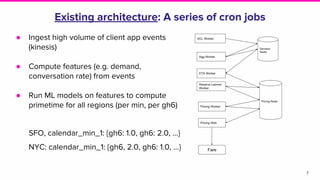
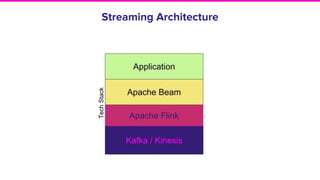
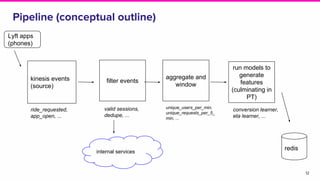
The document presents an overview of Lyft's dynamic pricing system, referred to as prime time, which adjusts ride fares based on location and time to balance supply and demand. It discusses the transition from existing infrastructure to a streaming-based architecture using tools like Beam and Flink to reduce latency and enhance feature integration. Key lessons learned emphasize the importance of system efficiency and effective profiling in machine learning deployment.