Download as PDF, PPTX

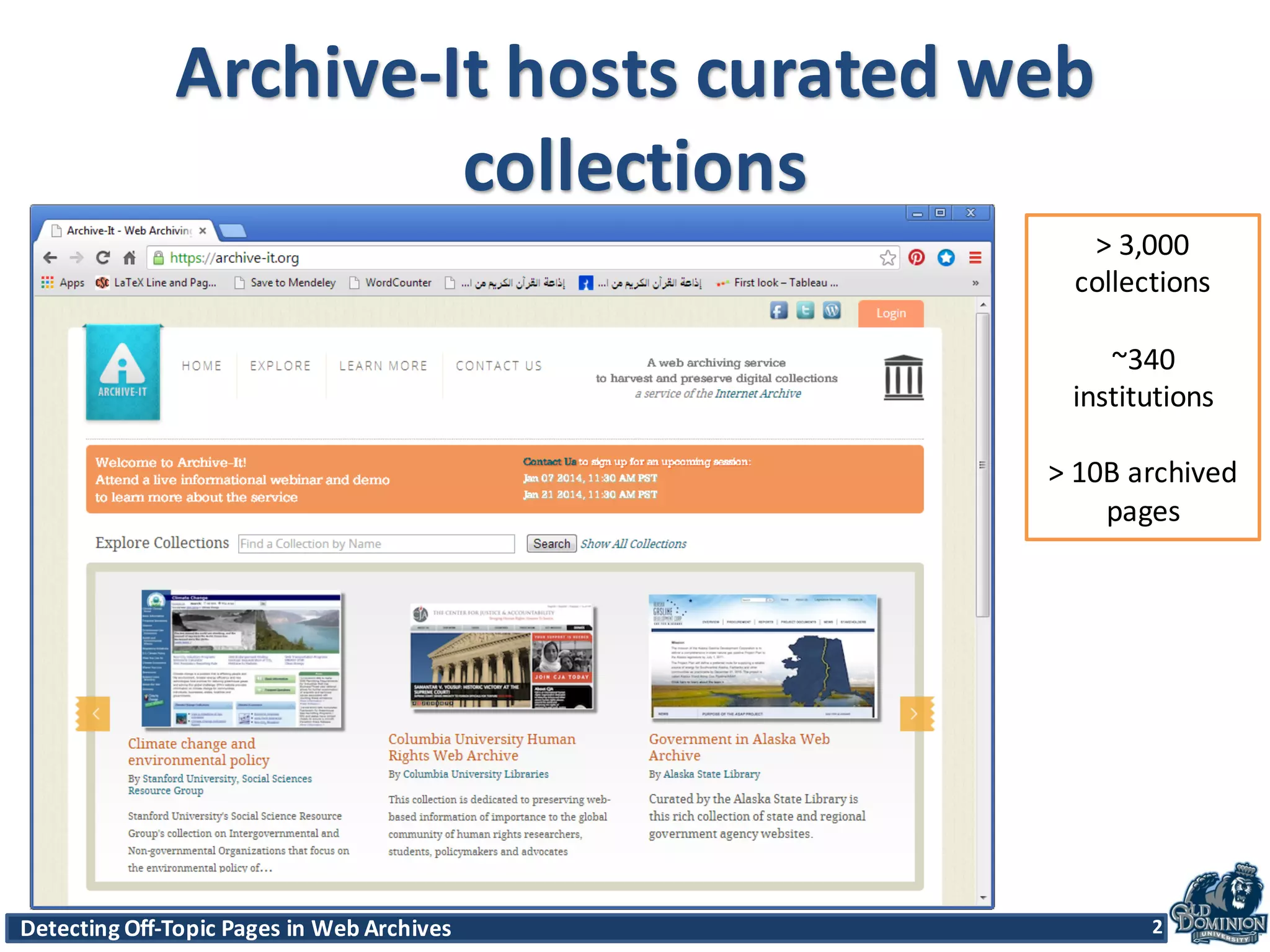
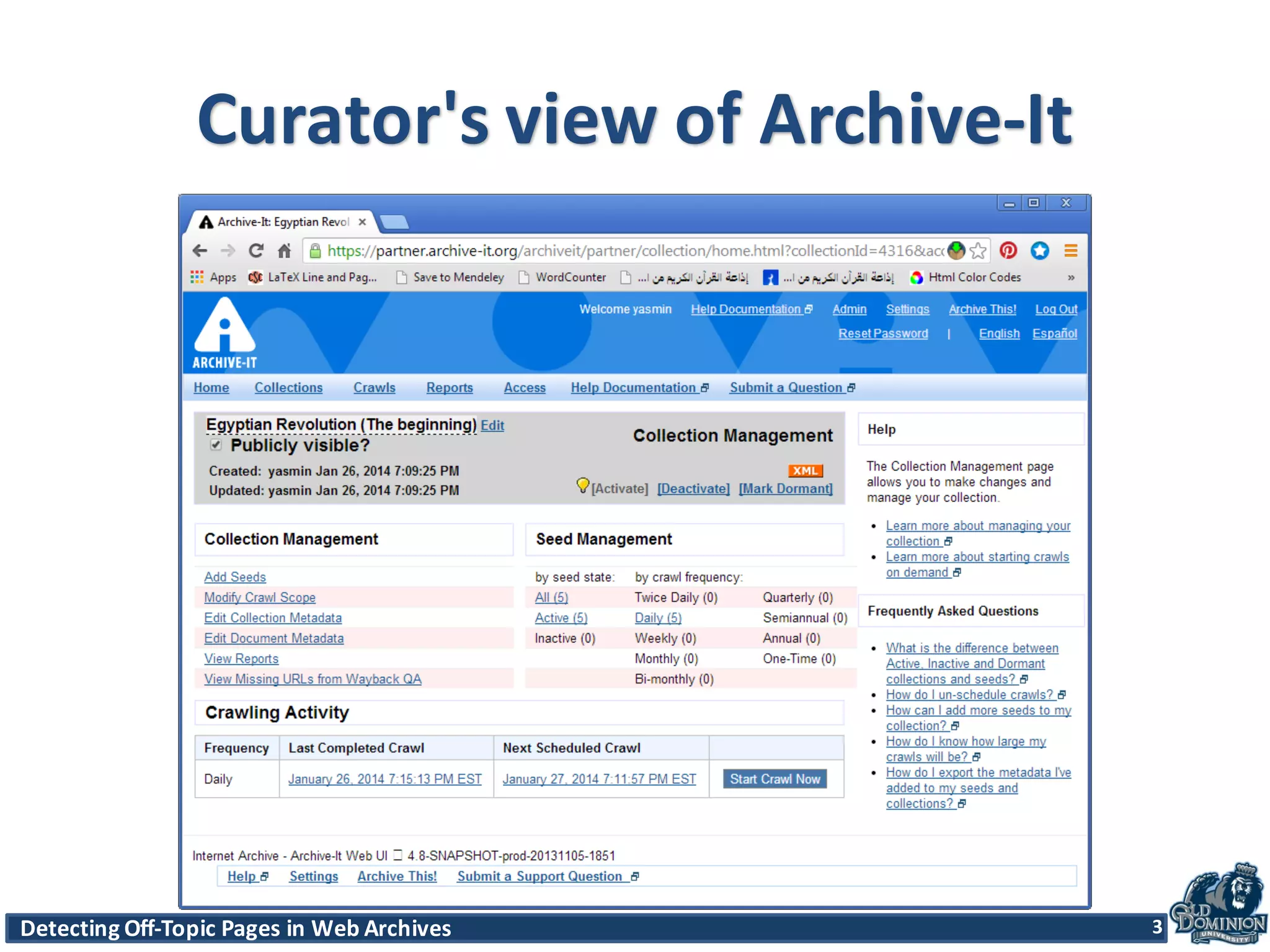
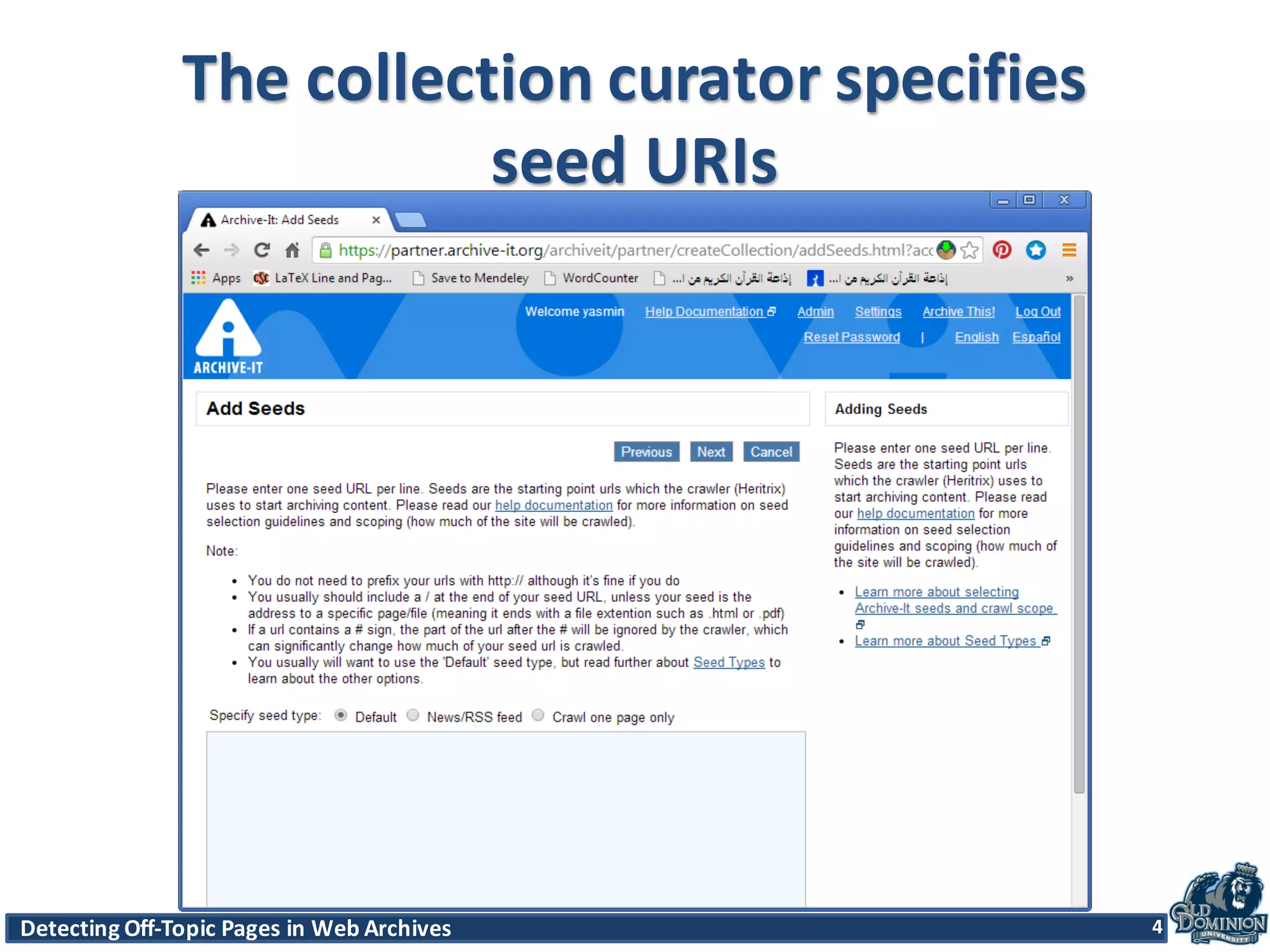
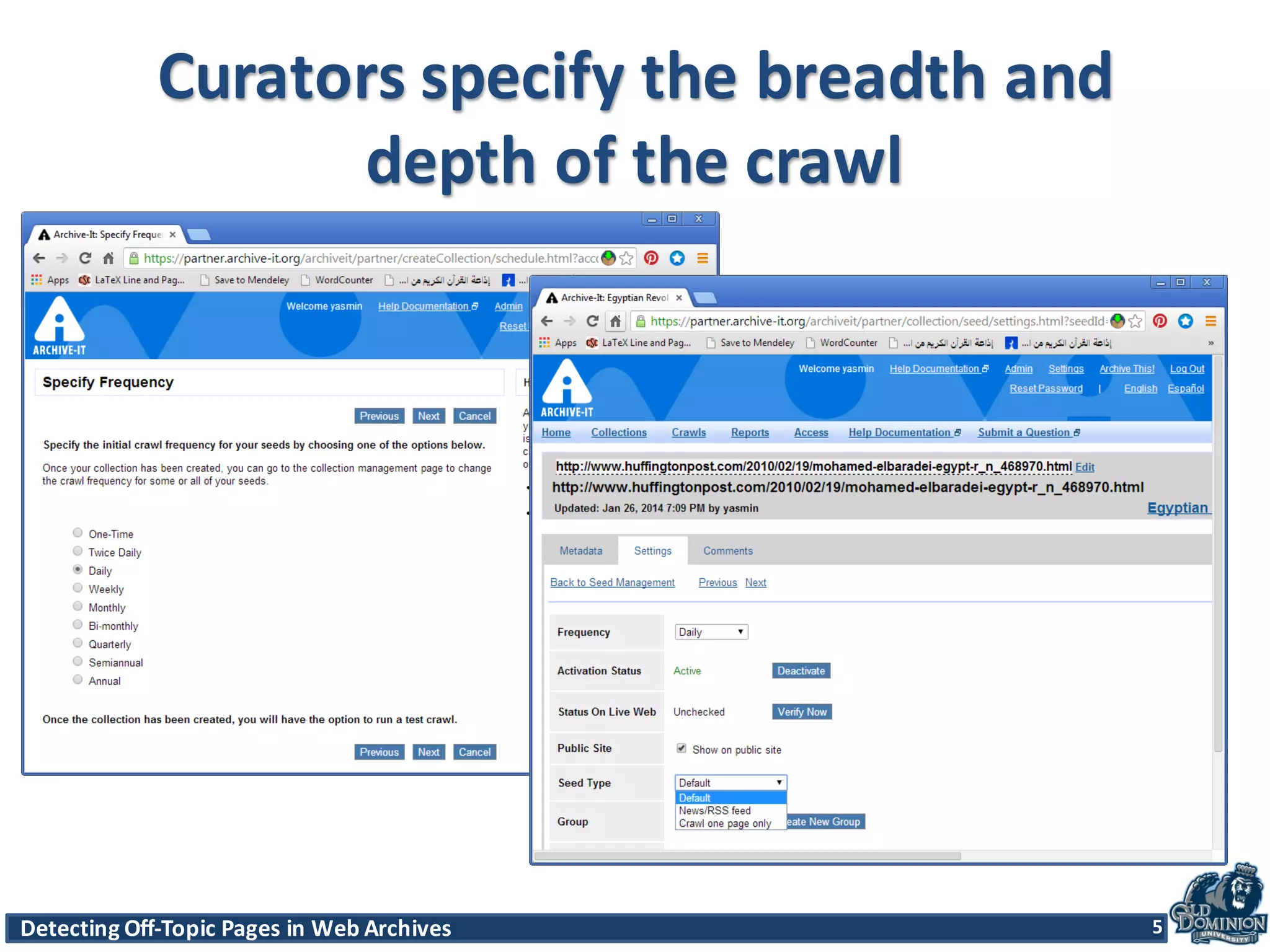
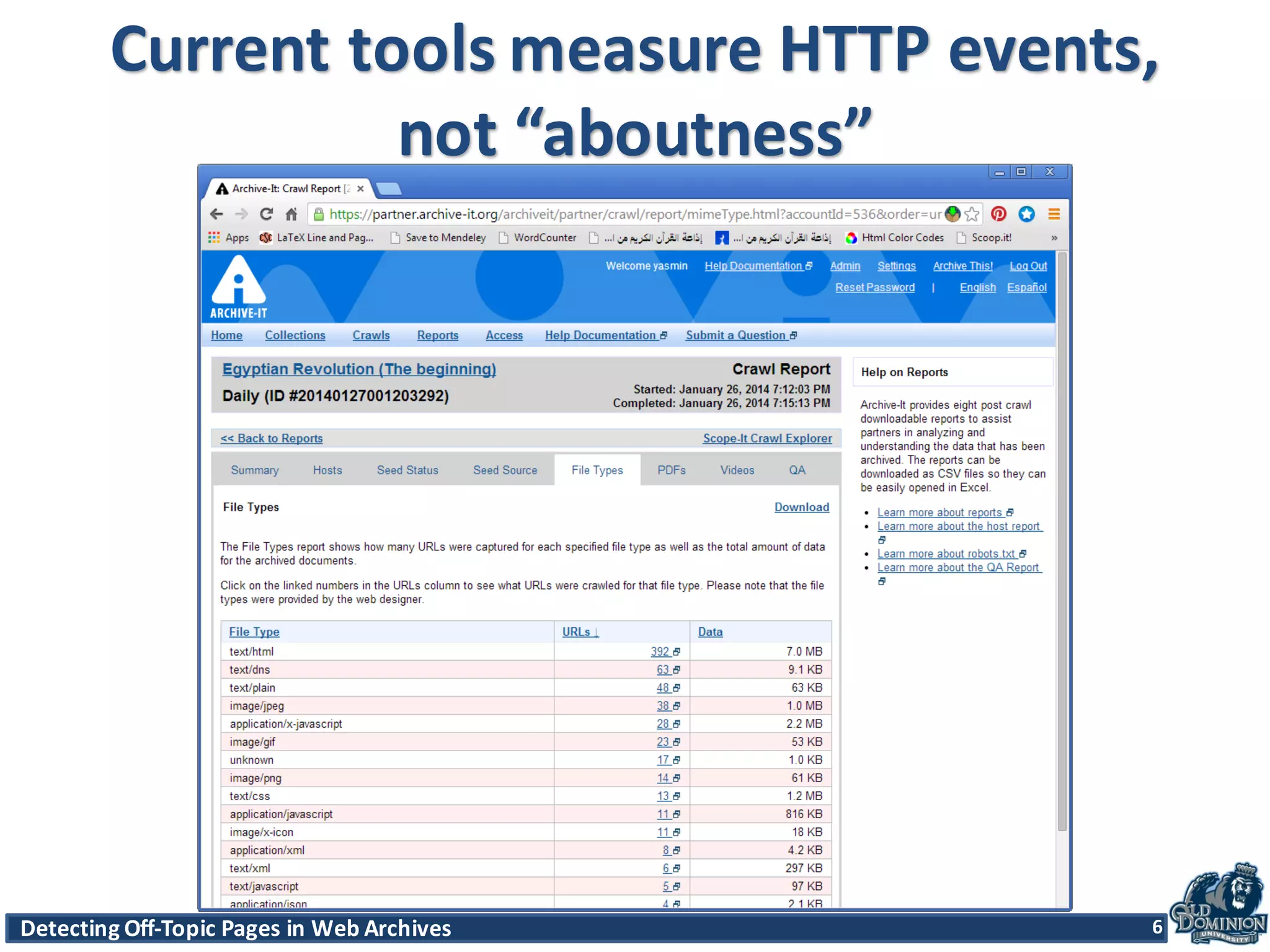


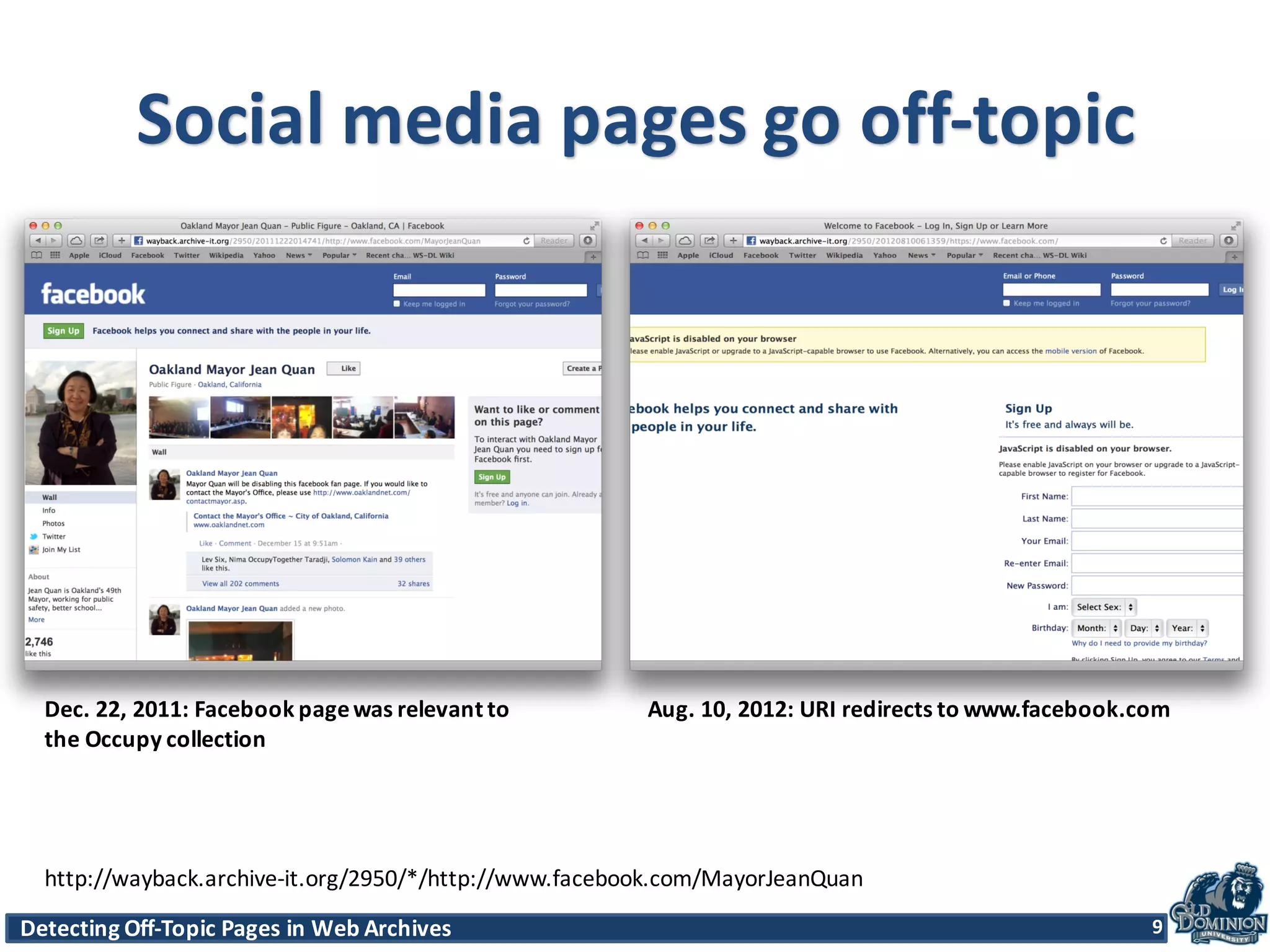

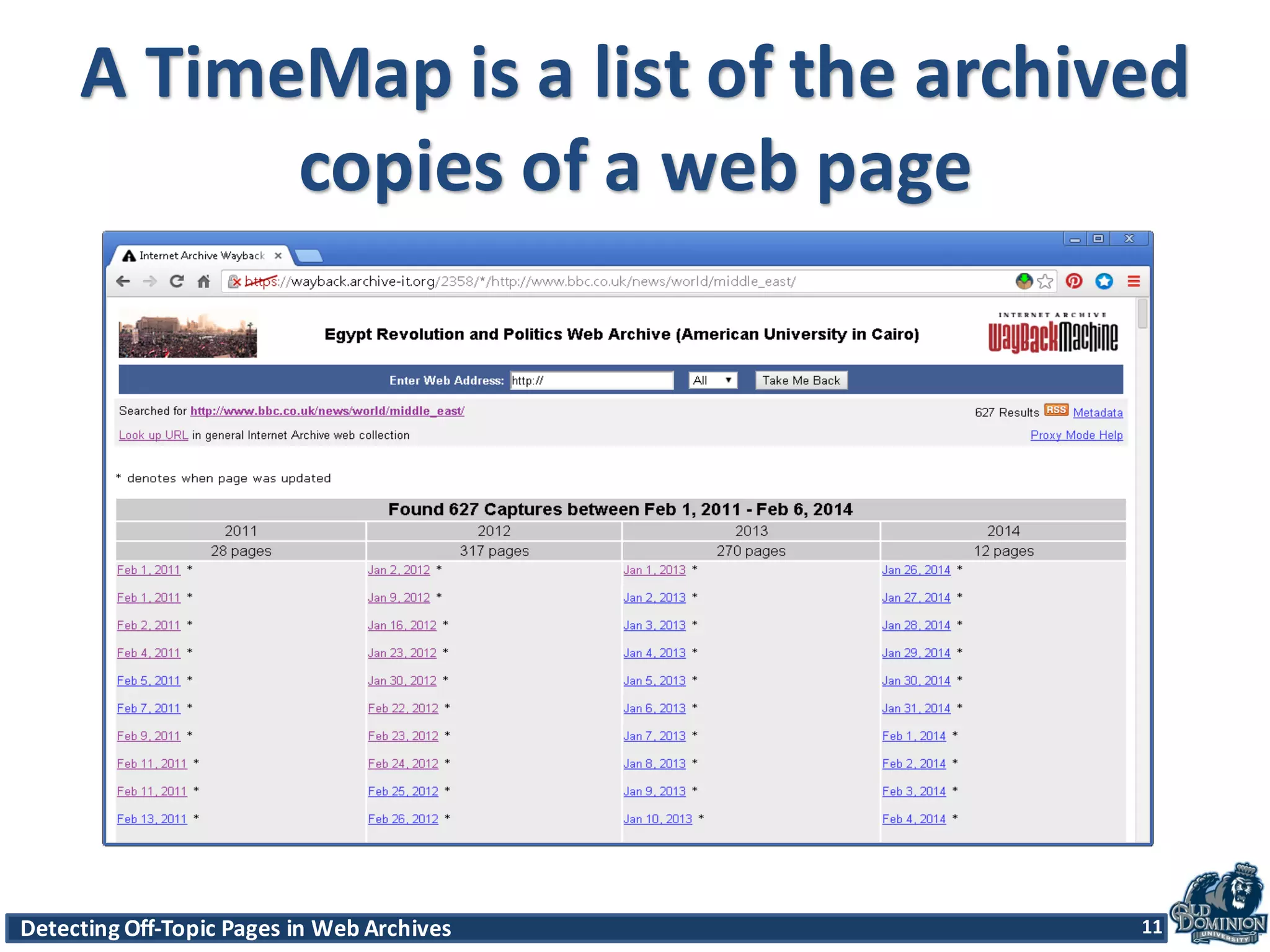
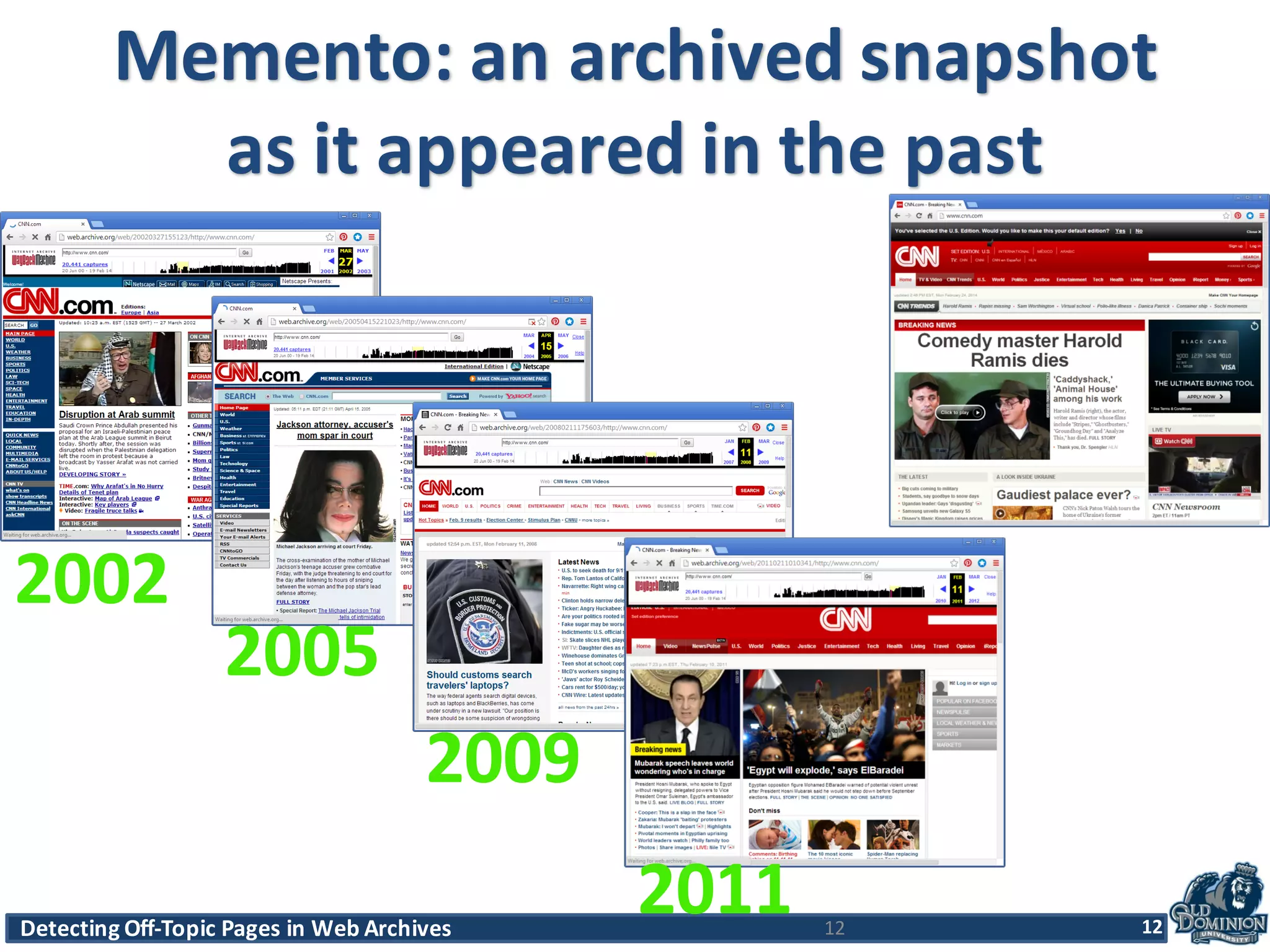


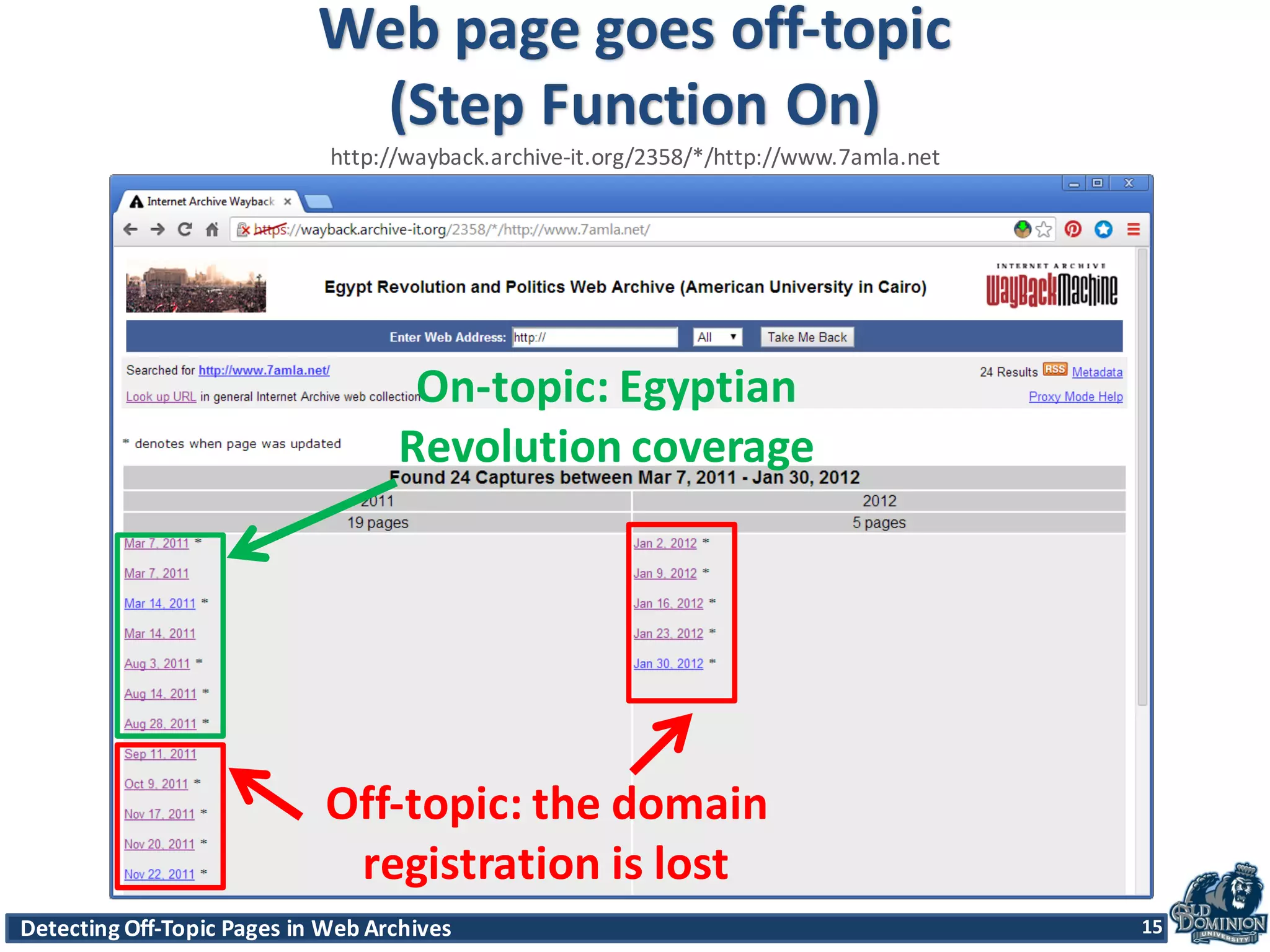
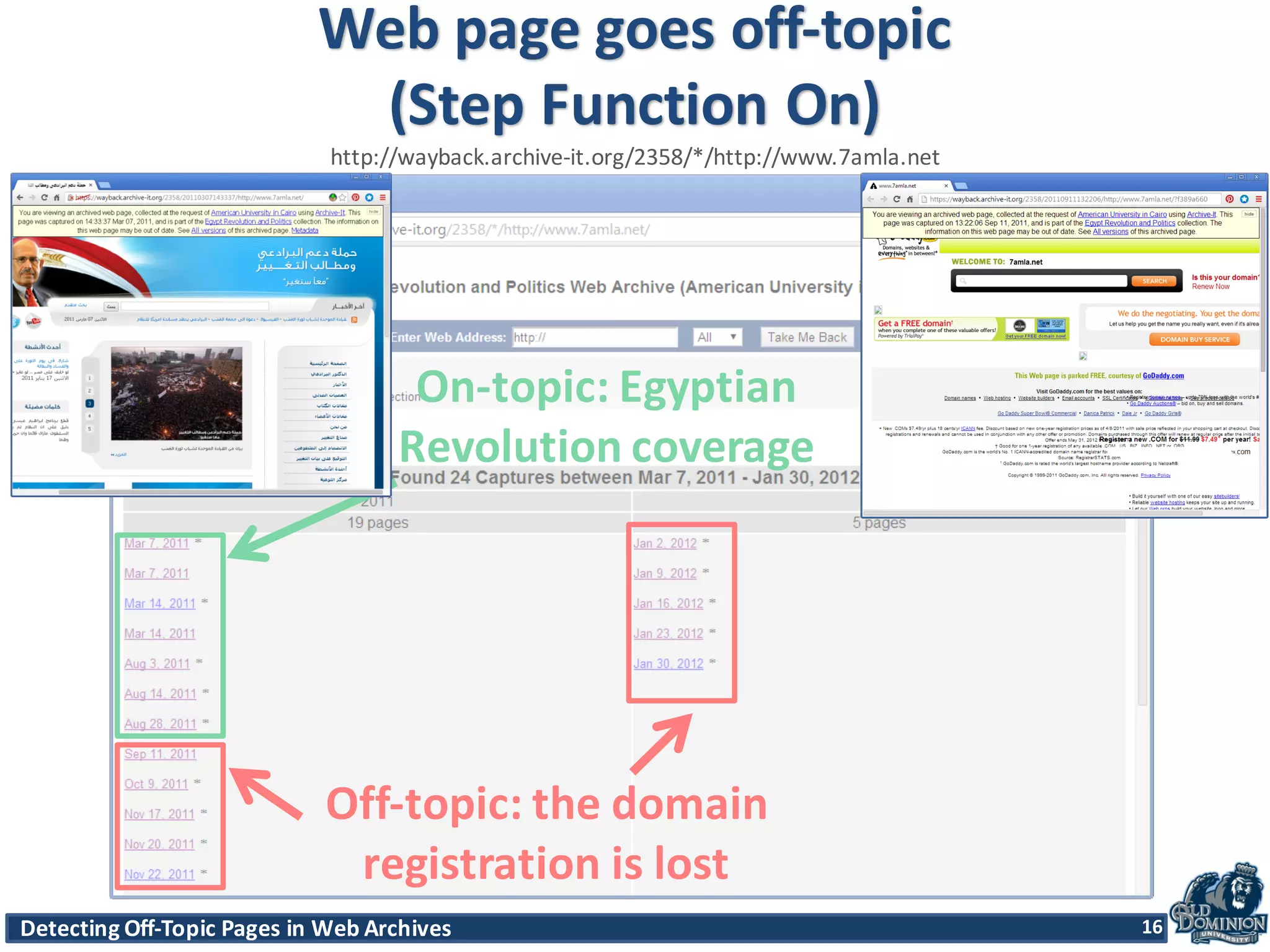
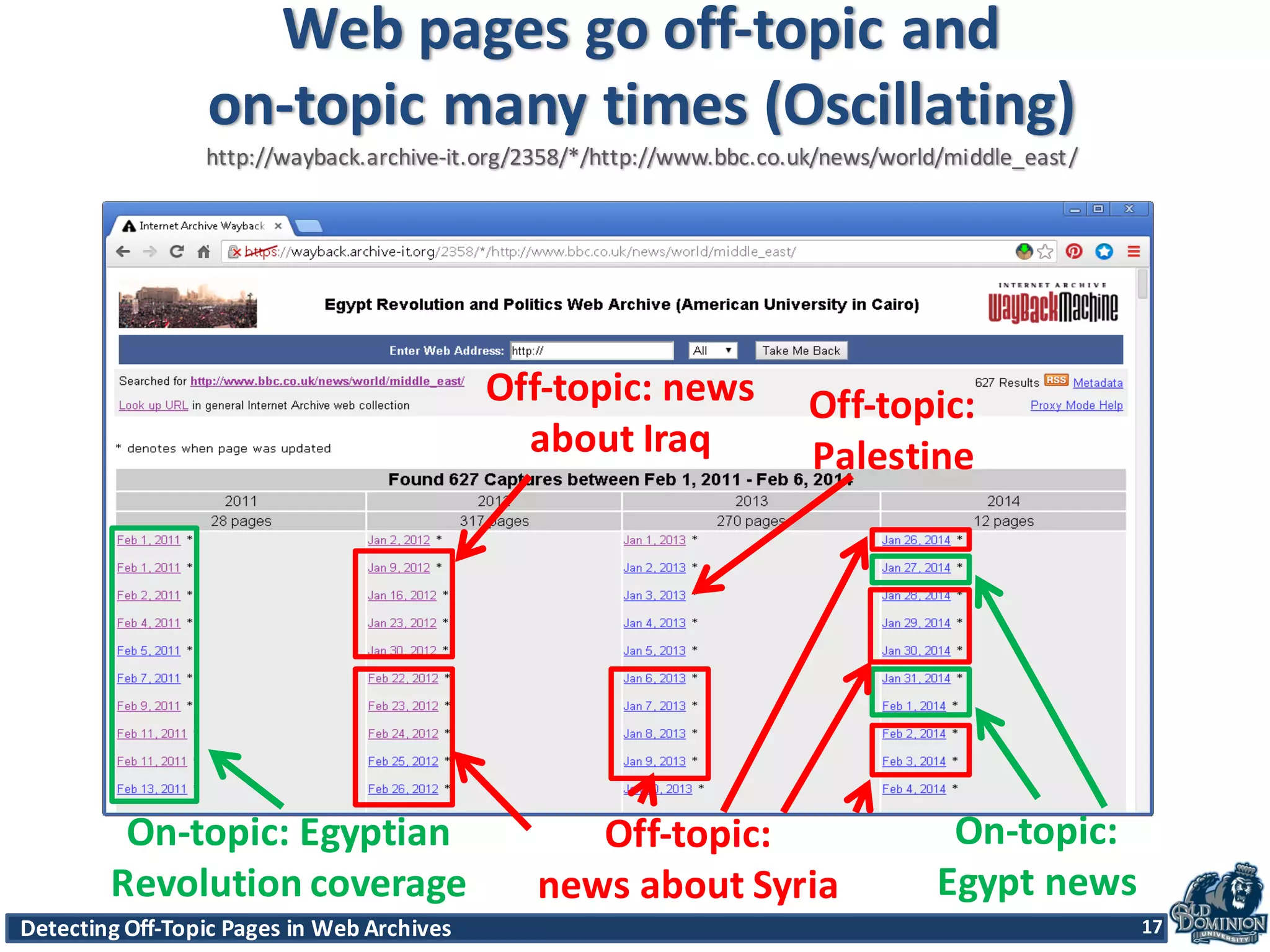
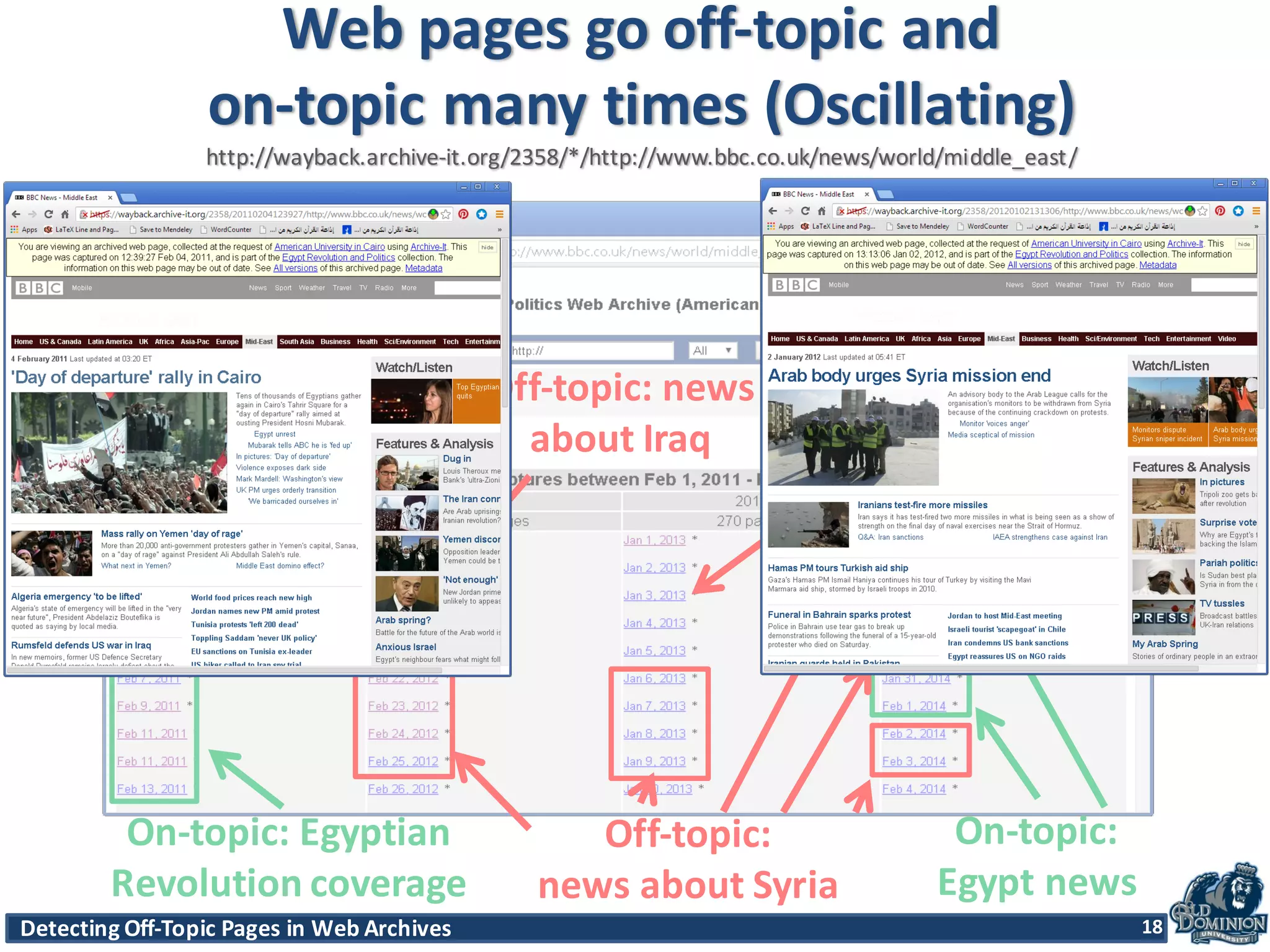















The document discusses techniques for detecting off-topic pages in web archives, particularly using Archive-It collections which contain millions of archived pages. It outlines the importance of assessing page relevancy over time, discovers various classifications of page behavior, and presents multiple methods for evaluating similarity and off-topic classification. The research evaluates a gold standard dataset and applies best methods to assess accuracy and precision across various collections.
















































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)














