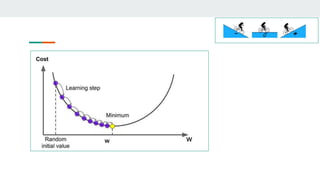
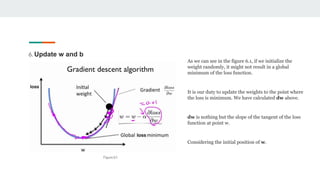
- Linear regression uses gradient descent to find the optimal weight (w) and bias (b) values that minimize the loss function and produce predictions closest to the actual target values.
- It starts with random w and b values and calculates predictions. The loss function captures the deviation between predictions and targets.
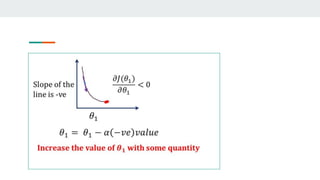
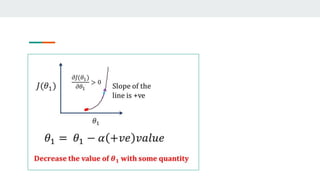
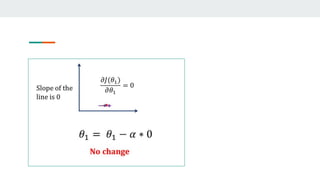
- It then computes the partial derivatives of the loss with respect to w and b to determine how to update them in a direction that decreases loss.
- This process repeats in a training loop, updating w and b with each iteration until reaching a minimum loss, producing the optimal regression model.