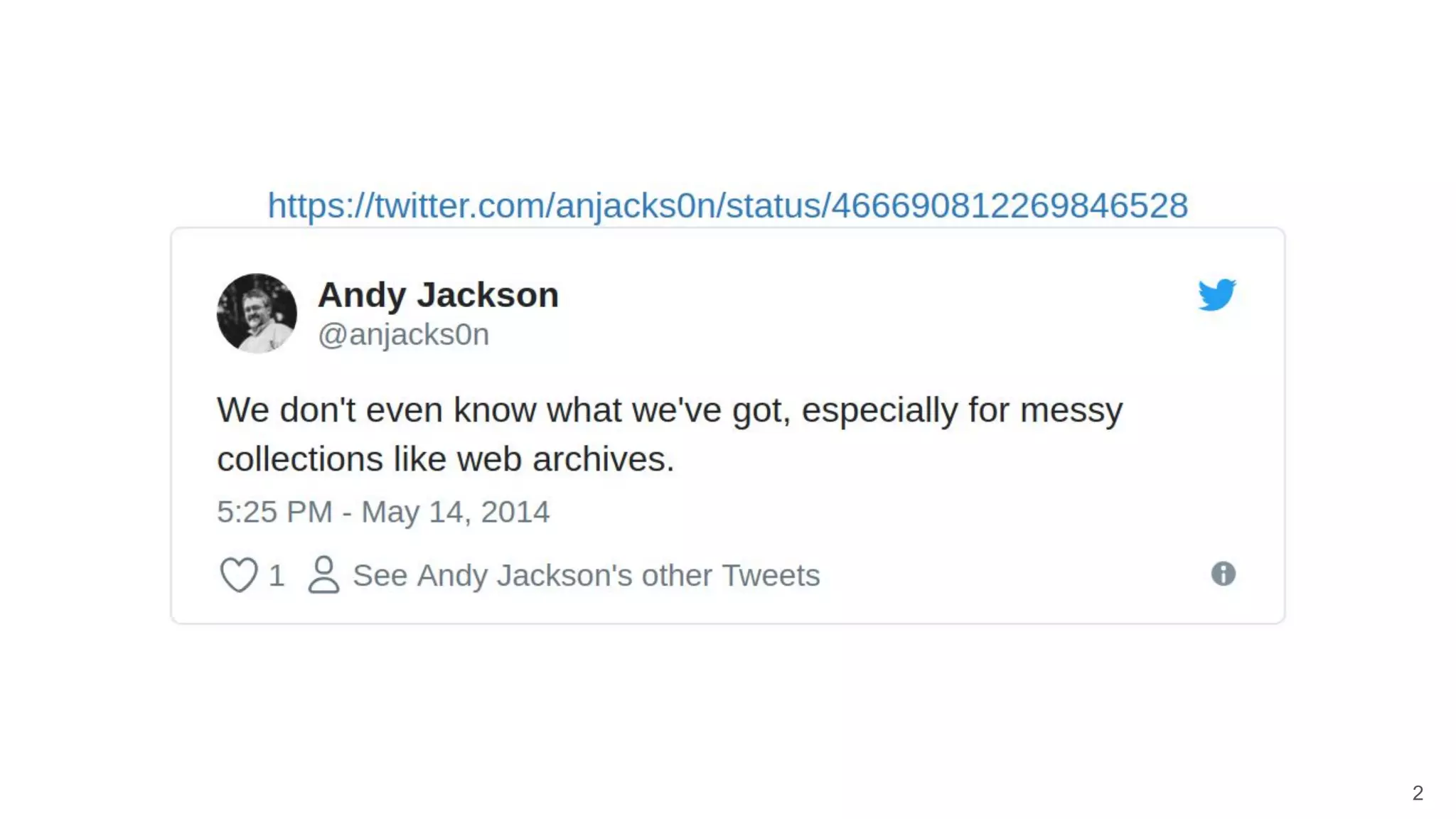
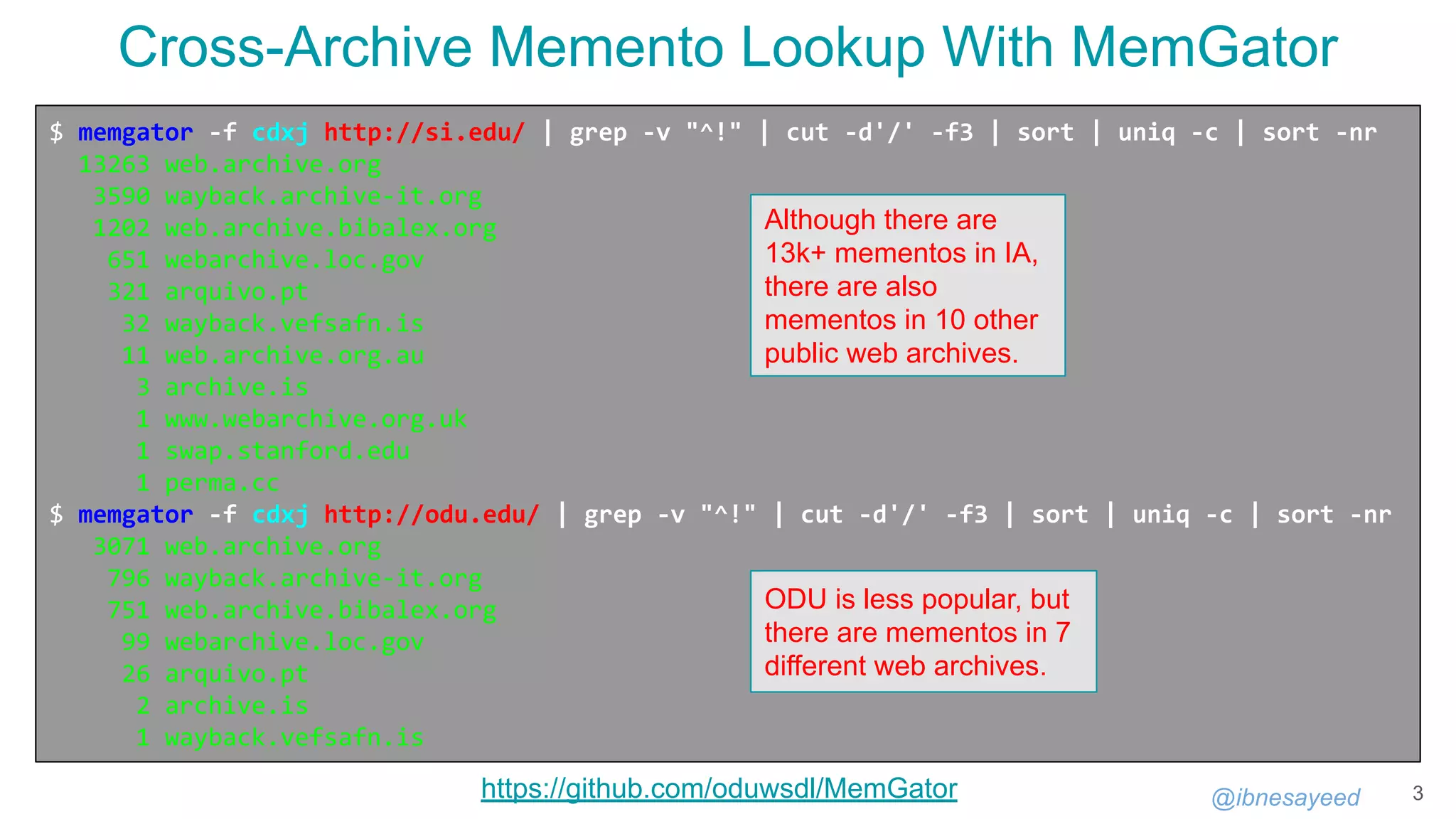
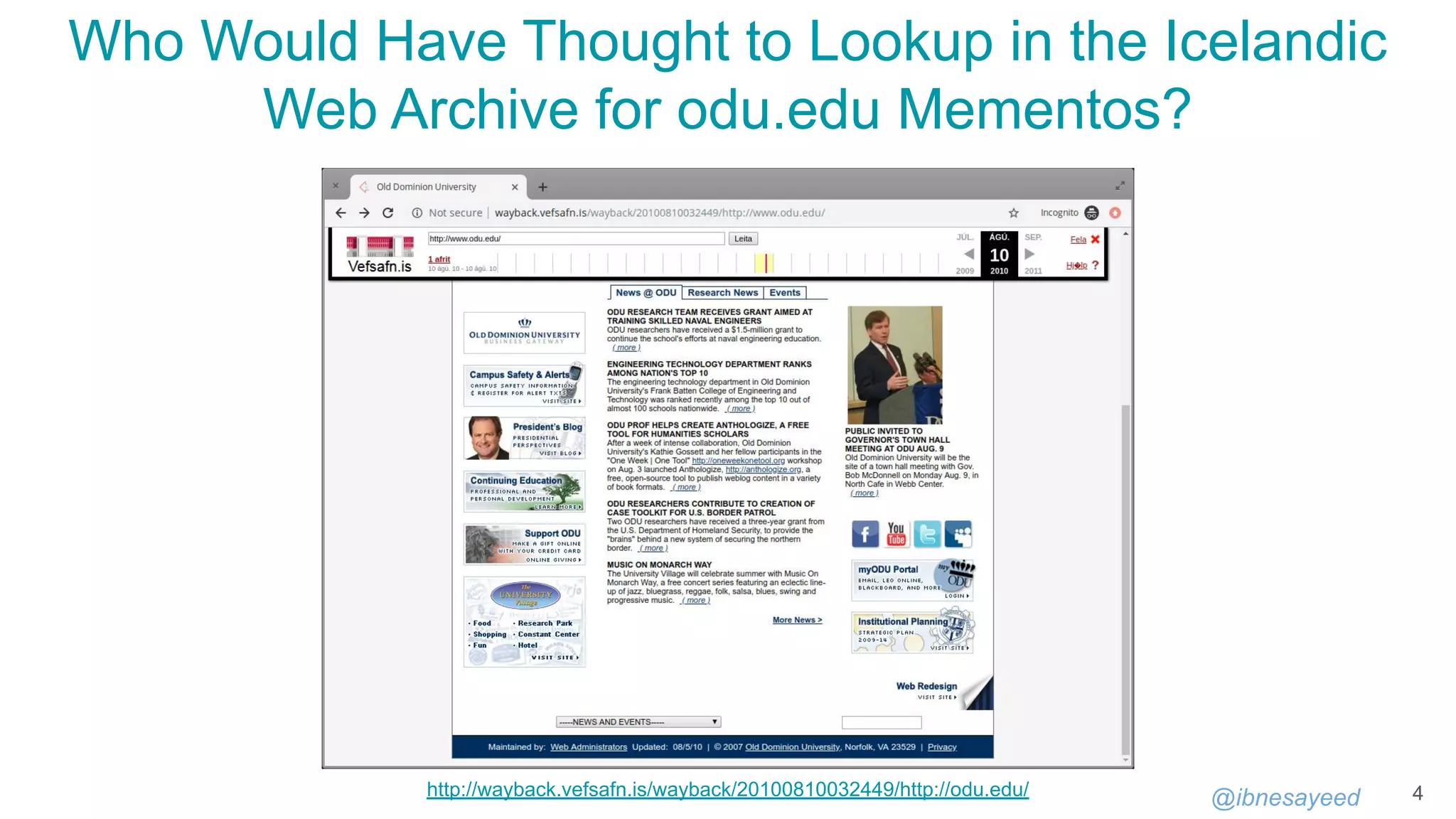
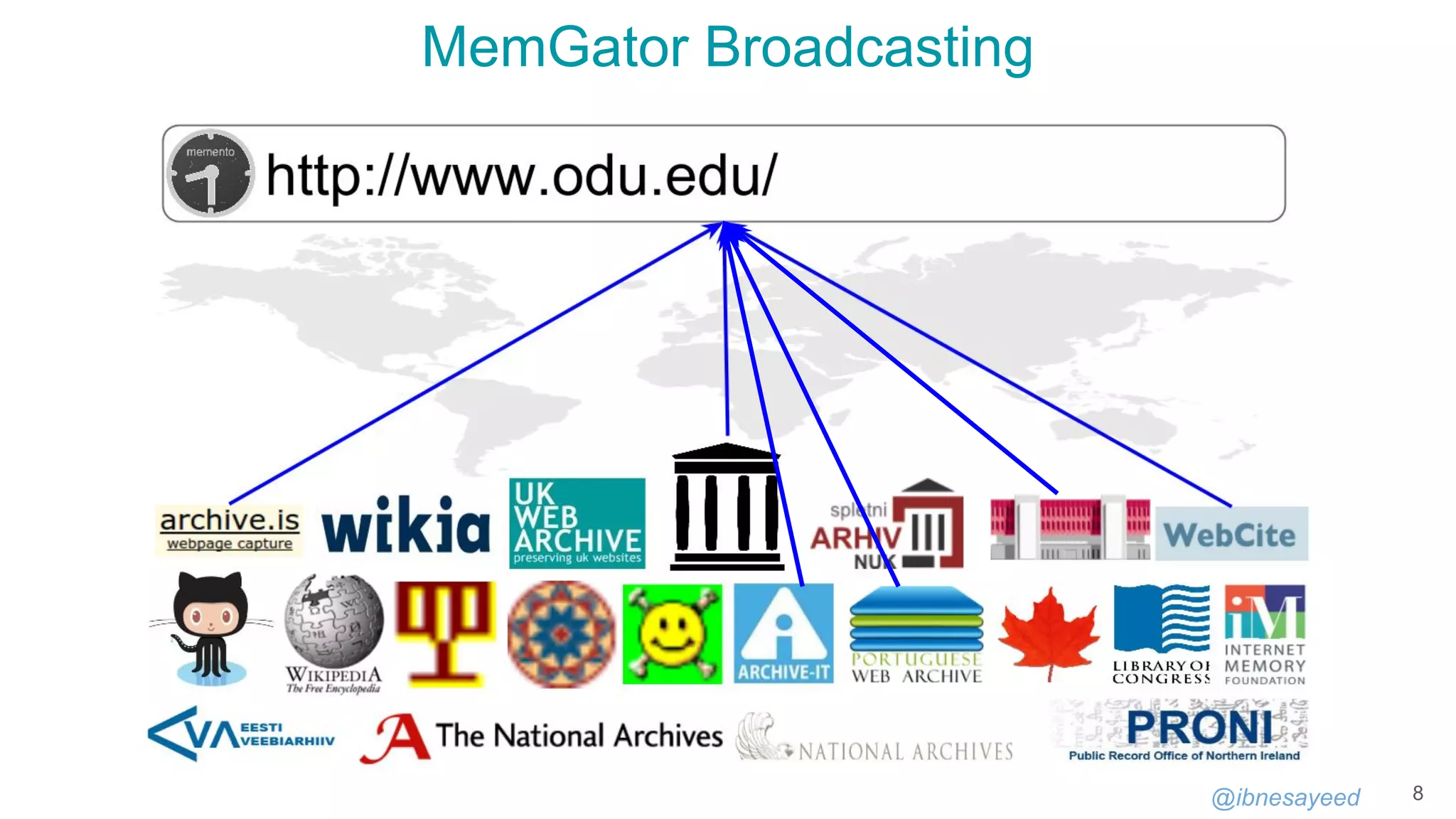
Download to read offline







![@ibnesayeed
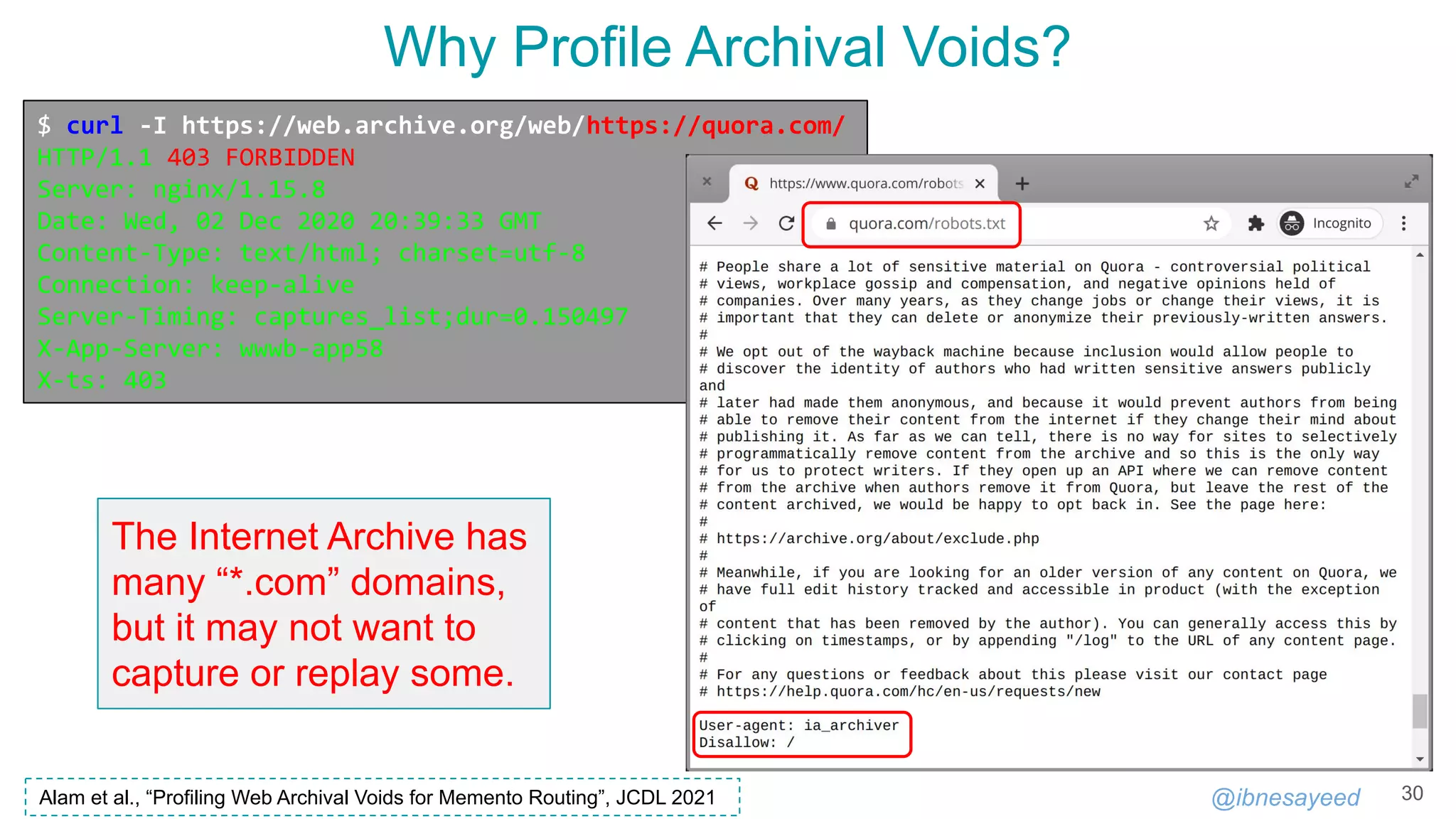
Archive Profiling Strategies
● Complete URI-R Profiling (1 URI-R = 1 Profile Key) [Sanderson et al., TPDL 2012]
○ bbc.co.uk/images/logo.png?w=90
○ cnn.com/2014/03/15/?id=128734
● TLD-Only Profiling (1 TLD = 1 Profile Key) [AlSum, et al., TPDL 2013]
○ *.com
○ *.uk
● Middle Ground
○ *.cnn.com
○ *.co.uk
○ *.bbc.co.uk
○ bbc.co.uk/images/*
17
We explore
these strategies
in this work.
Top three archives after
IA produce full TimeMaps
52% of the time.](https://image.slidesharecdn.com/mementomap-iipc-wac-2021-210607171439/75/Summarize-Your-Archival-Holdings-With-MementoMap-17-2048.jpg)



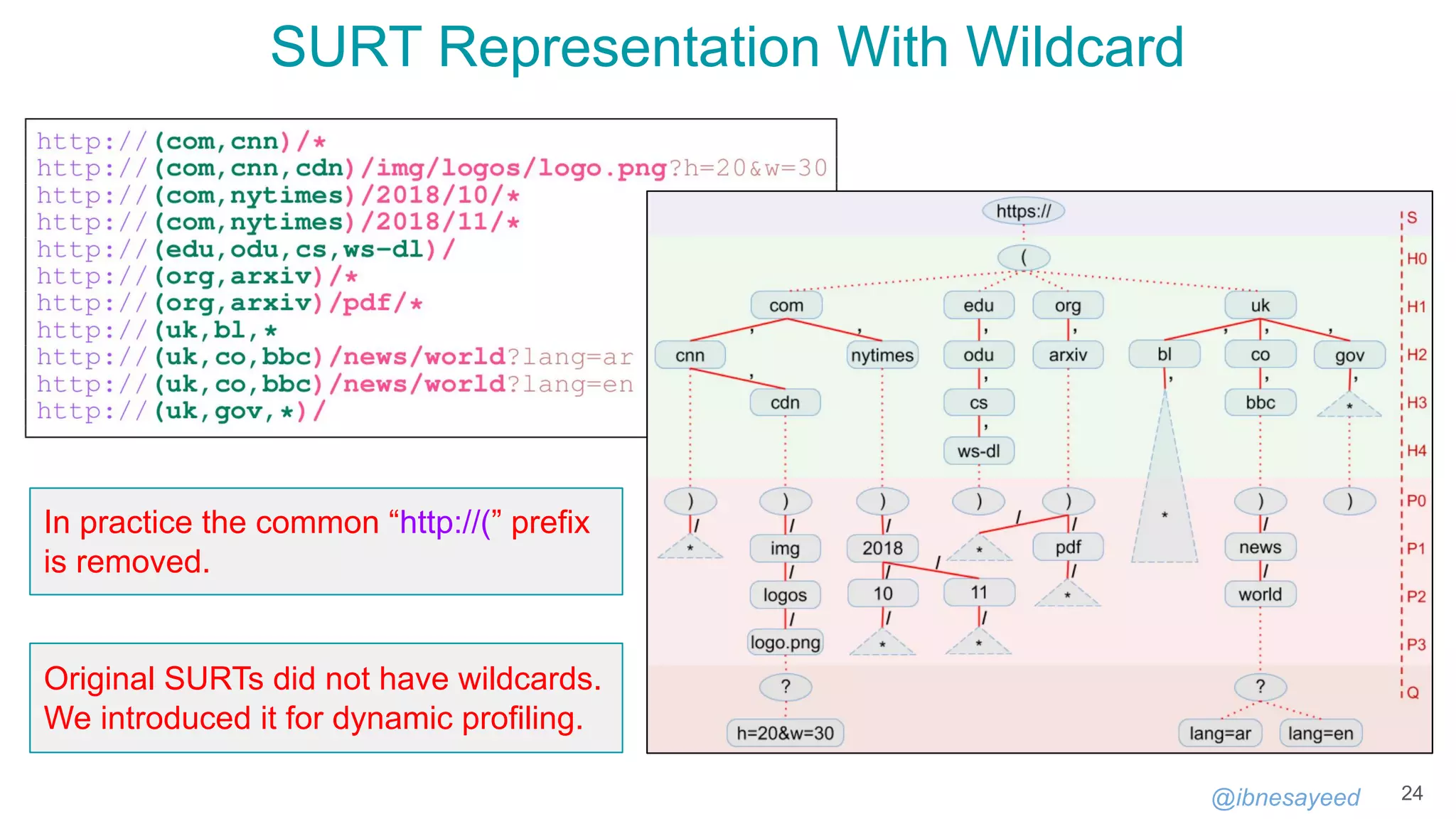
![@ibnesayeed
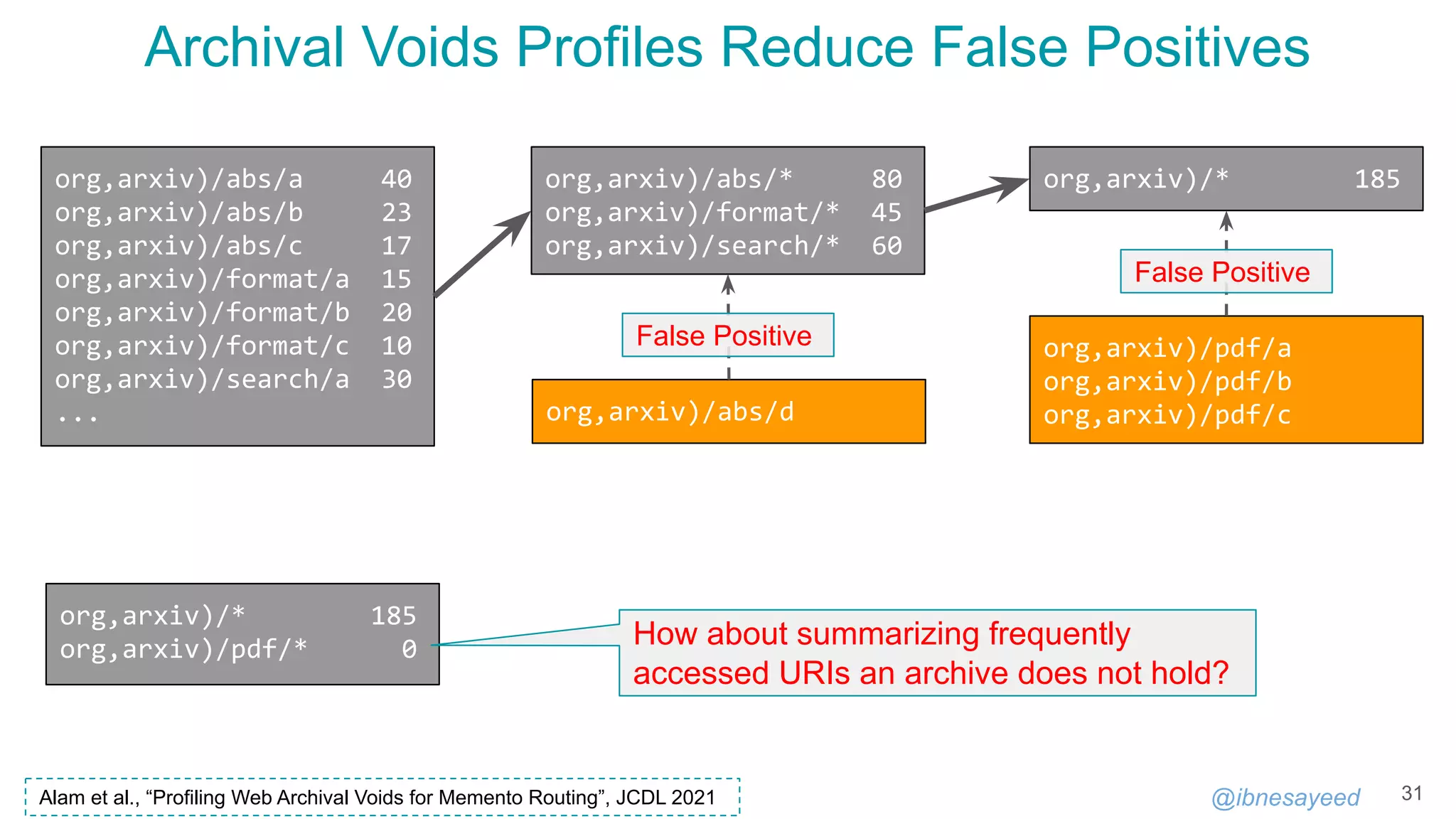
A MementoMap Example
26
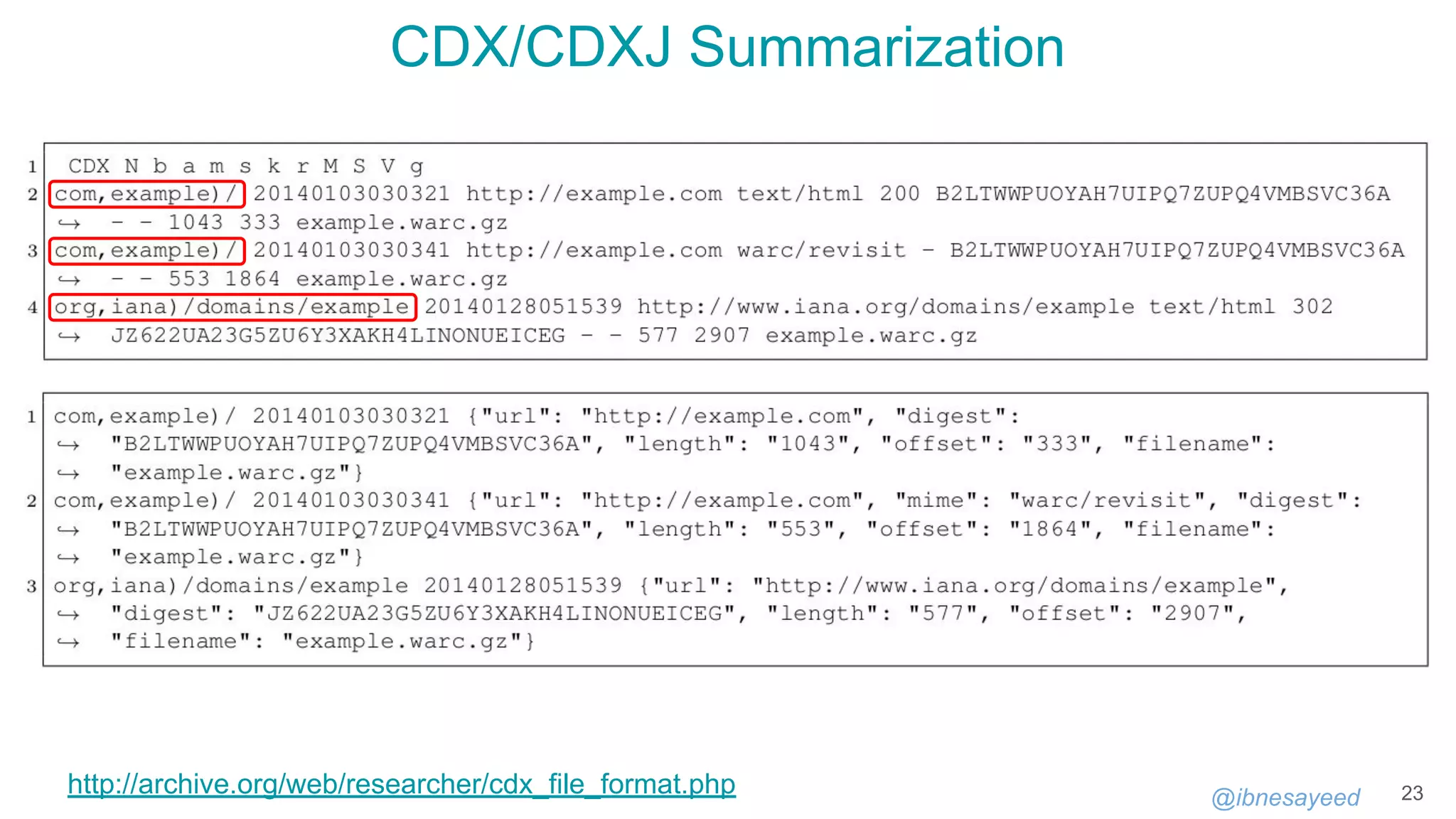
!context ["http://oduwsdl.github.io/contexts/ukvs"]
!id {uri: "http://archive.example.org/"}
!fields {keys: ["surt"], values: ["frequency"]}
!meta {type: "MementoMap", name: "A Test Web Archive", year: 1996}
!meta {updated_at: "2018-09-03T13:27:52Z"}
* 54321/20000
com,* 10000+
org,arxiv)/ 100
org,arxiv)/* 2500~/900
org,arxiv)/pdf/* 0
uk,co,bbc)/images/* 300+/20-
https://github.com/oduwsdl/ORS/blob/master/ukvs.md
Goodbye HmPn/DLim static profiling policies, thanks to our SURT with wildcard.](https://image.slidesharecdn.com/mementomap-iipc-wac-2021-210607171439/75/Summarize-Your-Archival-Holdings-With-MementoMap-26-2048.jpg)
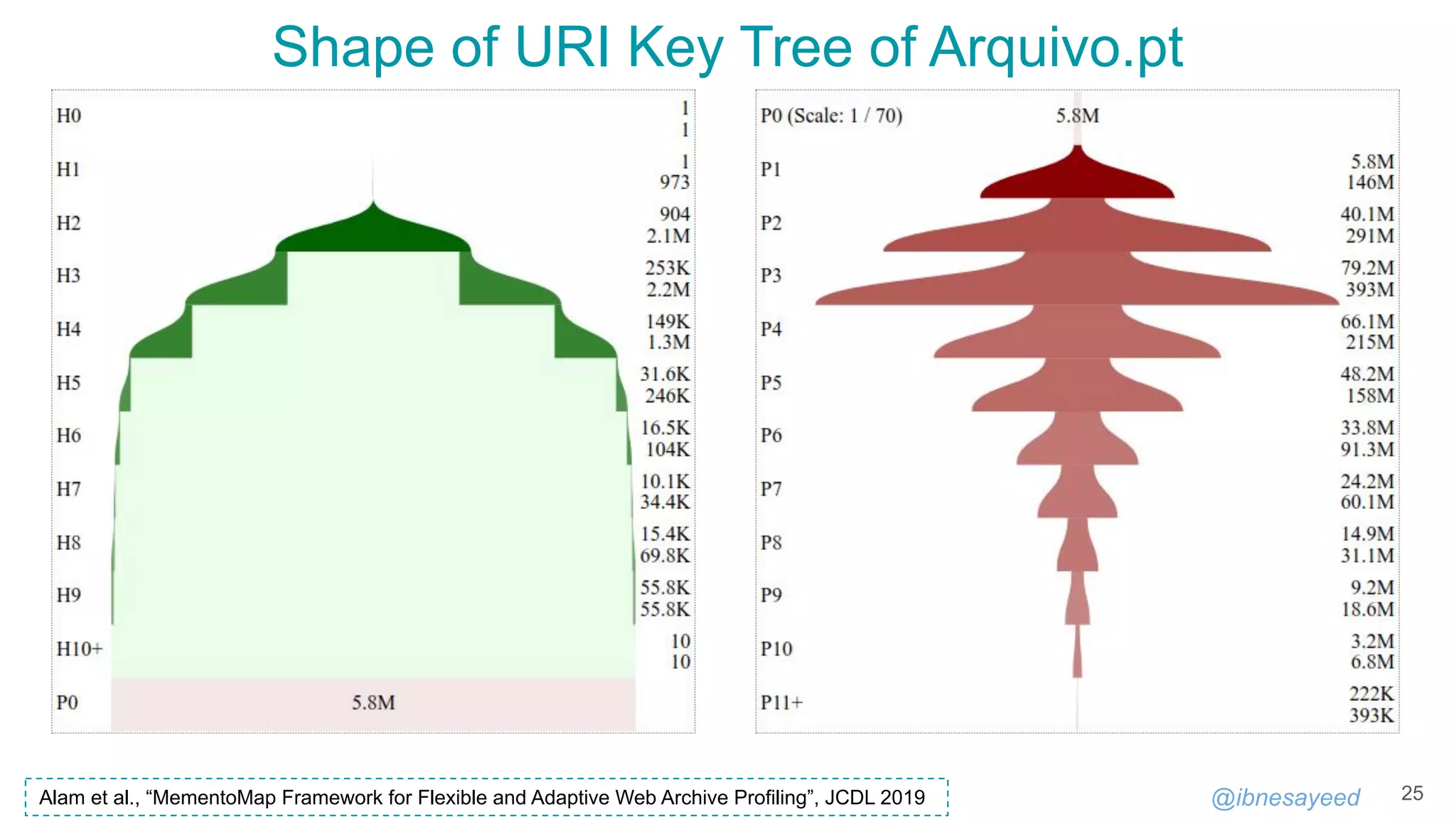
![@ibnesayeed
MementoMap
27
https://github.com/oduwsdl/MementoMap
$ mementomap
Usage: mementomap [-h] {generate,compact,lookup,batchlookup} ...
Positional Arguments:
{generate,compact,lookup,batchlookup}
generate Generate a MementoMap from a sorted file with the
first columns as SURT (e.g., CDX/CDXJ)
compact Compact a large MementoMap file into a small one
lookup Search for a URI/SURT into a MementoMap
batchlookup Search for a list of URIs/SURTs into a MementoMap
Optional Arguments:
-h, --help Show this help message and exit
Alam et al., “MementoMap Framework for Flexible and Adaptive Web Archive Profiling”, JCDL 2019](https://image.slidesharecdn.com/mementomap-iipc-wac-2021-210607171439/75/Summarize-Your-Archival-Holdings-With-MementoMap-27-2048.jpg)
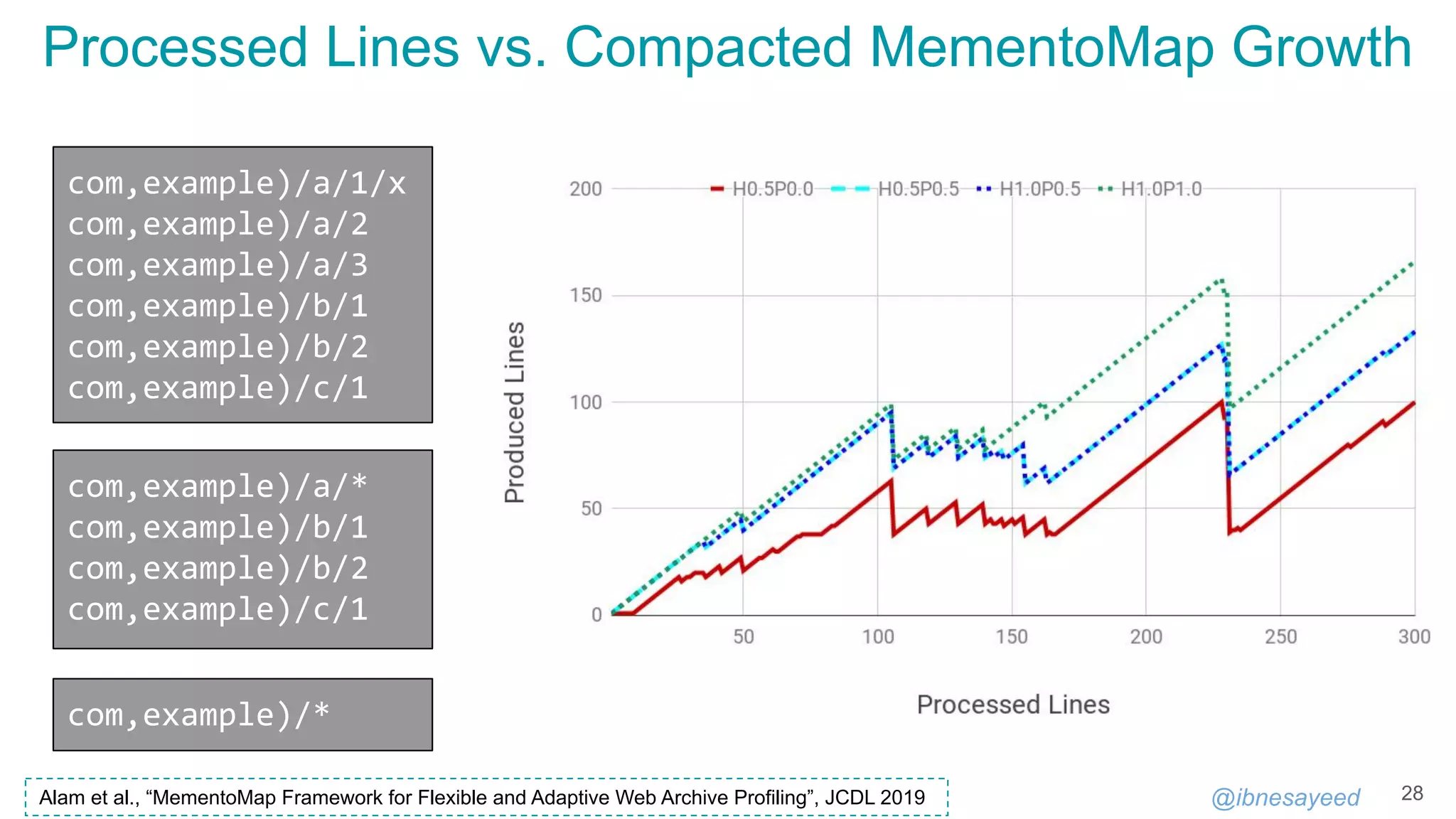
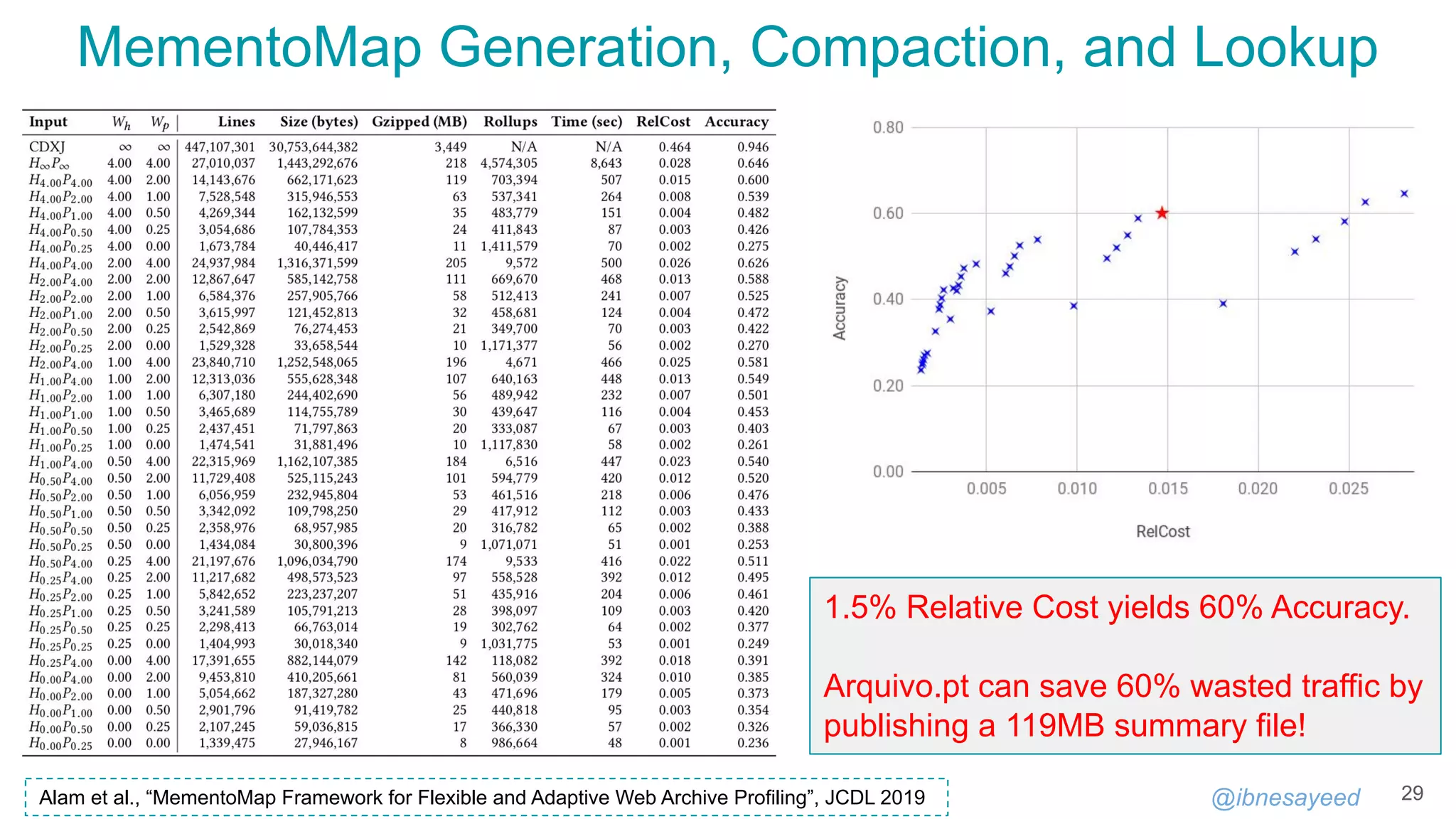




![@ibnesayeed
MementoMap Call for Adoption
36
🕮
MementoMap Framework (Doctoral Dissertation)
https://digitalcommons.odu.edu/computerscience_etds/129/
Unified Key Value Store (UKVS)
https://github.com/oduwsdl/ORS/blob/master/ukvs.md
⚙
MementoMap CLI
https://github.com/oduwsdl/MementoMap
MemGator
https://github.com/oduwsdl/MemGator
$ mementomap generate --hcf=4.0 --pcf=2.0 index.cdx[j] mementomap.ukvs
# Provide sorted list of SURTs to STDIN if not using CDX[J] index
$ scp mementomap.ukvs ${WEBHOST}:${WEBROOT}/.well-known/mementomap
# Preferably, compress the file and allow content negotiation
✉
Email: sawood@archive.org
Twitter: @ibnesayeed
IIPC Slack: #mementomap](https://image.slidesharecdn.com/mementomap-iipc-wac-2021-210607171439/75/Summarize-Your-Archival-Holdings-With-MementoMap-36-2048.jpg)

This document summarizes a presentation about using MementoMaps to efficiently route memento lookup requests to appropriate web archives. MementoMaps provide concise summaries of what URIs are held by each archive in order to avoid broadcasting requests to all archives. They can be generated from archive indexes, compacted for size, and published for discovery. Adopting MementoMaps could significantly reduce wasted lookup requests across archives.

















































































