Download as PDF, PPTX









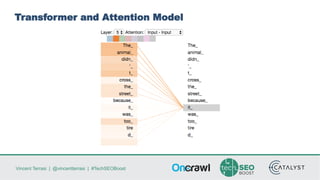
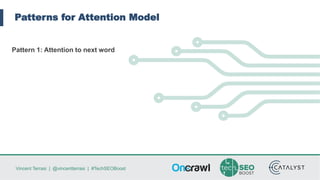
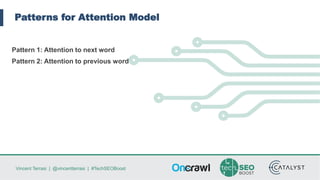













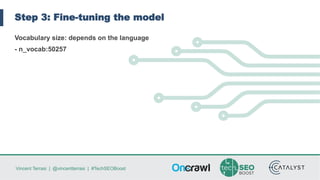
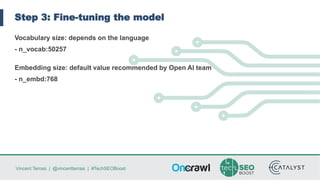
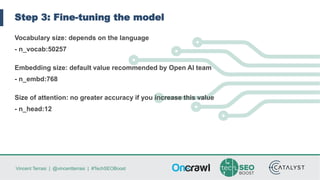
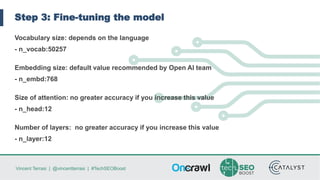







Vincent Terrasi discusses using AI models like GPT-2 and BERT to generate qualitative content in different languages. He outlines the steps to fine-tune a GPT-2 model for a new language using SentencePiece to compress the training data into byte-pair encodings. With sufficient training data in that language, the model can generate fluent multi-sentence texts that pass quality checks by a native speaker and language analysis tool. However, limited training data results in weaker performance. Terrasi provides resources to experiment with a French GPT-2 model and encourages adapting the approach for other languages.




































































![[rokonz.com] Glossary of Semantic SEO Part-1.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rokonz-260123200456-440e4060-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[rokonz.com] Glossary of Semantic SEO Part-3.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rokonz-260123200835-55123e1e-thumbnail.jpg?width=640&height=640&fit=bounds)