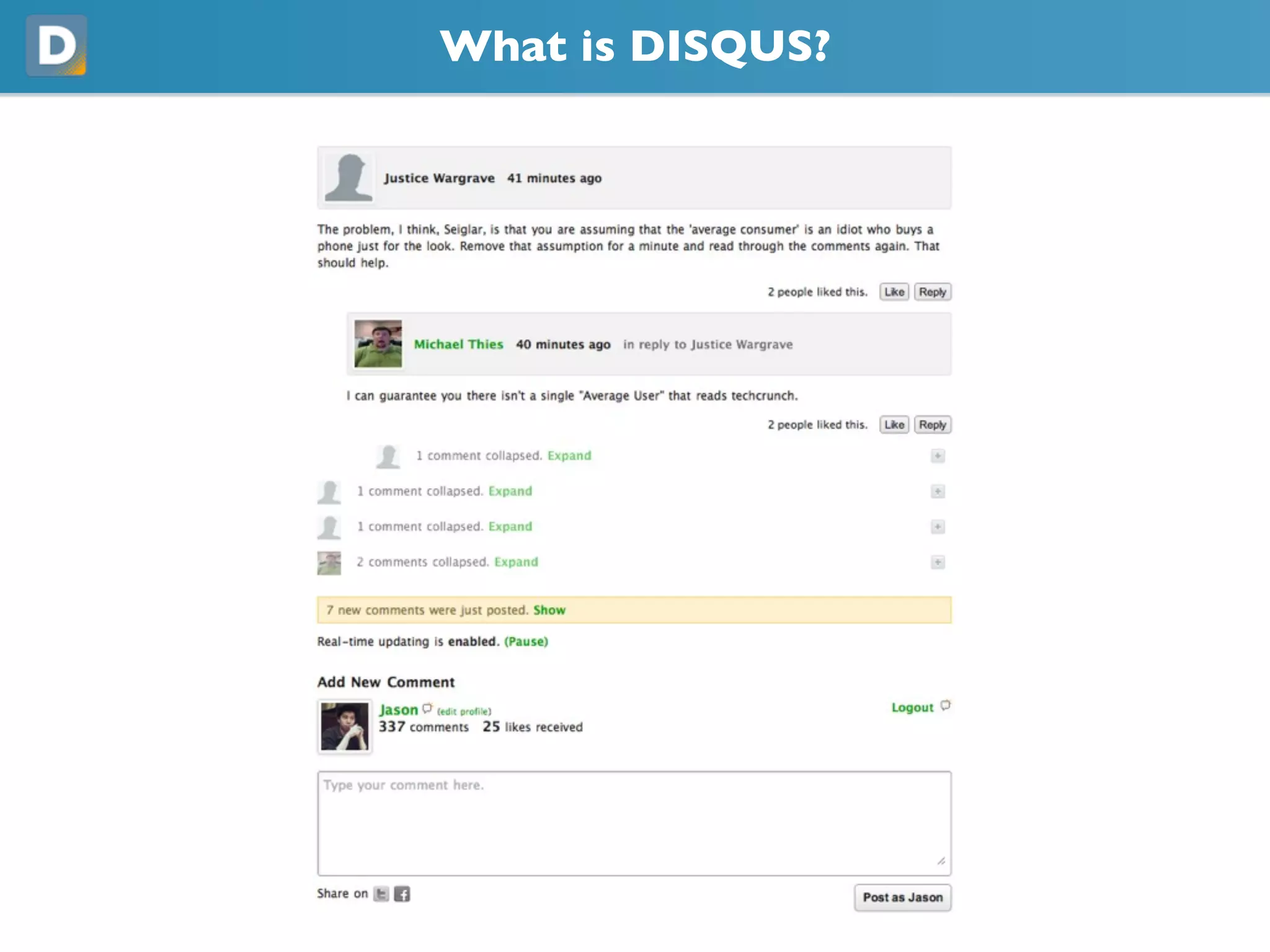
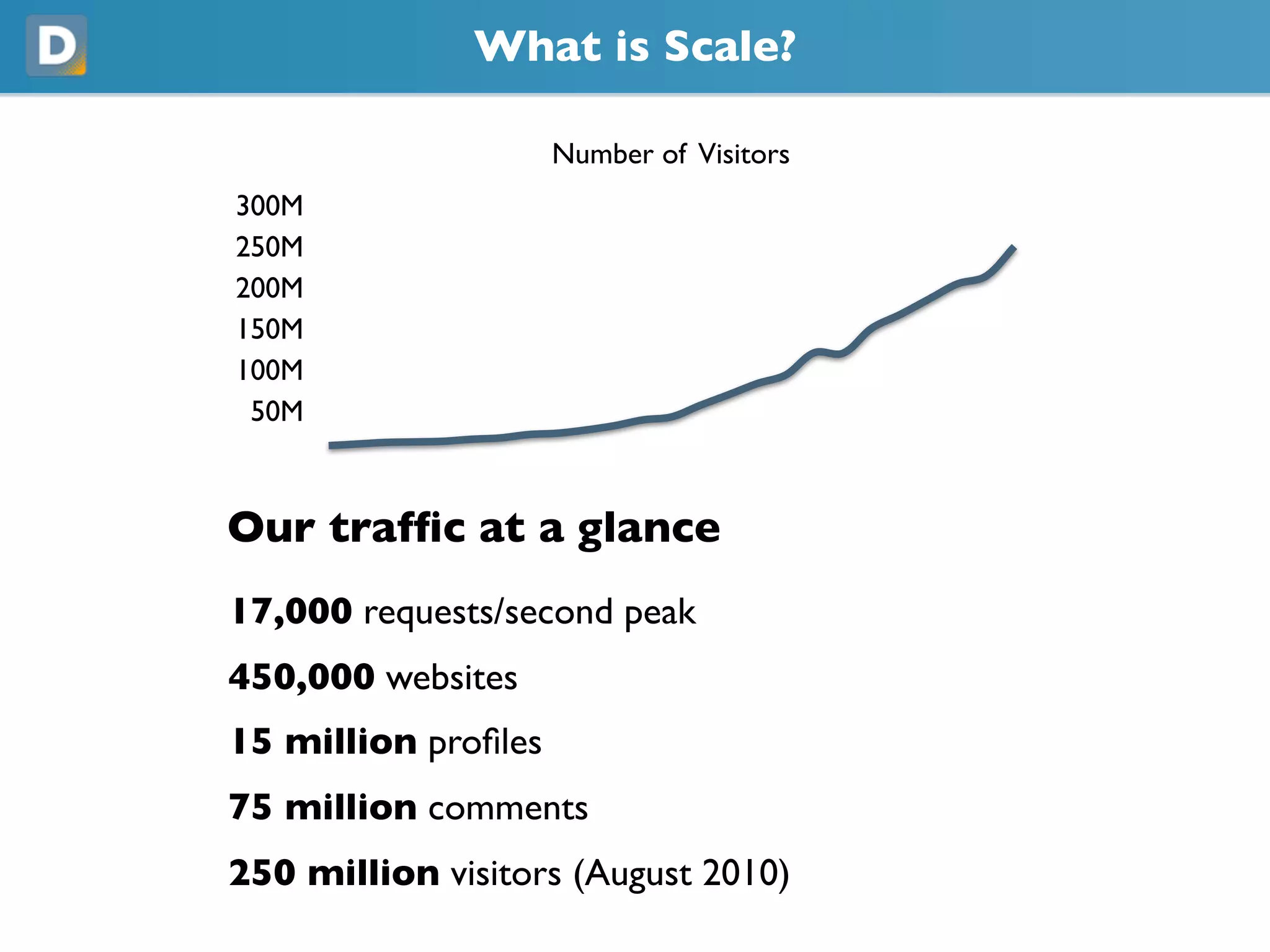
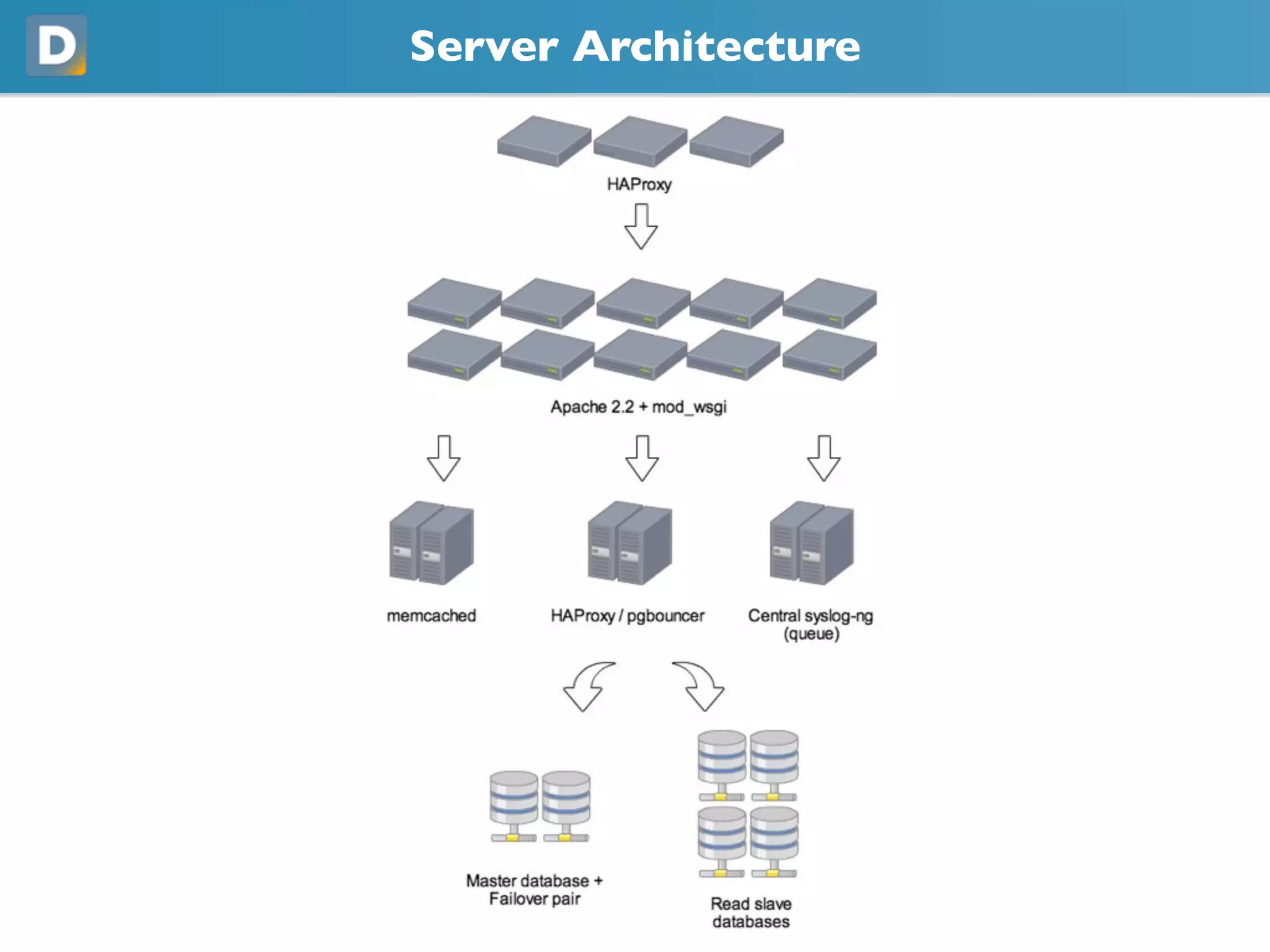
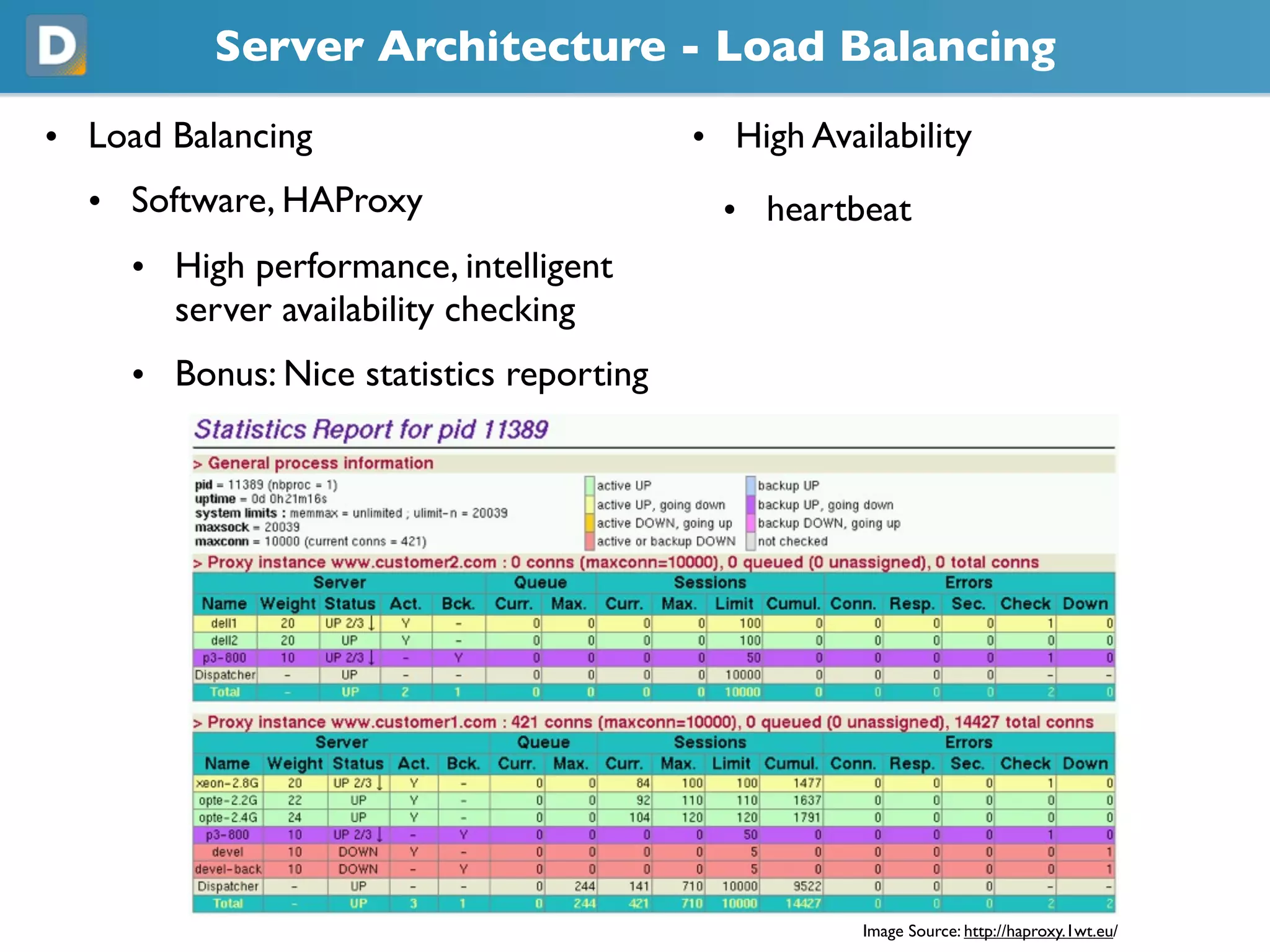
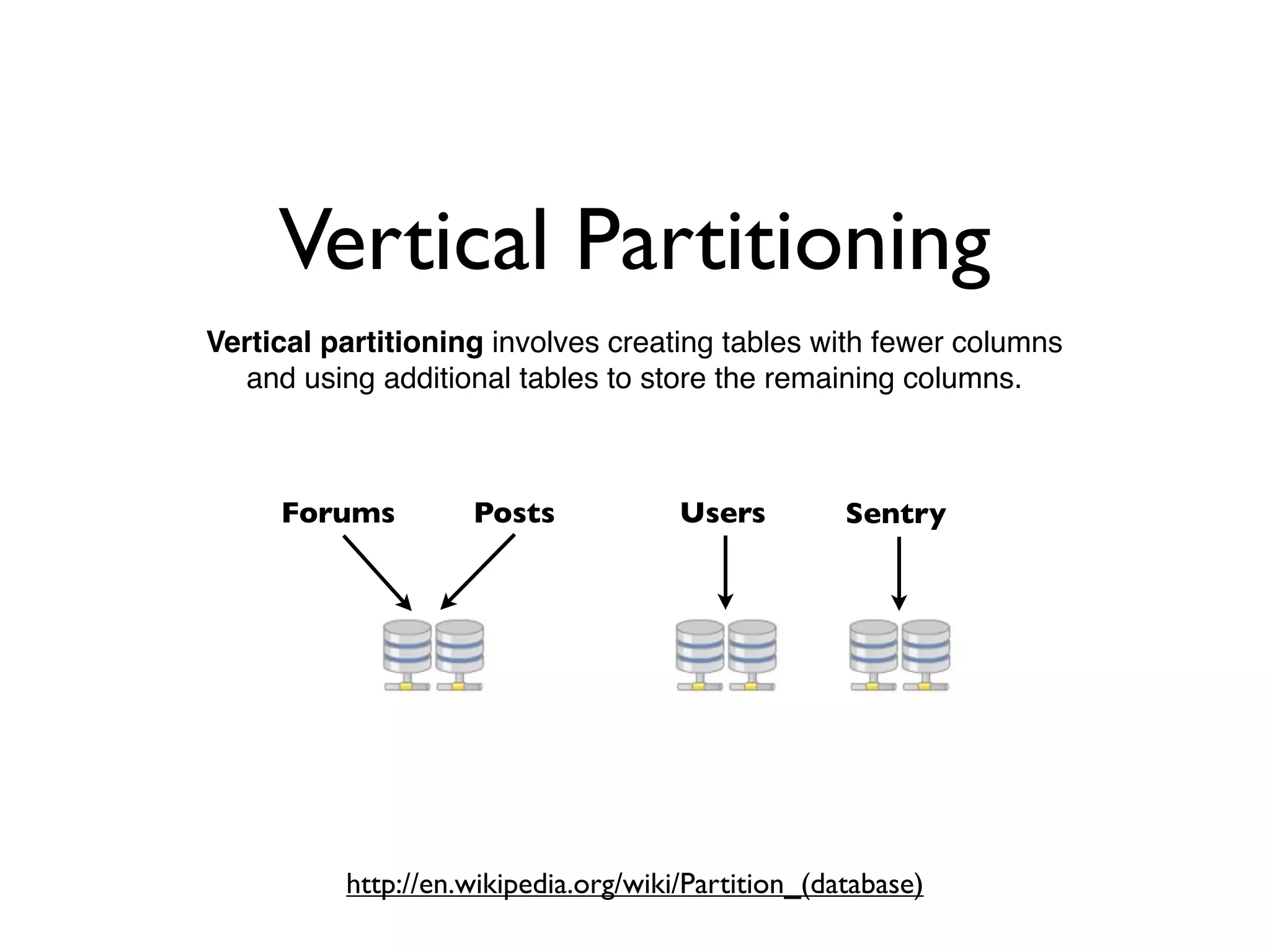
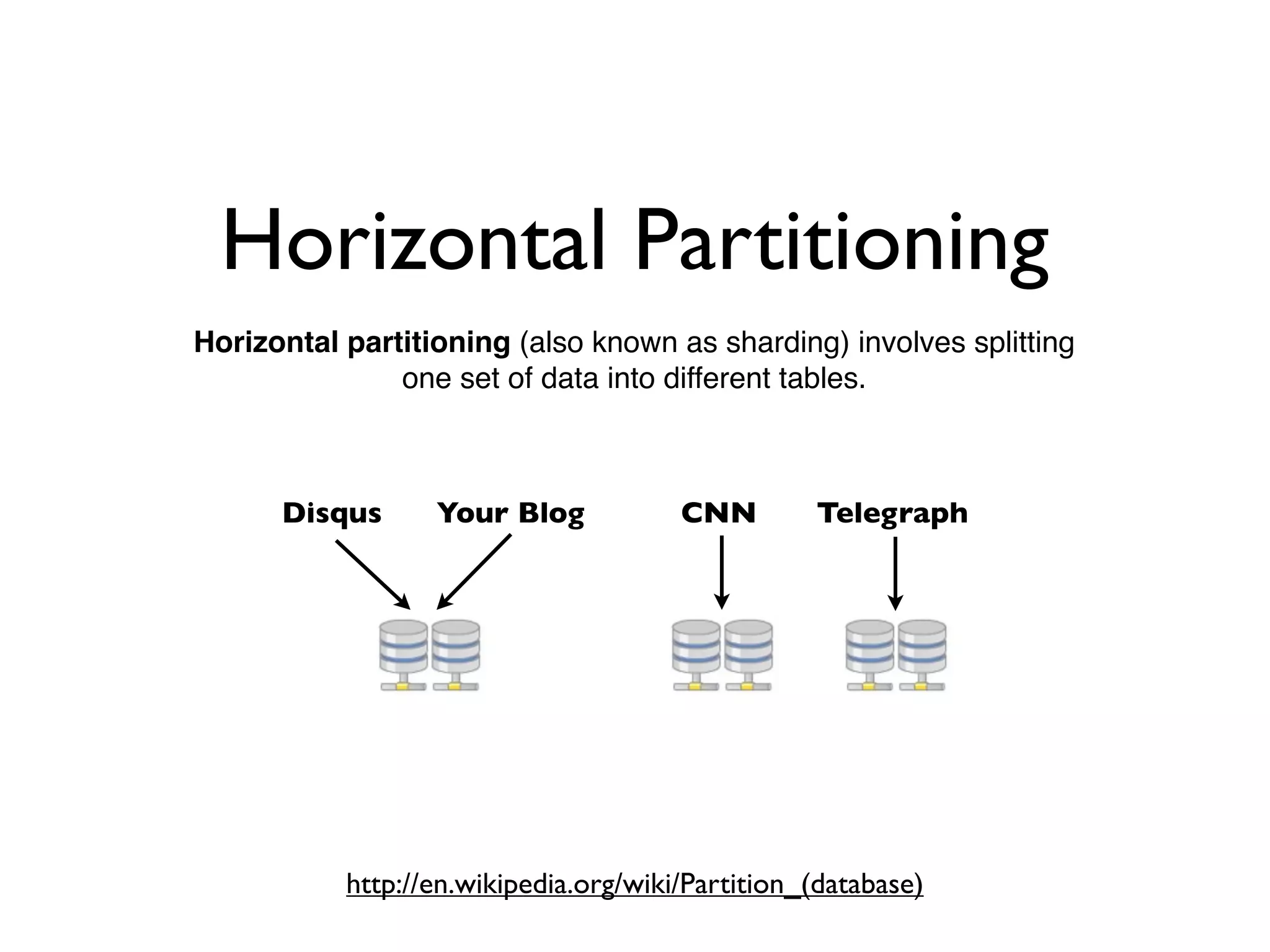
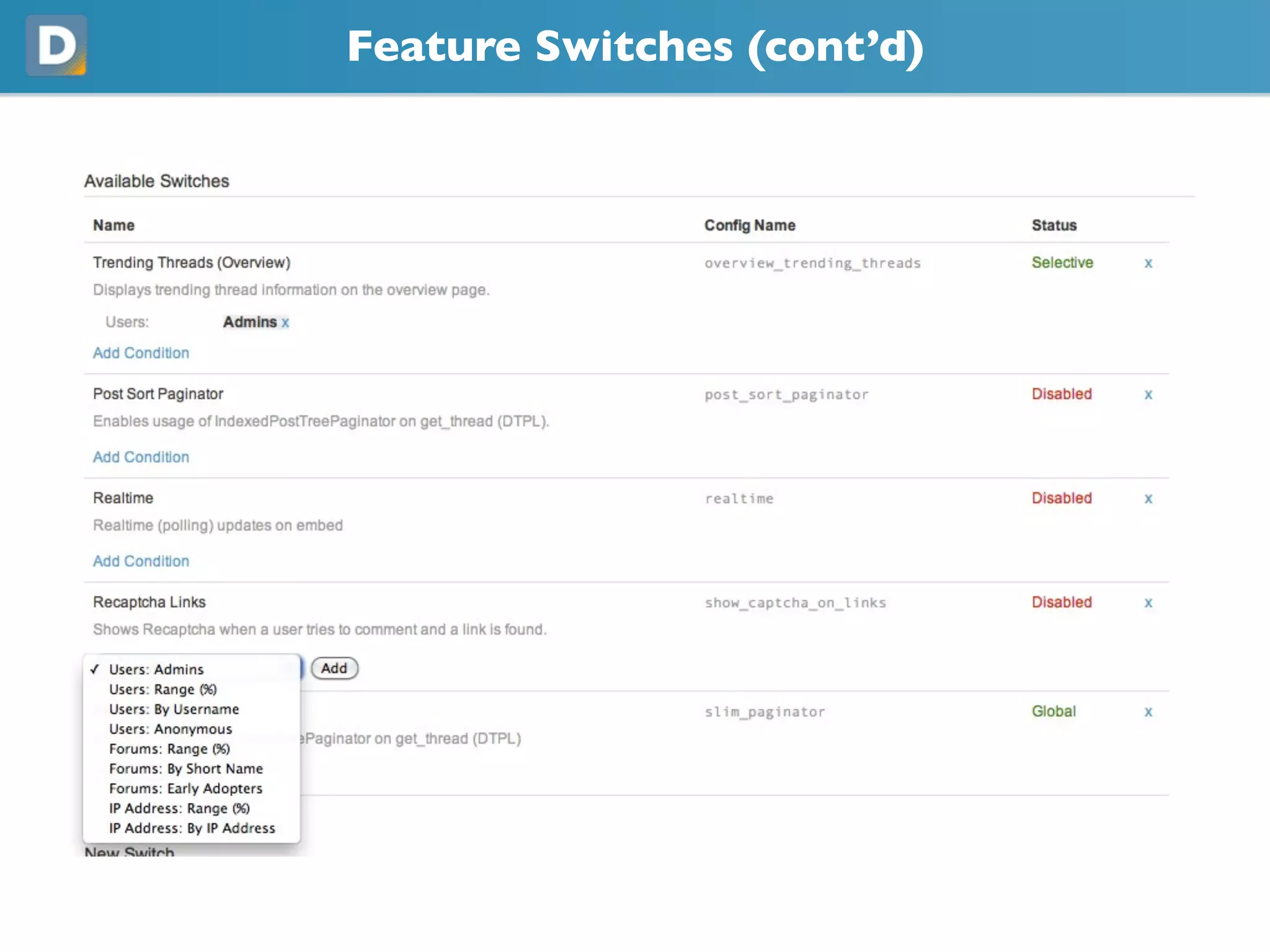
DISQUS is a comment system that handles high volumes of traffic, with up to 17,000 requests per second and 250 million monthly visitors. They face challenges in unpredictable spikes in traffic and ensuring high availability. Their architecture includes over 100 servers split between web servers, databases, caching, and load balancing. They employ techniques like vertical and horizontal data partitioning, atomic updates, delayed signals, consistent caching, and feature flags to scale their large Django application.










![Pythonic Joins
Allows us to separate datasets
posts = Post.objects.all()[0:25]
# store users in a dictionary based on primary key
users = dict(
(u.pk, u) for u in
User.objects.filter(pk__in=set(p.user_id for p in posts))
)
# map users to their posts
for p in posts:
p._user_cache = users.get(p.user_id)](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-17-2048.jpg)






![Removing the Cache
• Django internally caches the results of your QuerySet
• This adds additional memory overhead
# 1 query
qs = Model.objects.all()[0:100]
# 0 queries (we don’t need this behavior)
qs = qs[0:10]
# 1 query
qs = qs.filter(foo=bar)
• Many times you only need to view a result set once
• So we built SkinnyQuerySet](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-25-2048.jpg)






![Delayed Signals (cont’d)
We send a specific serialized version
of the model for delayed signals
from disqus.common.signals import delayed_save
def my_func(data, sender, created, **kwargs):
print data[‘id’]
delayed_save.connect(my_func, sender=Post)
This is all handled through our Queue](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-32-2048.jpg)


![Caching (cont’d)
• Default (naive) hashing behavior
• Modulo hashed cache key cache for index
to server list.
• Removal of a server causes majority of
cache keys to be remapped to new
servers.
CACHE_SERVERS = [‘10.0.0.1’, ‘10.0.0.2’]
key = ‘my_cache_key’
cache_server = CACHE_SERVERS[hash(key) % len(CACHE_SERVERS)]](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-35-2048.jpg)


![Transactions
• TransactionMiddleware got us started, but
down the road became a burden
• For postgresql_psycopg2, there’s a database
option, OPTIONS[‘autocommit’]
• Each query is in its own transaction. This
means each request won’t start in a
transaction.
• But sometimes we want transactions
(e.g., saving multiple objects and rolling
back on error)](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-38-2048.jpg)








![Testing (cont’d)
Query Counts
# failures yield a dump of queries
def test_read_slave(self):
Model.objects.using(‘read_slave’).count()
self.assertQueryCount(1, ‘read_slave’)
Selenium
def test_button(self):
self.selenium.click('//a[@class=”dsq-button”]')
Queue Integration
class WorkerTest(DisqusTest):
workers = [‘fire_signal’]
def test_delayed_signal(self):
...](https://image.slidesharecdn.com/djangocon2010scalingdisqus-100907133713-phpapp01/75/DjangoCon-2010-Scaling-Disqus-47-2048.jpg)







![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)














































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













