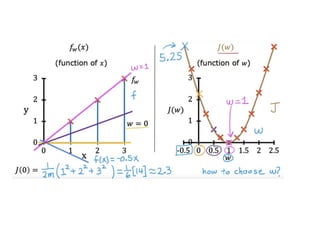
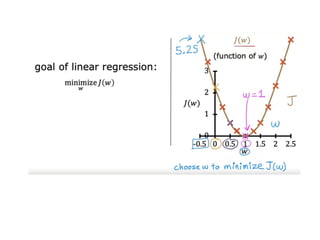
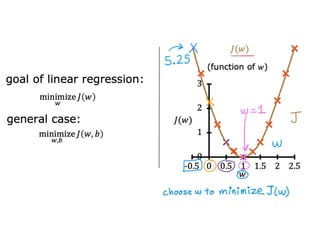
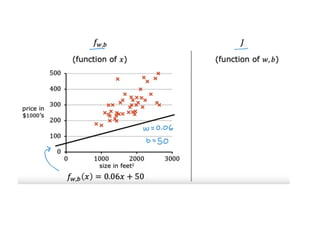
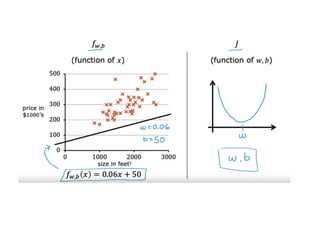
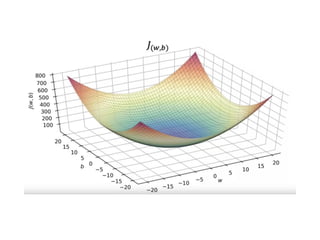
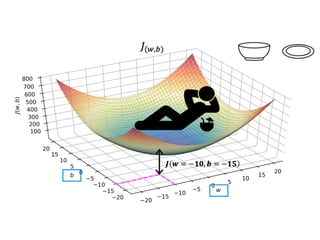
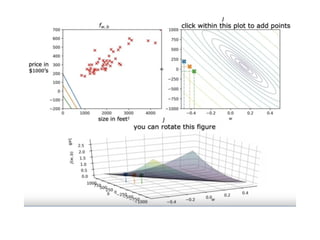
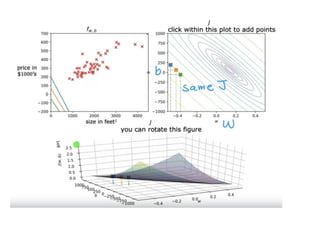
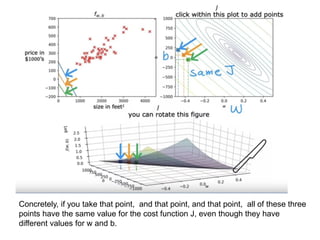
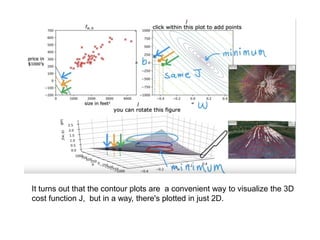
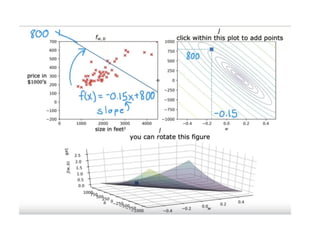
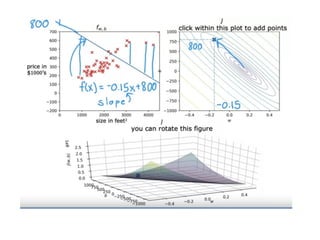
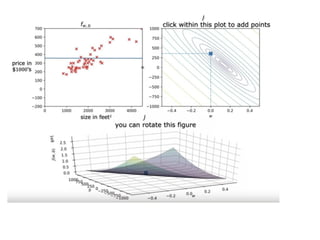
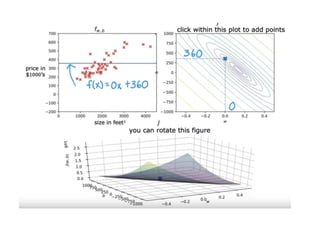
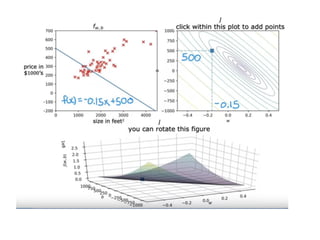
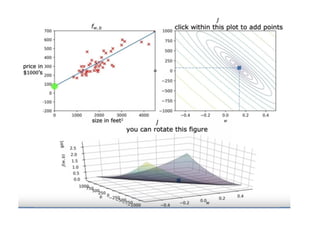
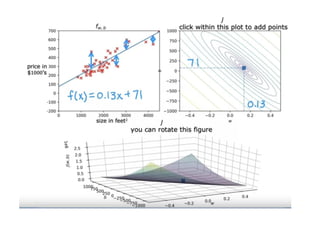
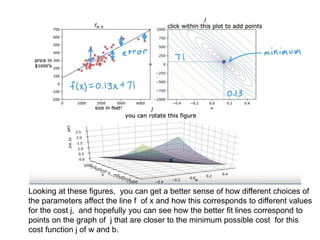
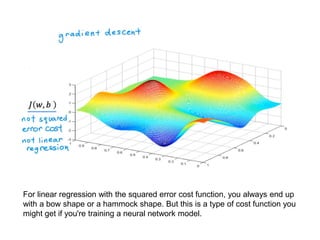
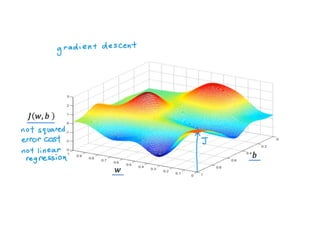
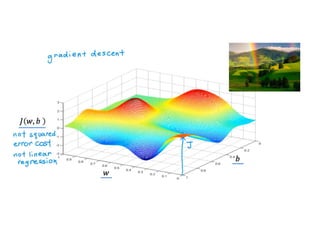
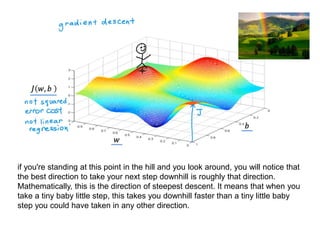
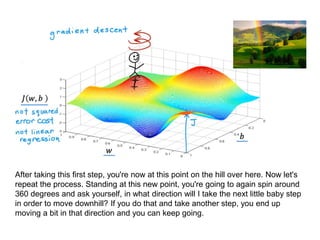
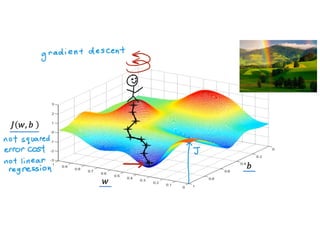
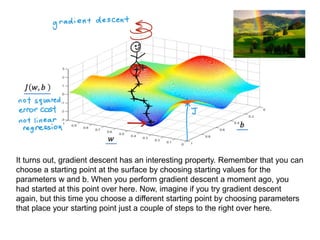
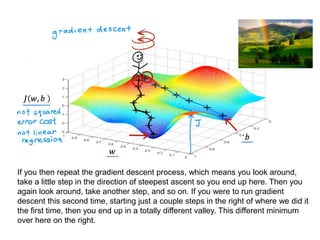
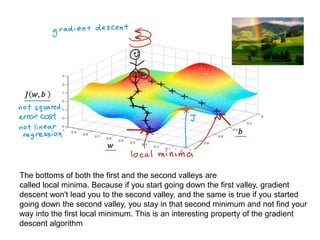
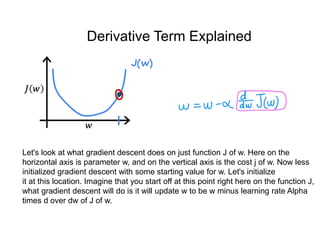
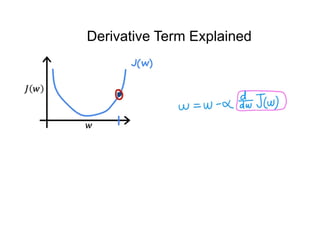
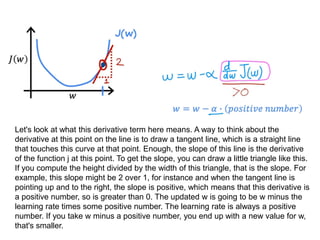
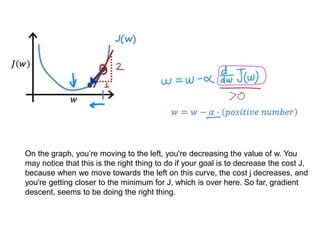
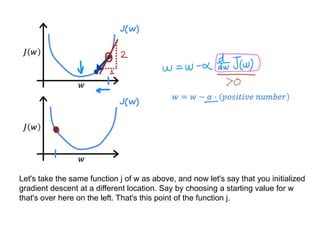
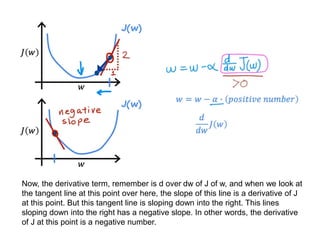
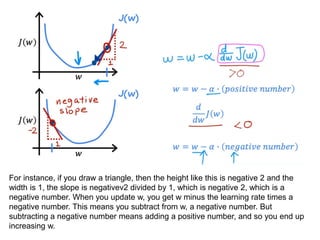
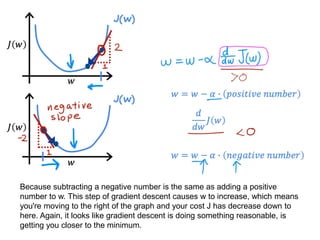
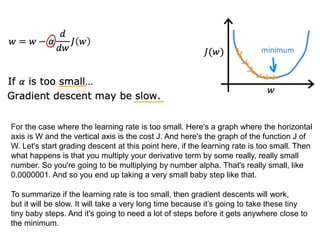
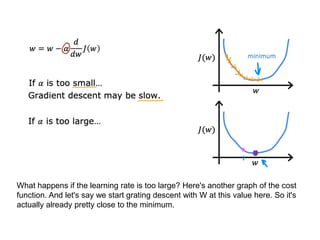
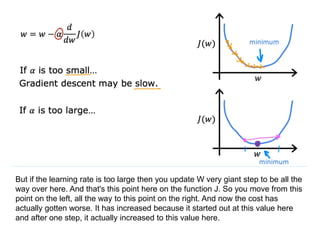
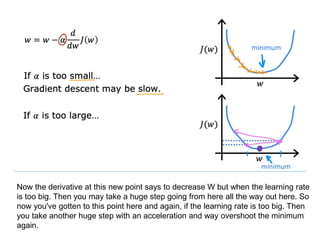
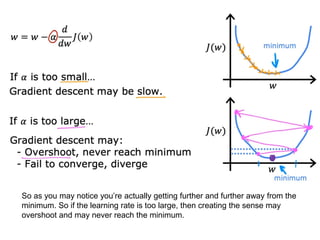
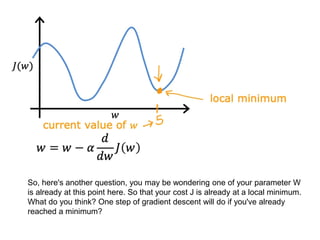
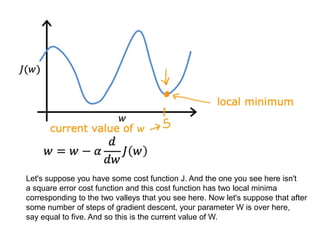
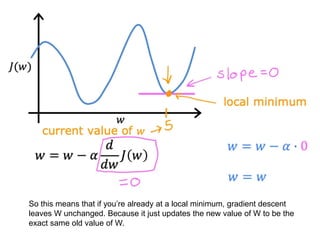
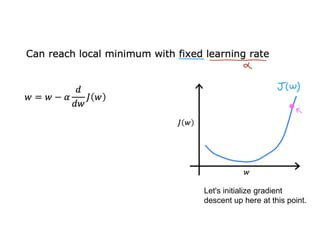
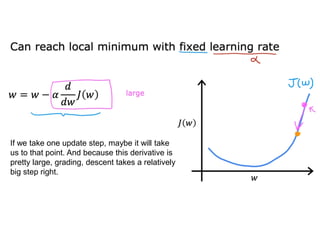
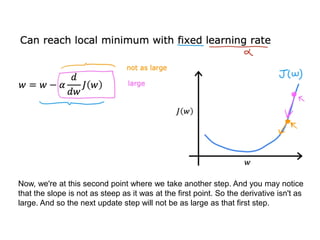
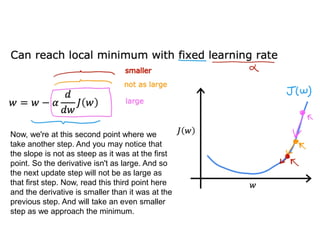
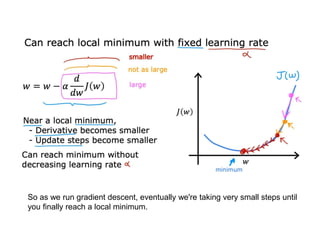
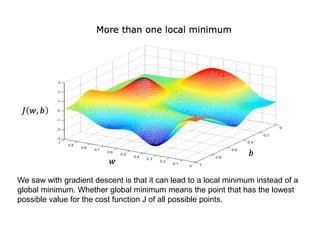
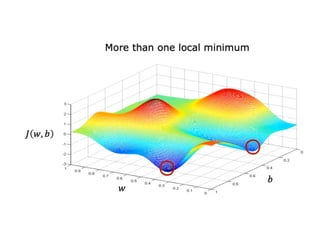
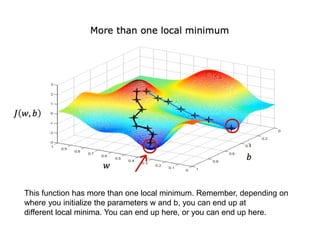
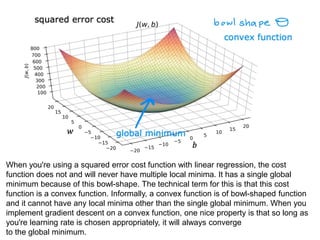
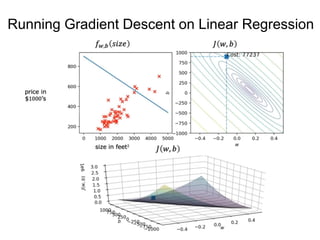
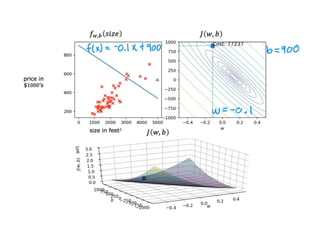
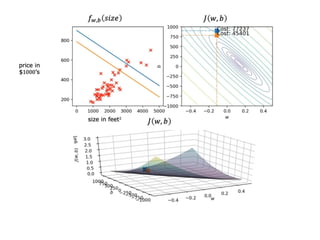
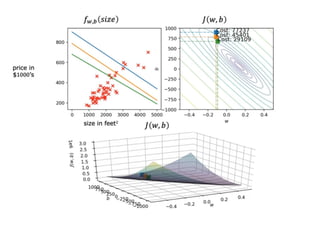
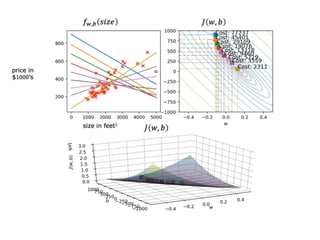
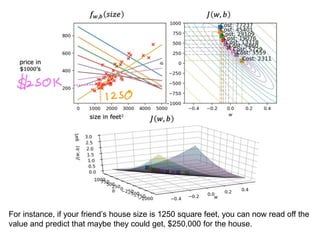
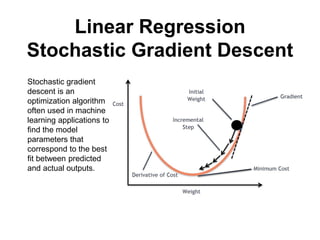
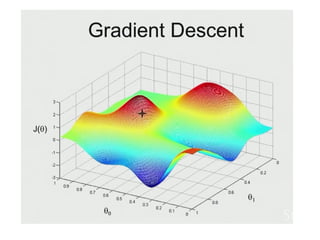
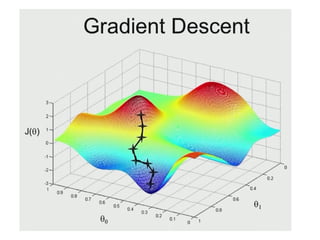
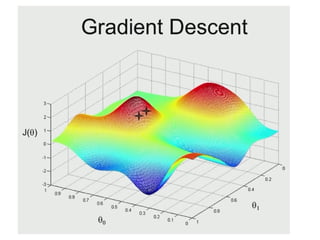
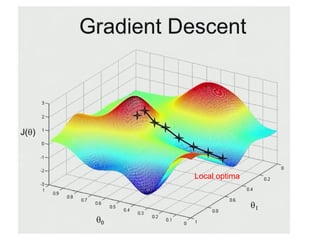
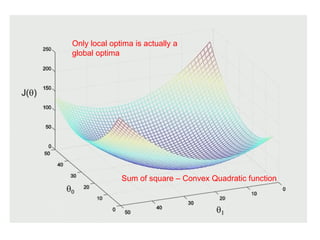
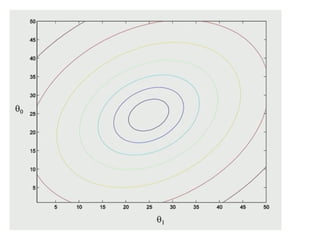
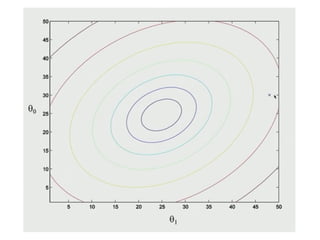
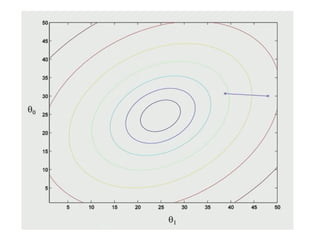
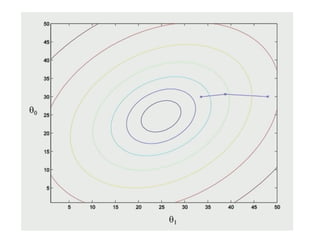
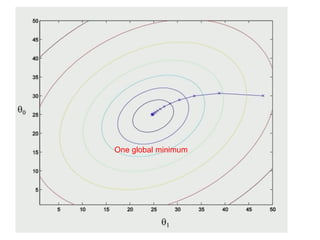
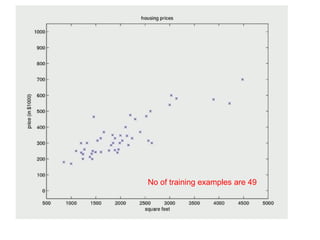
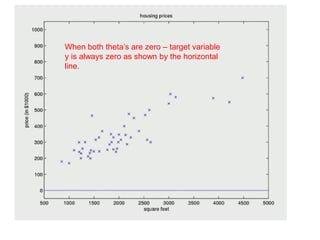
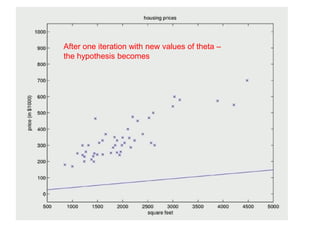
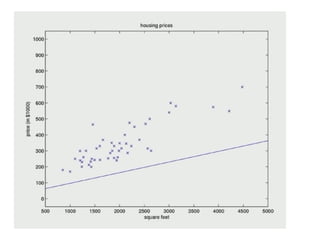
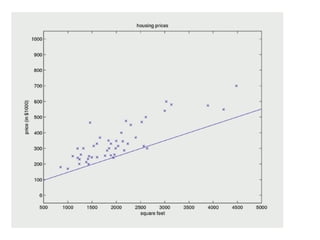
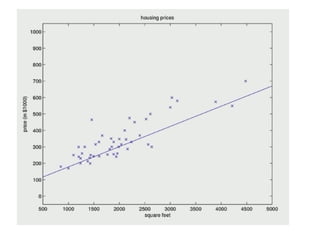
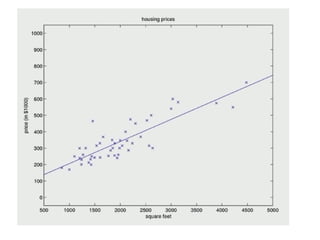
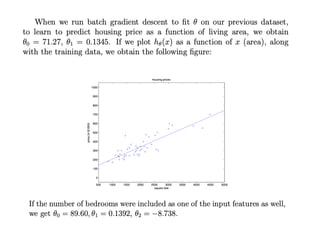
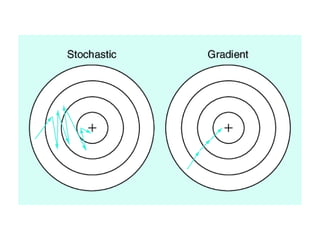
The document discusses supervised learning using linear regression, emphasizing the use of a linear function as a foundation for modeling relationships, particularly in predicting housing prices. It introduces the concept of a cost function, specifically the average squared error, and explains the gradient descent algorithm for minimizing this cost, highlighting its importance in machine learning for achieving optimal model parameters. It also addresses the nuances of choosing a learning rate and the consequences of its values on the efficiency and effectiveness of the gradient descent process.