Download as PDF, PPTX










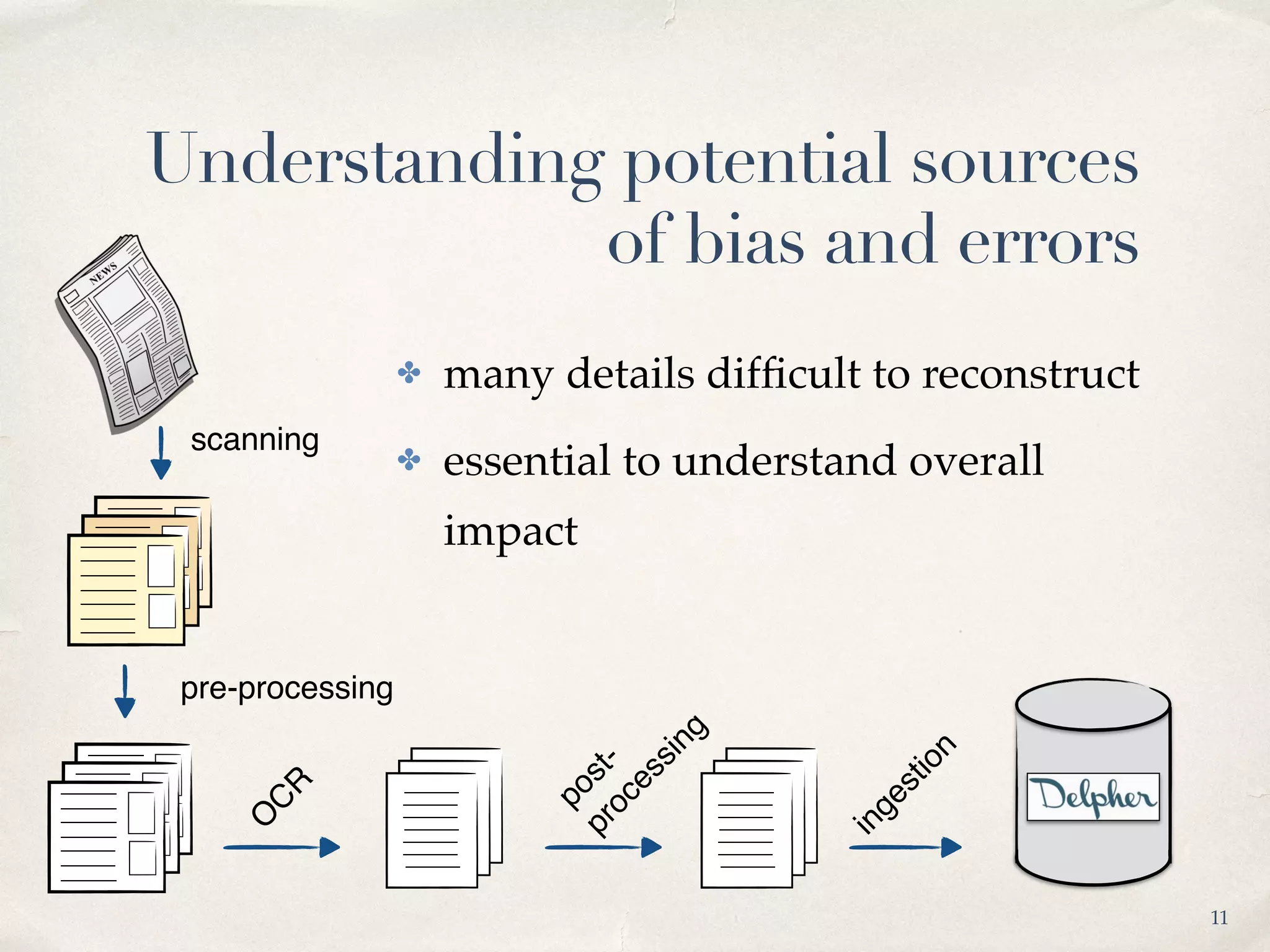


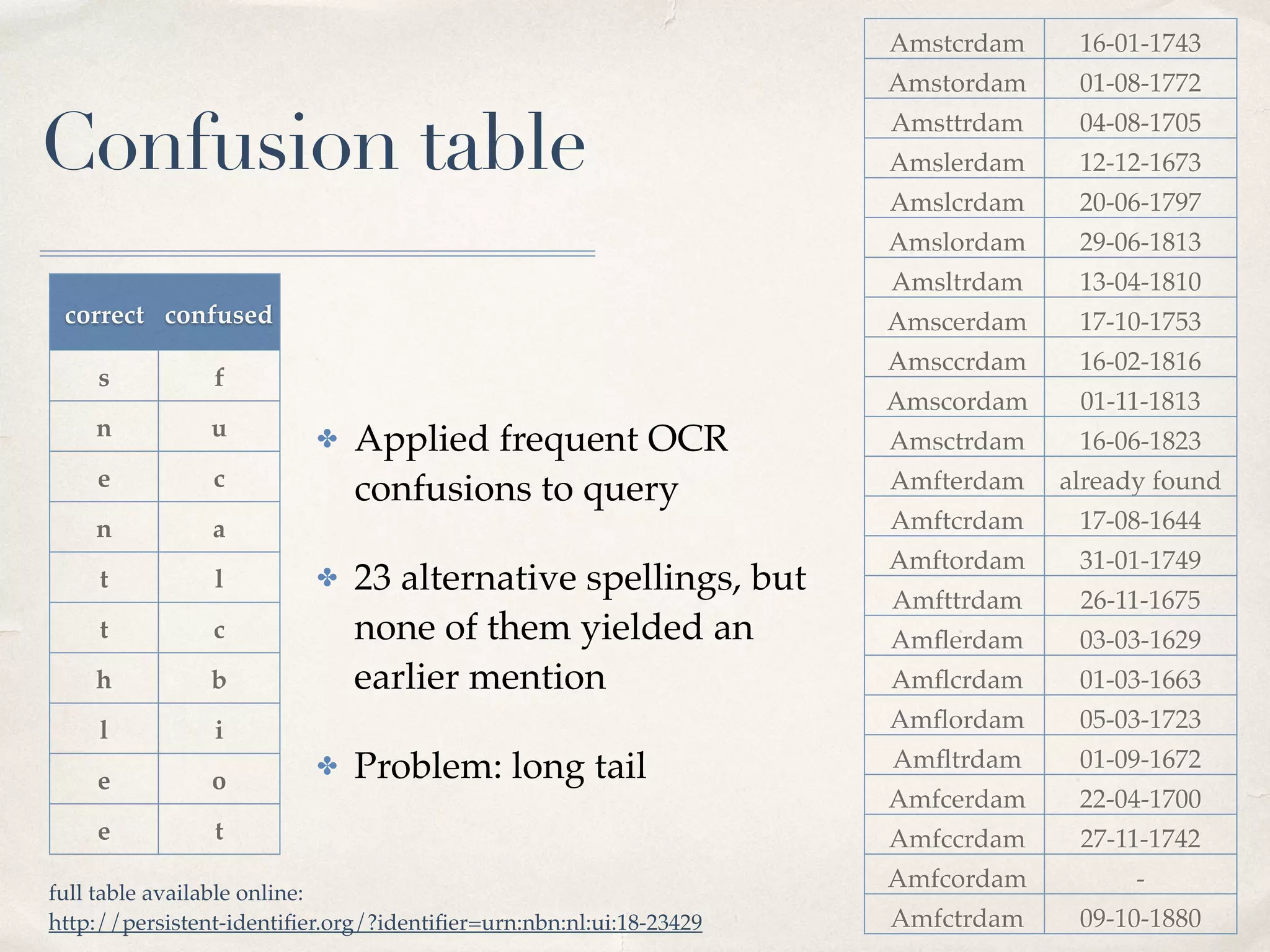


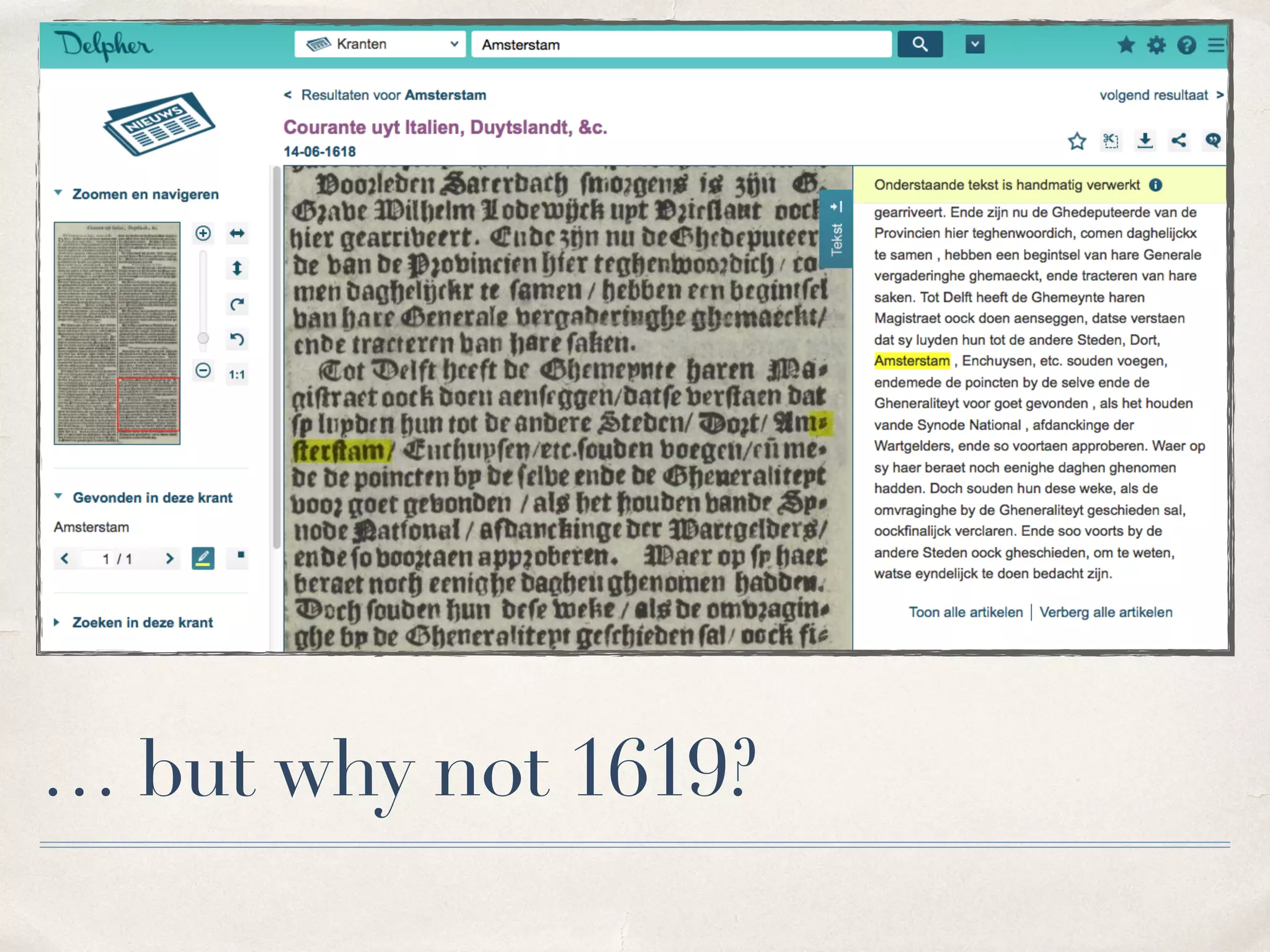
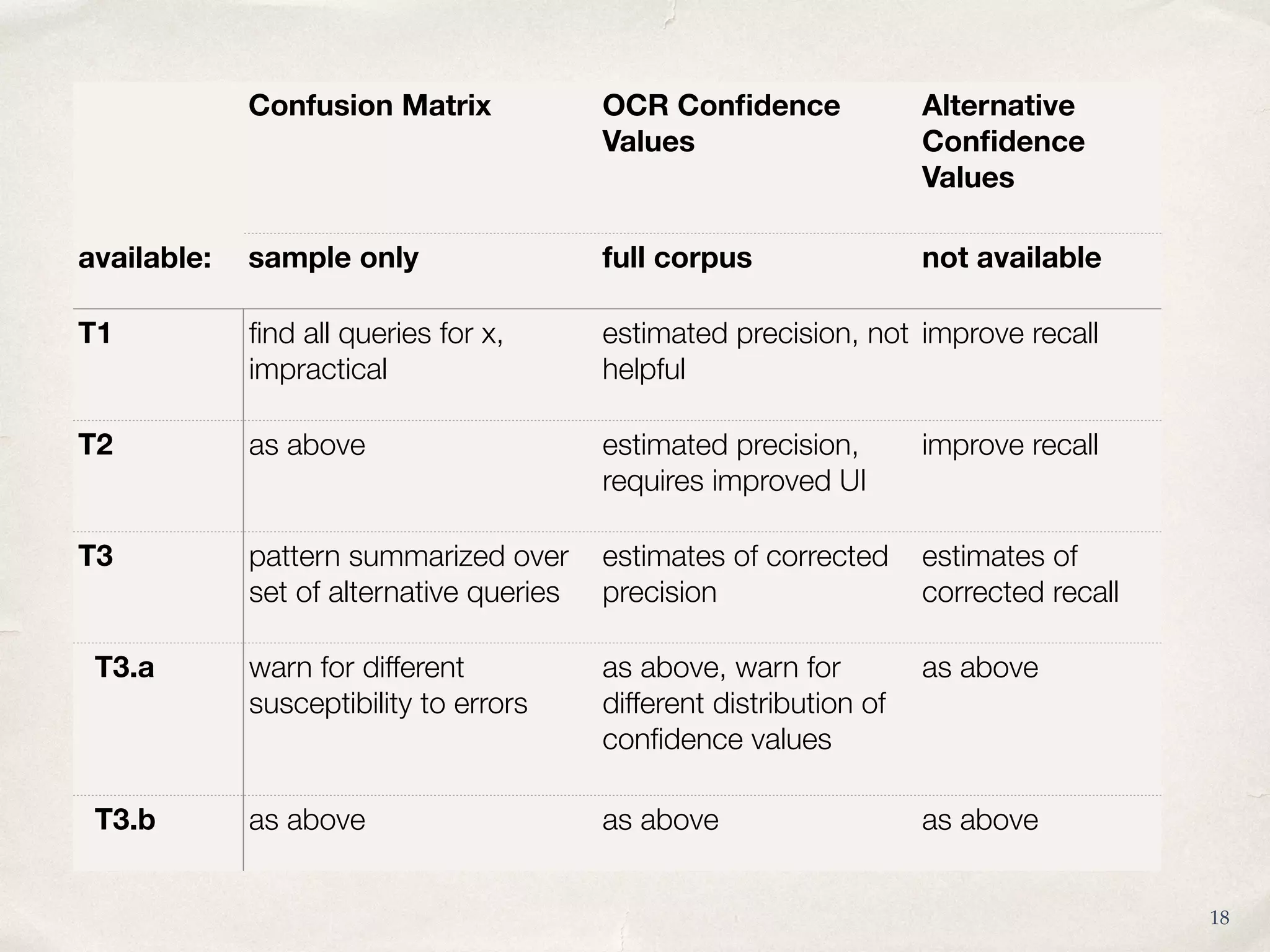




The document analyzes the impact of OCR quality on research tasks within digital archives, particularly focusing on a collaboration with the National Library of the Netherlands and its digital newspaper archive. It highlights that while scholars use these archives for exploration and selection, the poor quality of OCR data affects the reliability of quantitative analyses. Furthermore, it calls for improved transparency and alternative quality metrics to better support research tasks in this digital context.





















































